본 문서는 Josh Odgers가 작성한 “Why Nutanix Acropolis hypervisor (AHV) is the next generation hypervisor” 문서를 번역한 것이다.
원문을 참조하기 위해서는 다음 URL을 방문하면 된다.
Why Nutanix Acropolis hypervisor (AHV) is the next generation hypervisor – Part 1 – Introduction
1. 개요 (Introduction)
아크로폴리스 하이퍼바이저(Acropolis Hypervisor: AHV)가 차세대 하이퍼바이저인 이유를 설명하기 전에 뉴타닉스 XCP(Xtreme Computing Platform)에 대해 간략하게
살펴보기로 한다.
다음 그림에서 보는 것과 같이, 뉴타닉스 XCP는 프리즘(Prism)과 아크로폴리스(Acropolis)로 구성되어 있다. 프리즘은 HTML5 기반의 유저 인터페이스이고,
아크로폴리스는 멀티-하이퍼바이저 및 퍼블릭 클라우드를 지원하기 위하여 DSF(Distributed Storage Fabric)와 AMF(Application Mobility Fabric)로 구성되어 있다.
그림의 맨 아래쪽에 뉴타닉스가 지원하는 하드웨어 플랫폼이 표시되어 있는데, 현재 Supermicro, Dell(OEM)을 지원하며, 2016년 상반기 중에 Lenovo(OEM)을 지원할 예정이다.

아크로폴리스(Acropolis)와 아크로폴리스 하이퍼바이저(Acropolis Hypervisor: AHV)를 혼동하지 않아야 한다. 아크로폴리스는 vSphere, Hyper-V,
그리고 AHV를 구동시키기 위한 플랫폼이며, 아크로폴리스 하이퍼바이저는 vSphere, Hyper-V와 같은 하이퍼바이저이다.
다음에서 AHV의 특징 및 장점에 대해 설명한다. AHV는 아크로폴리스와 연동되어 동작하기 때문에, 아크로폴리스의 특징 및 장점에 대한 내용이 포함되어 있다.
2. 간단함 (Simplicity)
현대 데이터센터에서 복잡성(Complexity)은 가장 심각하면서도 가장 간과된 이슈 중의 하나이다.
가상화(Virtualization)는 데이터센터 내에서의 유연성(Flexibility)을 증가시켰으며, 데이터센터에서 해결하여야 할 수많은 문제들을 해결하였다.
그러나, 시간이 지나면서 데이터센터의 복잡성이 증가하였는데, 특히, 관리자 및 운영자의 인터페이스인 관리 컴포넌트의 복잡성이 증가하였다.
복잡성(Complexity)은 여러 가지 문제점을 수반하는데, 비용(CAPEX 및 OPEX)을 증가시킬 뿐만 아니라 가용성 및 성능 저하 등과 관련된 위험(Risk)을 증가시킨다.
고객을 위한 솔루션을 설계할 때 가장 중요한 목표 중의 하나는 고객의 요구사항을 충족시키면서도 가능하면 가장 단순하고 간단한 아키텍처를 설계하는 것이다.
아크로폴리스는 웹-스케일 기술(Web-Scale Technologies)을 기반으로 사용자 수준의 간단한 인터페이스를 갖는 엔터프라이즈 레벨의 기능을 제공하는데,
AHV 환경에서 아크로폴리스는 보다 간단하면서도 풍부한 기능을 제공한다.
2.1 의존성 제거 (Removing Dependencies)
뉴타닉스 XCP(Xtreme Computing Platform)의 간단함(Simplicity)의 가장 대표적인 특징은 외부 의존성(External Dependencies)을 제거하였다는 것이다.
AHV를 구동하기 위해 외부 데이터베이스를 사용할 필요가 없다. 이것은 Oracle, MS-SQL 등과 같은 엔터프라이즈 레벨의 데이터베이스 사용과 관련된 설계, 구현,
유지보수 등과 관련된 복잡성을 원천적으로 제거한다.
엔터프라이즈 레벨의 데이터베이스가 필요하지 않다는 것은 고가용성을 위해 AlwaysOn Availability Groups(Microsoft MS-SQL)
또는 Real Application Cluster(Oracle RAC)와 같은 환경을 고려해야 하는 경우에 더욱 큰 장점이 있다. 3rd 파티 데이터베이스에 대한 의존성이 전혀 없기 때문에,
AHV를 사용하는 경우에 제품들간의 호환성 또는 멀티 벤더 접촉 등과 관련된 복잡성을 원천적으로 제거한다.
또한, HCLs (Hardware Compatibility Lists)를 조사하거나 업그레이드를 위해 상호 호환성 매트릭스를 확인할 필요가 전혀 없다.
2.2 VM 관리 (VM Management)
전세계적으로 분산된 멀티 클러스터 AHV 환경을 관리하기 위해 단지 1개의 관리 VM(프리즘 센트럴: Prism Central)만을 배포하면 된다.
프리즘 센트럴은 어플라이언스로 제공되기 때문에 배포가 매우 간단하고, 상태 정보를 가지고 있지 않기 때문에 어플라이언스 및 데이터를 백업할 필요가 없다.
프리즘 센트럴 어플라이언스가 손실되는 경우에도, 관리자는 간단하게 새로운 프리즘 센트럴 어플라이언스를 배포한 후에 관리하고자 하는 클러스터에 연결하면 되는데,
이 작업은 클러스터 당 수초 이내에 완료된다. 데이터는 관리하고자 하는 클러스터에 저장되어 있기 때문에 히스토리컬 데이터가 손실될 우려가 전혀 없다.
아크로폴리스는 추가적인 컴포넌트를 요구하지 않기 때문에, 다른 가상화 및 하이퍼컨버지드 제품과 비교할 때, 관리를 위한 설계, 구현, 운영 등과 관련된 복잡성을 원천적으로 제거한다.
뉴타닉스 XCP에서 지원하는 ESXi, Hyper-V와 같은 하이퍼바이저는 일반적으로 기본적인 운영 및 관리 기능을 위해,
그것이 비록 상대적으로 적은 규모이거나 간단한 배포 과정을 지원한다고 할지라도, 복수의 관리 VM 및 백엔드 데이터베이스를 요구한다.
아크로폴리스는 설치 단계에서 다른 외부 컴포넌트에 대한 의존성이 전혀 없기 때문에, 고객은 데이터센터에 기존 하드웨어/소프트웨어가 전혀 없다고 하더라도,
모든 기능을 제공하는 AHV 환경을 구축할 수 있다. 이것은 초기 배포를 매우 쉽게 수행할 수 있게 할 뿐만 아니라 패치 또는 업그레이드 시에 상호 호환성과 관련된 복잡성을 제거한다.
2.3 관리 편이성 (Ease of Management)
뉴타닉스 XCP 클러스터는 탑재된 하이퍼바이저 종류에 관계 없이 프리즘 엘리먼트(Prism Element)를 사용하여 클러스터를 개별적으로 관리할 수 있을 뿐만 아니라
프리즘 센트럴(Prism Central)을 이용하여 멀티-클러스터를 중앙 집중화된 방법으로 관리할 수 있다.
프리즘 엘리먼트는 뉴타닉스 CVM에 내장되어 있기 때문에 별도의 설치 과정이 필요하지 않다. 관리자는 뉴타닉스 XCP 클러스터 IP 또는 클러스터 내의
임의의 CVM IP 주소를 통해 프리즘 엘리먼트에 액세스 할 수 있다.
레거시 가상화 제품의 관리자는 때때로 설계/배포, 컴포넌트의 관리 등과 관련된 작업을 수행하기 위해 하이퍼바이저가 제공하는 툴을 사용해야 할 필요성이 있다.
그러나, AHV 환경에서는 모든 하이퍼바이저 레벨의 기능을 HTML5 기반의 프리즘(Prism) 인터페이스를 통하여 수행할 수 있는데, 이것은 스토리지(Storage),
컴퓨트(Compute), 백업(Backup), 데이터 복제(Data Replication), 하드웨어 모니터링(Hardware Monitoring)
등과 관련된 모든 작업을 하나의 인터페이스를 통해 수행할 수 있다는 것을 의미한다.
다음 그림은 프리즘 센트럴(Prism Central)의 홈 스크린으로 AHV 환경에서 모든 멀티-클러스터에 대한 하이-레벨 정보를 제공한다.
개별 클러스터에 대한 상세 정보는 특정 클러스터를 선택하여 확인할 수 있다.
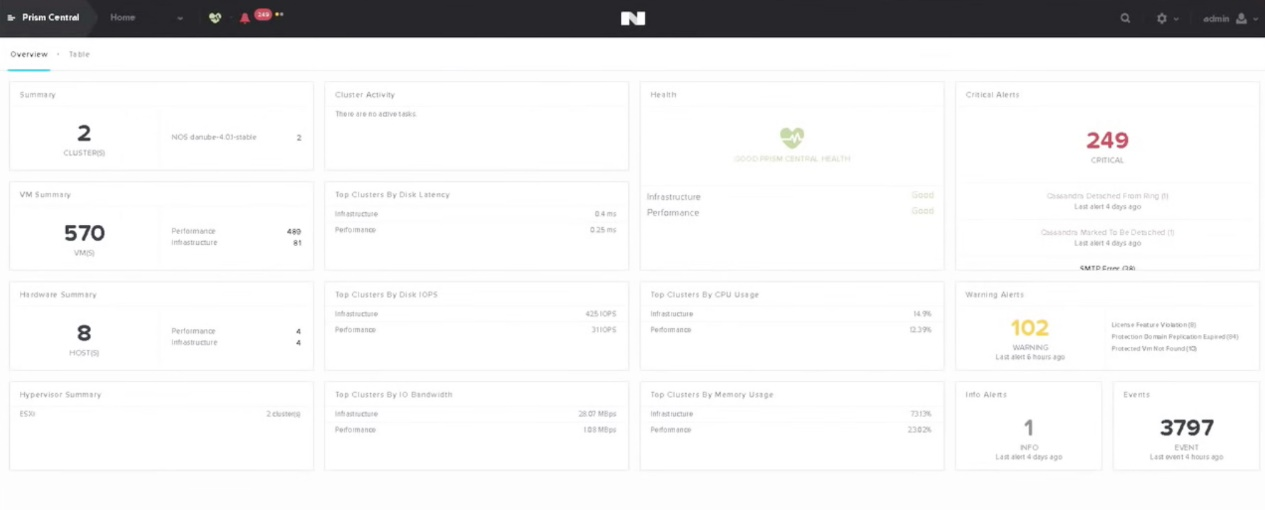
관리자는 모든 업그레이드 작업을 외부 업데이트 관리 애플리케이션/어플라이언스/VM 또는 백엔드 데이터베이스 없이 프리즘에서 원클릭으로 수행할 수 있다. 즉, 프리즘에서 원클릭으로 하이퍼바이저, Acropolis Base Platform (이전에 NOS로 알려진), 펌웨어 및 NCC(Nutanix Cluster Check) 등과 같은 모든 컴포넌트를 자동화된 롤링 업그레이드 방식으로 업그레이드 작업을 수행할 수 있다.
2.4 스토리지 복잡성의 제거
스토리지는 오랫동안 많은 고객들에게 성공적인 가상화 환경 구축의 걸림돌이었다. 뉴타닉스는 지난 수년 동안 SAN, Zoning, Masking, RAID, LUN
등과 같은 요구사항을 원천적으로 제거함으로써 진정한 의미의 소프트웨어 정의 스토리지 기능을 구현하였다.
AHV를 사용하는 경우에, 데이터스토어/마운트, 가상 SCSI 컨트롤러 등과 같은 개념을 제거함으로써 뉴타닉스 XCP의 혁신 및 특징을 한 단계 더 발전시킨다.
각 VM 디스크에 대해, AHV는 vDisk를 VM에 집적적으로 연결시키기 때문에, VM은 vDisk를 마치 물리적으로 장착된 드라이브로 인식한다. 즉 In-Guest 설정이 필요하지 않다.
이것은 얼마나 많은 가상 SCSI 컨트롤러를 사용해야 하고, VM 또는 vDisk를 어디에 위치시켜야 할지를 결정할 필요가 없다는 것을 의미한다.
아크로폴리스는 vSphere의 Storage DRS에서와 같은 VM 위치 및 용량 관리를 위한 고급 기능에 대한 필요성을 제거하였다.
Storage DRS는 전통적인 스토리지와 관련된 많은 심각한 문제들을 해결해주는 매우 훌륭한 기능이다. 그러나, 뉴타닉스 XCP에서는 전통적 스토리지가 갖고 있는 문제점들이 존재하지 않는다.
다음 그림은 프리즘 엘리먼트의 VM 설정 메뉴에서 VM이 가지고 있는 vDisk 정보를 보여준다. vDisk를 VM에 할당할 필요가 없기 때문에 vDisk는 쉽게 추가/제거 될 수 있다.
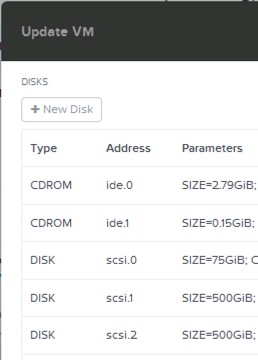
2.5 노드 설정 (Node Configuration)
프리즘에서 AHV 환경을 설정하면 클러스터 내의 각 노드에 모든 변경사항이 자동으로 적용된다. 아크로폴리스 호스트 프로파일 기능을 활성화 또는 설정할 필요가 없으며,
또한 관리자가 컴플라이언스 체크할 필요가 없고, 프로파일을 노드에 생성/적용할 필요가 없다.
AHV에서 모든 네트워킹은 vSphere의 분산 스위치(Distributed Switch)와 유사하게 완벽하게 분산되어 있다.
AHV 네트워크 설정은 클러스터 내의 모든 노드에 자동적으로 적용되기 때문에, 관리지가 노드/호스트를 가상 네트워크에 연결할 필요가 없다. 이것은 클러스터 레벨에서 설정의 일관성을 보장해 준다.
상기에서 언급한 기능이 중요한 이유는, 다음과 같은 매우 복잡한 설계/설정 관련 항목을 제거함으로써 환경을 매우 단순화시킬 수 있기 때문이다.
- 멀티패싱(Multipathing)
- 데이터스토어 개수 및 사이즈에 대한 결정
- 데이터스토어/LUN 당 수용할 수 있는 VM의 개수에 대한 고려
- 데이터스토어/패스와 관련된 설정 최대값
- 모든 노드/호스트가 동일한 설정 값을 갖도록 관리
- 네트워크 설정 관리
관리자는 SSO(Single Sign-On) 컴포넌트에 대한 요구사항을 제거하기 위해 선택적으로 아크로폴리스 내장 인증을 Active Directory 도메인에 조인할 수 있다. 모든 아크로폴리스 컴포넌트는 HA 기능을 포함하고 있기 때문에, 개별 관리 컴포넌트를 위해 HA 솔루션이 필요하지 않다.
2.6 데이터 보호 / 복제 (Data Protection / Replication)
뉴타닉스 CVM은 내장된 데이터 보호 및 복제 컴포넌트를 포함하고 있으므로, 데이터 보호 및 복제를 위해 1개 이상의 VA(Virtual Appliance)를 설계/배포/관리할 필요가 없다.
또한 클러스터 사이즈가 증가하더라도, 뉴타닉스 XCP가 자동으로 확장 및 설정하기 때문에 관리자가 수작업을 통해 이러한 컴포넌트를 설계, 구현 또는 확장할 필요가 없다.
데이터 보호 및 복제와 관련된 모든 기능은 프리즘에서 지원된다. 보다 중요한 것은 데이터 보호 및 복제 기능을 VM 기반으로 설정할 수 있기 때문에 설정의 편의성을 증가시키고 오버헤드를 줄여준다.
2.7 요약
AHV는 간단함을 위해 다음과 같은 복잡성을 원천적으로 제거한다.
- 모든 관리 컴포넌트에서 SPOF(Single Point Of Failure) 제거
- 아크로폴리스 컴포넌트를 위한 전용 관리 클러스터에 대한 필요성 제거
- 3rd 파티 OS 및 데이터베이스 플랫폼에 대한 의존성 제거
- 가상화 관리 컴포넌트의 설계, 구현, 유지보수에 대한 필요성 제거
- Web 또는 데스크탑 형태의 설계, 설치, 설정/관리에 대한 필요성 제거
- 다음과 같은 복잡성 제거
- 패치 또는 업그레이드를 위한 소프트웨어 또는 어플라이언스를 설치해야 하는 필요성 제거
- 관리 컴포넌트의 HA를 지원하기 위한 필요성 제거
- 보안 컴플라이언스를 달성하기 위해 복잡한 Hardening Guide에 대한 필요성 제거
- 추가적인 어플라이언스/인터페이스 및 외부 컴포넌트에 대한 의존성 제거
- 노드의 중앙 집중화 관리를 위해 필요한 라이선스 기능에 대한 요구사항 제거
3. 확장성 (Scalability)
확장성(Scalability)은 클러스터를 구성하는 노드의 개수 또는 최대 스토리지 용량과 관련된 것만은 아니다. 확장성과 관련된 보다 중요한 관점은 관리, 성능, 용량, 리질리언시, 운영 등을 포함한 많은 다양한 관점에서 환경을 어떤 방식으로 확장시킬 수 있느냐 하는 것이다.
3.1 관리 확장성 (Management Scalability)
AHV는 클러스터의 초기 배포 또는 클러스터에 노드를 추가할 경우에 관리 컴포넌트의 사이즈를 자동으로 결정한다.
이것은 클러스터의 초기 또는 최종 사이즈에 관계 없이 뉴타닉스 XCP 관리 컴포넌트를 사이즈를 수작업으로 설정 또는 확장할 필요가 없다는 것을 의미한다.
Resiliency Factor 3 (N+2)를 설정하게 되면, 아크로폴리스 관리 컴포넌트는 N+2 요구사항을 충족시키기 위해 자동으로 확장된다.
3.2 스토리지 용량 확장 (Storage Capacity Scaling)
뉴타닉스 DSF(Distributed Storage Fabric)은 최대 스토리지 용량에 대한 제약이 없을 뿐만 아니라 NX-6035C와 같은 “스토리지 전용(Storage-only)”
노드를 추가함으로써 컴퓨트 자원과 독립적으로 스토리지 용량을 확장할 수 있다. 뉴타닉스 “스토리지 전용”
노드는 전통적인 스토리지와 비교할 때 용량 확장과 관련된 많은 문제점들을 근본적으로 해결한다.
AHV가 탑재된 스토리지 전용 노드는 하이퍼바이저에 관계 없이 스토리지 용량을 확장할 수 있다는 장점을 제공한다.
스토리지 전용 노드는 하이퍼바이저 라이선스나 별도의 관리 컴포넌트가 필요하지 않다. 스토리지 전용 노드도 “컴퓨트+스토리지”
노드와 마찬가지로 Acropolis Base Software 및 AHV의 원클릭 업그레이드를 지원한다.
전통적인 스토리지를 확장할 때의 문제점 중의 하나는 Drive Shelf 만을 추가하고 데이터 서비스 및 관리 기능을 확장하지 않는다는 것이다.
이것은 IOPS/GB가 떨어지고, 스토리지 컨트롤러와 같은 컴포넌트의 장애 발생 시에 워크로드에 대한 영향이 증가한다는 것을 의미한다.
3.3 컴퓨트 확장성 (Compute Scalability)
클러스터에서 HA를 활성화하기 위해서는 HA를 위해 1개 이상의 노드를 예약하여야 한다. 이것은 하이퍼바이저가 최대 클러스터 사이즈에 대한 제약을 갖고 있는 경우에 불필요한 비효율성을 초래한다. AHV는 클러스터를 구성하는 노드의 수에 대한 제약이 없다. 따라서, AHV는 HA를 위해 클러스터에서 1개 이상의 노드를 예약할 필요가 없기 때문에 인프라스트럭처의 비효율적인 사용을 초래하는 불필요한 사일로우의 필요성을 제거한다. AHV 노드는 기존 클러스터에 조인될 때 필요한 모든 설정이 자동으로 수행된다. 관리자가 수행하여야 할 작업은 단지 기본 IP 정보를 입력하고, “Expand Cluster” 버튼을 클릭하는 것이다.
3.4 분석 기능의 확장성 (Analytics Scalability)
AHV는 내장된 분석 기능을 포함하고 있는데, 다른 아크로폴리스 컴포넌트와 마찬가지로 분석 컴포넌트는 초기 배포 및 노드의 추가 시에 자동으로 사이즈가 결정된다.
이것은 관리자가 새로운 분석 인스턴스 및 컴포넌트의 배포 또는 확장을 위해 별도의 추가 작업이 필요하지 않다는 것을 의미한다. 분석 기능 및 성능은 클러스터의 규모에 관계 없이 선형적으로 확장된다.
이것은 AHV가 분석 기능을 제공하기 위해 별도의 소프트웨어 인스턴스 및 데이터베이스에 대한 요구사항을 제거했다는 것을 의미한다.
3.5 리질리언시 확장성 (Resiliency Scalability)
아크로폴리스가 뉴타닉스 DSF를 사용하기 때문에, 디스크 또는 노드의 장애 시에 클러스터를 구성하는 모든 노드가 손상된 데이터를 복구하기 위해
설정된 RF(Resiliency Factor)의 복구 작업에 참여한다. 이러한 작업은 하이퍼바이저에 관계 없이 수행되지만,
AHV는 진정한 의미의 분산 관리 컴포넌트를 포함하고 있기 때문에 클러스터의 사이즈가 증가할수록 관리 계층의 리질리언시 또한 향상된다.
예를 들어, 4개의 노드로 구성된 클러스터에서 1개의 노드에 장애가 발생하면 관리 컴포넌트의 성능 측면에서 잠재적으로 25% 정도가 영향을 받을 수 있다.
그러나, 32개의 노드로 구성된 클러스터에서 1개의 노드에 장애가 발생하면 단지 3.125% 정도의 영향을 받는다.
AHV 환경이 확장됨에 따라 장애의 영향도는 감소하게 되고, 복구 시간은 빨라지게 된다.
3.6 성능 확장성 (Performance Scalability)
하이퍼바이저에 관계 없이, 뉴타닉스 XCP 클러스터가 확장됨에 따라 성능 또한 향상된다.
새로운 노드가 클러스터에 추가되는 시점에, 해당 노드에 VM이 동작하지 않더라도 추가된 CVM은 관리 및 데이터 리질리언시 태스크에 참여하게 된다.
새로운 노드를 추가하면 Storage Fabric이 좀 더 많은 컨트롤러에 RF 트래픽의 분산을 가능하게 하기 때문에 Write I/O & Resiliency가 증가하고 레이턴시는 감소한다.
AHV가 뉴타닉스 XCP가 지원하고 있는 ESXi, Hyper-V와 비교할 때 갖는 장점은 관리 컴포넌트의 성능이 클러스터 규모가 확장됨에 따라 자동적으로 향상된다는 것이다.
분석 기능과 유사하게, AHV 관리 컴포넌트도 같이 확장된다. 클러스터가 확장됨에 따라 관리 컴포넌트의 확장을 위한 수작업은 전혀 필요하지 않다.
가장 중요한 것은 뉴타닉스 XCP는 데이터 및 관리 기능을 클러스터의 모든 노드에 분산한다는 것이다.
아크로폴리스는 “mirrored” 하드웨어/컴포넌트 또는 오브젝트를 사용하지 않기 때문에, SPOF(Single Point Of Failure) 또는 병목현상이 존재하지 않는다.
4. 보안 (Security)
보안(Security)은 뉴타닉스 XCP 설계의 핵심 기능이다. 혁신적인 자동화 기능의 사용은 아마도 업계에서 가장 안전하고, 간단하며 포괄적인 가상화 인프라스트럭처를 제공할 수 있는 기반이 된다.
AHV는 많은 하드웨어 벤더 또는 범용 제품을 지원하기 위해 설계된 플랫폼이 아니다. AHV는 모든 기능 및 서비스를 진정한 의미의 웹-스케일(Web-Scale)
방식으로 제공하기 위하여 뉴타닉스 DSF(Distributed Storage Fabric) 및 뉴타닉스 OEM 파트너 장비에서 최고의 성능을 제공하도록 설계되었다.
전용 하드웨어 벤더 및 부품을 사용하기 때문에 다른 하이퍼바이저와 비교할 때 AHV는 품질 관리를 좀 더 세밀하게 집중적으로 수행할 수 있고,
제한된 컴포넌트 및 인터페이스를 갖고 있기 때문에 공격 경로를 현저하게 줄여준다.
모든 코드 라인의 완벽성을 보장하기 위해 전체 아크로폴리스 플랫폼을 통하여 SecDL(Security Development Lifecycle)이 적용된다.
이러한 설계는 DID(Defense-In-Depth) 모델을 따르는데, libvirt/QEMU에 포함된 모든 불필요한 서비스를 제거하고,
최소한의 권한을 위해 libvirt non-root group socket, vmescape 보호를 위해 SELinux confined guest, 임베디스 침임 탐지 시스템을 사용한다.
AHV는 SCCDP STIG 보안 베이스라인을 준수하는 자가 치유 기능을 제공하는 하이퍼바이저이다. 사용자가 설정을 변경하는 경우에,
AHV는 지원되는 보안 베이스라인에 기반하여 모든 변경 사항을 스캔하고, 만약 이상 징후 등이 발생하면 사용자의 개입 없이 백그라운드로 베이스라인은 안전한 상태로 초기화된다.
아크로폴리스 플랫폼은 보안 인증과 관련하여 다음과 같은 권고를 준수한다.

아크로폴리스 플랫폼이 제공하고 있는 보안 관련 기능을 요약하면 다음과 같다.
- STIG(Security Technical Implementation Guides) 준수 및 자체 감사 기능 제공
- 관리자가 보안 적용을 위해 추가적인 작업이 필요하지 않는 Out-Of-Box 하이퍼바이저
- ESXi, Hyper-V와 비교할 때 취약한 공격 경로의 최소화
5. 리질리언시 (Resiliency)
일반적으로 리질리언시(Resiliency)에 대해 이야기할 때, 단지 데이터 리질리언시만을 언급하고, 비즈니스 애플리케이션을 서비스하는데 필요한 스토리지 컨트롤러,
관리 컴포넌트의 리질리언시를 고려하지 않는 실수를 범하곤 한다.
RAID 및 Hot Spare 드라이브 등과 같은 레거시 기술들은 특정한 경우에 데이터에 대해 높은 리질리언시를 제공할 수 있지만,
스케일-아웃 및 셀프 힐링 기능을 제공하지 않은 듀얼 컨트롤러 형태로 구성된 경우에 단지 1개의 컴포넌트에 장애가 발생하더라도 데이터가 가용하지 않거나 또는 성능 및 기능이 심각하게 저하될 수 있다.
추가적으로, 만약 관리 애플리케이션 레이어가 리질리언시를 지원하지 않으면,
데이터 레이어의 높은 가용성/리질리언시는 비즈니스 애플리케이션이 정상적으로 동작하지 않을 수 있기 때문에 무용지물이 될 가능성이 있다.
아크로폴리스 플랫폼은 N+1 또는 N+2 (Resiliency Factor 2 or 3) 설정을 통하여 데이터 및 관리 레이어에서 모두 높은 리질리언시를 제공하는데,
동시에 2개의 노드에 장애가 발생하더라도 데이터 및 관리 레이어에 액세스할 수 있다. “블록 폴트 톨러런스(Block Fault Tolerance)”가 적용된 경우에는,
전체 블록(최대 4개까지의 노드 장착)에 장애가 발생하더라도 클러스터는 정상적인 서비스를 제공한다.
이것은 뉴타닉스 XCP에서 데이터 및 관리 컴포넌트의 리질리언시가 최대 N+4가 된다는 것을 의미한다.
더욱이, 뉴타닉스 XCP 클러스터의 규모가 크면 클수록, 노드/컨트롤러/컴포넌트의 장애에 따른 영향은 더욱 적어진다. 4개의 노드로 구성된 환경에서,
N-1은 25%의 영향을 미치는 반면 8개의 노드로 구성된 환경에서 N-1은 12.5%의 영향을 미친다.
즉, 클러스터 사이즈가 클수록 컨트롤러/노드 장애에 대한 영향이 적어진다. 듀얼 컨트롤러 SAN으로 구성된 환경에서,
1개의 컨트롤러에 장애가 발생하면 대부분의 경우에 약 50% 정도의 성능 저하가 발생하고, 나머지 1개의 컨트롤러에 장애가 발생하면 서비스를 제공할 수 없는 상태가 된다.
뉴타닉스 XCP는 셀프-힐링 기능을 제공하기 때문에 N-1로 구성된 환경에서 노드에 장애가 발생하더라도 데이터 손실 없이 서비스를 제공할 수 있다.
아크로폴리스 마스터 인스턴스에 장애가 발생하면, 최대 30초 이내에 새로운 아크로폴리스 마스터를 선정한 후에 정상적인 서비스를 제공한다.
이것은 관리 가용성이 99.9999% 보다 크다는 것을 의미한다. 여기서 중요한 사실은,
AHV는 이러한 관리 컴포넌트의 리질리언시가 뉴타닉스 XCP에 내장되어 디폴트로 제공될 뿐만 아니라 추가적인 설정이 전혀 필요하지 않다는 것이다.
데이터 가용성과 관련하여, 하이퍼바이저에 관계 없이 뉴타닉스 DSF는 2개 또는 3개의 데이터 및 패리티 복제본을 유지하고,
디스크 또는 노드의 장애 시에 클러스터 내에 존재하는 모든 노드가 설정된 RF의 복구 작업에 참여한다.
5.1 데이터 리질리언시 (Data Resiliency)
데이터센터에서 데이터 리질리언시가 유일하게 가장 중요한 요소는 아닐지라도, 역시 핵심 기능 중의 하나이다. 만약 공유 스토리지 솔루션에서 데이터 손실이 발생한다고 하면,
이것은 데이터센터의 목적에 부합하지 않는 것이다.
데이터 리질리언시는 뉴타닉스 DSF의 근간을 이루는 특징이기 때문에, 데이터 리질리언시 상태 정보가 프리즘의 홈 스크린에서 제공된다.
뉴타닉스 XCP 클러스터에서 정상 상태 및 장애 발생 시의 리질리언시는 다음 그림과 같이 출력된다.
즉, 클러스터에 존재하는 모든 데이터는 설정된 Resiliency Factor (RF2 또는 RF3)를 준수하며,
노드 장애가 발생하더라도 데이터를 재구축할 수 있도록 최소한 N+1의 가용 용량을 갖는다.

상기 박스를 클릭하면 허용 가능 장애에 대한 상세 정보를 제공하는 다이얼로그 박스가 출력된다. 아래 그림에서 보는 것과 같이,
RF2로 설정된 클러스터에서 메타데이터, Extent Groups, Zookeeper, OpLog 등의 컴포넌트 장애를 동시에 1개씩 허용한다.
여기에서 중요한 조건은 “동시”라는 의미이다. 뉴타닉스 XCP는 디스크 및 노드 장애 시에 자체 힐링 및 데이터 복구 작업을 수행하기 때문에,
1개의 디스크 또는 노드에 장애가 발생하더라도, 해당 장애에 대한 복구가 완료된 이후에 추가적인 장애가 발생한 경우에는 데이터 손실이 전혀 없고 클러스터는 정상적인 서비스를 제공한다.
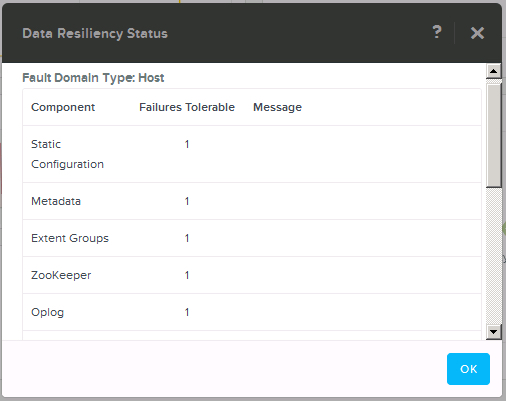
상기와 같은 장애가 발생하면 클러스터가 정상 상태가 아니므로, 프리즘은 관리자에게 경고 메시지를 보낸다.
5.2 데이터 무결성 (Data Integrity)
게스트 OS의 Write I/O에 대한 ACK는 설정된 RF에 기반하여 2개 또는 3벌의 데이터를 디스크 Write 작업이 완료된 이후에 반환된다.
만약, 데이터의 Write 작업이 완료되기 이전에 ACK를 반환하면 비록 확률이 극히 낮을지라도 데이터 손실 가능성이 존재한다.
데이터의 Write 작업이 완료되기 전에 ACK를 반환하는 경우에 얻을 수 있는 장점은 성능인데, 이러한 경우에는 데이터 손실에 대한 가능성을 감수하여야 한다.
엔터프라이즈 레벨의 스토리지 솔루션에 대한 요구사항 중에 간과되는 것 중의 하나는 SDC(Silent Data Corruption)을 검출하고 이를 복구하는 기능의 제공 여부이다.
아크로폴리스는 모든 Write 및 Read 오퍼레이션 시에 소프트웨어적으로 체크섬을 사용하여 SDC를 검출하고 복구하는 작업을 수행한다.
여기에서 중요한 것은 뉴타닉스는 데이터 무결성을 보장하기 위해 3rd 파티 솔루션이나 하드웨어 기능을 사용하지 않고, 오로지 체크섬 등과 같은 소프트웨어적인 방법만을 사용한다는 것이다.
SDC(Silent Data Corruption) 이벤트가 발생하면, 이것은 해당 데이터의 체크섬이 맞지 않는다는 것을 의미하기 때문에,
뉴타닉스는 XCP는 다른 노드에 저장되어 있는 복제본 데이터를 사용한다. 만약, Erasure Coding이 활성화되어 있는 환경에서 체크섬이 맞지 않는 경우에,
EC-X는 디스크 장애 시에 사용하는 동일한 알고리즘을 적용하여 체크섬을 재계산 한 후에 서비스를 제공한다.
뉴타닉스 DSF(Distributed Storage Fabric)는 백그라운드 작업으로 손상된 데이터를 폐기하고 정상적인 복제본 또는
Strip(EX-X가 사용되는 경우)으로 설정된 RF(Resiliency Factor)에 따라 데이터를 복구한다.
이러한 과정은 VM 및 최종 사용자에게 전혀 영향을 주지 않고 수행되는 뉴타닉스 XCP의 리질리언시를 위한 핵심 컴포넌트이다.
뉴타닉스 XCP의 근간이 되는 DSF는 모든 아크로폴리스 관리 컴포넌트를 자동으로 보호하는데, 이것은 많은 아크로폴리스 아키텍처의 장점 중의 하나이다.
RF3로 설정된 컨테이너를 갖는 환경에서 관리 컴포넌트는 N+2 가용성을 제공하므로, 동시에 3개의 노드에 장애가 발생하지 않으면 관리 컴포넌트의 가용성이 보장된다.
“블록 폴트 톨러런스(Block Fault Tolerance)”가 적용된 환경에서는 전체 블록(최대 4개까지의 노드 장착)에 장애가 발생하더라도 데이터 및 관리 컴포넌트의 가용성이 보장된다.
아크로폴리스는 원클릭 롤링 업그레이드를 지원한다. 그리고 뉴타닉스 XCP의 모든 컴포넌트가 철저하게 분산되어 있기 때문에 SPOF(Single Point Of Failure)가 없다.
가장 최악의 시나리오는 아크로폴리스 마스터 노드에 장애가 발생하는 것인데, 이 경우에도 최대 30초 이내에 새로운 아크로폴리스 마스터가 선정되고, 클러스터는 정상적인 서비스를 제공한다.
상기에서 언급한 기능은 AHV의 기능이라기 보다는 뉴타닉스 XCP의 기능이다. 그러나 뉴타닉스 XCP의 특징 및 장점은 AHV를 사용하는 경우에 배가된다.
다음에서 AHV의 로드 밸런싱 및 페일오버 기능에 대해 설명한다.
전통적인 3-티어 아키텍처(i.e. SAN/NAS)와 달리 뉴타닉스 솔루션은 모든 I/O를 로컬 컨트롤러에서 서비스하기 때문에 멀티-패싱(Multi-Pathing)과 같은 기능을 요구하지 않는다.
따라서, 멀티-패싱 정책이 존재하지 않는다.
그러나, 어떤 이유로든 로컬 CVM이 가용하지 않는 경우(CVM 장애, CVM 업그레이드,
유저에 의한 CVM의 Power-Off 등)에 해당 노드에서 동작중인 모든 VM의 I/O 서비스를 제공해주기 위해 CVM 오토패싱(CVM Autopathing or
Data Path Redundancy) 기능을 제공한다. 이러한 기능을 제공하기 위해 AHV에서는 vDisk 레벨에서 I/O를 리모트 CVM으로 리다이렉트 한다.
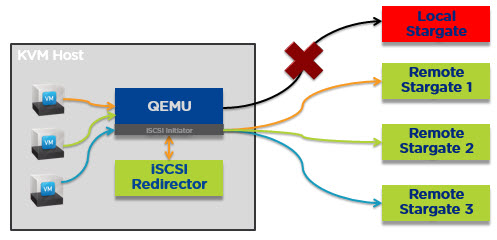
AHV에서는 모든 vDisk가 iSCSI로 제공되고, 각각은 자신의 TCP 연결을 갖는다. 이것이 의미하는 것은, MS-SQL, MS Exchange, Oracle 등과 같은 애플리케이션이 멀티 vDisk를 갖는 경우에, 각 vDisk는 자신의 스토리지 컨트롤러를 갖고 동시에 작업을 수행할 수 있다. 즉, 동시에 멀티 I/O 패스를 제공하기 때문에 Read/Write I/O 성능이 향상된다.
5.3 요약
리질리언스 관련된 기능을 요약하면 다음과 같다.
- 셀프 힐링 기능을 제공하는 Out-Of-Box 하이퍼바이저
- 데이터 레이어: SDD, HDD, 노드 장애 대응
- 관리 레이어: 아크로폴리스 및 프리즘 장애 대응
- 소프트웨어 기반의 체크섬을 이용한 내장된 데이터 무결성 보장
- 동시에 최대 4개 노드의 장애를 허용 (블록 폴트 톨러런스가 적용된 경우)
- 관리 컴포넌트의 가용성은 99.9999% 이상
- 데이터 또는 관리 레이어의 리질리언시를 위한 하드웨어 의존성이 전혀 없음
6. 성능 (Performance)
데이터센터 레벨에서 성능을 이야기할 때, 단순히 IOPS, 대역폭, 레이턴시 등과 같은 단편적인 성능 지표만으로 데이터센터의 성능을 판단할 수는 없다. 데이터센터의 성능을 전체적으로 파악하기 위해서는 관리 컴포넌트, 애플리케이션/VM, 분석, 데이터 리질리언시 등과 같은 데이터센터를 구축 및 운영하는데 필요한 모든 것을 살펴보아야 한다.
6.1 관리 성능 (Management Performance)
아크로폴리스 관리 레이어는 아크로폴리스 운영체제(이전에 NOS로 알려진), 프리즘(HTML5 GUI), 그리고 “마스터(Master)” 및
“슬레이브(Slave)”로 이루어진 AHV 관리 스택을 모두 포함한다.
아크로폴리스 아키텍처에서 모든 CVM은 플랫폼의 원활한 운영을 보장하기 위해 동등한 역할을 분산하여 수행한다. 이것은 병목현상을 유발할 수 있는 마스터 애플리케이션,
데이터베이스 또는 컴포넌트가 없고, 모든 컴포넌트가 웹-스케일(Web-Scale) 플랫폼을 제공하기 위해 완벽하게 분산되었다는 것을 의미한다.

모든 CVM은 로컬 노드를 관리하기 위해 필요한 모든 컴포넌트를 포함하고 있으며, 클러스터를 구성하기 위한 DSF 및 관리 태스크 작업에 참여한다.
클러스터의 모든 노드에서 동작하는 CVM은 역할에 따라 아크로폴리스 마스터(Acropolis Master) 또는 아크로폴리스 슬레이브(Acropolis Slave)로 동작한다.
아크로폴리스 마스터(Acropolis Master)는 다음과 같은 태스크를 수행한다.
- HA를 위한 스케줄러
- 네트워크 컨트롤러
- 태스크 실행
- 하이퍼바이저로부터 로컬 통계정보 수집 및 배포
- VM 콘솔 연결을 위한 VNC 프록시
- IP 주소 관리
아크로폴리스 슬레이브(Acropolis Slave)는 다음과 같은 태스크를 수행한다.
- 하이퍼바이저로부터 로컬 통계정보 수집 및 배포
- VM 콘솔 연결을 위한 VNC 프록시
“마스터” 또는 “슬레이브” 역할에 관계 없이, 모든 CVM은 가장 부하가 큰 2가지의 태스크를 수행하는데,
하나는 하이퍼바이저로부터 통계 정보를 수집/배포하는 것이고, 다른 하나는 VM의 콘솔 연결을 위한 VNC 프록시 역할을 수행하는 것이다.
뉴타닉스 XCP 플랫폼의 분산 아키텍처는 일관성 있는 높은 성능을 제공한다. 중앙 관리 VM 또는 관련된 데이터베이스 서버에 통계 정보를 전송하는 것은
일종의 병목현상을 유발할 수 있을 뿐만 아니라 애플리케이션 레벨의 HA(e.g. SQL Always On Availability Group)를 도입하는 경우에 이것이 하나의 SPOF가 될 수 있다.
아크로폴리스 마스터가 수행하는 역할은 HA를 위한 스케줄러, 네트워크 컨트롤러, 태스크 실행, IP 주소 관리 등과 같은 매우 가벼운 태스크이다.
HA 스케줄러 태스크는 노드 장애가 발생할 경우에만 활성화되는데, 이것은 마스터에게 매우 적은 오버헤드만 준다.
네트워크 컨트롤러 태스크는 새로운 VLAN이 설정되는 것과 같은 특정 이벤트가 발생할 경우에만 활성화된다.
태스크 실행자는 단순히 태스크 모니터링과 CVM에 태스크를 분산하는 역할을 수행한다. IP 주소 관리 모듈은 일반적인 DHCP 서버로 매우 적은 오버헤드만 준다.
6.2 데이터 로컬리티 (Data Locality)
데이터 로컬리티(Data Locality)는 뉴타닉스 XCP의 독특한 기능으로 새로운 I/O Write는 VM이 동작하고 있는 로컬 노드에 저장되며,
복제본은 클러스터의 임의의 다른 노드에 저장된다. 데이터 로컬리티는 Read I/O 시에 네트워크를 경유하거나 또는 리모트 컨트롤러를 사용하는 경우를 최소화한다.
VM이 클러스터에서 마이그레이션 될 경우에도, Write I/O는 항상 로컬에서 수행된다. 만약 데이터가 리모트 노드에 존재하면 리모트 Read가 발생하지만,
이 경우에 데이터를 로컬 노드로 마이그레이션 하기 때문에, 이후의 Read I/O는 로컬 노드에서 수행된다. 데이터가 리모트에 있을지라도,
데이터에 대한 Read I/O가 없으면 리모트 I/O는 발생하지 않는다. 즉, 일반적으로 90% 이상의 I/O는 로컬에서 발생한다.
데이터 로컬리티 기능은 뉴타닉스 XCP가 지원하는 ESXi, Hyper-V에서도 제공되지만, AHV는 VM의 데이터 위치를 고려하는 VM 데이터 인식(Data-Aware)
기능을 지원하기 때문에 다른 하이퍼바이저와 비교할 때 다른 많은 장점을 제공한다. 예를 들어, AHV는 VM의 전원이 인가될 때,
로컬 데이터를 많이 저장하고 있는 노드에 VM을 구동시켜 주기 때문에, 리모트 I/O를 최소화하고, VM의 장애 또는 유지보수와 관련된 작업에 수반되는 오버헤드를 줄여준다.
추가적으로, 데이터 로컬리티는 하이퍼바이저 및 VM 통계 등과 같은 분석을 위해 필요한 백엔드 데이터를 수집하여 저장하는 경우에도 적용된다.
즉, 통계 데이터는 로컬에 저장되고, 복제본은 리모트 노드에 저장된다(RF3인 경우에 나머지 2벌의 복제본은 리모트 노드에 저장된다).
이것은 상당히 많은 통계 데이터를 모든 노드에 균일하게 분산하여 저장하기 때문에, 클러스터의 사이즈에 관계 없이 모든 노드는 일정한 양의 데이터를 관리하면 된다는 것을 의미한다.
6.3 요약
성능(Performance)과 관련된 요약은 다음과 같다.
- 일관성 있는 성능을 보장하기 위해 관리 컴포넌트는 클러스터와 함께 자동으로 확장된다.
- 데이터 로컬리티는 데이터를 컴퓨트(CM)과 가능하면 가장 가까이에 위치하도록 보장한다.
- 데이터 위치에 따라 VM의 위치를 인텔리전트 하게 결정한다.
- 모든 뉴타닉스 CVM은 클러스터의 모든 컴포넌트 및 워크로드가 최적의 성능을 발휘할 수 있도록 팀(Team)으로 동작한다.
7. 민첩성 (Agility)
다른 하이퍼바이저 및 관리 솔루션을 배포하는 경우에, 일관된 성능 보장, 다운타임 최소화,
민첩성 향상 등과 같은 기능을 보장하기 위해서는 일반적으로 많은 설계 노력 및 전문가를 필요로 한다. 아크로폴리스 관리 컴포넌트는 뉴타닉스 소프트웨어에 내장되어 있고,
클러스터 환경에 최적화되어 있기 때문에 설계 부분에 대해 전혀 신경을 쓸 필요가 없다. 이것은 다른 하이퍼바이저에 비해 AHV를 보다 빠르고 신속하게 배포할 수 있다는 것을 의미한다.
AHV 기반의 환경에서는 초기 클러스터 사이즈에 관계 없이, 모든 관리, 분석, 데이터 보호, BC/DR 컴포넌트는 자동으로 배포 및 설정된다.
즉, AHV 클러스터 사이즈에 관계 없이, 관리 컴포넌트에 대한 설계 노력은 전혀 필요하지 않다.
AHV는 고객이 솔루션을 쉽고 빠르게 배포할 수 있는 많은 기능을 제공한다.
내장된 관리 및 분석 기능
클러스터 관리를 위해 필요한 모든 툴은 클러스터와 함께 자동으로 배포된다는 것은 이러한 관리 툴의 설계/배포/검증을 위한 작업이 전혀 필요하지 않다는 것을 의미한다. 또한, 웹 브라우저에서 모든 관리 작업을 수행할 수 있기 때문에, AHV 관리를 위해 클라이언트를 설치할 필요가 없다.
내장된 보안/감사 기능을 갖는 사전에 설정된 하이퍼바이저
디폴트로 보안 기능을 제공한다는 것은 구축 단계에서 보안 관련된 작업을 할 필요가 없다는 것을 의미한다. 또한 자동화된 감사 기능을 제공한다는 것은 일상적인 비즈니스 오퍼레이션 동안에 보안 설정이 변경된 경우에 이를 자동으로 감지하고 설정된 보안 기준에 따라 감사를 수행한 후에, 보안 베이스라인 위배 시에 요구된 보안 프로파일로 자동으로 초기화 된다는 것을 의미한다.
인텔리전트 클론
AHV 환경에서 동작하는 DSF는 VM의 즉각적인 클론 작업을 가능하게 한다. 클론 작업은 VM의 전원 상태에 무관하게 지원된다.
민첩성과 관련된 요약은 다음과 같다.
- AHV 환경에서는 설계/구현 단계에서 필요한 노력을 최소화한다.
- 멀티-클러스터 중아 관리가 요구되는 경우에, VA로 제공되는 프리즘 센트럴만을 설치하면 된다.
- 분석, 데이터 보호, 복제, 관리 고가용성을 위해 추가적인 어플라이언스 및 컴포넌트의 설치가 필요하지 않다.
- 아크로폴리스 플랫폼의 배포를 위해 SME(Subject Matter Experts)가 필요하지 않다.
8. 분석 기능 (Analytics)
아크로폴리스는 강력하지만 사용하기 매우 쉬운 분석 기능을 제공하는데, 이것은 아크로폴리스 플랫폼, 컴퓨트(아크로폴리스 하이퍼바이저 / VM), 및 스토리지(DSF)를 포함한다.
다른 분석 솔루션과 달리, 아크로폴리스는 설계/배포/설정을 위한 추가적인 소프트웨어 라이선스, 관리 인프라스트럭처, 또는 VM/애플리케이션의 설치를 필요로 하지 않는다.
뉴타닉스 Controller VM은 내장된 분석 기능을 포함하고 있으므로 외부 의존성이 전혀 없다. 분석 데이터를 다른 제품 또는 VA로 임포트 하거나 추출할 필요가 없다.
분석 기능은 클러스터 생성과 동시에 사용할 수 있을 뿐만 아니라 클러스터 사이즈가 증가하더라도 아크로폴리스가 분석 컴포넌트를 자동으로 확장하기 때문에,
분석 기능을 위한 새로운 인스턴스의 생성/설정 등과 같은 추가적인 작업을 수행할 필요가 전혀 없다.
분석 기능과 관련된 요약은 다음과 같다.
- 분석 솔루션 내장
- 추가적인 라이선스 필요하지 않음
- 설계/구현이 필요하지 않으며, VM/어플라이언스의 배포도 필요하지 않다.
- 뉴타닉스 XCP가 확장됨에 따라 분석 컴포넌트도 자동으로 확장된다.
9. 비용 (Cost)
비용 측면을 고려할 때, AHV는 하이퍼바이저 및 하이퍼바이저와 관련된 관리 컴포넌트 라이선스 등과 관련된 직접적인 비용을 절감할 수 있다는 것 이외에, 설계, 구현, 운영, 유지보수 등과 관련된 많은 시간과 노력을 절감할 수 있다.
단순화된 설계 단계 (Simplified Design Phase)
AHV는 고가용성 및 자동 확장을 지원하는 관리 컴포넌트가 내장되어 있기 때문에, 관리 솔루션의 설계를 위해 SME(Subject Matter Expert)를 투입할 필요가 없다.
단순화된 구현 단계 (Simplified Implementation Phase)
모든 관리 컴포넌트가 자동으로 배포(프리즘 센트럴 제외)되기 때문에, 관리 컴포넌트의 설치 및 패치 작업을 위한 엔지니어가 필요하지 않다.
아크로폴리스 및 모든 관리 컴포넌트가 CVM에 포함되어 있다는 것은 설치 및 설정이 잘못될 가능성이 거의 없을 뿐만 아니라 이를 별도의 절차에 따라 검증할 필요가 없다는 것을 의미한다.
단순화된 오퍼레이션 및 운영 관리 (Simplified ongoing operations)
아크로폴리스는 Acropolis Base Software(이전에 NOS로 알려진), AHV, 펌웨어,
NCC(Nutanix Cluster Check) 등을 한번의 클릭으로 자동화된 롤링 업그레이드 기능을 제공한다.
또한, 업그레이드를 위해 HCLs(Hardware Compatibility Lists) 및 상호운용성 매트릭스를 확인할 필요가 없다.
AHV는 용량 관리를 스토리지 풀(Storage Pool) 레이어에서 수행하기 때문에 용량 관리를 매우 단순화시킨다. 이것은 관리자가 LUN 등을 관리하지 않아도 된다는 것을 의미한다.
3rd 파티 라이선스 비용의 절감 (Reduced 3rd party licensing costs)
AHV는 모든 관리 컴포넌트를 내장하고 있기 때문에(프리즘 센트럴은 어플라이언스로 제공), 관리컴포넌트를 위해 OS를 라이선스 할 필요가 없다. 또한, AHV는 MS-SQL, Oracle 등과 같은 3rd 파티 DBMS를 필요로 하지 않는다.
관리 인프라스트럭처 비용 절감 (Reduced Management Infrastructure Costs)
가상화 솔루션이 중앙 관리, 패치, 성능 및 용량 관리 등을 위해 여러 개의 관리 컴포넌트(전용 VM을 필요로 할 수도 있음)를 가져야 한다는 것은 상식적이지 않다.
이러한 경우에, 클러스터 사이즈가 증가함에 따라 관리 VM의 개수 및 관리 VM의 고가용성을 위한 요구사항이 증가하게 되며, 이것은 결국 추가적인 컴퓨트 및 스토리지를 요구하게 된다.
모든 관리 컴포넌트가 뉴타닉스 노드에서 동작하는 뉴타닉스 Controller VM에 포함되어 있기 때문에, 전용 VM 또는 전용 관리 클러스터가 필요하지 않다. 따라서, 컴퓨트/스토리지 자원을 절감할 수 있다.
상면 및 전력의 절감
뉴타닉스 플랫폼은 집적도가 높기 때문에 다음과 같은 부분에서 비용을 절감할 수 있다.
- 상면 공간
- 전원 및 냉각 장치
- 네트워크 포트
- 적은 컴퓨트 노드 수
- 적은 스토리지 용량