
The Nutanix Bible - Classic Edition
[NOTE] 한글 번역본에서는 PDF 다운로드를 지원하지 않습니다.

뉴타닉스 바이블의 클래식 에디션에 오신 것을 환영합니다!! 뉴타닉스 바이블의 목적은 뉴타닉스 플랫폼 아키텍처에 대한 대한 보다 심층적인 기술 정보를 제공하는 것입니다.
Part 1: Core
Book of Basics
web·scale - /web ‘ skãl/ - noun - computing architecture
인프라 및 컴퓨팅 아키텍처에 대한 새로운 접근 방식.
뉴타닉스는 소프트웨어 스택 전체에서 "웹-스케일(Web-scale)" 원칙을 활용한다. 웹-스케일은 이를 활용하기 위해 Google, Facebook, Amazon 또는 Microsoft만큼 커질 필요가 있음을 의미하지 않는다. 웹-스케일 원칙은 3개 노드 또는 수천 개의 노드에 관계없이 모든 규모에 적용 가능하며 많은 장점을 제공한다.
"웹 스케일" 인프라에 대해 이야기할 때 사용되는 몇 가지 핵심 컨스트럭트가 있다.
- 하이퍼컨버전스 (Hyper-convergence)
- 소프트웨어 정의 인텔리전스 (Software defined intelligence)
- 분산 자율 시스템 (Distributed autonomous system)
- 점진적인 선형 스케일-아웃 (Incremental and linear scale out)
기타 관련 항목은 다음과 같다.
- API 기반 자동화 및 풍부한 분석 기능 (API-based automation and rich analytics)
- 핵심 테넌트로서의 보안 (Security as a core tenant)
- 셀프 힐링 (Self-healing)
본 BOOK에서는 이러한 기본적인 아키텍처뿐만 아니라 핵심 아키텍처의 개념을 설명한다.
전략 및 비전
뉴타닉스는 한 가지 목표에 집중했다.
Make infrastructure computing invisible, anywhere.
이러한 간단함은 세 가지 핵심 영역에 중점을 두어 달성할 수 있었다.
- 선택의 자유 및 이식성을 제공한다 (HCI/클라우드/하이퍼바이저)
- 컨버전스, 추상화 및 지능형 소프트웨어(AOS)를 통해 "스택"을 단순화한다.
- 사용자 경험(UX) 및 디자인(프리즘)에 중점을 두어 직관적인 사용자 인터페이스(UI) 제공
HCI/클라우드/하이퍼바이저: “선택의 자유”
뉴타닉스는 단일 하이퍼바이저(ESXi)를 지원하는 단일 하드웨어 플랫폼(NX)으로 시작했지만, 우리는 항상 단일 하이퍼바이저/플랫폼/클라우드 회사 이상이라는 것을 알고 있었다. 이것이 뉴타닉스가 vCenter에서 플러그인으로 실행하지 않고 처음부터 자체 UI를 구축하고, 기본적으로 커널이 아닌 VM을 실행하는 이유 중 하나였다 (물론 더 많은 이유가 있다). 왜 "선택의 자유"를 이야기할까요?
하나의 하이퍼 바이저, 하나의 플랫폼 또는 하나의 클라우드로 모든 고객의 니즈를 만족시킬 수 있는 것은 아니다. 동일 플랫폼에서 여러 개의 환경을 지원함으로써 뉴타닉스는 고객에게 선택과 활용의 자유를 제공한다. 고객에게 선택의 자유를 제공함으로써 뉴타닉스는 고객에서 유연성을 제공한다. 뉴타닉스가 제공하는 모든 것이 뉴타닉스 플랫폼의 일부이므로 모두 동일한 경험을 제공한다.
뉴타닉스는 이제 12개가 넘는 하드웨어 플랫폼(직접/OEM/써드-파티), 여러 개의 하이퍼바이저(AHV, ESXi, Hyper-V 등)를 지원하고, 모든 주요 클라우드 공급 업체(AWS, Azure, GCP)와의 통합을 확장하고 있다. 이를 통해 고객은 자신에게 가장 적합한 것을 선택할 수 있으며 공급 업체 간의 협상 목적으로 이를 사용할 수 있다.
NOTE: 플랫폼은 섹션 전체에서 일반적으로 사용되는 키워드이다. 우리는 일회성 제품을 만들려고 하지 않으며 플랫폼을 만든다.
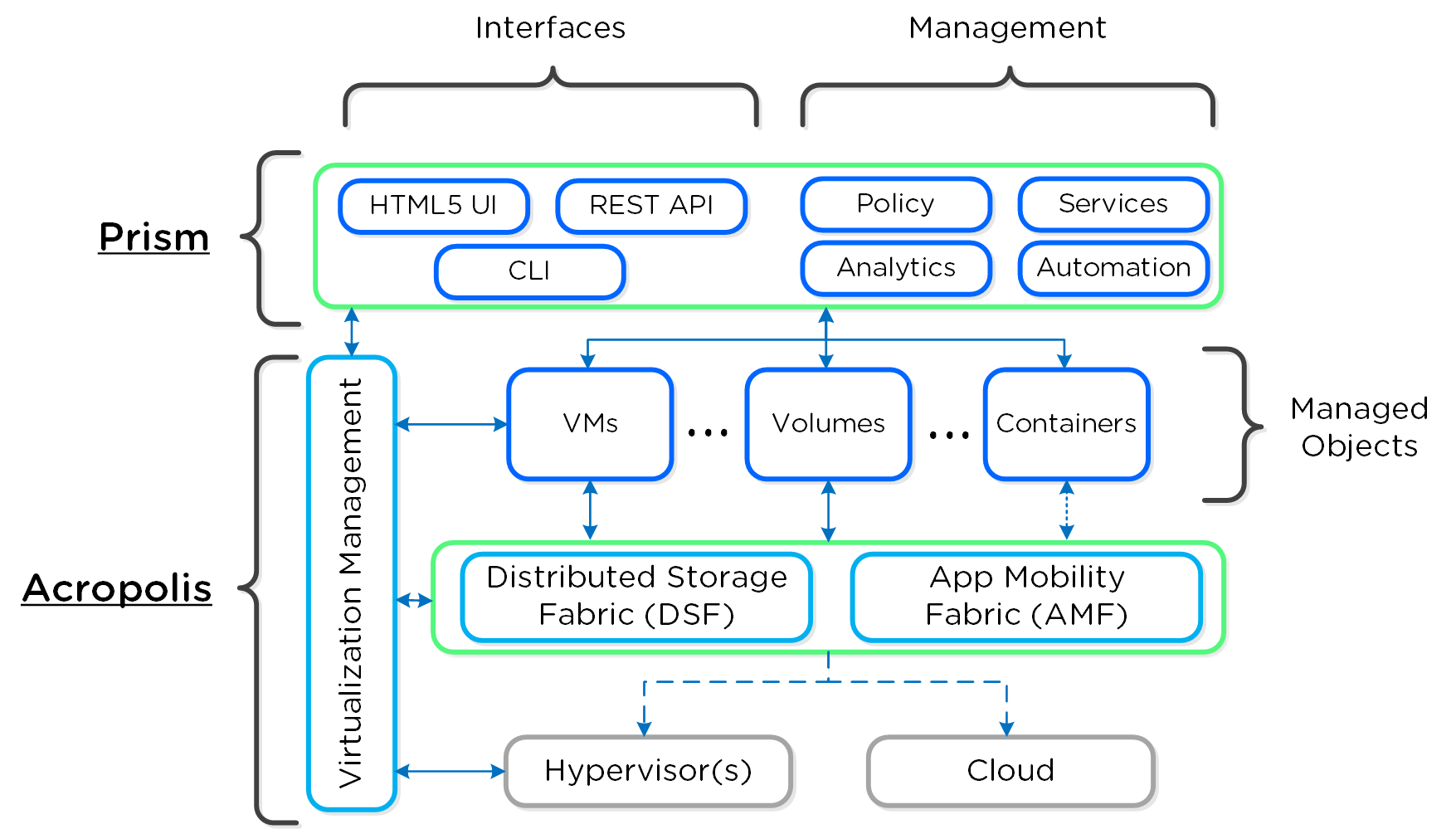
다음은 뉴타닉스 플랫폼의 하이-레벨 아키텍처를 보여준다.
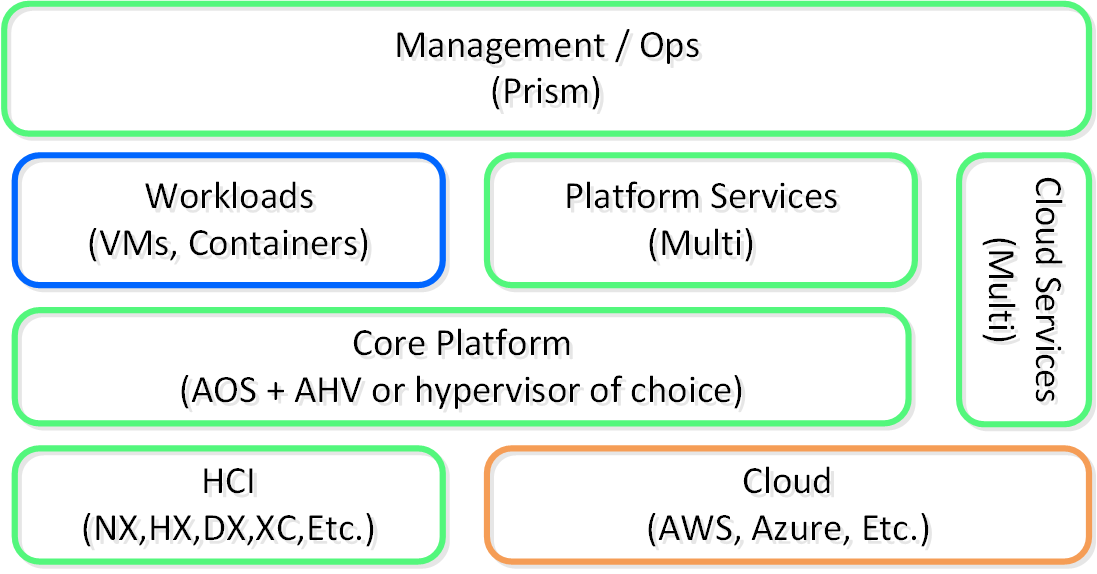 뉴타닉스 플랫폼 - 아키텍처 (Nutanix Platform - Architecture)
뉴타닉스 플랫폼 - 아키텍처 (Nutanix Platform - Architecture)
AOS + AHV/하이퍼바이저: “런타임”
뉴타닉스는 로컬 스토리지 리소스와 지능형 소프트웨어를 결합하여 "중앙 집중식 스토리지"를 제공하는 분산 스토리지 패브릭(DSF는 뉴타닉스 분산 파일 시스템 또는 NDFS라고도 함) 기능으로 스토리지를 단순화함으로써 이러한 여정을 시작했다.
수년에 걸쳐 뉴타닉스는 많은 기능을 추가했다. 단순화를 위해 이것을 두 가지 핵심 영역으로 나눈다.
- 핵심 서비스
- 기반 서비스
- 플랫폼 서비스
- 핵심 서비스를 기반으로 추가 기능/서비스를 제공하는 서비스
핵심 서비스는 워크로드(VM/컨테이너) 및 하이-레벨 뉴타닉스 서비스의 실행을 용이하게 하는 기반 서비스 및 컴포넌트를 제공한다. 처음에는 이것이 DSF 제품이었지만 스택의 단순화 및 추상화를 돕기 위해 플랫폼의 기능을 계속 확장하고 있다.
다음은 AOS 핵심 플랫폼에 대한 하이-레벨 뷰를 보여준다.
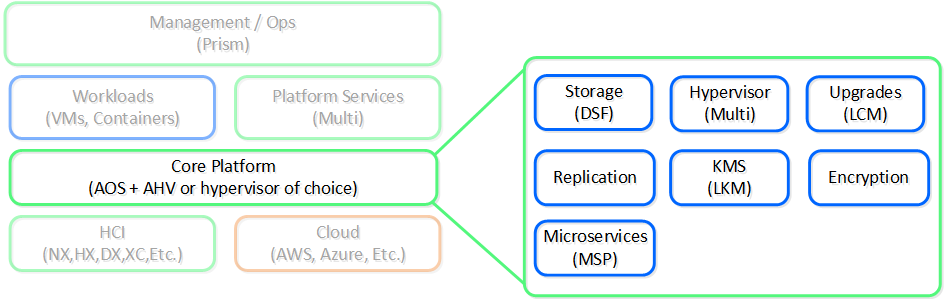 뉴타닉스 플랫폼 - AOS 코어 (Nutanix Platform - AOS Core)
뉴타닉스 플랫폼 - AOS 코어 (Nutanix Platform - AOS Core)
수년에 걸쳐 이것은 자체 하이퍼바이저(AHV)를 도입하고, 업그레이드를 단순화하고, 보안 및 암호화와 같은 다른 필수 서비스의 제공함으로써 가상화의 추상화(이것은 시스템의 일부이고 투명해야 함)로 확장되었다.
이러한 기능으로 우리는 많은 인프라 수준 문제를 해결했지만 거기서 멈추지 않았다. 사람들은 여전히 파일 공유, 오브젝트 스토리지 또는 컨테이너와 같은 추가 서비스가 필요했다.
고객에게 일부 서비스에 대해 다른 벤더 및 제품을 사용하도록 요구하기보다 뉴타닉스는 파트너가 해야 하는 것과 뉴타닉스가 구축해야 하는 것을 파악했다. 백업을 위해서는 Veeam 및 HYCU와 같은 벤더와 파트너 관계를 맺고, 파일 및 오브젝트 서비스 등과 같은 서비스는 뉴타닉스 플랫폼에 서비스로 구축했다.
다음은 뉴타닉스 플랫폼 서비스에 대한 하이-레벨 뷰를 보여준다.
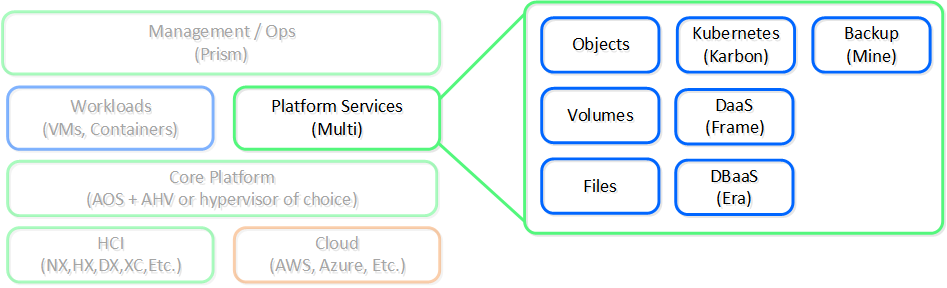 뉴타닉스 플랫폼 - 서비스 (Nutanix Platform - Services)
뉴타닉스 플랫폼 - 서비스 (Nutanix Platform - Services)
프리즘: “인터페이스”
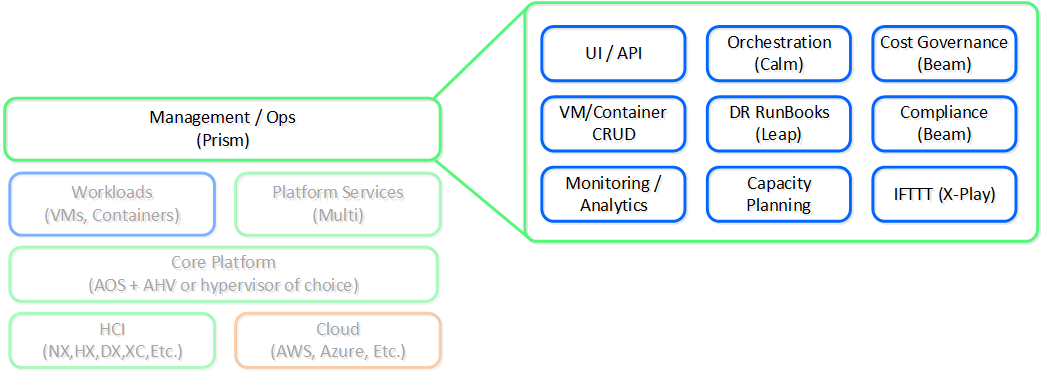 뉴타닉스 플랫폼 - 프리즘 (Nutanix Platform - Prism)
뉴타닉스 플랫폼 - 프리즘 (Nutanix Platform - Prism)
간단히 말해, 간단함, 일관성 및 직관성에 중점을 둔 Apple과 같은 회사에서 개발한 일부 디자인 원칙을 적용한다. 처음부터 우리는 뉴타닉스 제품의 "프런트 엔드"에 상당한 시간과 노력을 투자했다. UI/UX 및 디자인 팀은 항상 선두에 있었다. 예를 들어, 뉴타닉스는 관리 UI를 HTML5로 작성한 최초의 엔터프라이즈 소프트웨어 회사 (SaaS 플레이어 제외) 중 하나였다.
여기서 또 다른 핵심 항목은 플랫폼에 단일 인터페이스를 제공하고 그 경험을 일관되게 유지하는 데 중점을 두는 것이다. 우리의 목표는 인프라를 컨버지드 한 것처럼 UI를 컨버지드 하는 것이다. 우리는 프리즘이 데이터센터에서 가상화 관리, 클라우드에서 DaaS 서비스 관리, 또는 비용 가시성 제공 등의 여부에 관계없이 뉴타닉스 플랫폼을 관리하고 소비할 수 있는 단일 인터페이스가 되기를 원한다.
이는 뉴타닉스가 기능/서비스 생성 및 획득을 통해 플랫폼을 계속 확장할 것이기 때문에 매우 중요하다. 새로운 기능을 강화하는 대신 플랫폼에 기본적으로 통합하는 데 시간을 투자하고 있다. 이를 위한 프로세스는 매우 느린 속도로 진행되지만 장기적으로는 일관된 경험을 유지하고 위험을 줄여준다.
뉴타닉스: 플랫폼
요약하면 뉴타닉스의 비전은 간단하다다: "하나의 플랫폼, 모든 앱, 모든 로케이션". 본 이미지를 제공해 주신 마케팅 팀에 감사드린다. 이것은 완벽하게 맞고 뉴타닉스의 목적을 간결하게 표현한다.
뉴타닉스 플랫폼 - 아키텍처 (Nutanix Platform - Architecture)
이것은 처음부터 끝까지 우리의 목표였다. 이에 대한 증거로, 아래는 뉴타닉스 플랫폼 아키텍처에 대해 설명하기 위해 2014년경에 생성된 이미지이다. 크게 변하지 않은 것을 알 수 있듯이 뉴타닉스는 계속 확장하고 이 목표를 향해 노력하고 있다.
 뉴타닉스 플랫폼 - Circa 2014 (Nutanix Platform - Circa 2014)
뉴타닉스 플랫폼 - Circa 2014 (Nutanix Platform - Circa 2014)
제품 및 플랫폼
수년에 걸쳐 뉴타닉스 플랫폼 기능 세트 및 포트폴리오가 크게 성장했다. 수년에 걸쳐 가상화를 단순화 및 추상화하고, 업그레이드 및 운영을 자동화하는 등 다양한 작업을 수행했다. 이 섹션에서는 현재 포트폴리오 및 파트너십을 다룬다. NOTE: 최신 포트폴리오 및 오퍼링에 대해서는 뉴타닉스 웹 페이지를 참조한다.
제품에 대해 이야기하기 보다 수년 동안 제품 포트폴리오가 성장함에 따라 오히려 결과 및 그것을 달성하기 위한 여정에 초점을 맞추고자 한다. 다음 단계에서 고객의 "여정(Journey)"과 뉴타닉스가 고객이 그것을 달성할 수 있도록 도와준 결과에 대해 다룬다.
1단계: 데이터센터 현대화 (Core: 코어)
코어(Core)는 복잡한 3-티어 인프라에서 간단한 HCI 플랫폼으로의 마이그레이션을 용이하게 하는 기본 뉴타닉스 제품을 포함한다. AOS는 모든 핵심 서비스(스토리지, 업그레이드, 복제 등)를 제공하고, 프리즘(Prism)은 컨트롤 플레인 및 관리 콘솔을 제공하며, AHV는 무료 가상화 플랫폼(NOTE: ESXi 및 Hyper-V를 사용할 수 있음)을 제공한다.
코어(Core) 기능은 다음을 포함한다.
- 핵심 플랫폼 (HCI)
- 스토리지 서비스
- 가상화
- 중앙 집중식 관리 및 운영
- 업그레이드
- 복제 / DR
 제품 에코시스템 - 코어 (Products Ecosystem - Core)
제품 에코시스템 - 코어 (Products Ecosystem - Core)
2단계: 프라이빗 클라우드 지원 (Essentials: 에센셜)
에센셜(Essentials)은 핵심 인프라를 프라이빗 클라우드처럼 사용할 수 있는 기능을 제공하는 데 중점을 둔다. Flow는 네트워크 세그멘테이션 및 보안 기능을 제공하고, Files는 파일 서비스를 제공하며, Calm은 셀프서비스, 쿼터 및 오케스트레이션 기능을 제공한다.
에센셜(Essentials) 기능은 다음을 포함한다.
- 고급 분석 및 이상 징후 탐지
- 자동화 및 오케스트레이션
- 셀프서비스 포탈 및 쿼터
- 마이크로세그멘테이션
- 파일 서비스
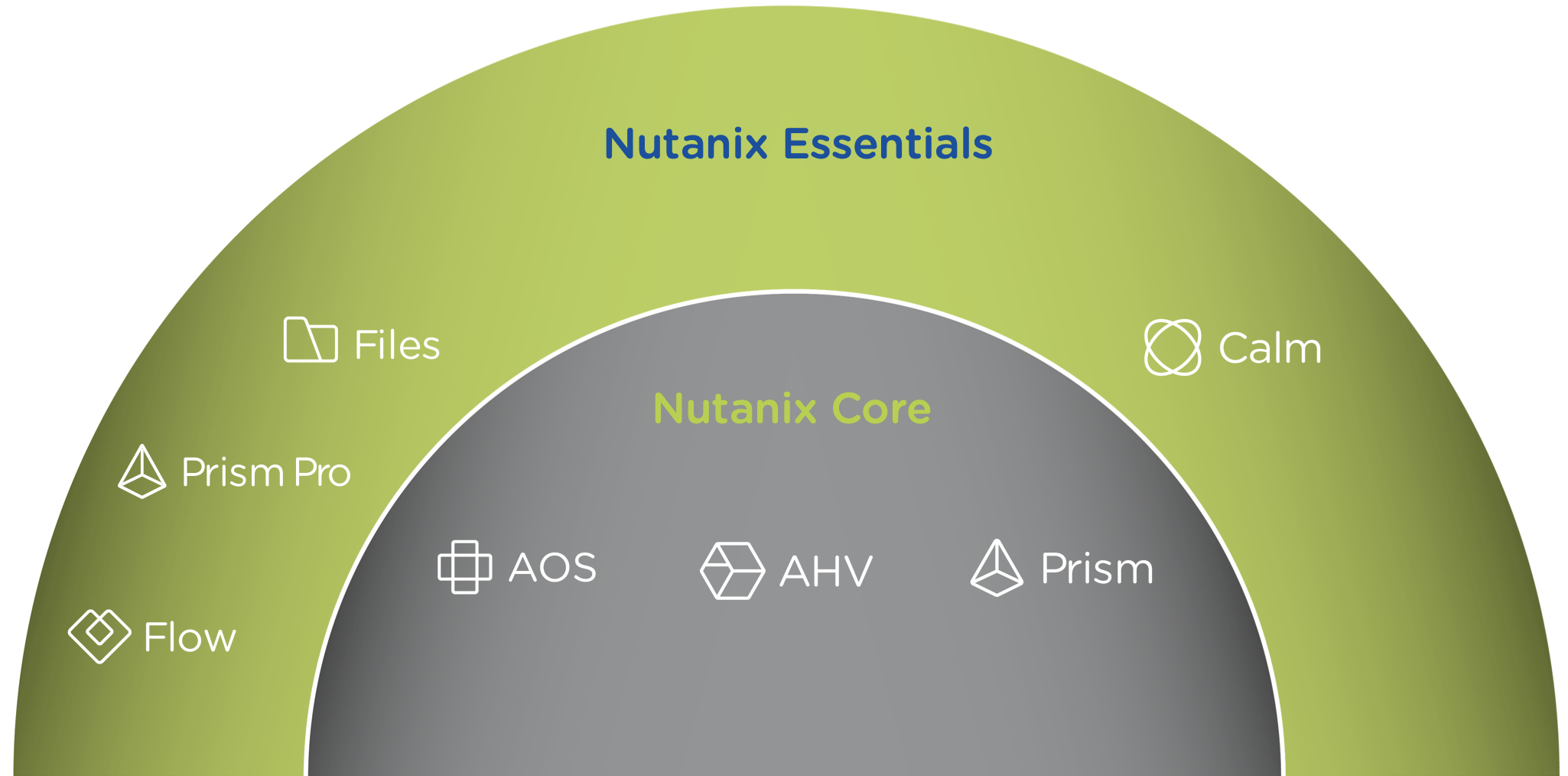 제품 에코시스템 - 프라이빗 클라우드 (Products Ecosystem - Private Cloud)
제품 에코시스템 - 프라이빗 클라우드 (Products Ecosystem - Private Cloud)
3단계: 하이브리드 클라우드 지원 (Enterprise: 엔터프라이즈)
엔터프라이즈(Enterprise)는 클라우드와 클라우드 서비스 간의 워크로드 마이그레이션 기능을 제공하는 데 중점을 둔다. 여기에는 클라우드와 온-프레미스 배포에서 비용 거버넌스 및 컴플라이언스 기능을 제공하는 Beam 뿐만 아니라 Frame(DaaS), Xi Leap(DRaaS) 등과 같은 다른 클라우드 서비스가 포함된다.
엔터프라이즈(Enterprise) 기능은 다음을 포함한다.
- 정책 기반 DR / 런북 자동화
- DRaaS
- 하이브리드 클라우드 비용 거버넌스 및 컴플라이언스
- Desktops As-A-Service (DaaS)
- Database As-A-Service (RDS)
- 쿠버네티스 / 도커 서비스
- 오브젝트 스토리지
- 블록 서비스
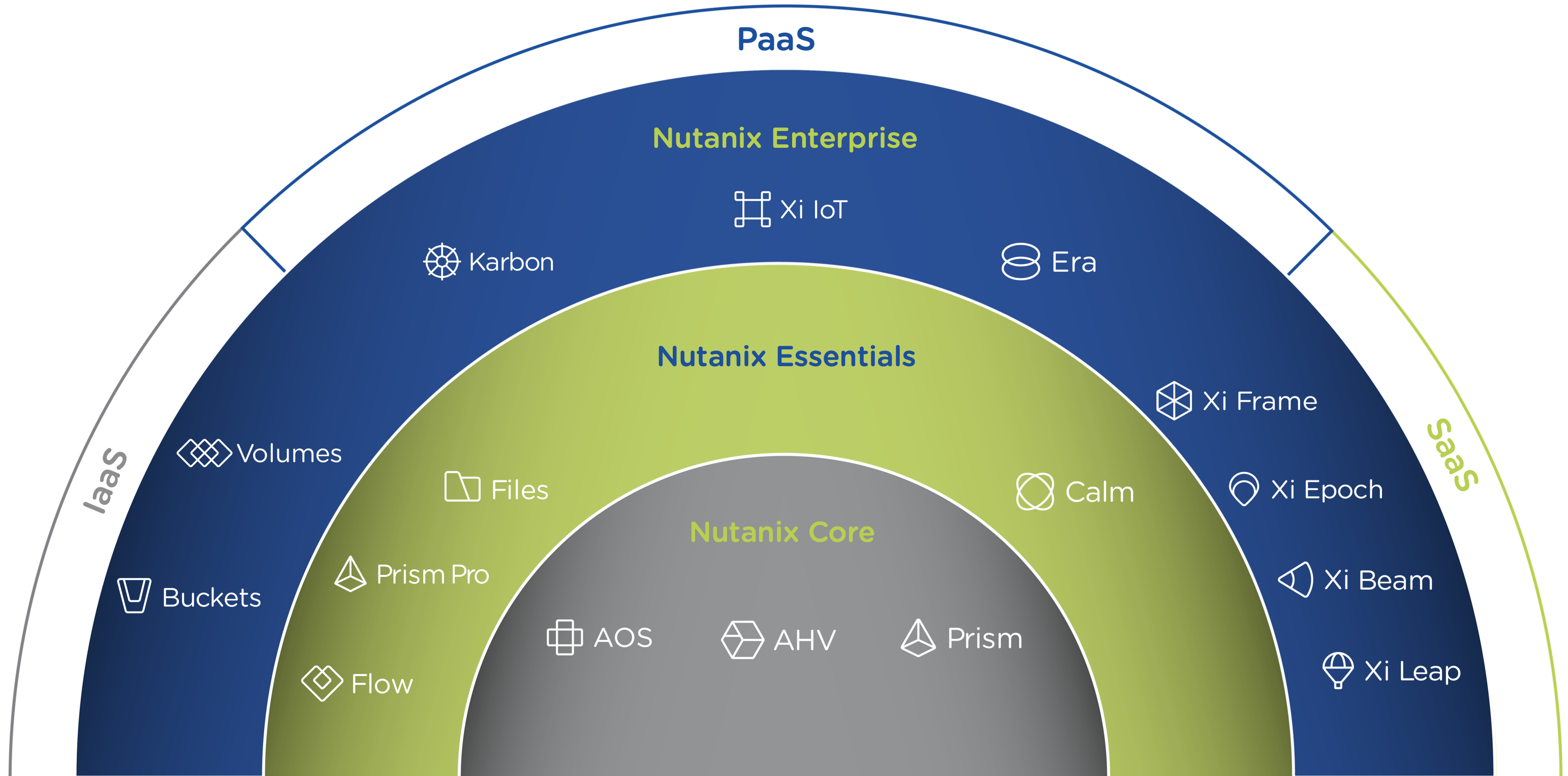 제품 에코시스템 - 하이브리드 클라우드 (Products Ecosystem - Hybrid Cloud)
제품 에코시스템 - 하이브리드 클라우드 (Products Ecosystem - Hybrid Cloud)
플랫폼
뉴타닉스는 현재 다음 플랫폼을 지원한다.
- 뉴타닉스 어플라이언스 (Nutanix Appliance)
- NX (Supermicro)
- OEM 어플라이언스 (OEM Appliance)
- Nutanix on HPE ProLiant DX
- Nutanix on Lenovo HX
- Nutanix on Fujitsu XF
- Nutanix on Dell XC
- Nutanix on Inspur InMerge
- 3rd 파티 서버 지원 (Third-Party Server Support)
- Nutanix on HPE Apollo
- Nutanix on Cisco UCS
- Nutanix on Intel Data Center Blocks
- Nutanix Tactical and Ruggedized platforms on Klas
하이퍼컨버지드 플랫폼
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
하이퍼컨버지드 시스템을 위한 몇 가지 핵심 컨스트럭트가 있다.
- 컴퓨팅 스택(e.g. 컴퓨트 + 스토리지)을 통합하고 단순화해야 한다.
- 시스템의 노드들 간에 데이터와 서비스를 분할(분산) 해야 한다.
- 중앙 집중식 스토리지와 동일한 기능(e.g. HA, 라이브 마이그레이션 등)을 제공해야 한다.
- 데이터를 가능한 한 실행(컴퓨트)과 가깝게 유지해야 한다 (레이턴시의 중요성).
- 하이퍼바이저와 무관해야 한다.
- 하드웨어와 무관해야 한다.
다음 그림은 일반적인 3-티어 스택과 하이퍼컨버지드 스택의 예를 보여준다.
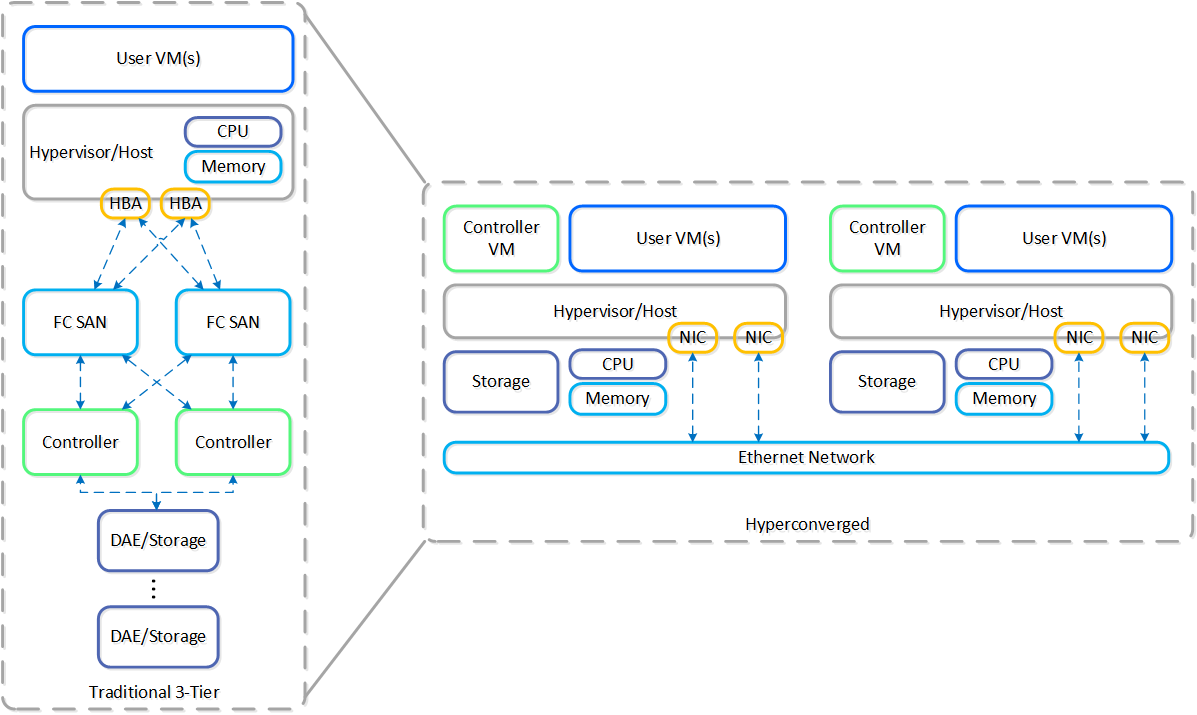 3-티어 vs. HCI (3-Tier vs. HCI)
3-티어 vs. HCI (3-Tier vs. HCI)
보시다시피 하이퍼컨버지드 시스템은 다음을 수행한다.
- 컨트롤러를 가상화하여 호스트로 이동
- 소프트웨어를 통해 핵심 서비스 및 로직 제공
- 시스템의 모든 노드에 데이터 분산(분할)
- 스토리지를 컴퓨트의 로컬로 이동
뉴타닉스 솔루션은 워크로드를 실행하기 위해 로컬 컴포넌트를 활용하여 분산 플랫폼을 생성하는 "컴퓨트 + 스토리지"가 컨버지드 된 솔루션이다.
각 노드는 업계 표준 하이퍼바이저(현재 ESXi, AHV, Hyper-V) 및 뉴타닉스 컨트롤러 VM(Controller VM: CVM)을 실행한다. 뉴타닉스 CVM은 뉴타닉스 소프트웨어를 실행하고 해당 호스트에서 실행 중인 하이퍼바이저 및 모든 VM에게 모든 I/O 오퍼레이션 서비스를 제공한다.
다음 그림은 일반적인 노드가 논리적으로 어떻게 보이는지에 대한 예를 제공한다.
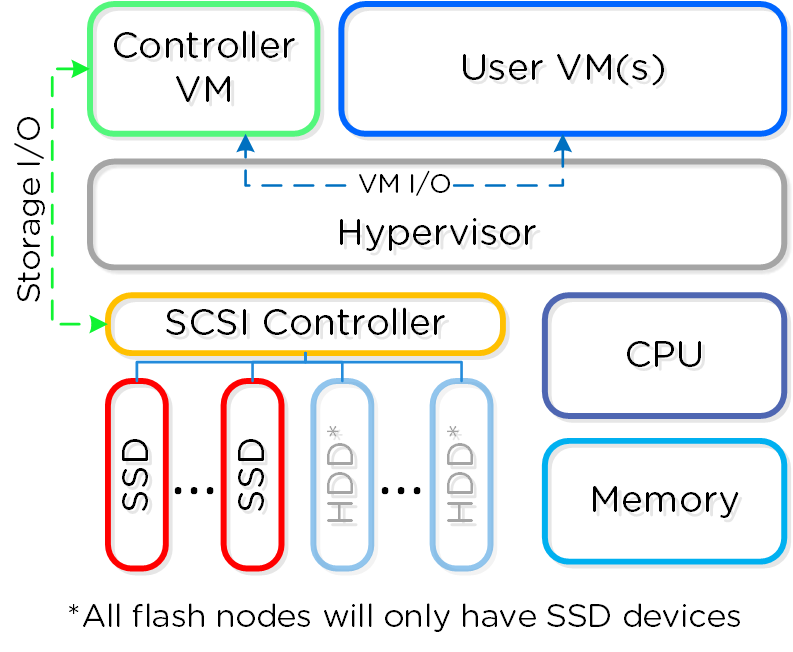 컨버지드 플랫폼 (Converged Platform)
컨버지드 플랫폼 (Converged Platform)
뉴타닉스 CVM은 핵심 뉴타닉스 플랫폼 로직을 담당하며 다음과 같은 서비스를 처리한다.
- 스토리지 I/O 및 변환 (중복제거, 압축, Erasure Coding)
- UI / API
- 업그레이드
- DR / 복제
- 기타
NOTE: 일부 서비스/기능은 추가 헬퍼 VM을 생성하거나 MSP(Microservices Platform)를 사용한다. 예를 들어 뉴타닉스 파일(Files)은 추가 VM을 배포하는 반면 뉴타닉스 오브젝트(Objects)는 MSP 용 VM을 배포하고 이를 활용한다.
VMware vSphere를 실행하는 뉴타닉스 유닛의 경우 SSD 및 HDD 디바이스를 관리하는 SCSI 컨트롤러는 VM-Direct 경로(인텔 VT-d)를 활용하는 CVM으로 직접 전달된다. Hyper-V의 경우 스토리지 디바이스는 CVM으로 전달된다.
Note
컨트롤러 가상화 (Virtualizing the Controller)
유저 스페이스에서 뉴타닉스 컨트롤러를 VM으로 실행하는 주요 이유는 크게 두 가지 핵심 영역으로 나뉜다.
- 모빌리티 (Mobility)
- 리질리언시 (Resiliency)
- 유지보수 / 업그레이드 (Maintenance / Upgrades)
- 성능 (Performance, yes really)
처음부터 우리는 우리가 단일 플랫폼 회사 이상이라는 것을 알고 있었다. 이러한 의미에서 그것이 하드웨어든 클라우드든 하이퍼바이저 벤더든 선택은 우리에게 항상 매우 중요한 일이었다.
유저 스페이스에서 VM으로 실행함으로써 뉴타닉스 소프트웨어를 기반 하이퍼바이저 및 하드웨어 플랫폼과 분리한다. 이를 통해 우리는 모든 운영 환경(온-프레미스 및 클라우드)에서 핵심 코드 베이스를 동일하게 유지하면서 다른 하이퍼바이저에 대한 지원을 신속하게 추가할 수 있었다. 추가적으로 우리에게 벤더 별 릴리스 주기에 구애받지 않는 유연성을 제공했다.
유저 스페이스에서 VM으로 실행되는 특성으로 인해 하이퍼바이저 외부에 있는 업그레이드 또는 CVM 장애와 같은 작업을 정교하게 처리할 수 있다. 예를 들어 CVM이 다운되는 치명적인 문제가 발생하더라도 전체 노드는 클러스터의 다른 CVM에서 오는 스토리지 I/O 및 서비스로 오퍼레이션을 지속한다. AOS (뉴타닉스 핵심 소프트웨어) 업그레이드 중에 해당 호스트에서 실행 중인 워크로드에 영향을 주지 않고 CVM을 재기동할 수 있다.
그러나, 커널에 있는 것이 훨씬 빠르지 않을까요? 간단히 말해서 아닙니다.
일반적인 토론 주제는 커널과 사용자 공간 사이의 논쟁이다. "유저 스페이스 및 커널 스페이스(User vs. Kernel Space)" 섹션을 읽을 것을 권장한다. 해당 섹션에서는 유저 및 커널 스페이스가 실제로 무엇인지, 그리고 각각의 장단점을 설명한다.
요약하자면, 운영체제(OS)에는 커널 스페이스(드라이버가 존재하는 OS 권한이 있는 코어)와 유저 스페이스(애플리케이션/프로세스가 존재하는)의 두 가지 실행 영역이 있다. 일반적으로 유저 스페이스와 커널 스페이스(일명 컨텍스트 전환) 사이를 이동하면 CPU 및 시간(~1,000ns/컨텍스트 전환) 측면에서 비용이 많이들 수 있다.
논쟁은 커널 스페이스에 있는 것이 항상 더 좋고 빠르다는 것이다. 어느 것이 맞을까요? 어쨋든지 간에 게스트 VM의 OS에는 항상 컨텍스트 스위치가 있다는 것이다.
분산 시스템
분산 시스템에는 세 가지 핵심 원칙이 있다.
- SPOF가 없어야 한다.
- 규모에 관계없이 병목현상이 없어야 한다 (선형적인 확장이 가능해야 함).
- 동시 실행 기능을 활용해야 한다 (MapReduce).
뉴타닉스 노드 그룹은 함께 프리즘 및 AOS 기능 제공을 담당하는 분산 시스템(뉴타닉스 클러스터)을 구성한다. 모든 서비스 및 컴포넌트는 고가용성 및 확장 시 선형적인 성능 제공을 위해 클러스터의 모든 CVM에 분산된다.
다음 그림은 이러한 뉴타닉스 노드가 뉴타닉스 클러스터를 구성하는 방법의 예를 보여준다.
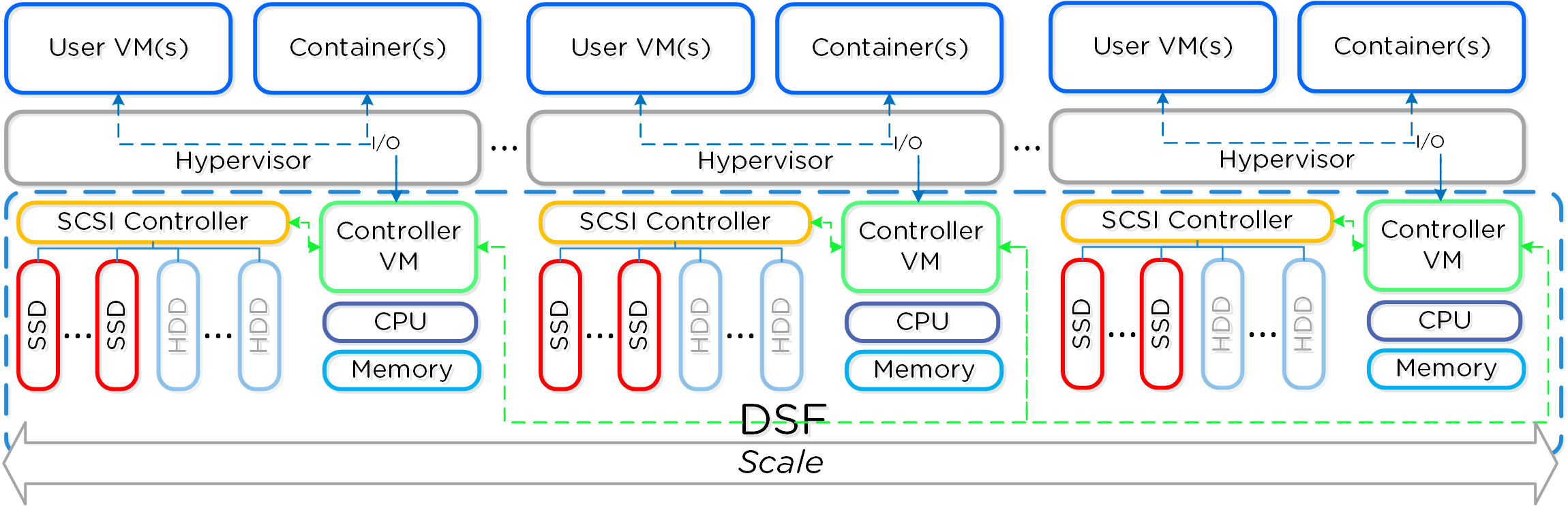 뉴타닉스 클러스터 - 분산 시스템 (Nutanix Cluster - Distributed System)
뉴타닉스 클러스터 - 분산 시스템 (Nutanix Cluster - Distributed System)
이러한 기술은 메타데이터와 데이터에 동일하게 적용된다. 메타데이터와 데이터가 모든 노드와 모든 디스크 디바이스에 분산되도록 함으로써 정상적인 데이터 입력 및 재보호 중에 가능한 최고의 성능을 보장할 수 있다.
이를 통해 맵리듀스 프레임워크(Curator)는 클러스터의 모든 자원을 활용하여 액티비티를 동시에 수행할 수 있다. 샘플 액티비티에는 데이터 재보호, 압축, Erasure Coding, 중복제거 등이 포함된다.
뉴타닉스 클러스터는 장애를 허용하고 수정하도록 설계되었다. 시스템은 오류를 투명하게 처리하고 수정하여 예상대로 동작을 지속한다. 사용자에게 경고가 표시되지만, 시간에 민감한 중요한 항목이 아닌 모든 작업(예: 장애 노드 교체)은 관리자의 스케줄에 따라 수행할 수 있다.
뉴타닉스 클러스터에 자원을 추가해야 하는 경우 새로운 노드를 추가하여 선형으로 클러스터를 확장할 수 있다. 기존의 3-Tier 아키텍처에서는 단순히 서버를 추가한다고 해서 스토리지 성능이 확장되지 않는다. 그러나 뉴타닉스와 같은 하이퍼컨버지드 플랫폼에서는 새로운 노드를 확장할 때 다음과 같은 자원이 동시에 확장된다.
- 하이퍼바이저/컴퓨트 노드의 수
- 스토리지 컨트롤러의 수
- 컴퓨트 및 스토리지 성능/용량
- 클러스터 전체의 오퍼레이션에 참여하는 노드의 수
다음 그림은 클러스터의 확장에 따라 각 노드에서 처리되는 작업 비율(%)을 어떤 방식으로 현저하게 감소되는지를 보여준다.
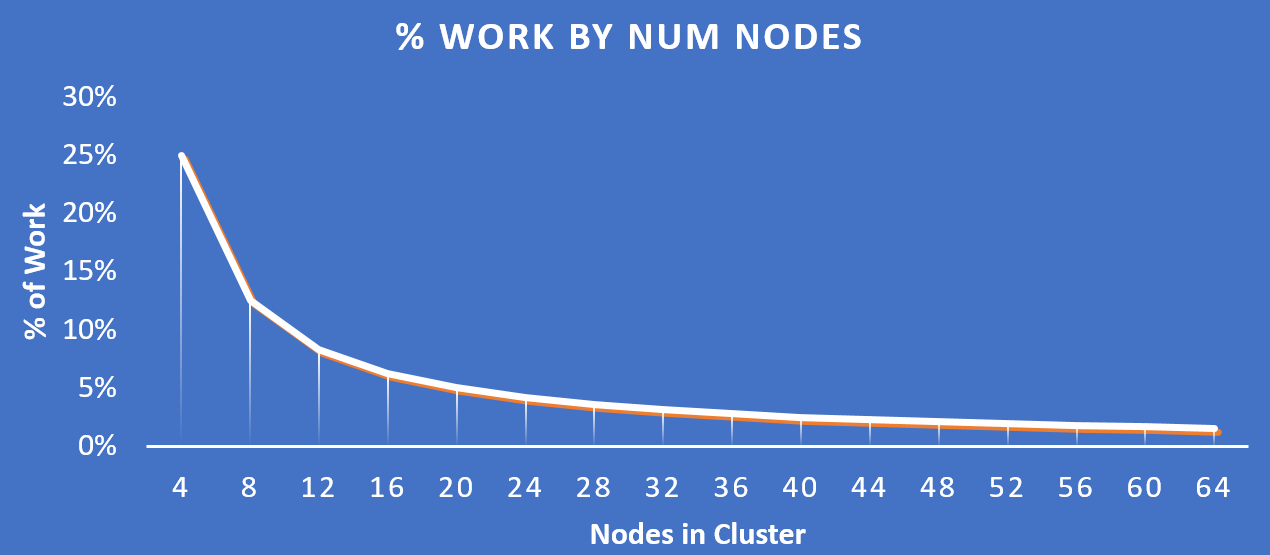 작업 분포 - 클러스터 규모 (Work Distribution - Cluster Scale)
작업 분포 - 클러스터 규모 (Work Distribution - Cluster Scale)
Key Point: 클러스터 내의 노드 수가 증가함에 따라 (클러스터 확장), 각 노드가 작업의 일부만을 처리하기 때문에 실제로 특정 액티비티가 더 효율적으로 된다.
소프트웨어 정의
소프트웨어 정의 시스템에는 세 가지 핵심 원칙이 있다.
- 플랫폼 이동성을 제공하여야 한다 (하드웨어, 하이퍼바이저)
- 맞춤 하드웨어에 의존해서는 안 된다.
- 빠른 개발 속도를 제공해야 한다 (기능, 버그 수정, 보안 패치).
- 무어 법칙의 장점을 활용해야 한다.
위에서 언급한 바와 같이 (아마도 여러 번) 뉴타닉스 플랫폼은 번들 된 소프트웨어 + 하드웨어 어플라이언스로 제공되는 소프트웨어 기반 솔루션이다. 컨트롤러 VM(Controller VM)은 뉴타닉스 소프트웨어 및 로직의 대부분이 있는 곳으로 처음부터 확장 가능하고 플러그인이 가능한 아키텍처로 설계되었다. 소프트웨어로 정의되고 하드웨어 오프로드 또는 구조에 의존하지 않는 주요 이점은 확장성에 있다. 모든 제품 수명주기와 마찬가지로 고급 및 새로운 기능이 항상 도입될 것이다.
맞춤형 ASIC/FPGA 또는 하드웨어 기능에 의존하지 않음으로써 뉴타닉스는 간단한 소프트웨어 업데이트를 통해 이러한 새로운 기능을 개발하고 배포할 수 있다. 즉 현재 버전의 뉴타닉스 소프트웨어를 업그레이드하여 새로운 기능(e.g. 중복제거)을 배포할 수 있다. 또한 레거시 하드웨어 모델에 새로운 세대의 기능을 배포할 수 있다. 예를 들어 이전 세대의 하드웨어 플랫폼(e.g. 2400)에서 구 버전의 뉴타닉스 소프트웨어로 워크로드를 실행하고 있다고 가정한다. 실행 중인 소프트웨어 버전은 워크로드에게 큰 도움이 될 수 있는 중복제거 기능을 제공하지 않는다. 이러한 기능을 사용하려면 워크로드가 실행되는 동안 뉴타닉스 소프트웨어 버전의 롤링 업그레이드를 수행하면 중복제거 기능을 사용할 수 있다. 정말로 그렇게 쉽다.
기능과 마찬가지로 DSF에 새로운 "어댑터" 또는 인터페이스를 만드는 것이 또 다른 핵심 능력이다. 제품이 처음 출시되었을 때 하이퍼바이저 I/O를 위해 단지 iSCSI만을 지원하였지만 이제는 NFS 및 SMB를 포함하도록 확장되었다. 향후에는 다양한 워크로드 및 하이퍼바이저를 (HDFS 등) 위한 새로운 어댑터를 만들 수 있다. 다시 반복하지만 이러한 모든 것은 소프트웨어 업데이트를 통해 배포될 수 있다. 이는 "최신 및 최고" 기능을 적용하기 위해 하드웨어 업그레이드 또는 일반적으로 소프트웨어 구매를 필요로 하는 대부분의 레거시 인프라와 반대되는 특징이다. 뉴타닉스를 사용하면 다르다. 모든 기능이 소프트웨어로 배포되므로 모든 하드웨어 플랫폼, 모든 하이퍼바이저에서 실행할 수 있으며 간단한 소프트웨어 업그레이드를 통해 배포될 수 있다.
디음 그림은 소프트웨어 정의 컨트롤러 프레임워크의 논리적인 표현을 보여준다.
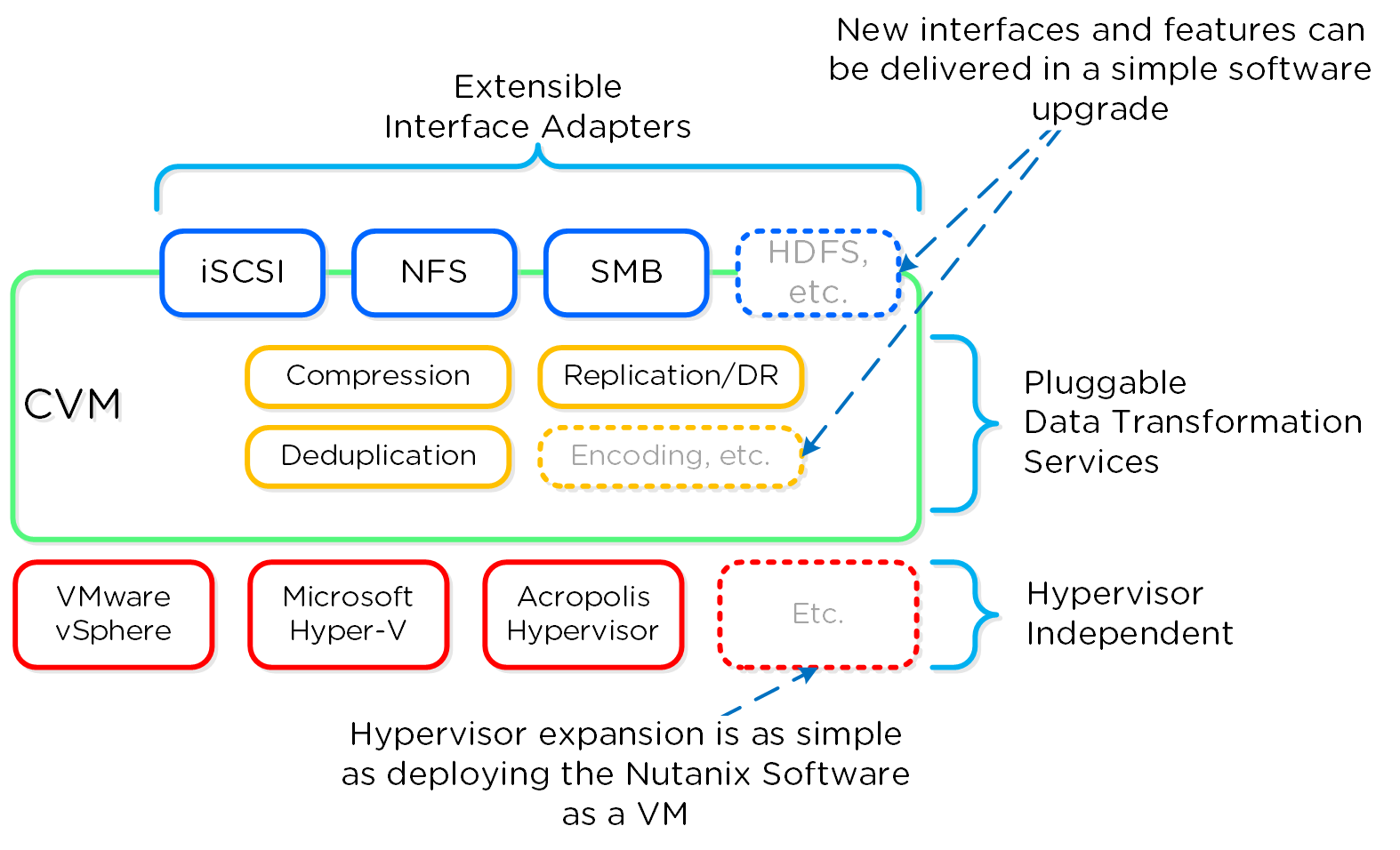 소프트웨어 정의 컨트롤러 프레임워크 (Software-Defined Controller Framework)
소프트웨어 정의 컨트롤러 프레임워크 (Software-Defined Controller Framework)
클러스터 컴포넌트
사용자 중심의 뉴타닉스 제품은 배포 및 운영이 매우 간단하다. 이것은 주로 추상화와 소프트웨어에서 많은 자동화/통합을 통해 가능하다.
다음은 메인 뉴타닉스 클러스터 컴포넌트에 대한 상세한 설명이다 (모든 것을 암기하거나 알 필요가 없으니 걱정하지 마세요).
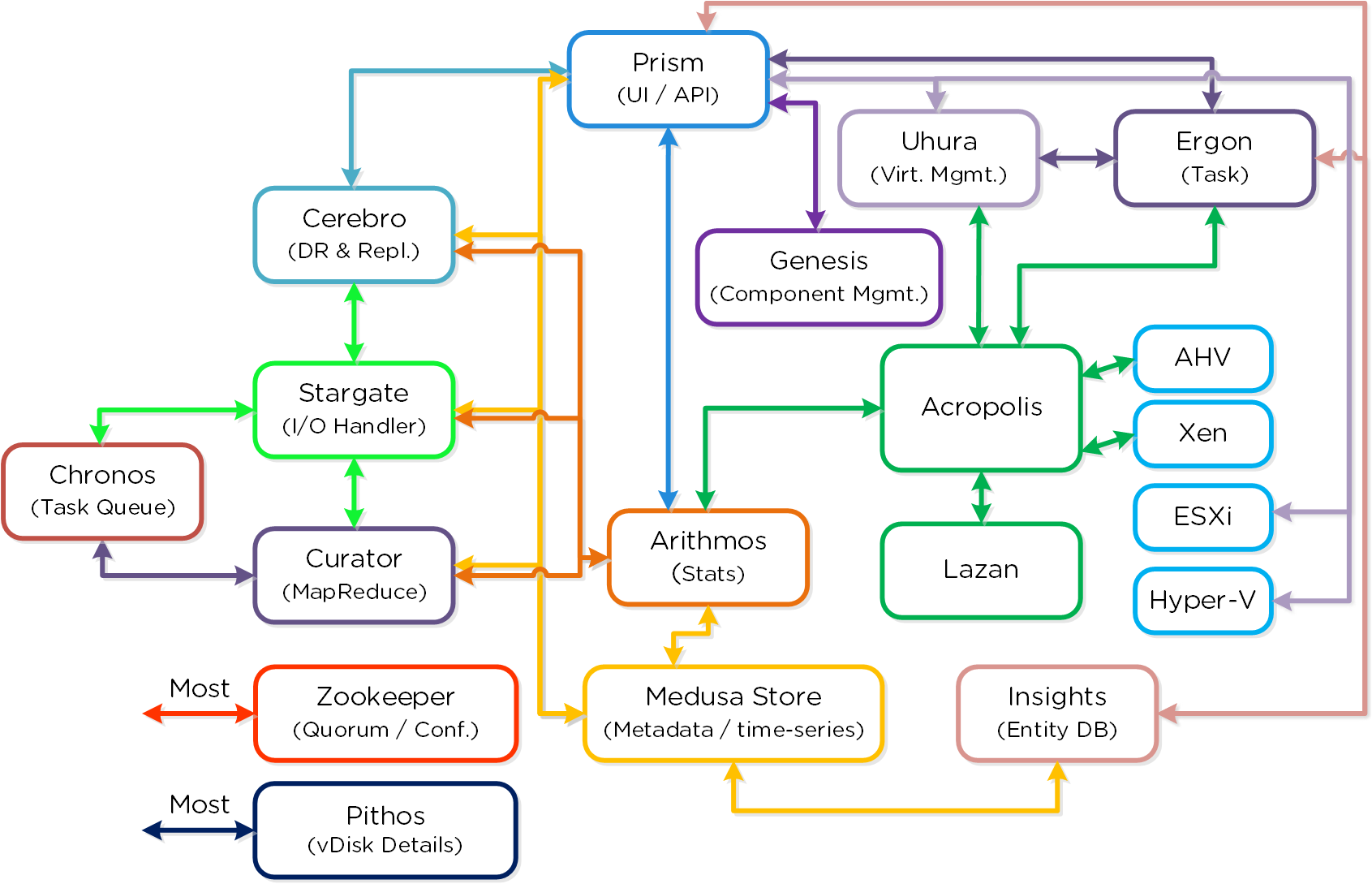 뉴타닉스 클러스터 컴포넌트 (Nutanix Cluster Components)
뉴타닉스 클러스터 컴포넌트 (Nutanix Cluster Components)
카산드라 (Cassandra)
- 주요 역할: 분산 메타데이터 스토어
- 설명: 카산드라는 크게 수정된 Apache Cassandra를 기반으로 모든 클러스터 메타데이터를 분산 링 방식으로 저장하고 관리한다. PAXOS 알고리즘이 “엄격한 일관성(Strict Consistency)”을 유지하기 위해 사용된다. 이 서비스는 클러스터의 모든 노드에서 실행된다. 카산드라는 메두사(Medusa)로 불리는 인터페이스를 통해 액세스 된다.
주키퍼 (Zookeeper)
- 주요 역할: 클러스터 설정 매니저
- 설명: 주키퍼는 호스트, IP 주소, 상태 등을 포함한 모든 클러스터 설정 정보를 저장하며 Apache Zookeeper를 기반으로 한다. 이 서비스는 클러스터의 세 노드에서 실행되며 그중 하나가 리더로 선출된다. 리더는 모든 요청을 받아 동료들에게 전달한다. 만약 리더가 응답하지 않으면 새로운 리더가 자동으로 선출된다. 주키퍼는 제우스(Zeus)로 불리는 인터페이스를 통해 액세스 된다.
스타게이트 (Stargate)
- 주요 역할: 데이터 I/O 매니저
- 설명: 스타게이트는 모든 데이터 관리 및 I/O 오퍼레이션을 담당하며 하이퍼바이저(NFS, iSCSI, 또는 SMB를 통해)의 메인 인터페이스이다. 이 서비스는 로컬 I/O를 지원하기 위해 클러스터의 모든 노드에서 실행된다.
큐레이터 (Curator)
- 주요 역할: 맵 리듀스 클러스터 관리 및 정리
- 설명: 큐레이터는 클러스터 전체에서 작업을 관리하고 분산하는 역할을 담당하며 디스크 밸런싱, 사전 예방적 스크러빙 등과 같은 많은 작업을 수행한다. 큐레이터는 모든 노드에서 실행되며 태스크(Task) 및 잡(Job) 위임을 담당하는 선출된 큐레이터 리더(Leader)에 의해 제어된다. 큐레이터에는 두 가지 스캔 유형이 있는데, 전체 스캔(Full Scan)은 6시간 주기로, 부분 스캔(Partial Scan)은 1시간 주기로 발생한다.
프리즘 (Prism)
- 주요 기능: UI 및 API
- 설명: 프리즘은 컴포넌트 및 관리자가 뉴타닉스 클러스터를 설정하고 모니터링할 수 있는 관리 게이트웨이이다. 여기에는 nCLI, HTML5 UI 및 REST API가 포함된다. 프리즘은 클러스터의 모든 노드에서 실행되며 클러스터의 모든 컴포넌트와 같이 선출된 리더를 사용한다.
제네시스 (Genesis)
- 주요 역할: 클러스터 컴포넌트 및 서비스 매니저
- 설명: 제네시스는 각 노드에서 실행되는 프로세스로 초기 설정뿐만 아니라 모든 서비스 상호작용(시작/중지 등)을 담당한다. 제네시스는 클러스터와 독립적으로 실행되는 프로세스로 클러스터 설정/실행을 요구하지 않는다. 제네시스가 실행되기 위한 유일한 요구 사항은 주키퍼가 기동되어 실행 중이어야 한다는 것이다. cluster_init 및 cluster_status 페이지는 제네시스에 의해 출력된다.
크로노스 (Chronos)
- 주요 역할: 잡 및 태스크 스케줄러
- 설명: 크로노스는 큐레이터 스캔 및 노드 간의 스케줄링/스로틀링의 결과로 발생되는 잡 및 태스크를 인계받는다. 크로노스는 모든 노드에서 실행되며 태스크 및 잡 위임을 담당하고 큐레이터 리더와 동일한 노드에서 실행되는 선출된 크로노스 리더에 의해 제어된다.
세레브로 (Cerebro)
- 주요 역할: 복제/DR 매니저
- 설명: 세레브로는 DSF의 복제 및 DR 기능을 담당한다. 여기에는 스냅샷 스케줄링, 원격 사이트로의 복제, 사이트 마이그레이션/페일오버가 포함된다. 세레브로는 클러스터의 모든 노드에서 실행되며 모든 노드가 원격 클러스터/사이트로의 복제에 참여한다.
피토스 (Pithos)
- 주요 역할: vDisk 설정 매니저
- 설명: 피토스는 vDisk (DSF에서 파일) 설정 데이터를 담당한다. 피토스는 모든 노드에서 실행되며 카산드라를 기반으로 구현되었다.
무중단 업그레이드
Book of Prism의 '뉴타닉스 소프트웨어 업그레이드' 및 '하이퍼바이저 업그레이드' 섹션에서 AOS 및 하이퍼바이저 버전 업그레이드를 수행하는 데 사용되는 단계를 강조하였다. 본 섹션에서는 다양한 유형의 업그레이드를 무중단 방식으로 수행할 수 있는 기술에 대해 다룬다.
AOS 업드레이드
AOS 업그레이드의 경우 수행되는 몇 가지 핵심 단계가 있다.
1 - 업그레이드 사전 검사
업그레이드 사전 검사 중에 다음 항목이 검증된다. NOTE: 업그레이드를 계속하려면 이 작업이 성공적으로 완료되어야 한다.
- AOS, 하이퍼바이저 버전 간의 버전 호환성 확인
- 클러스터 헬스 체크 (클러스터 상태, 여유 공간) 및 컴포넌트 체크 (e.g. 메두사, 스타게이트, 주키퍼 등)
- 모든 CVM과 하이퍼바이저 간의 네트워크 연결 확인
2 - 업그레이드 소프트웨어를 두 노드에 업로드
업그레이드 사전 검사가 완료되면 시스템은 업그레이드 소프트웨어 바이너리를 클러스터의 두 노드에 업로드한다. 이것은 폴트-톨러런스를 위해 수행되는데 하나의 CVM이 재부팅하면 다른 CVM이 다른 소프트웨어를 가져올 수 있도록 한다.
3 - 업그레이드 소프트웨어 단계
소프트웨어가 두 CVM에 업로드되면 모든 CVM은 병렬로 업그레이드를 준비한다.
CVM에는 AOS 버전 용으로 두 개의 파티션이 있다.
- 활성 파티션 (Active Partition) - 현재 실행 중인 버전
- 수동 파티션 (Passive Partition) - 업그레이드가 준비되는 곳
AOS 업그레이드가 발생하면 비횔성 파티션에서 업그레이드를 수행한다. 업그레이드 토큰이 수신되면 업그레이드된 파티션을 액티브 파티션으로 표시하고 CVM을 업그레이드된 버전으로 재부팅한다. 이는 bootbank / altbootbank와 유사하다.
NOTE: 업그레이드 토큰은 노드 간에 반복적으로 전달된다. 이를 통해 한 번에 하나의 CVM만 재부팅한다. CVM이 재부팅되고 안정되면(서비스 상태 및 통신 확인) 모든 CVM이 업그레이드될 때까지 토큰을 다음 CVM으로 전달할 수 있다.
Note
업그레이드 오류 처리 (Upgrade Error Handling)
일반적인 질문은 업그레이드가 성공적이지 않거나 부분적으로 프로세스에 이슈가 있으면 무슨 일이 발생하는가에 대한 것이다.
일부 업그레이드 이슈가 발생할 경우 업그레이드는 중지되고 진행되지 않는다. NOTE: 업그레이드가 실제로 시작되기 전에 업그레이드 사전 검사에서 대부분의 문제를 발견할 수 있기 때문에 이는 매우 드문 경우이다. 그러나 업그레이드 사전 검사가 성공하고 실제 업그레이드 중에 일부 문제가 발생할 경우 클러스터에서 실행 중인 워크로드 및 사용자 I/O에 아무런 영향을 미치지 않는다.
뉴타닉스 소프트웨어는 지원되는 업그레이드 버전 간에 혼합 모드로 무기한 동작하도록 설계되었다. 예를 들어 클러스터가 x.y.foo를 실행 중이고 x.y.bar로 업그레이드하는 경우 시스템은 두 버전 모두에서 CVM을 무기한 실행할 수 있다. 이것은 실제로 업그레이드 프로세스 중에 발생한다.
예를 들어 x.y.foo로 실행 중인 4노드 클러스터를 x.y.bar로 업그레이드를 시작한 경우 첫 번째 노드를 업그레이드하면 첫 번째 노드는 x.y.bar가 실행되고 다른 노드는 x.y.foo가 실행된다. 이 프로세스는 계속 진행되고 CVM은 업그레이드 토큰을 받을 때 x.y.bar로 재부팅된다.
파운데이션 (이미징)
파운데이션 이미징 아키텍처
파운데이션(Foundation)은 뉴타닉스 클러스터의 부트스트래핑, 이미징 및 배포를 위해 활용되는 뉴타닉스 제공 툴이다. 이미징 프로세스는 선택한 하이퍼바이저뿐만 아니라 원하는 버전의 AOS 소프트웨어를 설치한다.
기본적으로 뉴타닉스 노드는 AHV가 사전 설치되어 제공되므로 다른 하이퍼바이저 유형을 활용하려면 파운데이션을 사용하여 노드를 원하는 하이퍼바이저로 재이미징해야 한다. NOTE: 일부 OEM 제품은 원하는 하이퍼바이저로 공장에서 직접 배송된다.
파운데이션 아키텍처의 하이-레벨 뷰는 다음 그림과 같다.
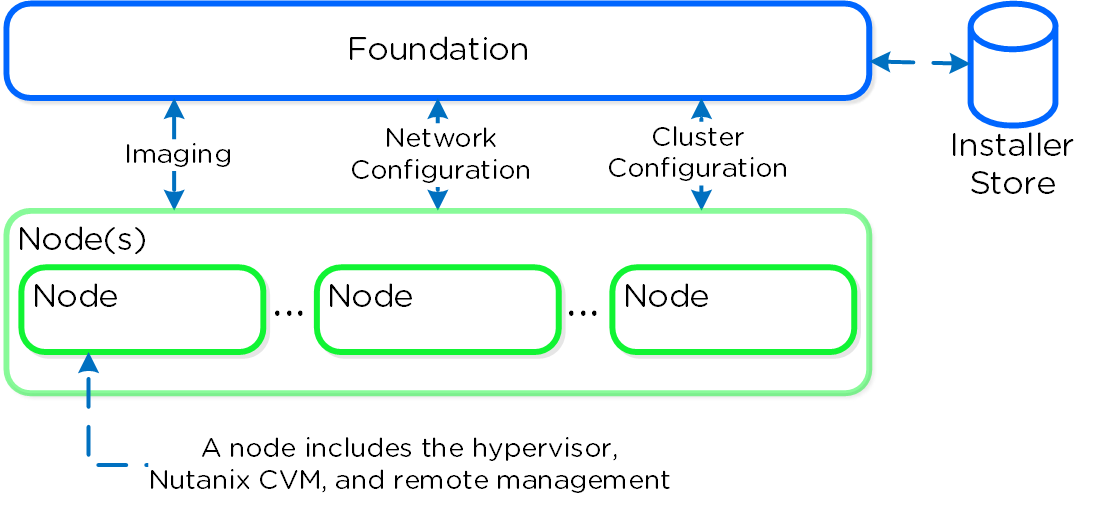 파운데이션 - 아키텍처 (Foundation - Architecture)
파운데이션 - 아키텍처 (Foundation - Architecture)
AOS 4.5 버전부터 파운데이션은 설정을 단순화하기 위해 CVM에 내장되어 있다. 인스톨러 스토어(Installer Store)는 업로드된 이미지를 저장하기 위한 디렉토리로 이미징이 필요할 때 클러스터 확장뿐만 아니라 초기 이미징을 위해 사용된다.
파운데이션 디스커버리 애플릿(여기에서 찾을 수 있음: HERE)은 노드를 검색하고 사용자가 연결할 노드를 선택할 수 있도록 한다. 사용자가 연결할 노드를 선택하면 애플릿은 localhost:9442 IPv4를 CVM의 8000번 포트에서 IPv6 링크 로컬 주소에 프록시한다.
애플릿 아키텍처의 하이-레벨 뷰는 다음 그림과 같다.
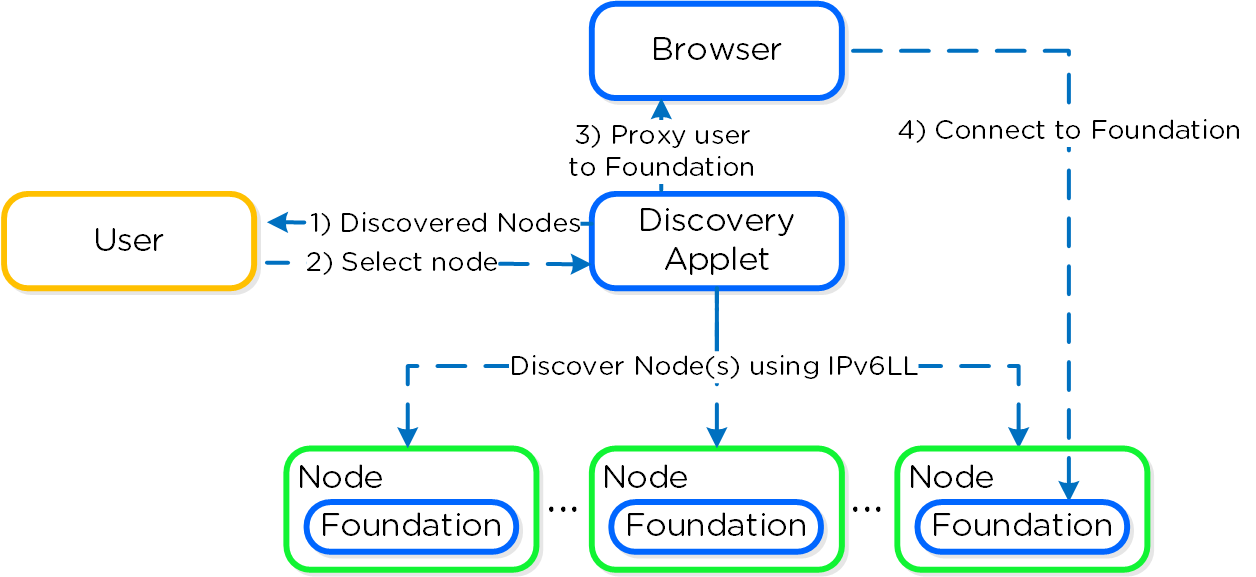 파운데이터션 - 애플릿 아키텍처 (Foundation - Applet Architecture)
파운데이터션 - 애플릿 아키텍처 (Foundation - Applet Architecture)
NOTE: 디스커버리 애플릿(Discovery Applet)은 노드에서 실행되는 파운데이션 서비스의 검색 및 프록시의 수단일 뿐이다. 모든 이미징 및 설정은 애플릿이 아닌 파운데이션 서비스에 의해 처리된다.
Note
Pro tip
타깃 뉴타닉스 노드(e.g. WAN을 통해)와 다른 네트워크를 사용하는 경우(L2) IPv4 주소가 할당된 CVM의 파운데이션 서비스에 직접 연결할 수 있다 (디스커버리 애플릿을 사용하는 대신에).
직접 연결을 위해 <CVM_IP>:8000/gui/index.html을 사용한다.
입력 (Inputs)
파운데이션 툴은 설정을 위해 다음과 같은 입력 값을 가진다 (아래). 일반적인 배포에는 노드 당 3개의 IP 주소가 필요하다 (하이퍼바이저, CVM, 원격 관리(e.g. IPMI, iDRAC 등)). 노드 별 주소 외에 클러스터 가상 IP와 데이터 서비스 IP를 설정하는 것이 좋다.
- 클러스터 (Cluster)
- 이름 (Name)
- IP*
- NTP*
- DNS*
- CVM
- CVM 당 IP (IP per CVM)
- 넷마스크 (Netmask)
- 게이트웨이 (Gateway)
- 메모리 (Memory)
- 하이퍼바이저 (Hypervisor)
- 하이퍼바이저 호스트 당 IP (IP per hypervisor host)
- 넷마스크 (Netmask)
- 게이트웨이 (Gateway)
- DNS*
- 호스트 이름의 접두사 (Hostname prefix)
- IPMI*
- 노드 당 IP (IP per node)
- 넷마스크 (Netmask)
- 게이트웨이 (Gateway)
NOTE: “*”로 표시된 항목은 선택 사항이지만 매우 권장됨
시스템 이미징 및 배포 (System Imaging and Deployment)
첫 번째 단계는 디스커버리 애플릿을 통해 수행할 수 있는 파운데이션 UI에 연결하는 것이다 (동일 L2에 있는 경우 노드 IP는 필요 없음).
 파운데이션 - 디스커버리 애플릿 (Foundation - Discovery Applet)
파운데이션 - 디스커버리 애플릿 (Foundation - Discovery Applet)
원하는 노드를 찾을 수 없는 경우 동일 L2 네트워크에 있는지 확인한다.
선택한 노드의 파운데이션 인스턴스에 연결하면 메인 파운데이션 UI가 나타난다.
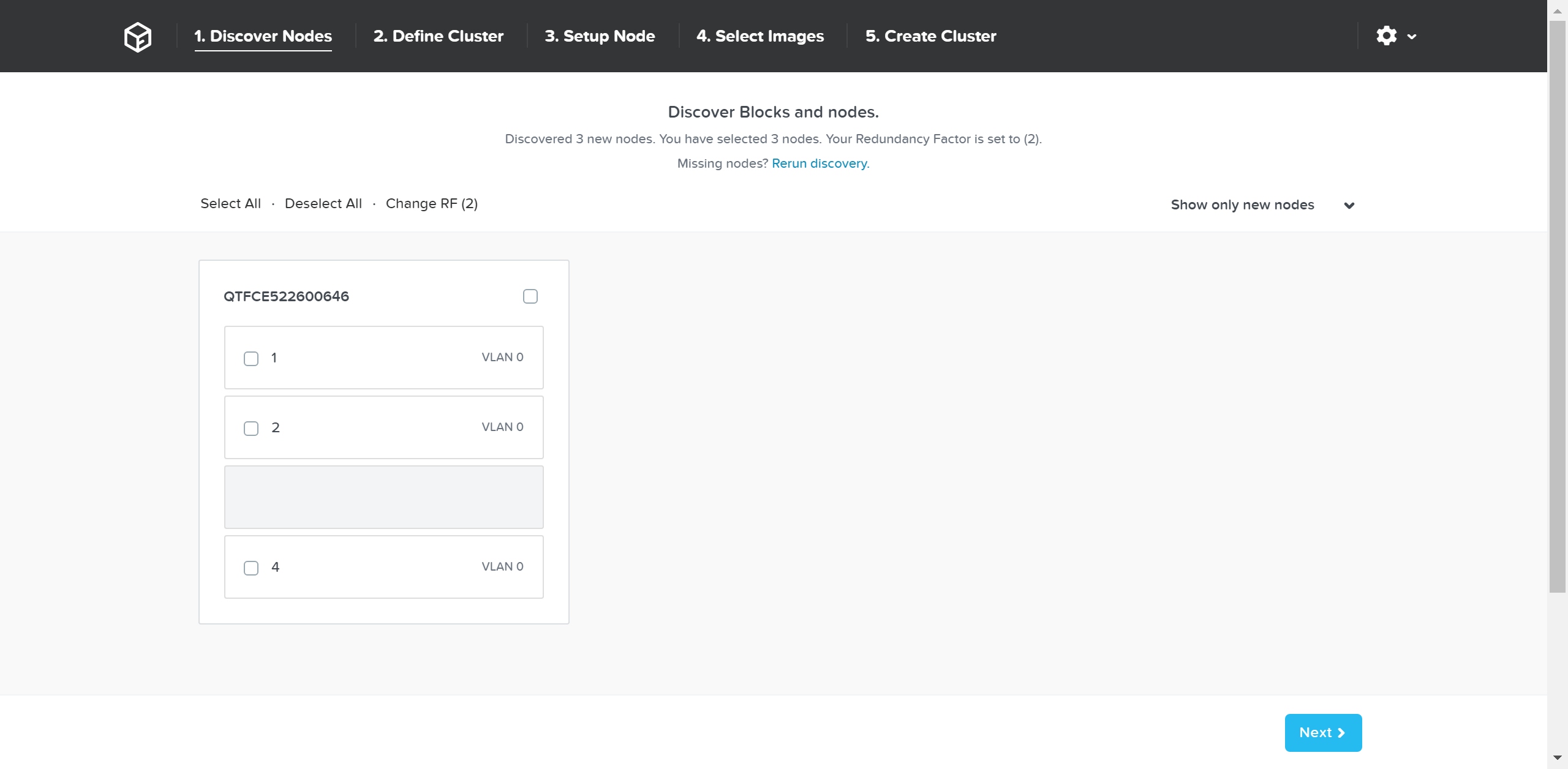 파운데이션 - 디스커버리 페이지 (Foundation - Discovery Page)
파운데이션 - 디스커버리 페이지 (Foundation - Discovery Page)
검색된 모든 노드와 해당 섀시가 표시된다. 클러스터를 구성할 노드를 선택하고 “Next” 버튼을 클릭한다.
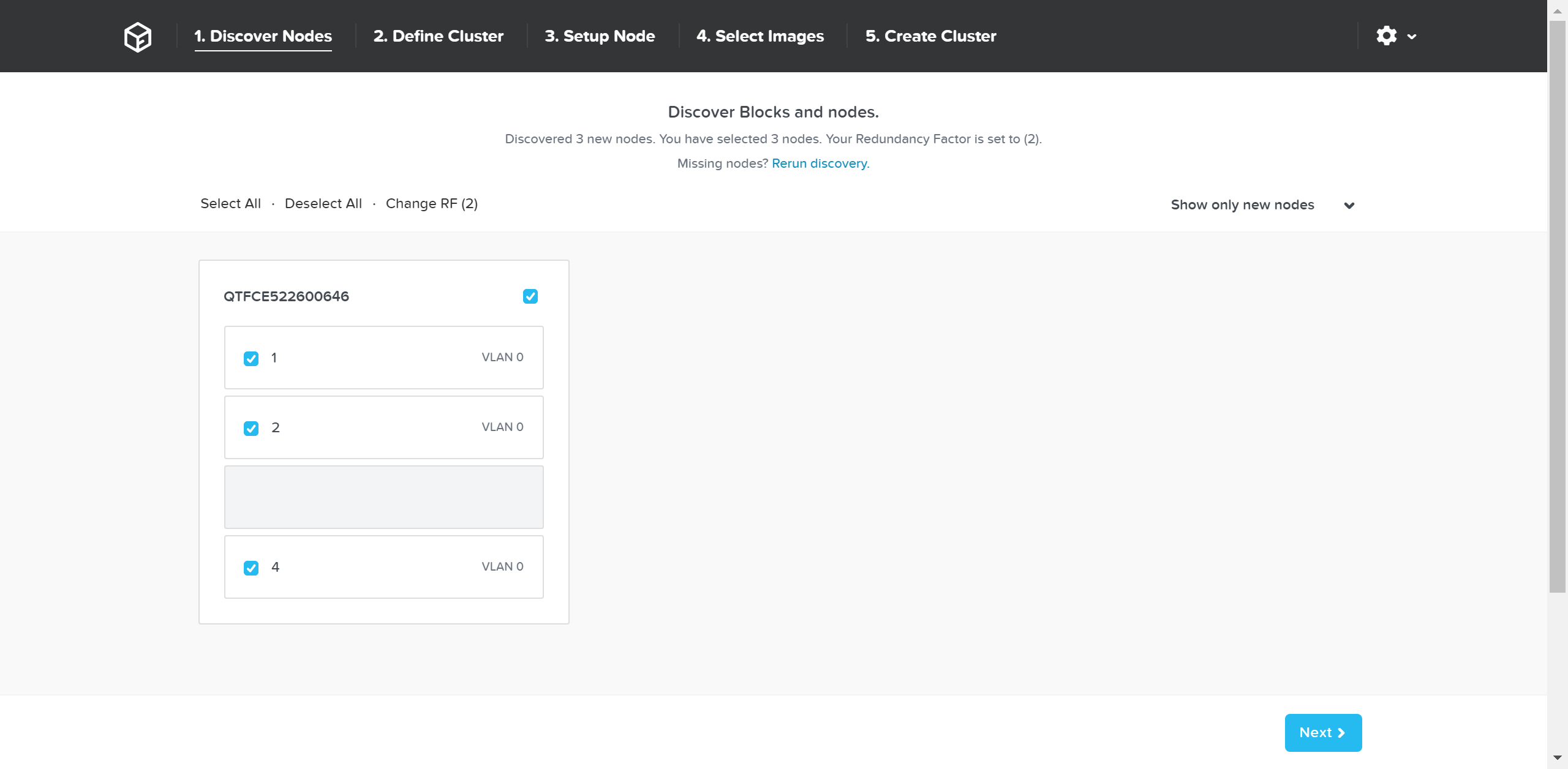 파운데이션 - 노드 선택 (Foundation - Node Selection)
파운데이션 - 노드 선택 (Foundation - Node Selection)
다음 페이지는 클러스터 및 네트워크 입력을 요구한다.
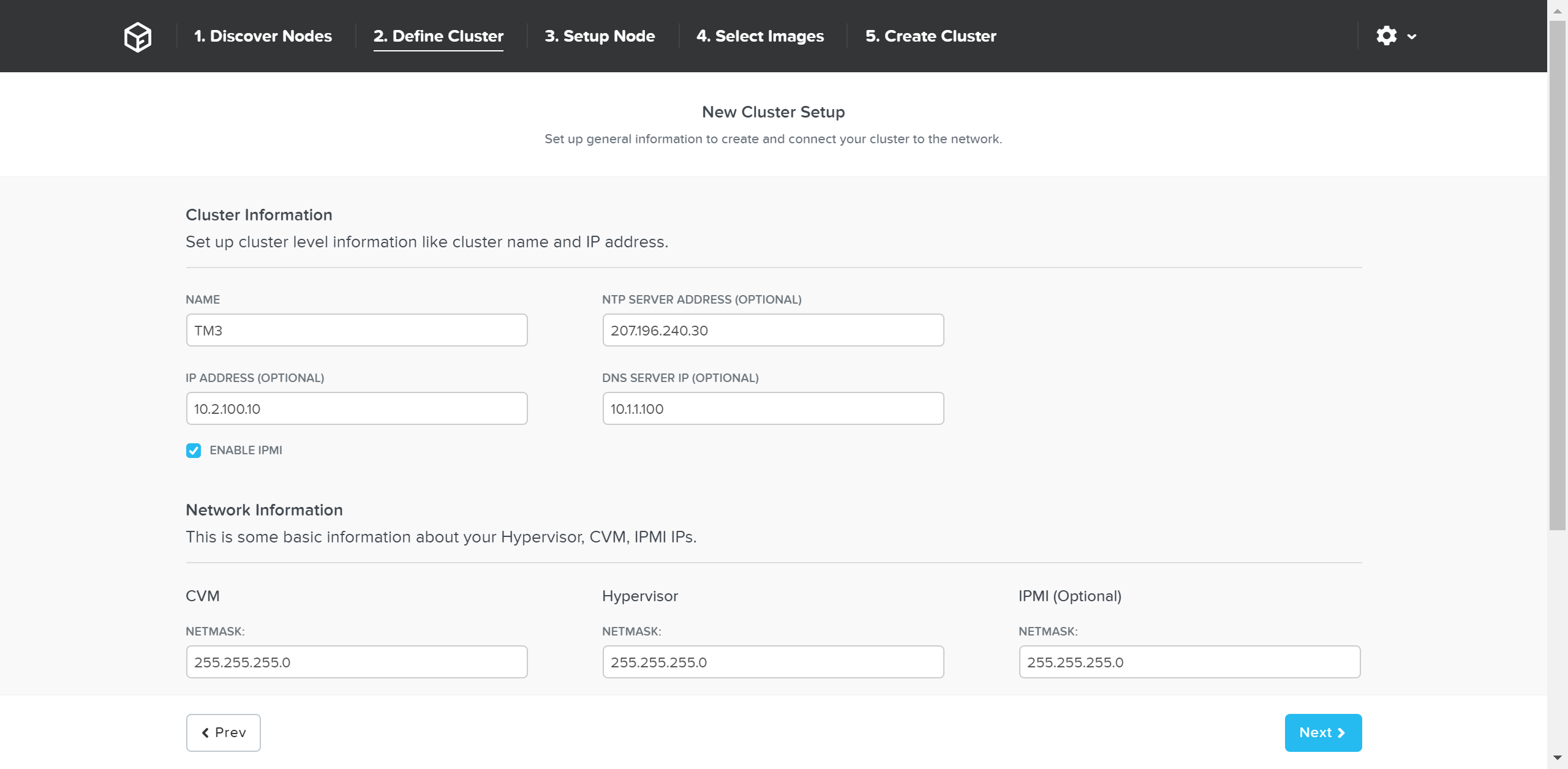 파운데이션 - 클러스터 정보 (Foundation - Cluster Information)
파운데이션 - 클러스터 정보 (Foundation - Cluster Information)
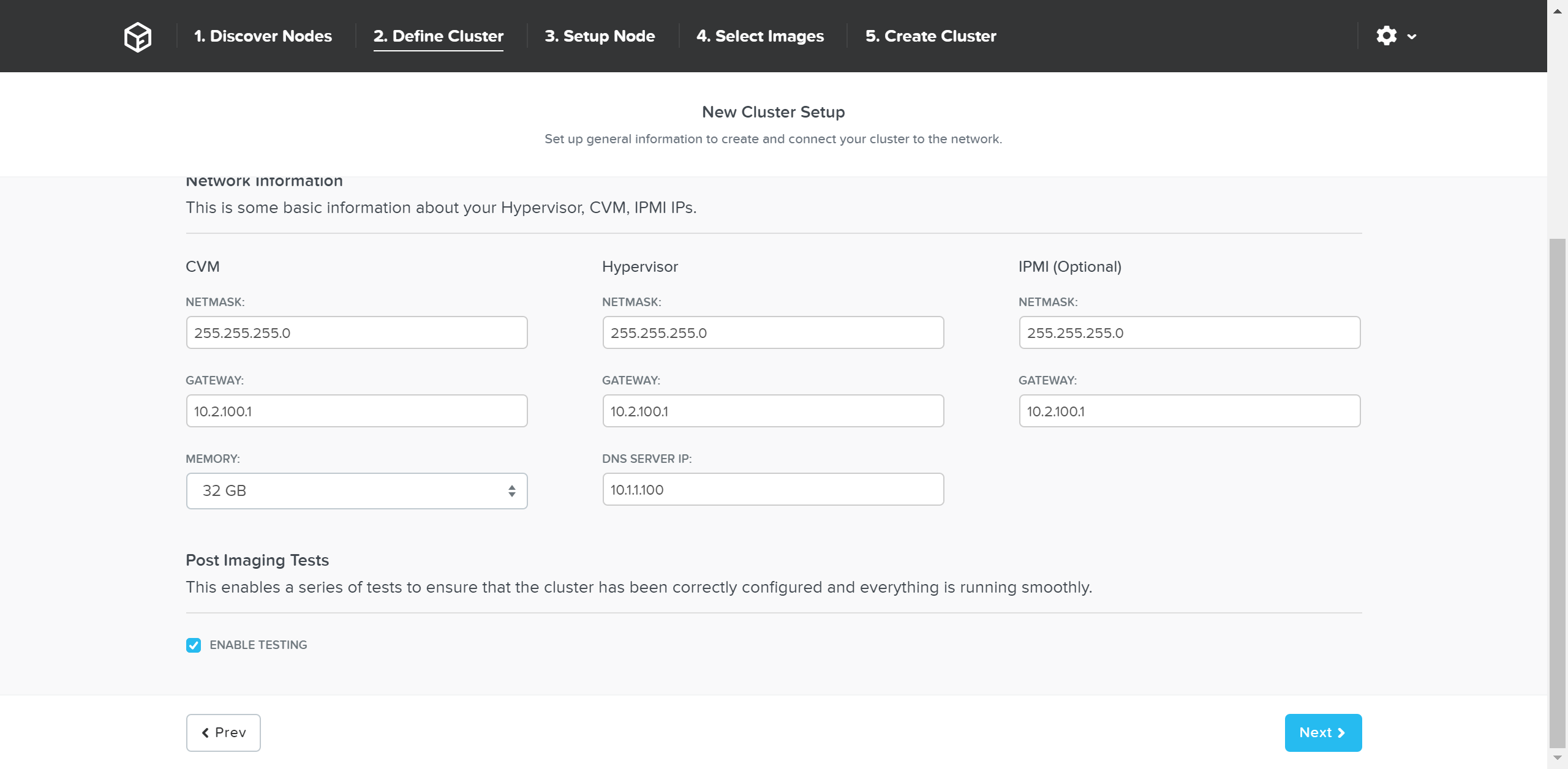 파운데이션 - 네트워크 정보 (Foundation - Network Information)
파운데이션 - 네트워크 정보 (Foundation - Network Information)
세부 정보를 입력한 후에 “Next” 버튼을 클릭한다.
다음으로 노드 세부 정보와 IP 주소를 입력한다.
 파운데이션 - 노드 설정 (Foundation - Node Setup)
파운데이션 - 노드 설정 (Foundation - Node Setup)
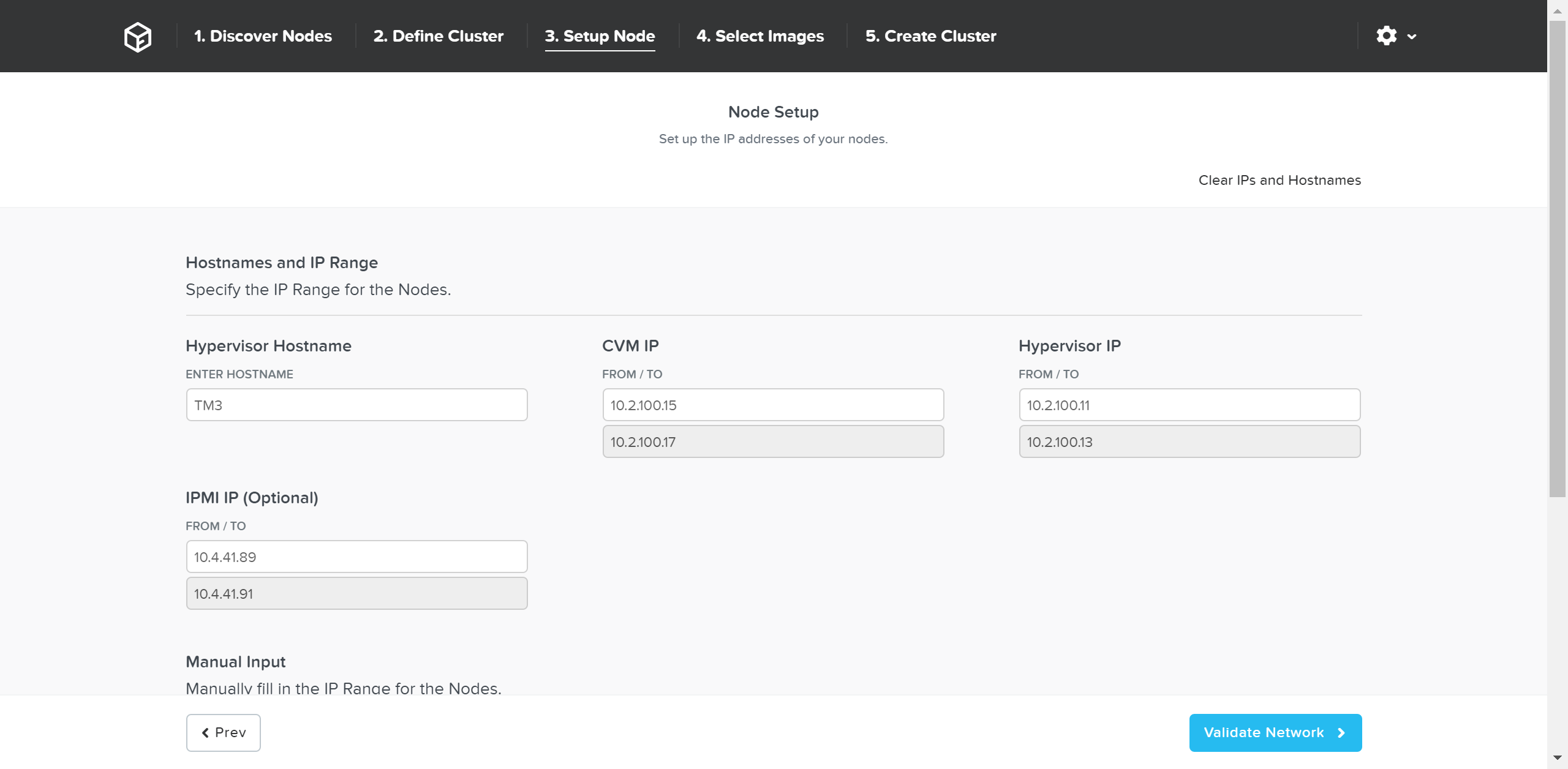
필요한 경우 호스트 이름과 IP 주소를 수동으로 재정의할 수 있다.
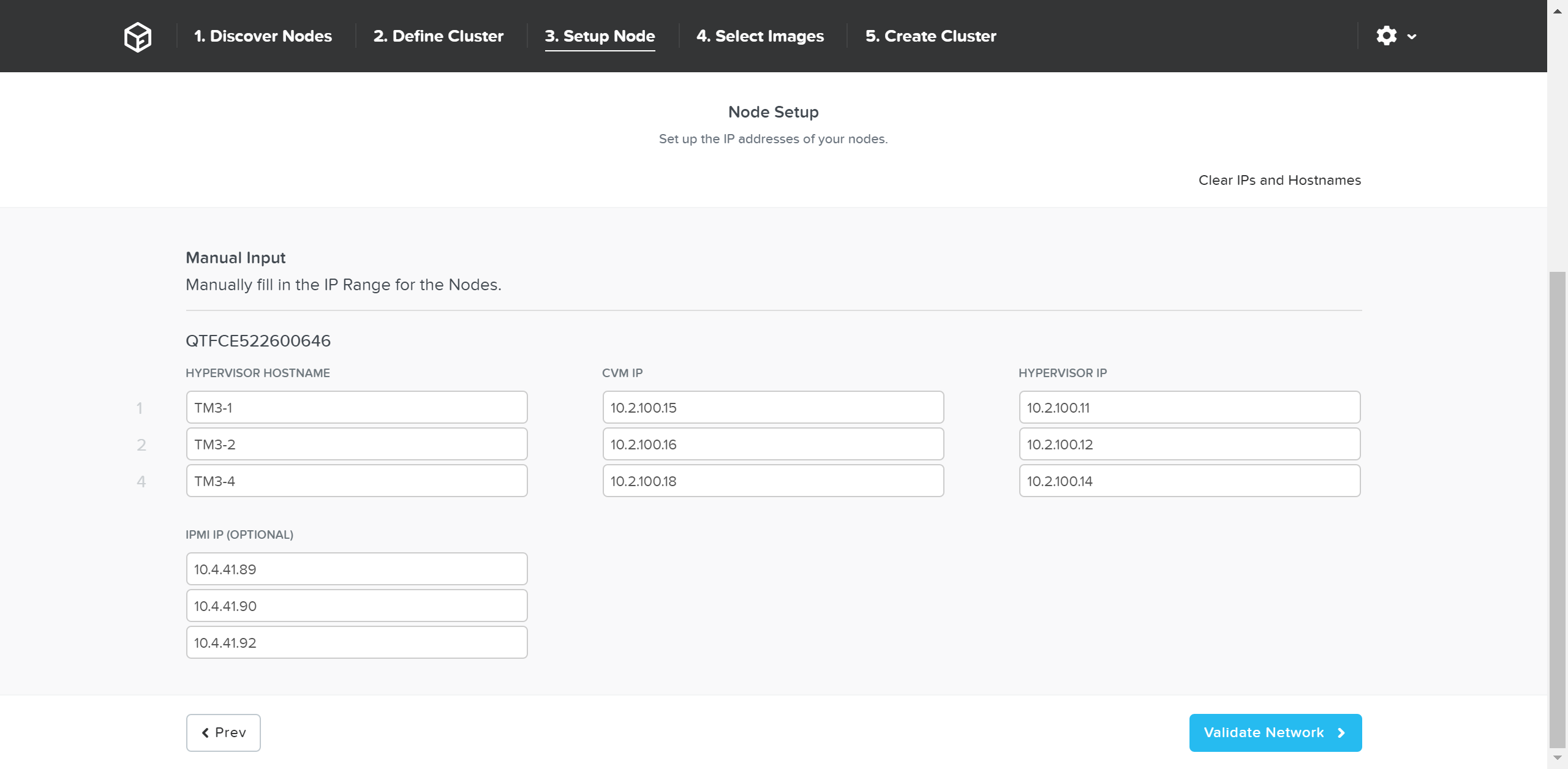 파운데이션 - 호스트 이름 및 IP (Foundation - Hostname and IP)
파운데이션 - 호스트 이름 및 IP (Foundation - Hostname and IP)
네트워크 설정을 검증하고 진행하려면 “Validate Network” 버튼을 클릭한다. 이를 통해 IP 주소 충돌을 체크하고 연결을 보장한다.
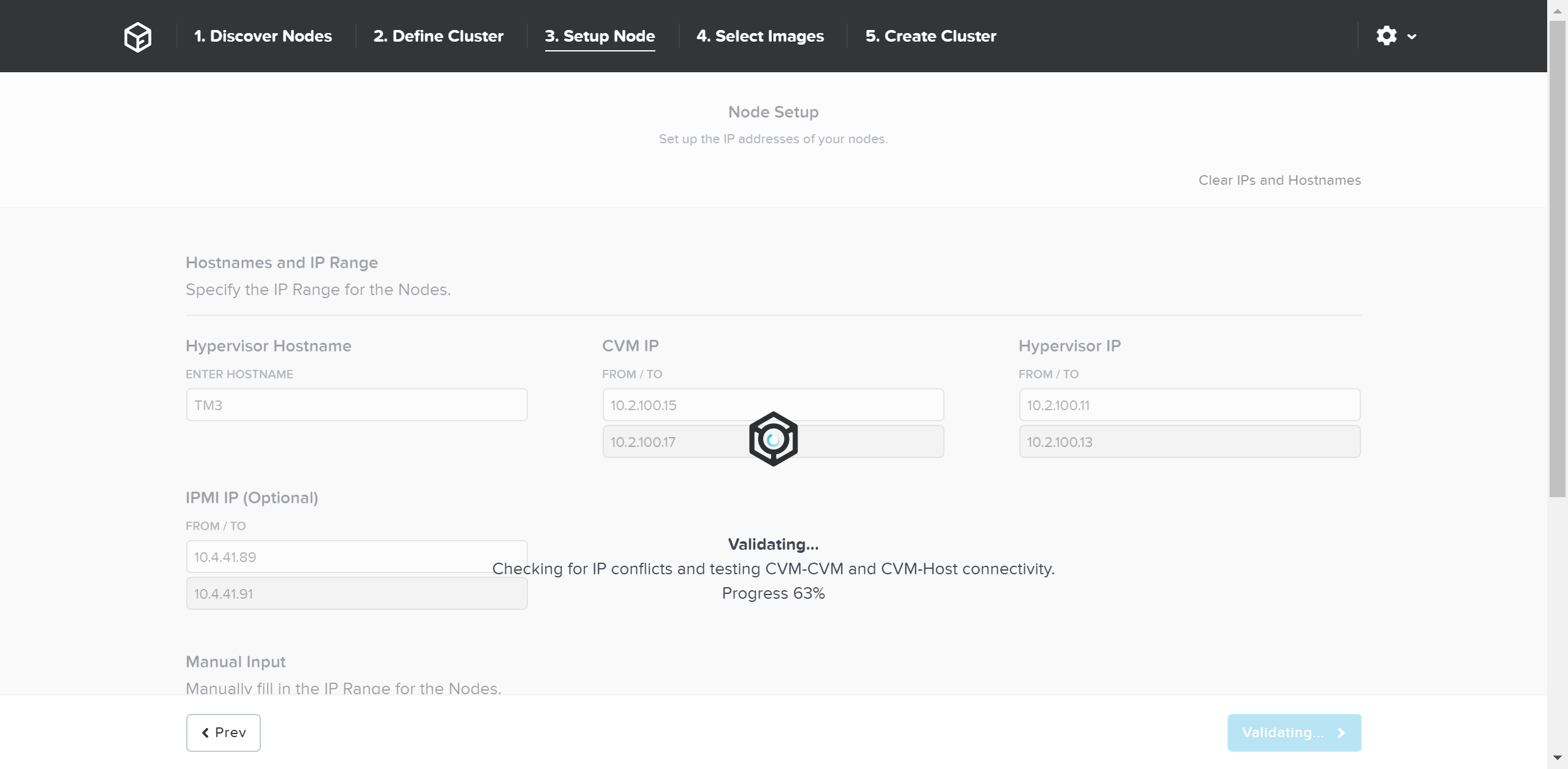 파운데이션 - 네트워크 검증 (Foundation - Network Validation)
파운데이션 - 네트워크 검증 (Foundation - Network Validation)
네트워크 검증이 성공적으로 완료되면 이제 원하는 이미지를 선택한다.
AOS를 현재 CVM에 있는 것보다 최신 버전으로 업그레이드하려면 포털에서 다운로드하고 Tarball을 업로드한다. 원하는 AOS 이미지를 얻은 후에 하이퍼바이저를 선택한다.
AHV의 경우 이미지는 AOS 이미지에 내장되어 있다. 다른 하이퍼바이저인 경우, 원하는 하이퍼바이저 이미지를 업로드해야 한다. NOTE: AOS와 하이퍼바이저 버전이 호환성 매트릭스(LINK)에 있는지 확인한다.
원하는 이미지가 있으면 “Create” 버튼을 클릭한다.
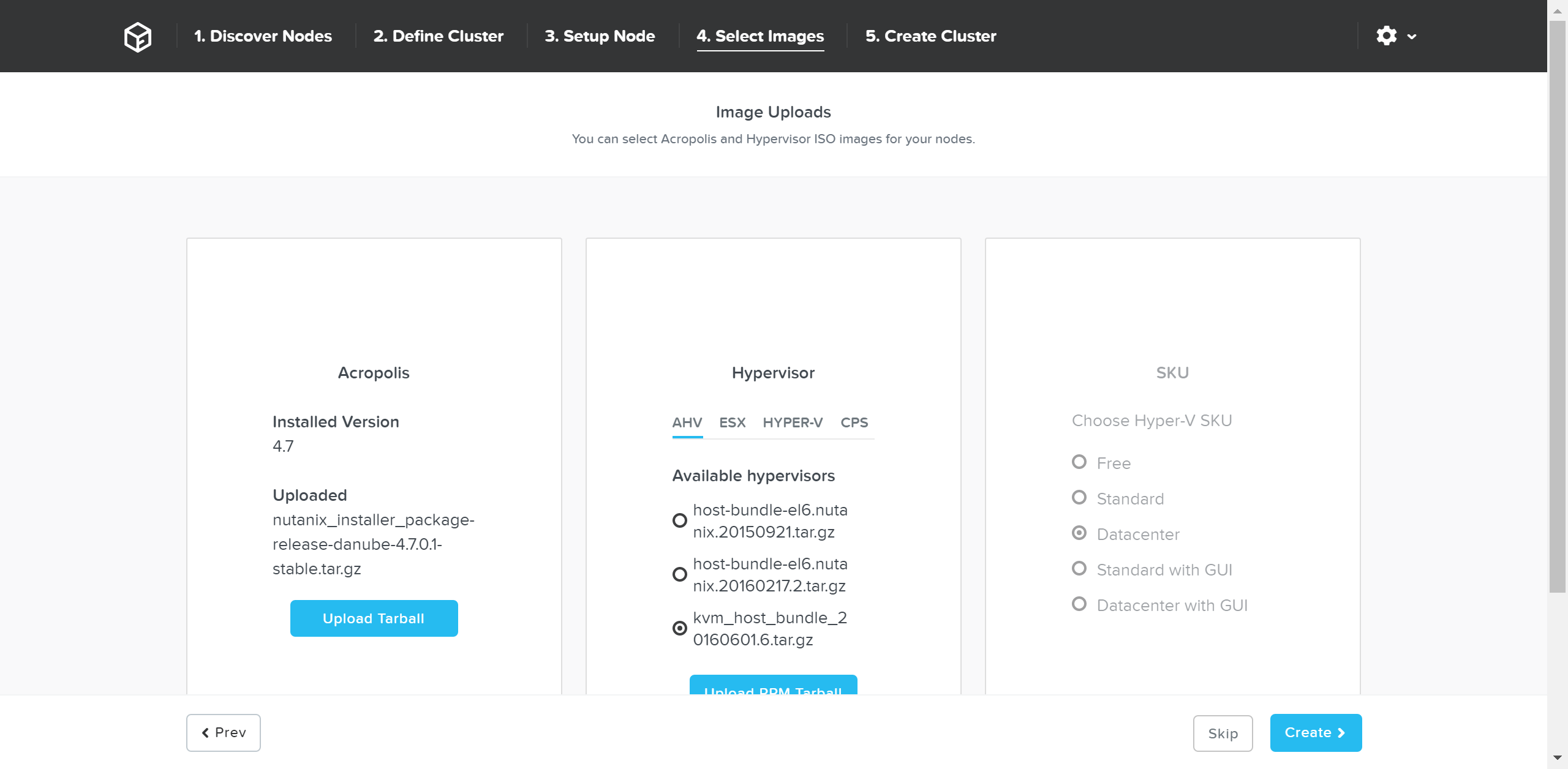 파운데이션 - 이미지 선택 (Foundation - Select Images)
파운데이션 - 이미지 선택 (Foundation - Select Images)
이미징이 필요하지 않은 경우 “Skip”을 클릭하여 이미징 프로세스를 건너뛸 수 있다. 이렇게 하면 하이퍼바이저 및 뉴타닉스 클러스터를 재이미징하지 않고 단지 클러스터만(e.g. IP 주소 등) 설정한다 .
그런 다음 파운데이션은 이미징 (필요한 경우) 및 클러스터 생성 프로세스를 진행한다.
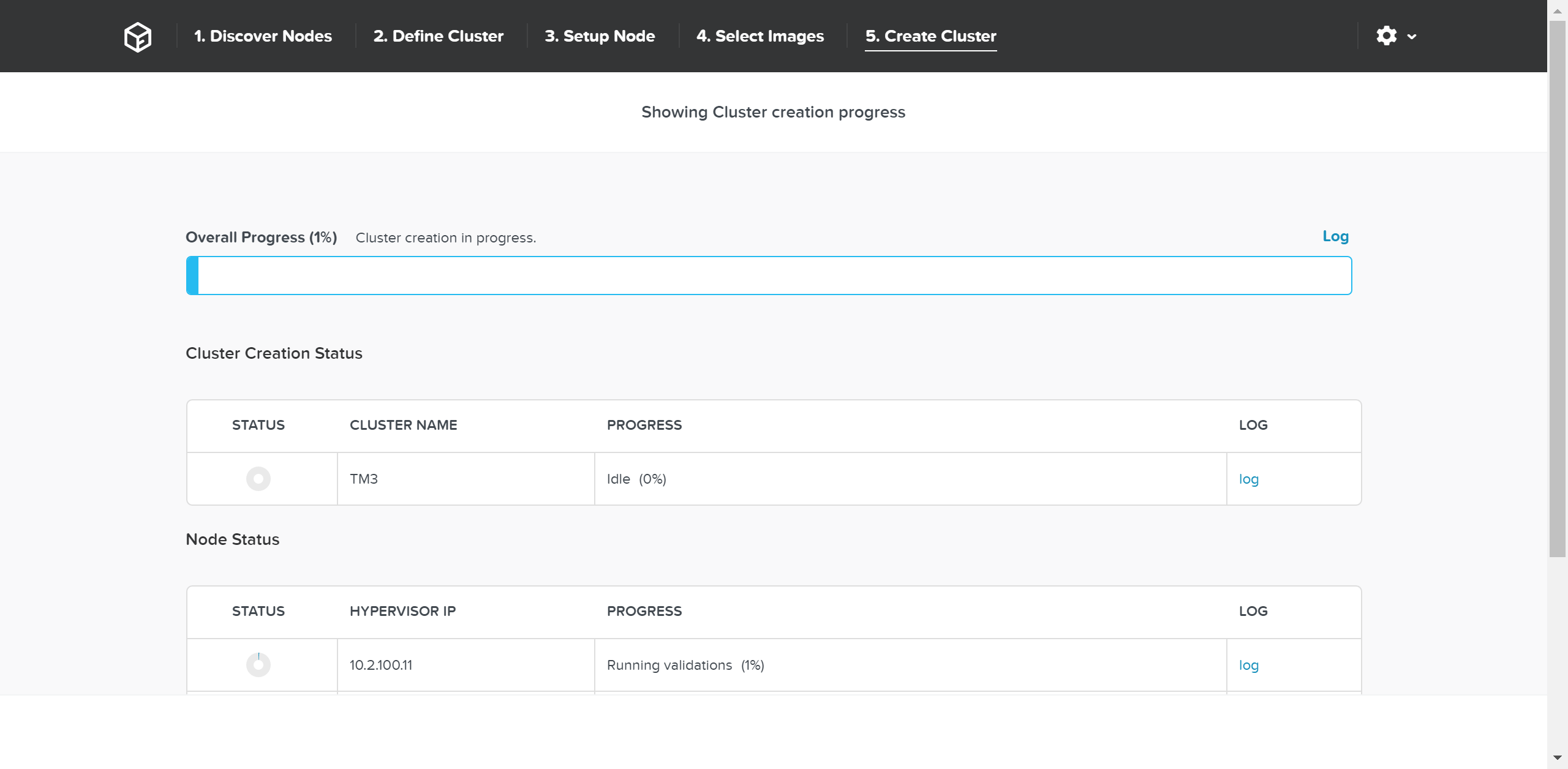 파운데이션 - 클러스터 생성 프로세스 (Foundation - Cluster Creation Process)
파운데이션 - 클러스터 생성 프로세스 (Foundation - Cluster Creation Process)
클러스터 생성이 성공하면 완료 화면이 나타난다.
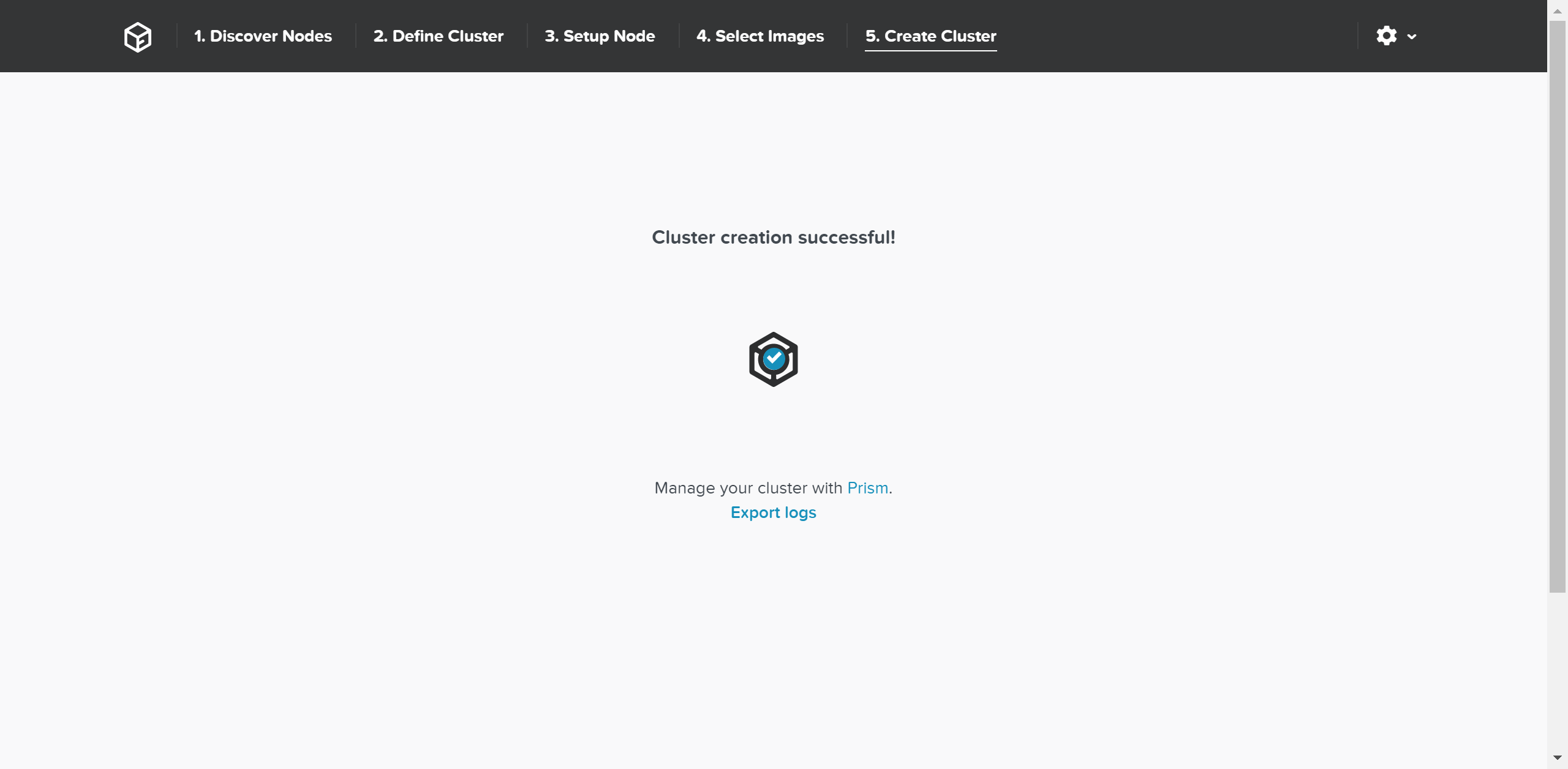 파운데이션 - 클러스터 생성 완료 (Foundation - Cluster Creation Complete)
파운데이션 - 클러스터 생성 완료 (Foundation - Cluster Creation Complete)
이제 임의의 CVM 또는 클러스터 가상 IP에 로그인하여 뉴타닉스 플랫폼을 사용할 수 있다.
드라이브 분해
본 섹션에서는 다양한 스토리지 디바이스(성능(NVMe/SSD) / 용량(SSD/HDD))가 뉴타닉스 플랫폼에 의해 어떻게 분할되고, 파티션되고, 활용되는지를 다룬다. NOTE: 사용된 모든 용량은 Base10 Gigabyte (GB)가 아닌 Base2 Gibibyte (GiB)를 기반으로 한다. 파일 시스템을 위한 드라이브 포맷팅 및 관련된 오버헤드를 고려하였다.
성능 디바이스
성능 디바이스는 노드에서 최고 성능의 디바이스이다. 성능 디바이스는 NVME 또는 NVME와 SSD의 혼합으로 구성될 수 있다. 성능 디바이스는 위에 자세히 설명된 몇 가지 주요 아이템을 저장한다.
- 뉴타닉스 홈 (CVM 코어)
- 메타데이터 (카산드라 / AES 스토리지)
- OpLog (영구 쓰기 버퍼)
- 익스텐트 스토어 (영구 스토리지)
다음 그림은 뉴타닉스 노드의 성능 디바이스(Performance Devices)에 대한 스토리지 분할의 예를 보여준다.
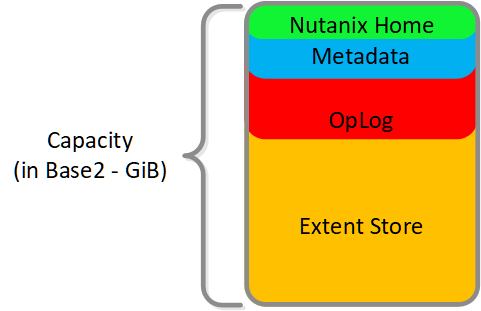 성능 드라이브 분해 (Performance Drive Breakdown)
성능 드라이브 분해 (Performance Drive Breakdown)
그래픽과 비율은 실제 크기에 맞게 그려지지 않았다. Remaining GiB GiB 용량은 탑-다운 방식으로 계산한다. 예를 들어, OpLog 계산에 사용될 Remaining GiB는 포맷된 SSD 용량에서 뉴타닉스 홈과 카산드라를 차감한 이후의 것이다.
뉴타닉스 홈(Nutanix Home)은 가용성을 보장하기 위해 처음 두 개의 SSD에 미러링되며 두 디바이스에 60GiB의 용량이 할당되어 있다.
AOS 5.0에서 카산드라는 SSD 당 15GiB의 초기 예약으로 노드의 여러 SSD(현재 최대 4개)에 분할된다 (메타데이터 사용이 증가하는 경우 일부 스타케이트 SSD를 활용할 수 있음). 듀얼 SSD 시스템에서 메타데이터는 SSD 간에 미러링된다. SSD 당 메타데이터 예약은 15GiB(듀얼 SSD의 경우 30GiB, 4+ SSD의 경우 60GiB)이다.
AOS 5.0 이전에는 카산드라가 기본적으로 첫 번째 SSD에 있었고, SSD에 장애가 발생하면 CVM이 다시 시작되고 카산드라 스토리지가 두 번째에 있었다. 이 경우 SSD 당 메타데이터 예약은 처음 두 디바이스에 대해 30GiB이다.
OpLog는 모든 SSD 디바이스에 노드 당 최대 12개까지 분배된다(Gflag : max_ssds_for_oplog). NVMe 디바이스를 사용할 수 있는 경우 OpLog는 SATA SSD 대신 NVME 디바이스에 배치된다.
디스크 당 OpLog 예약은 다음 공식을 사용하여 계산할 수 있다: MIN (((Max cluster RF / 2) * 400 GiB) / numDevForOplog), ((Max cluster RF / 2) * 25 %) x Remaining GiB). NOTE: OpLog 사이징은 AOS 4.0.1부터 동적으로 수행되므로 익스텐트 스토어(Extent Store) 부분이 동적으로 커질 수 있다. 사용된 값은 완전히 활용된 OpLog를 가정한다.
예를 들어, 1TB인 SSD 디바이스가 8개인 RF2(FT1) 클러스터에서 계산된 결과는 다음과 같다.
- MIN(((2/2)*400 GiB)/ 8), ((2/2)*25%) x ~900GiB) == MIN(50, 225) == 디바이스 당 OpLog에 50GiB가 예약됨
RF3(FT2) 클러스터의 경우는 다음과 같다.
- MIN(((3/2)*400 GiB)/ 8), ((3/2)*25%) x ~900GiB) == MIN(75, 337) == 디바이스 당 OpLog에 75GiB가 예약됨
1TB인 4개의 NVMe와 8개의 SSD 디바이스가 있는 RF2(FT1) 클러스터의 경우 결과는 다음과 같다.
- MIN(((2/2)*400 GiB)/ 4), ((2/2)*25%) x ~900GiB) == MIN(100, 225) == 디바이스 당 OpLog에 100GiB가 예약됨
익스텐트 스토어(Extent Store) 용량은 다른 모든 예약이 고려된 후 남은 용량이다.
HDD 디바이스
HDD 디바이스는 기본적으로 대용량의 스토리지로 사용되기 때문에 분할이 훨씬 간단하다.
- 큐레이터 예약 (큐레이터 스토리지)
- 익스텐트 스토어 (영구 스토리지)
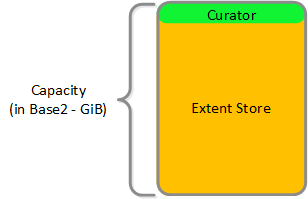 HDD 드라이브 분해 (HDD Drive Breakdown)
HDD 드라이브 분해 (HDD Drive Breakdown)
Book of Prism
prism - /’prizɘm/ - noun - control plane
데이터센터 운영을 위한 원클릭 관리 및 인터페이스.
아름답고 공감적이며 직관적인 제품을 만드는 것이 뉴타닉스 플랫폼의 핵심이며 뉴타닉스가 진지하게 고민하는 것이다. 본 섹션에서 설계 방법론과 설계 반복 과정에 대해 다룬다.
뉴타닉스 비지오 스텐실은 다음 링크에서 다운로드할 수 있다: http://www.visiocafe.com/nutanix.htm
프리즘 아키텍처
프리즘은 분산 리소스 관리 플랫폼으로, 사용자는 로컬 또는 클라우드에서 호스팅되는 뉴타닉스 환경에서 오브젝트 및 서비스를 관리하고 모니터링 할 수 있다.
이러한 기능은 두 가지 주요 카테고리로 구분된다.
- 인터페이스 (Interfaces)
- HTML5 UI, REST API, CLI, PowerShell CMDlets 등
- 관리 기능 (Management Capabilities)
- 플랫폼 관리, VM/컨테이너 CRUD, 정책 정의 및 규정 준수, 서비스 디자인 및 상태, 분석 및 모니터링
다음 그림은 뉴타닉스 플랫폼의 일부로서 프리즘의 개념적 특성을 보여준다.
하이-레벨 프리즘 아키텍처 (High-Level Prism Architecture)
프리즘은 두 가지 메인 컴포넌트로 나뉜다.
- 프리즘 센트럴 (Prism Central: PC)
- 여러 개의 뉴타닉스 클러스터를 관리하기 위한 멀티 클러스터 매니저로 단일 중앙 집중식 관리 인터페이스를 제공한다. 프리즘 센트럴은 AOS 클러스터 (실행 가능) 이외에도 배포할 수 있는 선택적인 소프트웨어 어플라이언스(VM)이다.
- 1-to-Many 클러스터 매니저
- 프리즘 엘리먼트 (Prism Element: PE)
- 로컬 클러스터 관리 및 오퍼레이션을 담당하는 로컬 클러스터 매니저이다. 모든 뉴타닉스 클러스터에는 프리즘 엘리먼트가 내장되어 있다.
- 1-to-1 클러스터 매니저
프리즘 센트럴과 프리즘 엘리먼트의 개념적 관계는 다음 그림과 같다.
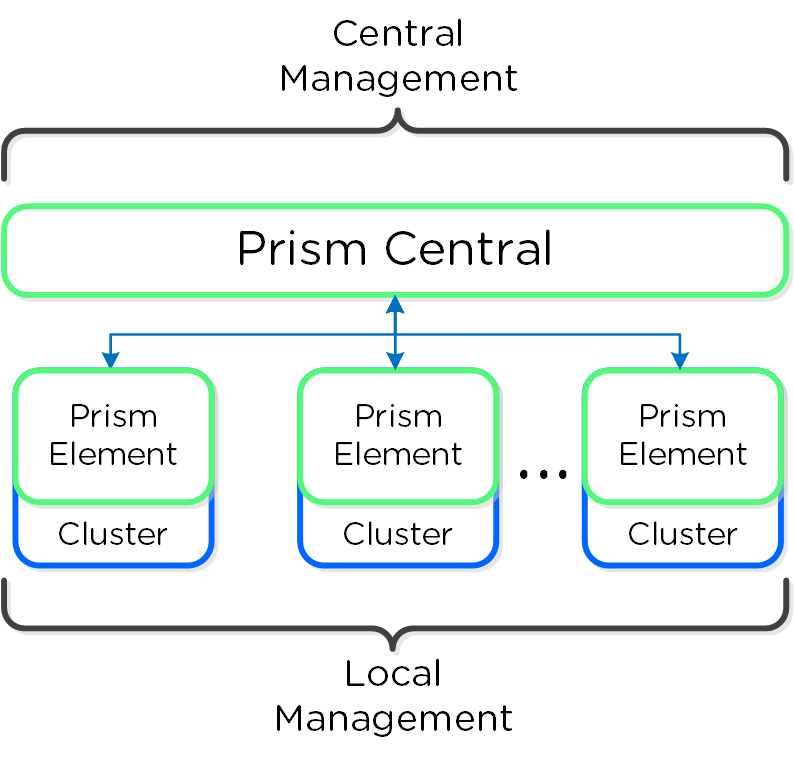 프리즘 아키텍처 (Prism Architecture)
프리즘 아키텍처 (Prism Architecture)
Note
Pro tip
대규모 또는 분산 배포(e.g. 1개 이상의 클러스터 또는 여러 개의 사이트)인 경우 오퍼레이션을 단순화하고 모든 클러스터/사이트에 대해 단일 관리 UI를 제공하기 위해 프리즘 센트럴의 사용을 권고한다.
프리즘 서비스
프리즘 서비스는 HTTP 요청의 처리를 담당하는 선출된 프리즘 리더와 함께 모든 CVM에서 실행된다. 리더를 갖는 다른 컴포넌트와 유사하게 프리즘 리더에 장애가 발생하면 새로운 리더가 선출된다. 프리즘 리더가 아닌 CVM이 HTTP 요청을 받으면, HTTP 응답 상태 코드인 “301’을 사용하여 현재 프리즘 리더로 영구적으로 리다이렉트한다.
다음은 프리즘 서비스의 개념과 HTTP 요청 처리 방법을 나타낸 것이다.
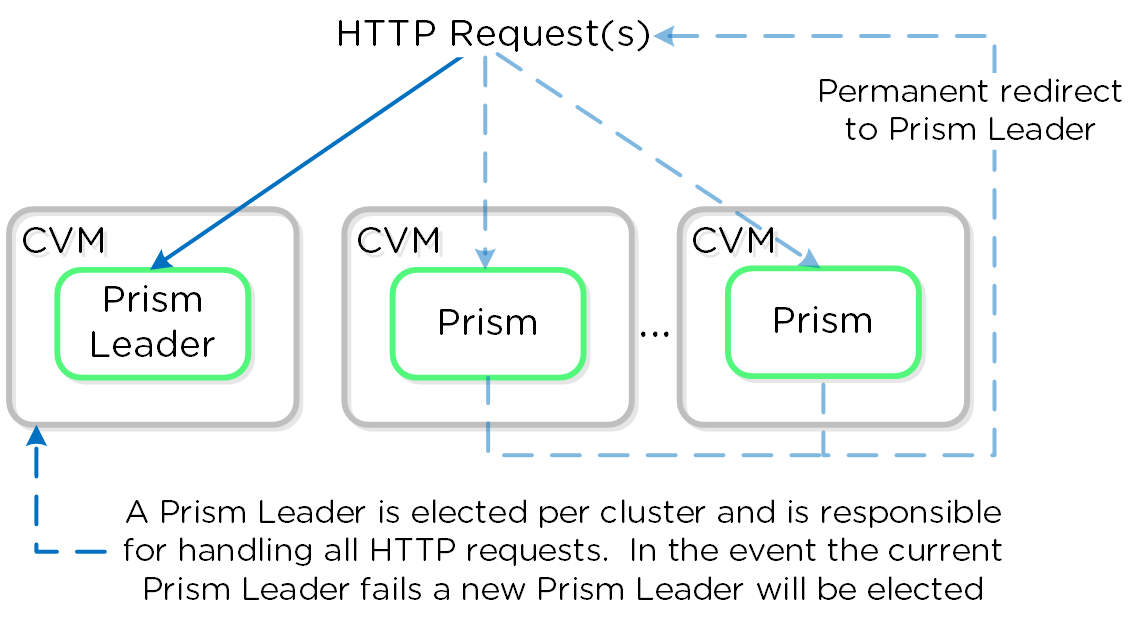 프리즘 서비스 – 요청 처리 (Prism Services - Request Handling)
프리즘 서비스 – 요청 처리 (Prism Services - Request Handling)
Note
프리즘 포트 (Prism Ports)
프리즘은 포트 80과 9440에서 수신 대기하며, 만약 HTTP 트래픽이 80번 포트로 들어오면 해당 요청은 9440 포트에서 HTTPS로 리다이렉트된다.
클러스터 가상 IP를 사용할 때(권장) 현재 프리즘 리더가 항상 호스트 한다. 프리즘 리더가 실패하면 클러스터 가상 IP는 새로 선출된 프리즘 리더가 맡게 되며 오래된 ARP 캐시 엔트리를 삭제하기 위해 Gratuitous ARP(gARP)가 사용된다. 이 시나리오에서는 클러스터 가상 IP를 사용하여 프리즘에 액세스할 때마다, 클러스터 가상 IP가 이미 프리즘 리더이므로 리다이렉션이 필요하지 않다.
Note
Pro tip
임의의 CVM에서 다음 명령을 실행하여 현재 프리즘 리더를 확인할 수 있다:
curl localhost:2019/prism/leader
인증 및 접근 제어 (RBAC)
인증 (Authentication)
프리즘은 현재 다음 인증 공급자와의 통합을 지원한다.
- 프리즘 엘리먼트 (Prism Element: PE)
- 로컬
- 액티브 디렉토리
- LDAP
- 프리즘 센트럴 (Prism Central: PC)
- 로컬
- 액티브 디렉토리
- LDAP
- SAML 인증 (IDP)
Note
SAML / 2FA
SAML 인증을 사용하면 프리즘을 SAML과 호환되는 외부 ID 제공 업체(e.g. Okta, ADFS 등)와 통합할 수 있다.
또한 이러한 공급자가 프리즘에 로그인하는 사용자를 지원하는 MFA(Multi-Factor Authentication) / 2FA(Two-Factor Authentication) 기능을 활용할 수 있다.
접근 제어 (Access Control)
내용 추가 예정입니다.
내비게이션 (Navigation)
프리즘은 상당히 직선적이고 사용하기 쉽지만, 몇 가지 메인 페이지와 기본적인 사용법을 다룬다.
프리즘 센트럴(배포된 경우에)은 설정 단계에서 지정한 IP 또는 해당 DNS 엔트리를 이용하여 액세스할 수 있다. 프리즘 엘리먼트는 프리즘 센트럴(특정 클러스터 클릭)을 통해 액세스하거나 뉴타닉스 CVM 또는 클러스터 가상 IP(선호)로 내비게이션 하여 액세스할 수 있다.
페이지가 로드되면 프리즘 또는 액티브 디렉토리 크리덴셜을 사용하여 로그인할 로그인 페이지가 나타난다.
 프리즘 로그인 페이지 (Prism Login Page)
프리즘 로그인 페이지 (Prism Login Page)
로그인이 성공하면 프리즘 센트럴에서는 관리 클러스터, 프리즘 엘리먼트에서는 로컬 클러스터에 대한 개요 정보를 제공하는 대시보드 페이지로 이동된다.
프리즘 센트럴 및 프리즘 엘리먼트에 대해서는 다음 섹션에서 보다 자세히 다룬다.
프리즘 센트럴 (Prism Central)
그림은 여러 개의 클러스터를 모니터링/관리할 수 있는 샘플 프리즘 센트럴 대시보드를 보여준다.
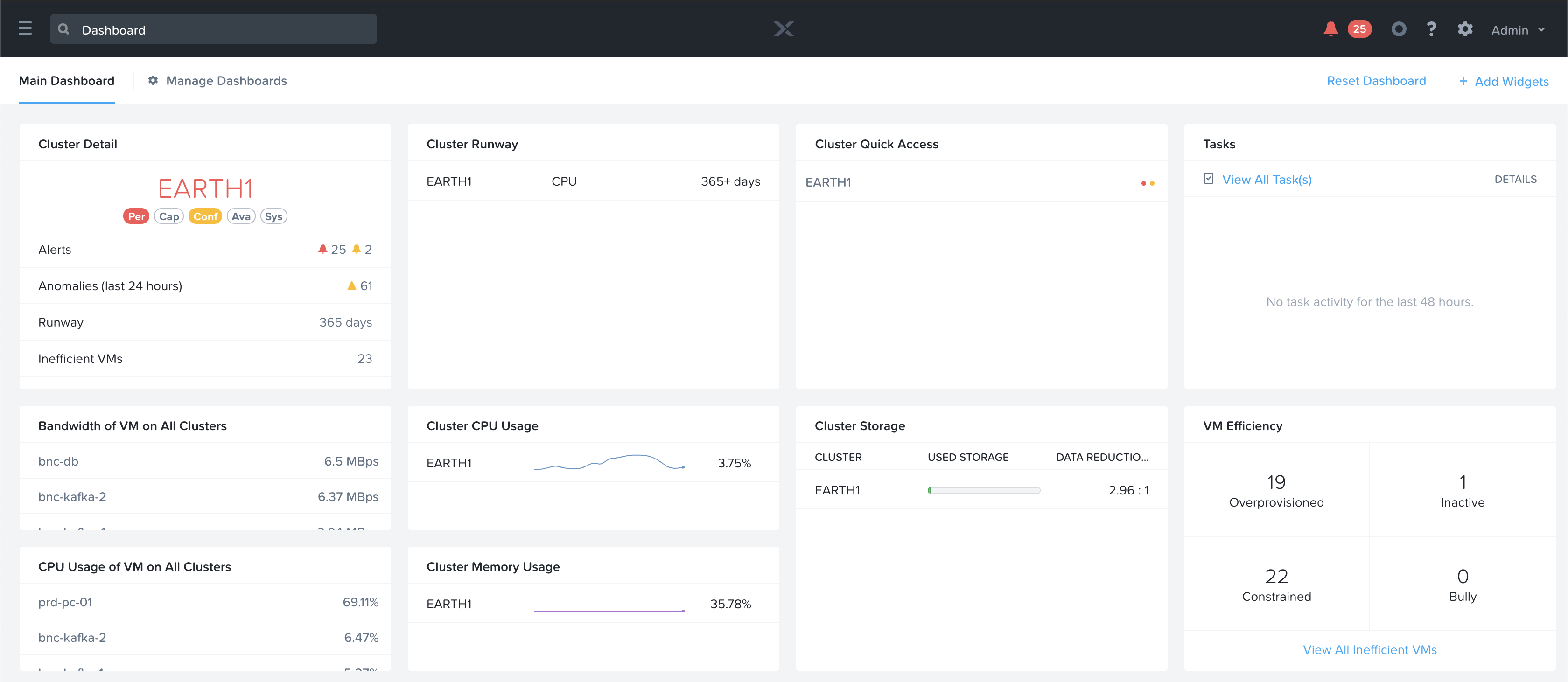 프리즘 센트럴 - 대시보드 (Prism Central - Dashboard)
프리즘 센트럴 - 대시보드 (Prism Central - Dashboard)
여기에서 환경의 전반적인 상태를 모니터링하고 경고 또는 관심 항목이 있는 경우 좀 더 자세히 파악할 수 있다.
프리즘 센트럴은 다음과 같은 메인 페이지가 있다 (NOTE: 검색은 내비게이션을 위한 선호/권고하는 방법):
- Home Page
- 서비스 상태, 용량 계획, 성능, 태스크 등에 대한 자세한 정보를 포함하는 환경 전반 모니터링 대시보드. 이들 중 어느 항목에 대한 추가 정보를 얻으려면 관심 아이템을 클릭한다.
- Virtual Infrastructure
- 가상 엔티티 (e.g. VMs, 컨테이너, 이미지, 카테고리 등)
- Policies
- 정책 관리 및 생성 (e.g. 보안 (FLOW), 보호 (백업/복제), 복구 (DR), NGT)
- Hardware
- 물리적 디바이스 관리 (e.g. 클러스터, 호스트, 디스크, GPU)
- Activity
- 환경 전반에 걸친 경고, 이벤트 및 태스크
- Operations
- 오퍼레이션 대시보드, 보고 및 액션 (X-Play)
- Administration
- 환경 구성 관리 (e.g. 사용자, 그룹, 역할, 가용성 영역)
- Services
- 부가 서비스 관리 (e.g. Calm, Karbon)
- Settings
- 프리즘 센트럴 설정
메뉴에 액세스하려면 햄버거 아이콘을 클릭한다.
 프리즘 센트럴 - 햄버거 (Prism Central - Hamburger)
프리즘 센트럴 - 햄버거 (Prism Central - Hamburger)
메뉴가 펼쳐져 사용 가능한 옵션이 표시된다.
 프리즘 센트럴 - 메뉴 바 (Prism Central - Menu Bar)
프리즘 센트럴 - 메뉴 바 (Prism Central - Menu Bar)
검색 (Search)
검색은 이제 프리즘 센트럴 UI 내비게이션을 위한 기본 메커니즘이다 (메뉴는 계속 사용할 수 있음).
검색 창을 통해 내비게이션 하려면 메뉴 아이콘 옆의 왼쪽 상단 모서리에 있는 검색 창을 사용할 수 있다.
 프리즘 센트럴 - 검색 (Prism Central - Search)
프리즘 센트럴 - 검색 (Prism Central - Search)
Note
검색 시맨틱 (Search Semantics)
PC 검색은 시맨틱을 활용할 수 있게 한다. 몇 가지 예는 다음과 같다.
| Rule | Example |
|---|---|
| Entity type | vms |
| Entity type + metric perspective (io, cpu, memory) | vms io |
| Entity type + alerts | vm alerts |
| Entity type + alerts + alert filters | vm alerts severity=critical |
| Entity type + events | vm events |
| Entity type + events + event filters | vm events classification=anomaly |
| Entity type + filters (both metric and attribute) | vm “power state”=on |
| Entity type + filters + metric perspective (io, cpu, memory) | vm “power state”=on io |
| Entity type + filters + alerts | vm “power state”=on alerts |
| Entity type + filters + alerts + (alert filters) | vm “power state”=on alerts severity=critical |
| Entity type + filters + events | vm “power state”=on events |
| Entity type + filters + events + event filters | vm “power state”=on events classification=anomaly |
| Entity instance (name, ip address, disk serial etc) | vm1, 10.1.3.4, BHTXSPWRM |
| Entity instance + Metric perspective (io, cpu, memory) | vm1 io |
| Entity instance + alerts | vm1 alerts |
| Entity instance + alerts + alert filters | vm1 alerts severity=critical |
| Entity instance + events | vm1 events |
| Entity instance + events + event filters | vm1 events classification=anomaly |
| Entity instance + pages | vm1 nics, c1 capacity |
| Parent instance + entity type | c1 vms |
| Alert title search | Disk bad alerts |
| Page name search | Analysis, tasks |
상기 예제는 시맨틱의 일부분에 지나지 않는다. 시맨틱에 익숙해지기 위한 가장 좋은 방법은 실제로 해보는 것이다.
프리즘 엘리먼트 (Prism Element)
프리즘 엘리먼트는 다음 메인 페이지를 포함한다.
- Home Page
- 경고, 용량, 성능, 헬스, 태스크 등에 대한 자세한 정보를 포함한 로컬 클러스터 모니터링 대시보드. 이들 중 어느 하나에 대한 추가 정보를 얻으려면 관심 항목을 클릭한다.
- Health Page
- 환경, 하드웨어, 관리 오브젝트 헬스 및 상태 정보. 또한, NCC 헬스 체크 상태를 포함한다.
- VM Page
- 전체 VM 관리, 모니터링 및 CRUD (AOS)
- Storage Page
- 컨테이너 관리, 모니터링 및 CRUD
- Hardware Page
- 서버, 디스크 및 네트워크 관리, 모니터링 및 헬스. 클러스터 확장과 노드 및 디스크 제거를 포함한다.
- Data Protection Page
- DR, 클라우드 커넥트 및 메트로 가용성 설정, PD 오브젝트, 스냅샷, 복제 및 복원 관리
- Analysis Page
- 이벤트와 상관관계가 있는 클러스터 및 관리 오브젝트에 대한 자세한 성능 분석
- Alerts Page
- 로컬 클러스터 및 환경 경고
홈 페이지는 경고, 서비스 상태, 용량, 성능, 태스크 등에 대한 자세한 정보를 제공한다. 이들 중 어느 하나에 대한 추가 정보를 얻으려면 관심 항목을 클릭한다.
그림은 로컬 클러스터 세부 정보가 표시되는 샘플 프리즘 엘리먼트 대시보드를 보여준다.
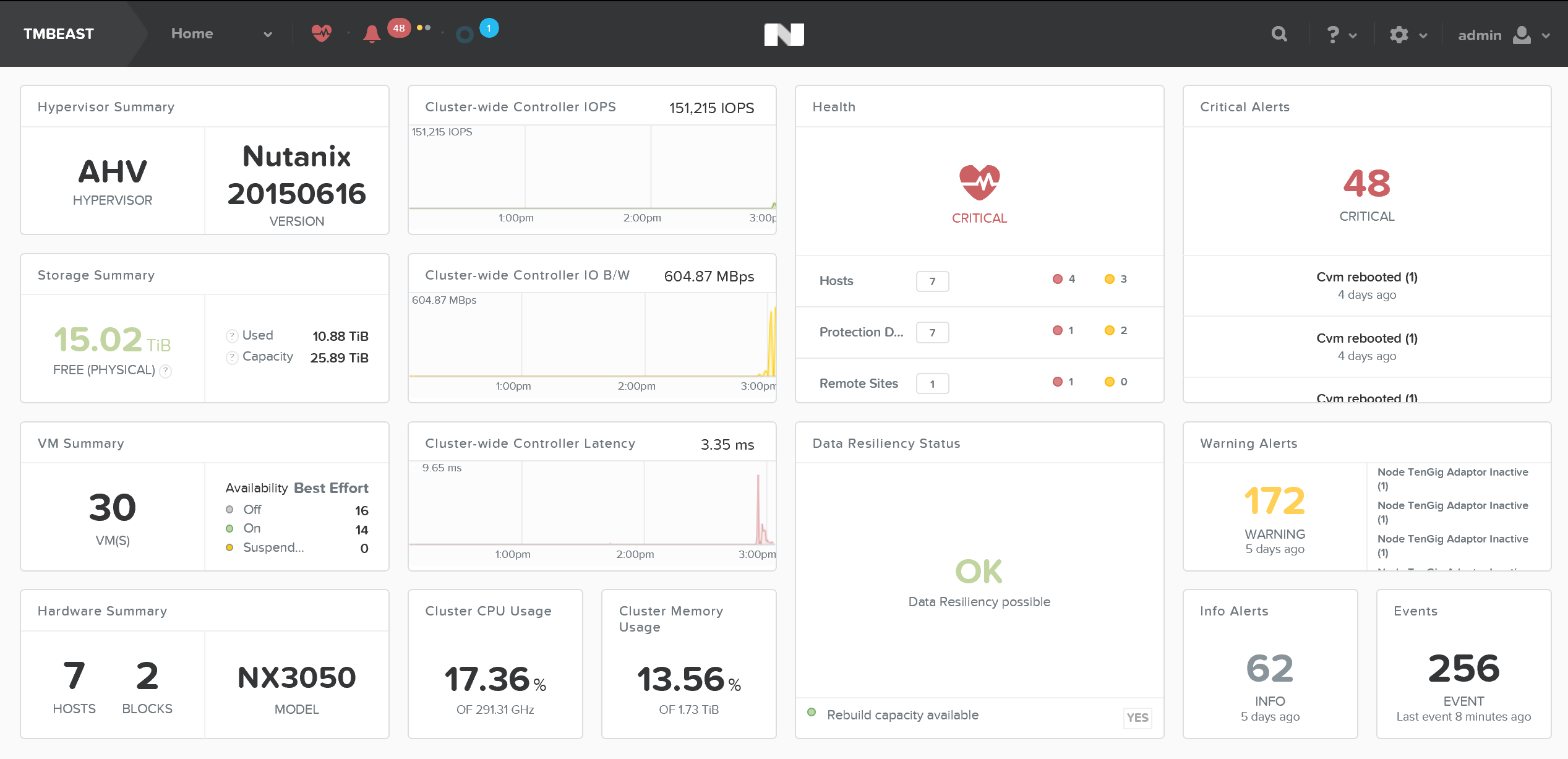 프리즘 엘리먼트 - 대시보드 (Prism Element - Dashboard)
프리즘 엘리먼트 - 대시보드 (Prism Element - Dashboard)
Note
키보드 단축키 (Keyboard Shortcuts)
접근성 및 사용 용이성은 프리즘에서 가장 중요이다. 최종 사용자의 작업을 단순화하기 위해 사용자가 키보드로 모든 작업을 수행할 수 있도록 단축키가 추가되었다.
다음은 몇 가지 주요 단축키의 특징이다.
뷰 변경 (페이지 컨텍스트 인식)
- O - Overview View
- D - Diagram View
- T - Table View
액티비티 및 이벤트
- A - Alerts
- P - Tasks
드롭 다운 및 메뉴 (화살표 키를 사용하여 선택항목 이동)
- M - Menu drop-down
- S - Settings (gear icon)
- F - Search bar
- U - User drop down
- H - Help
기능 및 사용법
다음 섹션에서 몇 가지 일반적인 장애 처리 시나리오와 함께 대표적인 프리즘 사용법에 대해 설명한다.
이상 징후 탐지
IT 운영의 세계에는 많은 노이즈가 있다. 전통적으로 시스템은 많은 경고, 이벤트 및 통지를 생성하며, 종종 운영자는 a) 노이즈에서 손실되었기 때문에 중요한 경고를 보지 못하거나 또는 b) 경고/이벤트를 무시할 수 있다.
뉴타닉스 이상 징후 탐지 기능을 사용하면 시스템은 시계열 데이터(e.g. CPU 사용량, 메모리 사용량, 레이턴시 등)의 계절적 추세를 모니터링하고 예상 값의 "밴드(Band)"를 설정할 수 있다. "밴드" 범위를 벗어나는 값에 대해서만 이벤트/경고를 발생시킨다. 모든 엔티티 또는 이벤트 페이지에서 이상 징후 이벤트/경고를 볼 수 있다.
다음 차트는 이러한 시스템에서 일부 대규모 배치 처리를 수행할 때 발생하는 많은 I/O 및 디스크 사용량의 이상 징후를 보여준다.
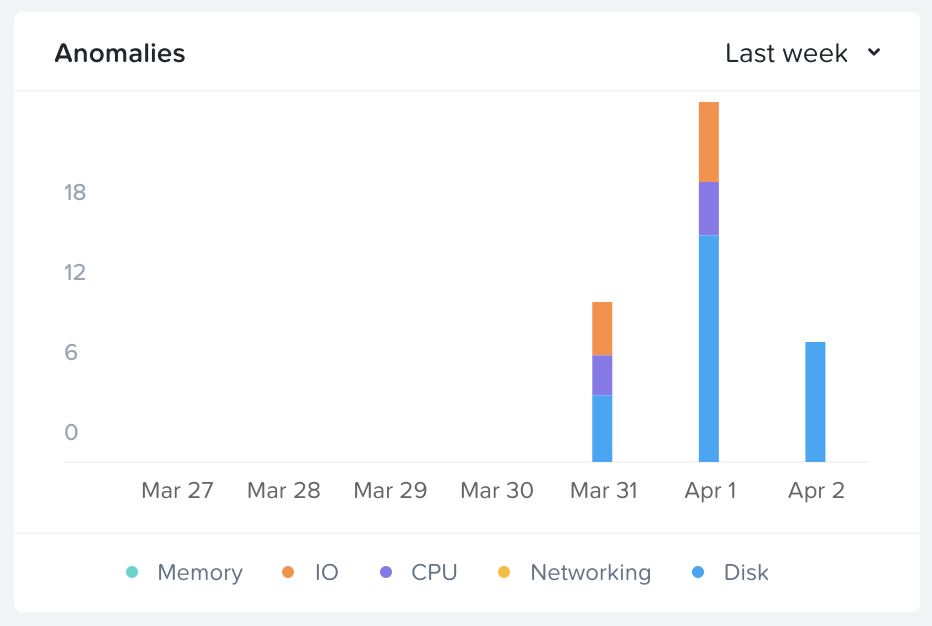 프리즘 - 이상 징후 차트 (Prism - Anomaly Chart)
프리즘 - 이상 징후 차트 (Prism - Anomaly Chart)
다음 이미지는 샘플 메트릭과 설정된 "밴드(band)"에 대한 시계열 값을 보여준다.
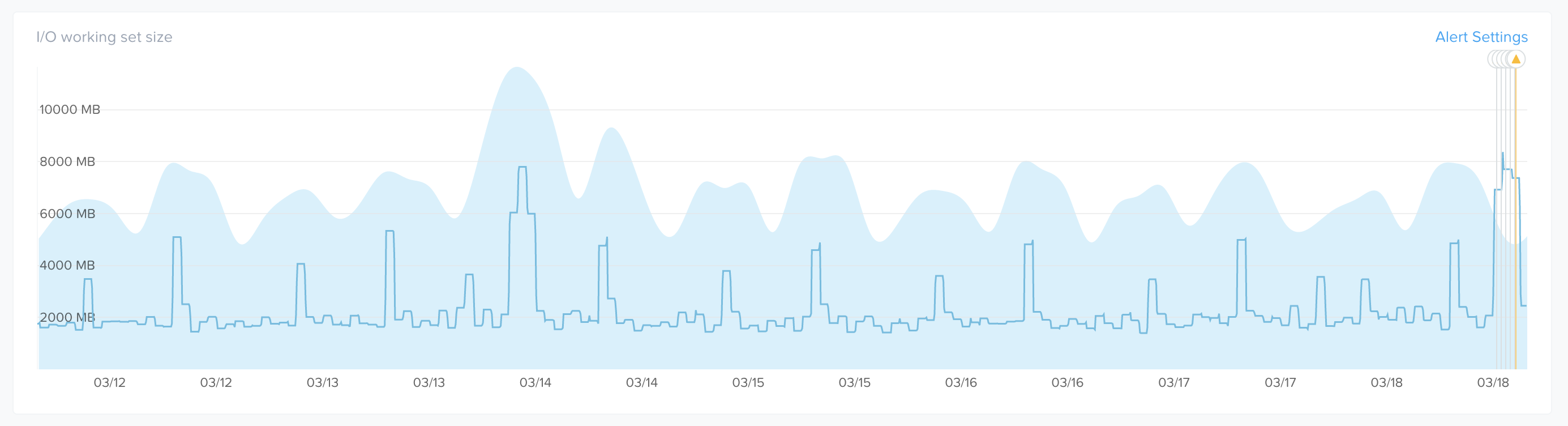 프리즘 - 이상 징후 밴드 (Prism - Anomaly Band)
프리즘 - 이상 징후 밴드 (Prism - Anomaly Band)
이것은 "정상"상태에 대한 경고를 원하지 않기 때문에 불필요한 경고를 감소시킨다. 예를 들어 데이터베이스 시스템은 캐싱 등으로 인해 정상적으로 95% 이상의 메모리 사용률로 실행된다. 이 경우에 뭔가 잘못될(e.g. 데이터베이스 서비스 다운) 수 있기 때문에 이상 징후일 가능성이 10%라고 말한다.
또 다른 예는 일부 배치 워크로드가 주말에 어떻게 실행되는지이다. 예를 들어 근무 주간에는 I/O 대역폭이 낮을 수 있지만, 일부 배치 프로세스(e.g. 백업, 보고서 등)가 실행되는 주말에 I/O가 급격히 증가할 수 있다. 시스템은 이것의 계절성을 감지하고 주말 동안에 밴드를 올린다.
여기에서 값이 예상되는 밴드를 벗어났기 때문에 이상 징후 이벤트가 발생했음을 알 수 있다.
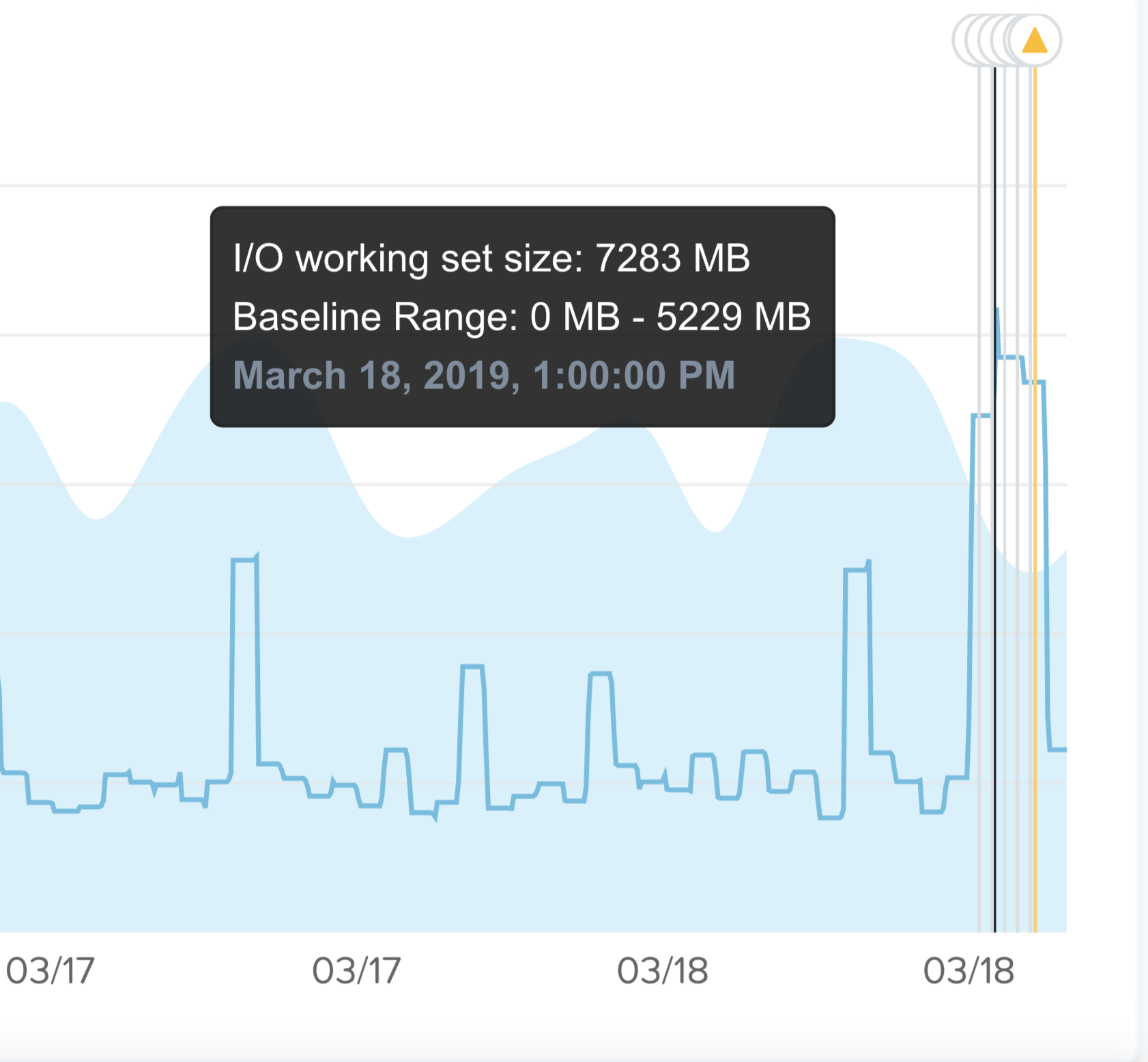 프리즘 - 이상 징후 이벤트 (Prism - Anomaly Event)
프리즘 - 이상 징후 이벤트 (Prism - Anomaly Event)
이상 징후에 대한 또 다른 관심 주제는 계절성이다. 예를 들어 소매업자는 휴일 기간 동안의 수요가 연중 다른 기간 또는 월 마감 동안 보다 높다는 것을 알 수 있다.
이상 징후 탐지는 이러한 계절성을 설명하며 다음 기간을 활용하여 미시적(일별) 및 거시적(분기별) 추세를 비교한다.
- 일별 (Daily)
- 주별 (Weekly)
- 월별 (Monthly)
사용자는 맞춤 경고 또는 정적 임계 값을 설정할 수 있다.
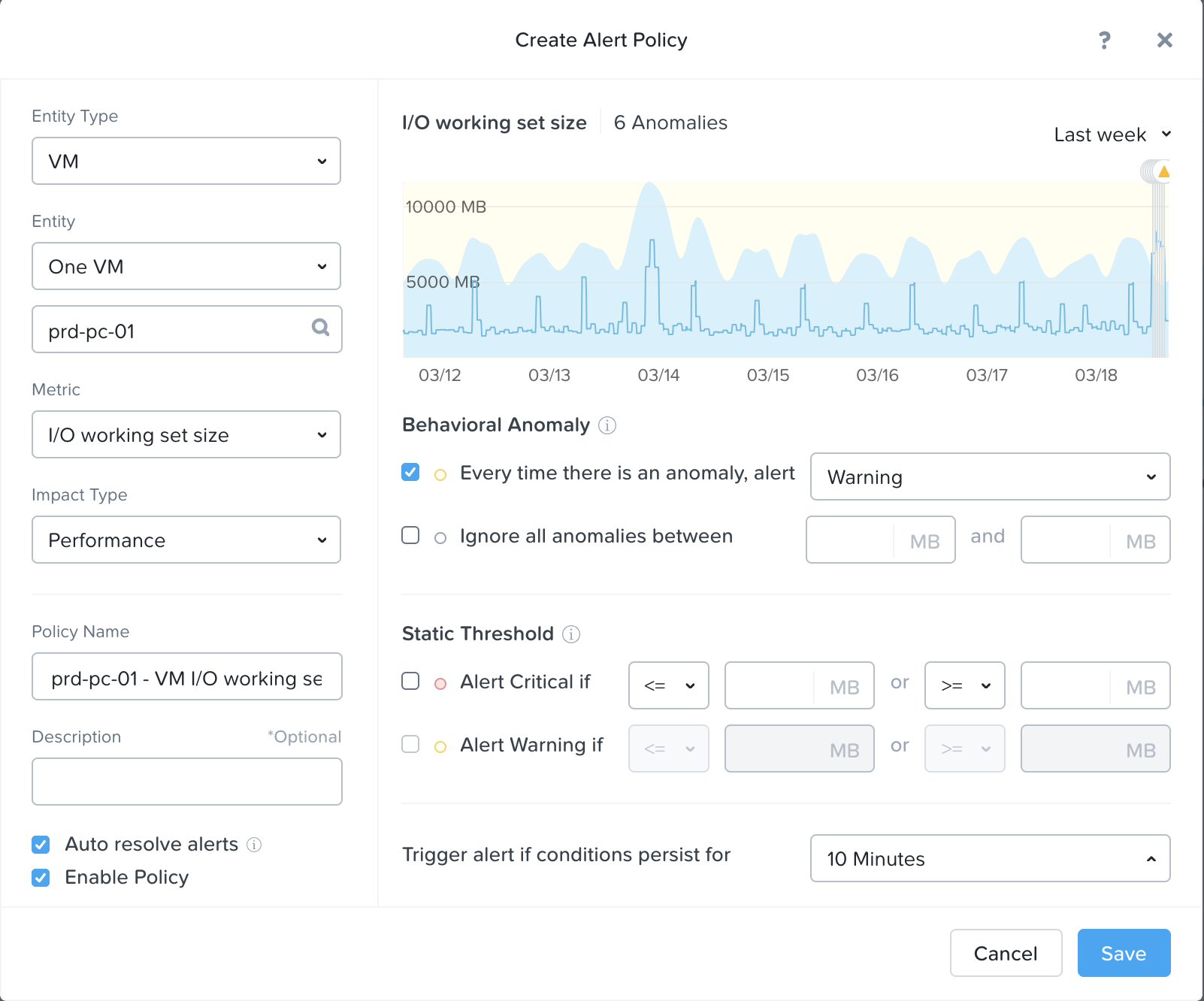 프리즘 - 이상 징후 커스텀 이벤트 (Prism - Anomaly Custom Event)
프리즘 - 이상 징후 커스텀 이벤트 (Prism - Anomaly Custom Event)
Note
이상 징후 탐지 알고리즘 (Anomaly Detection Algorithm)
뉴타닉스는 밴드를 결정하기 위해 '일반화된 극한의 학생 편차 테스트(Generalized Extreme Studentized Deviate Test)'라는 방법을 활용한다. 이것을 이해하는 간단한 방법은 값이 알고리즘에 의해 설정된 상한과 하한 사이에 있는 신뢰 구간과 유사하다.
알고리즘은 계절성 및 예상되는 밴드를 계산하기 위해 3배의 세분화된 데이터(e.g. 일별, 주별, 월별 등)가 필요하다. 예를 들어 각각의 계절성을 반영하기 위해 다음과 같은 양의 데이터가 필요하다.
- 일별 (Daily): 3일
- 주별 (Weekly): 3주 (21일)
- 월별 (Monthly): 3개월 (90일)
트위터는 이것을 어떻게 활용하는지에 대한 좋은 자료를 가지고 있는데, 로직에 대한 보다 자세한 설명은 다음 링크 참조: LINK
뉴타닉스 소프트웨어 업그레이드
뉴타닉스 소프트웨어 업그레이드를 수행하는 것은 매우 간단하고 무중단(non-disruptive) 프로세스이다.
시작하려면 프리즘에 로그인하고 오른쪽 상단의 기어 아이콘(설정)을 클릭하거나 'S'를 누르고 “Upgrade Software”를 선택한다.
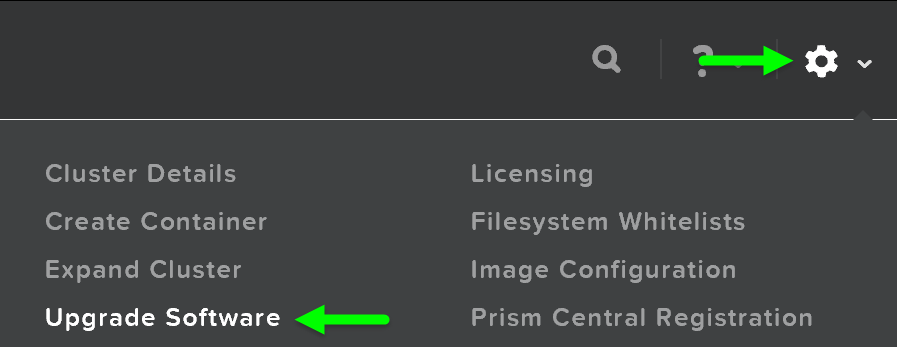 프리즘 – 설정 – 업그레이드 소프트웨어 (Prism - Settings - Upgrade Software)
프리즘 – 설정 – 업그레이드 소프트웨어 (Prism - Settings - Upgrade Software)
그러면 “Upgrade Software” 다이얼로그 박스가 나타나고 현재 소프트웨어 버전과 사용 가능한 업그레이드 버전이 표시된다. AOS 바이너리 파일을 수동으로 업로드하는 것도 가능하다.
그런 다음 클라우드에서 업그레이드 버전을 다운로드하거나 수동으로 버전을 업로드할 수 있다.
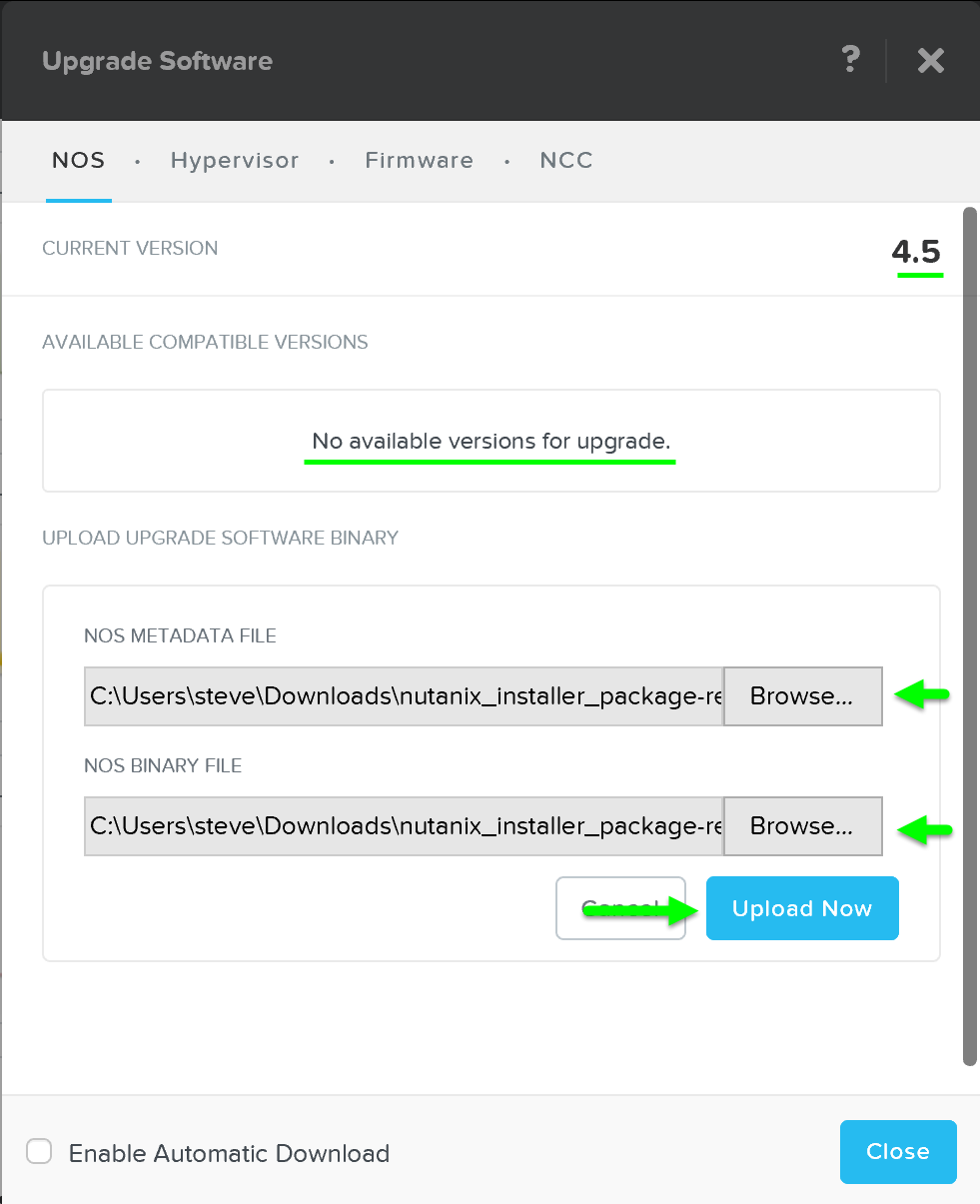 업그레이드 소프트웨어 – 메인 (Upgrade Software - Main)
업그레이드 소프트웨어 – 메인 (Upgrade Software - Main)
Note
CVM에서 소프트웨어 업로드 (Upload software from the CVM)
경우에 따라 소프트웨어를 다운로드하고 CVM 자체에서 업로드 할 수도 있다. 예를 들어, 빌드를 CVM에 로컬로 다운로드하는 데 사용할 수 있다.
먼저 CVM에 SSH로 접속하고 프리즘 리더를 찾는다:
curl localhost:2019/prism/leader
프리즘 리더에 SSH로 접속하고 소프트웨어 번들 및 메타데이터 JSON을 다운로드한다.
다음 명령을 실행하여 소프트웨어를 프리즘에 "업로드" 한다:
ncli software upload file-path=PATH_TO_SOFTWARE meta-file-path=PATH_TO_METADATA_JSON software-type=SOFTWARE_TYPE
다음은 프리즘 센트럴에 대한 예를 보여준다:
ncli software upload file-path=/home/nutanix/tmp/leader-prism_central.tar meta-file-path=/home/nutanix/tmp/leader-prism_central-metadata.json software-type=prism_central_deploy
그런 다음 업그레이드 소프트웨어를 뉴타닉스 CVM에 업로드한다.
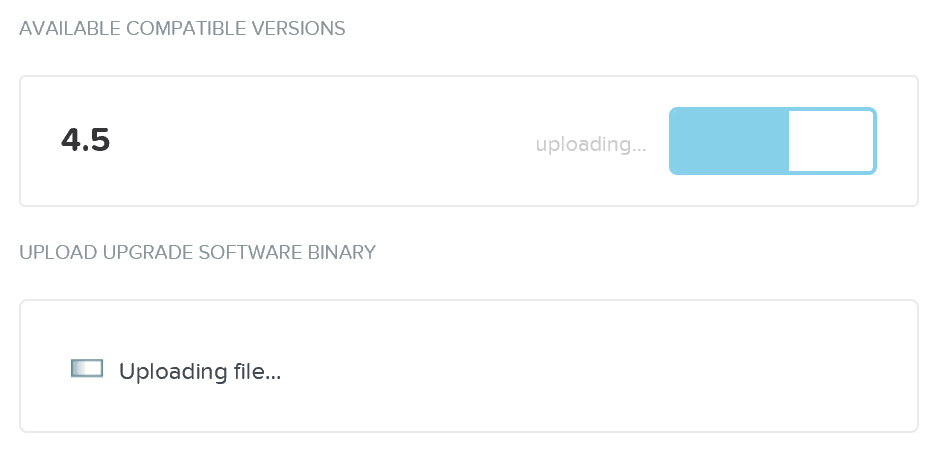 업그레이드 소프트웨어 – 업로드 (Upgrade Software - Upload)
업그레이드 소프트웨어 – 업로드 (Upgrade Software - Upload)
소프트웨어가 로드된 후 “Upgrade”를 클릭하여 업그레이드 프로세스를 시작한다.
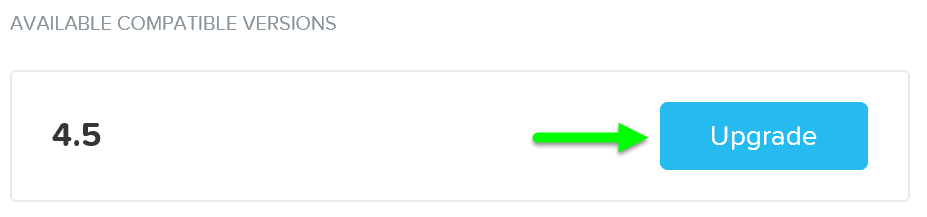 업그레이드 소프트웨어 – 업그레이드 정합성 체크 (Upgrade Software - Upgrade Validation)
업그레이드 소프트웨어 – 업그레이드 정합성 체크 (Upgrade Software - Upgrade Validation)
그러면 “확인” 다이얼로그 박스가 나타난다.
 업그레이드 소프트웨어 – 업그레이드 확인 (Upgrade Software - Confirm Upgrade)
업그레이드 소프트웨어 – 업그레이드 확인 (Upgrade Software - Confirm Upgrade)
업그레이드는 업그레이드 사전 검사부터 시작하여 롤링 방식으로 소프트웨어 업그레이드를 시작한다.
 업그레이드 소프트웨어 – 업그레이드 작업 수행 (Upgrade Software - Execution)
업그레이드 소프트웨어 – 업그레이드 작업 수행 (Upgrade Software - Execution)
업그레이드가 완료되면 업데이트된 상태가 표시되고 모든 새로운 기능에 액세스할 수 있다.
 업그레이드 소프트웨어 – 업그레이드 작업 완료 (Upgrade Software - Complete)
업그레이드 소프트웨어 – 업그레이드 작업 완료 (Upgrade Software - Complete)
Note
Note
현재 프리즘 리더가 업그레이드될 때 프리즘 세션이 잠시 중단된다. 실행 중인 모든 VM 및 서비스는 영향을 받지 않는다.
하이퍼바이저 업그레이드
뉴타닉스 소프트웨어 업그레이드와 마찬가지로 하이퍼바이저 업그레이드는 프리즘을 통해 롤링 방식으로 완전히 자동화될 수 있다.
시작하려면 위의 비슷한 단계에 따라 “Upgrade Software” 다이얼로그 박스를 열고 'Hypervisor'를 선택한다.
그런 다음 클라우드에서 하이퍼바이저 업그레이드 버전을 다운로드하거나 수동으로 버전을 업로드할 수 있다.
 업그레이드 하이퍼바이저 – 메인 (Upgrade Hypervisor - Main)
업그레이드 하이퍼바이저 – 메인 (Upgrade Hypervisor - Main)
그런 다음 업그레이드 소프트웨어를 하이퍼바이저에 로드한다. 소프트웨어가 로드된 후 'Upgrade'를 클릭하여 업그레이드 프로세스를 시작한다.
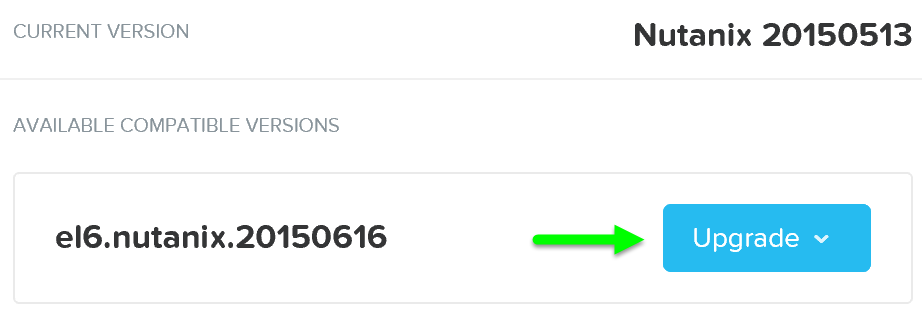 업그레이드 하이퍼바이저 – 업그레이드 정합성 체크 (Upgrade Hypervisor - Upgrade Validation)
업그레이드 하이퍼바이저 – 업그레이드 정합성 체크 (Upgrade Hypervisor - Upgrade Validation)
그러면 “확인” 다이얼로그 박스가 나타난다.
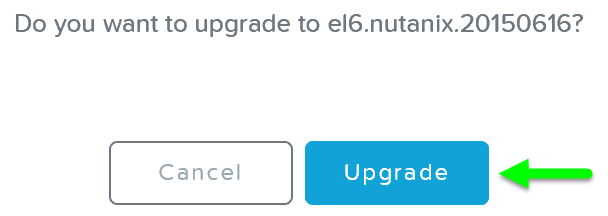 업그레이드 하이퍼바이저 – 업그레이드 확인 (Upgrade Hypervisor - Confirm Upgrade)
업그레이드 하이퍼바이저 – 업그레이드 확인 (Upgrade Hypervisor - Confirm Upgrade)
그러면 시스템은 호스트 업그레이드 사전 검사를 수행하고 하이퍼바이저 업그레이드를 클러스터에 업로드한다.
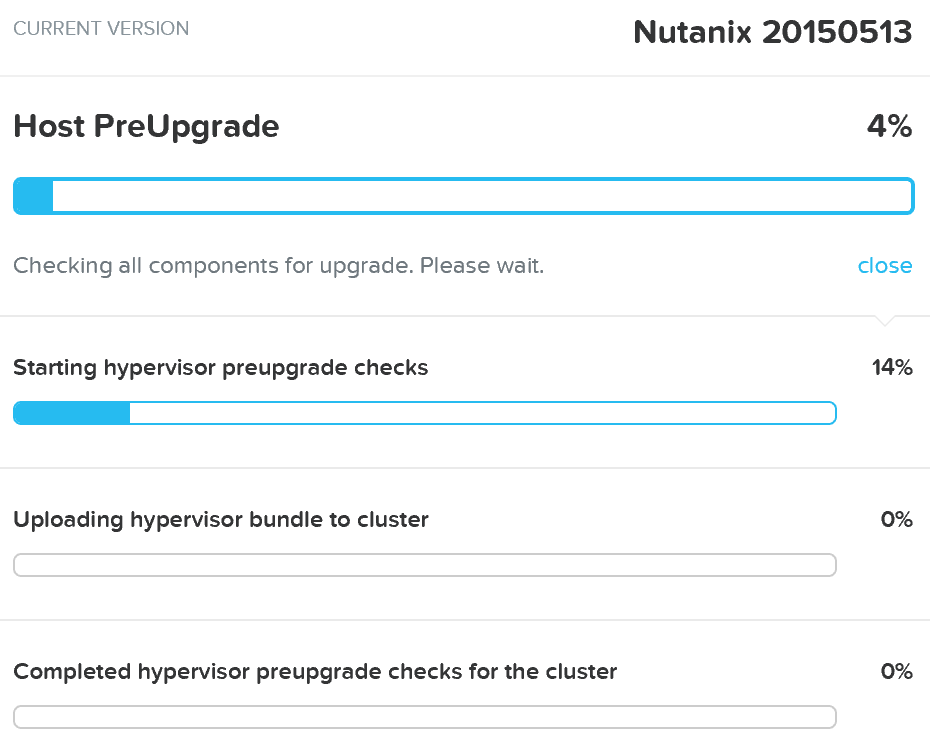 업그레이드 하이퍼바이저 – 업그레이드 사전 검사 (Upgrade Hypervisor - Pre-upgrade Checks)
업그레이드 하이퍼바이저 – 업그레이드 사전 검사 (Upgrade Hypervisor - Pre-upgrade Checks)
업그레이드 사전 검사가 완료되면 롤링 방식으로 하이퍼바이저 업그레이드가 진행된다.
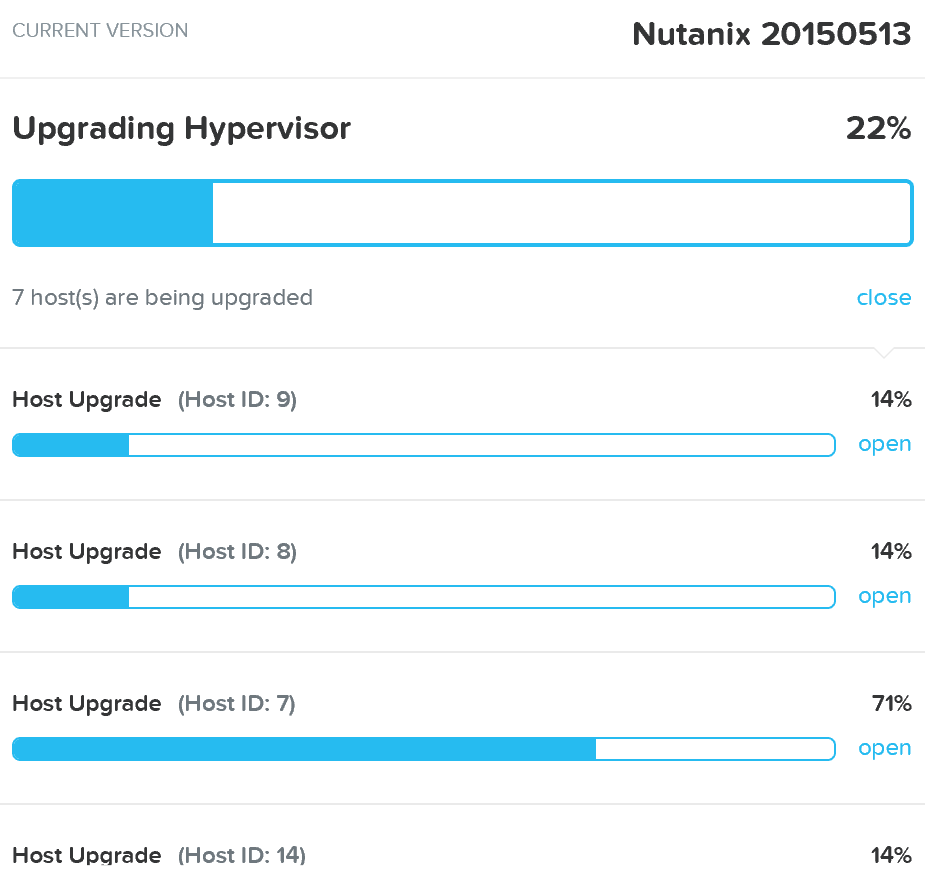 업그레이드 하이퍼바이저 – 업그레이드 작업 수행 (Upgrade Hypervisor - Execution)
업그레이드 하이퍼바이저 – 업그레이드 작업 수행 (Upgrade Hypervisor - Execution)
뉴타닉스 소프트웨어 업그레이드의 롤링 특성과 마찬가지로 각 호스트는 실행 중인 VM에 영향을 주지 않고 롤링 방식으로 업그레이드된다. VM은 현재 호스트에서 라이브 마이그레이션되고, 호스트는 업그레이드된 다음 재부팅된다. 이 프로세스는 클러스터의 모든 호스트를 업그레이드할 때까지 각 호스트에서 반복된다.
Note
Pro tip
뉴타닉스 CVM에서 “host_upgrade –-status”를 실행하여 클러스터 전체 업그레이드 상태를 확인할 수 있다. 호스트 별 상세 상태는 “~/data/logs/host_upgrade.out”에 기록된다.
업그레이드가 완료되면 업데이트된 상태가 표시되고 모든 새로운 기능에 액세스할 수 있다.
 업그레이드 하이퍼바이저 – 업그레이드 작업 완료 (Upgrade Hypervisor - Complete)
업그레이드 하이퍼바이저 – 업그레이드 작업 완료 (Upgrade Hypervisor - Complete)
클러스터 확장 (노드 추가)
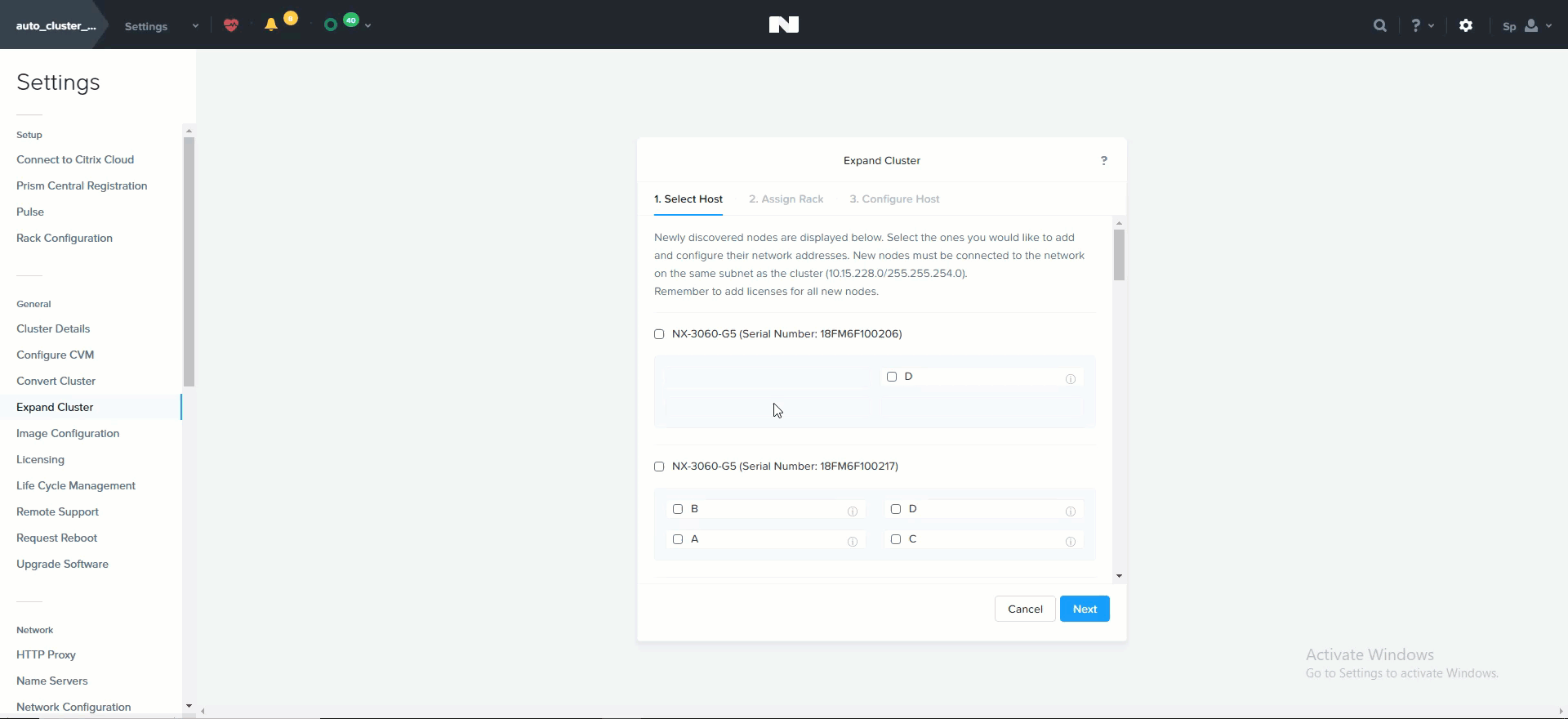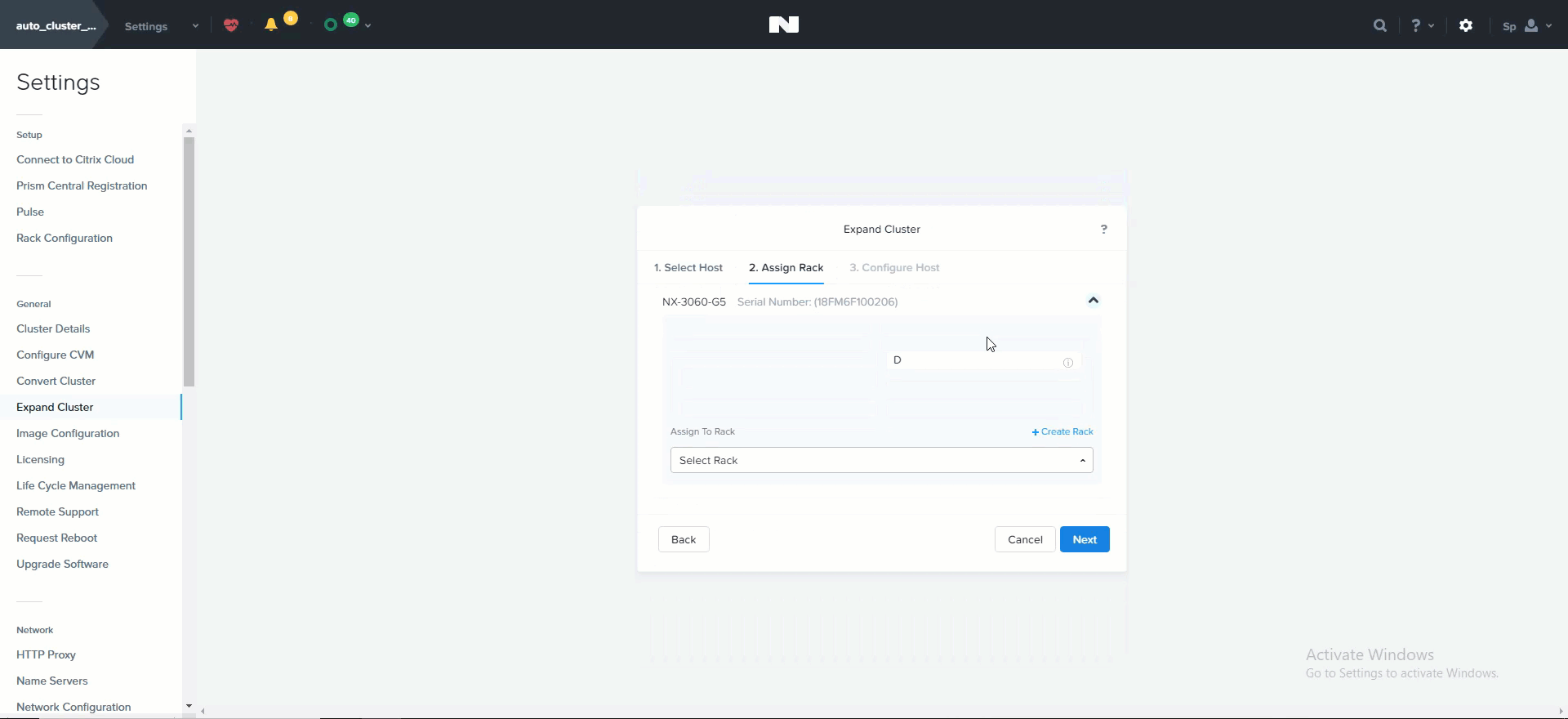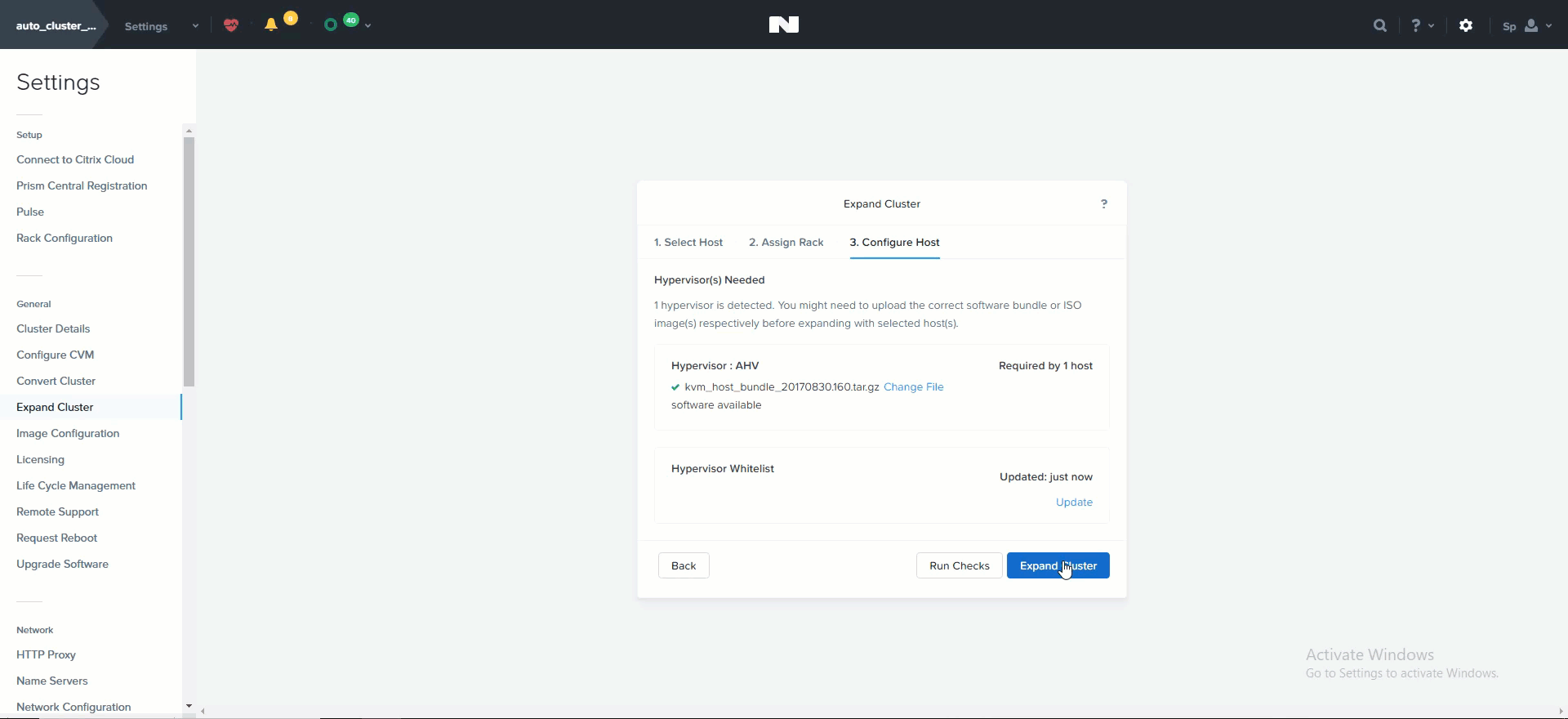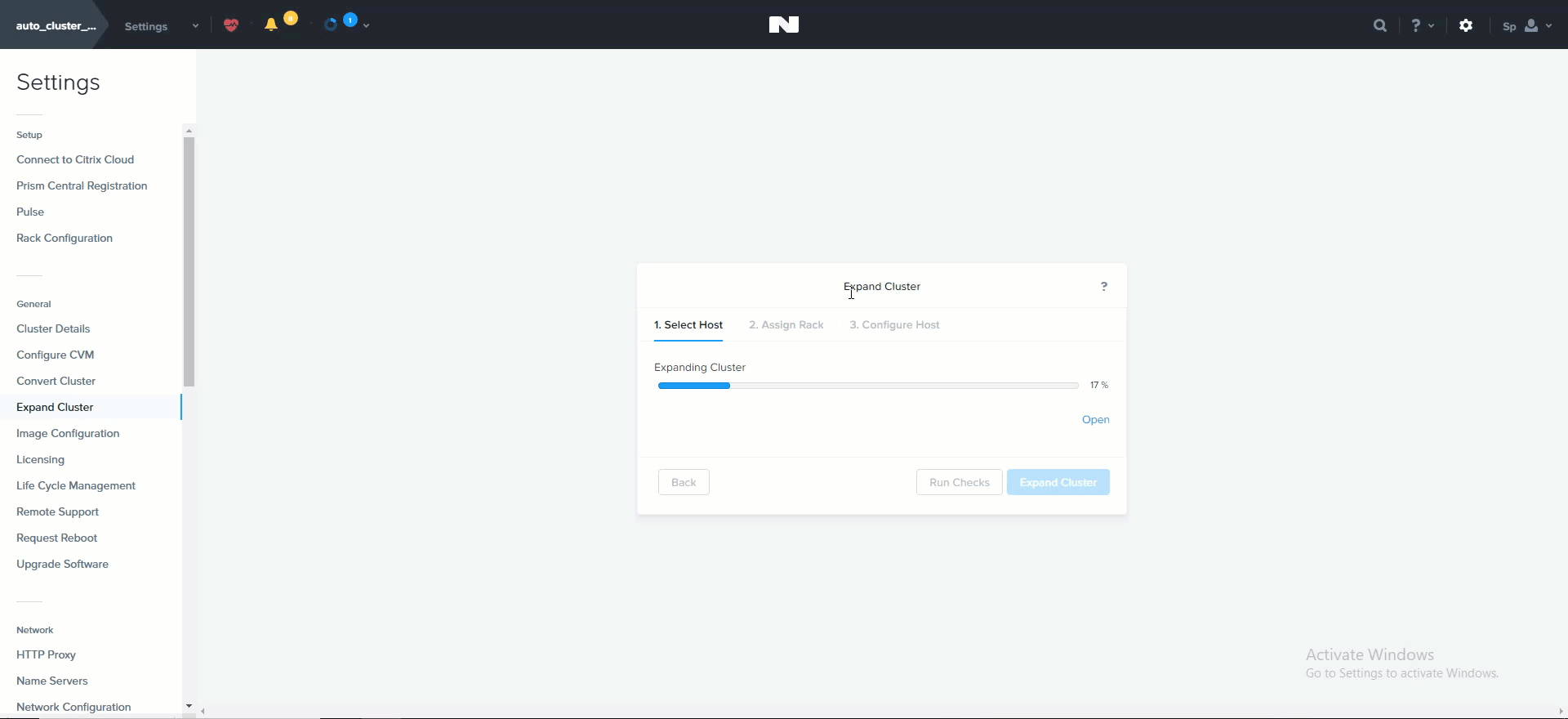 클러스터 확장 (Cluster Expansion)
클러스터 확장 (Cluster Expansion)
뉴타닉스 클러스터를 동적으로 확장할 수 있는 능력은 뉴타닉스 플랫폼의 핵심 기능이다. 뉴타닉스 클러스터를 확장하려면 노드를 랙에 장착하고 케이블을 연결한 후에 전원을 켠다. 노드 전원을 켜면 현재 클러스터는 mDNS를 사용하여 노드를 검색한다.
그림은 검색된 노드가 1개인 예제 7노드 클러스터를 보여준다.
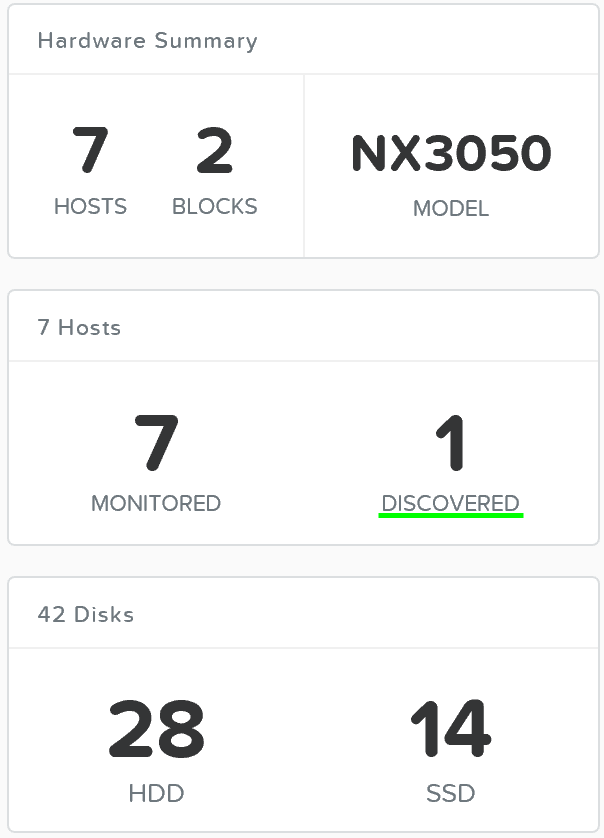 노드 추가 – 검색 (Add Node - Discovery)
노드 추가 – 검색 (Add Node - Discovery)
여러 개의 노드를 동시에 검색하여 클러스터에 추가할 수 있다.
노드가 검색되면 “Hardware” 페이지의 오른쪽 상단에서 있는 “Expand Cluster”를 클릭하여 확장을 시작할 수 있다.
 하드웨어 페이지 - 클러스터 확장 (Hardware Page - Expand Cluster)
하드웨어 페이지 - 클러스터 확장 (Hardware Page - Expand Cluster)
또한 모든 페이지에서 설정 아이콘을 클릭하여 클러스터 확장 프로세스를 시작할 수 있다.
 설정 메뉴 – 클러스터 확장 (Gear Menu - Expand Cluster)
설정 메뉴 – 클러스터 확장 (Gear Menu - Expand Cluster)
그러면 추가할 노드를 선택하고 컴포넌트의 IP 정보를 설정할 수 있는 확장 클러스터 메뉴가 시작된다.
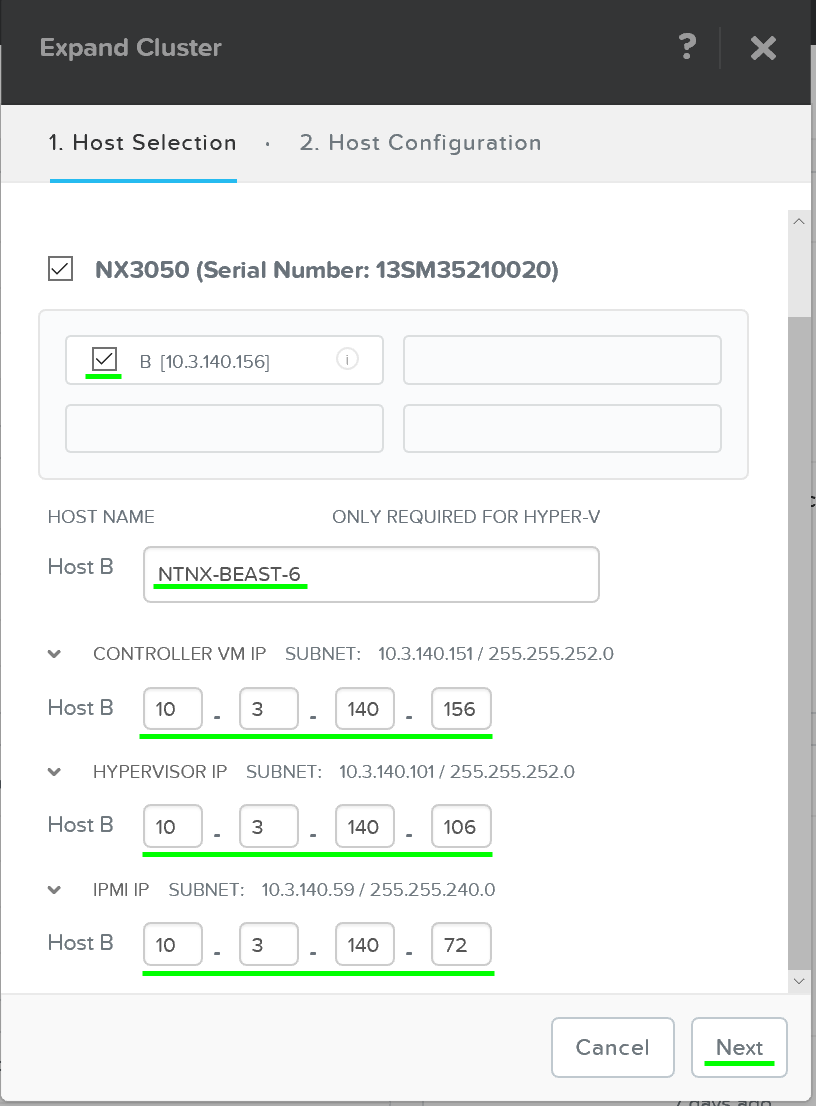 클러스터 확장 – 호스트 선택 (Expand Cluster - Host Selection)
클러스터 확장 – 호스트 선택 (Expand Cluster - Host Selection)
호스트를 선택하면 추가될 노드의 이미지를 만드는 데 사용될 하이퍼바이저 이미지를 업로드하라는 메시지가 표시된다. AHV 또는 이미지가 파운데이션 인스톨러 스토어에 이미 있는 경우에는 업로드가 필요하지 않다.
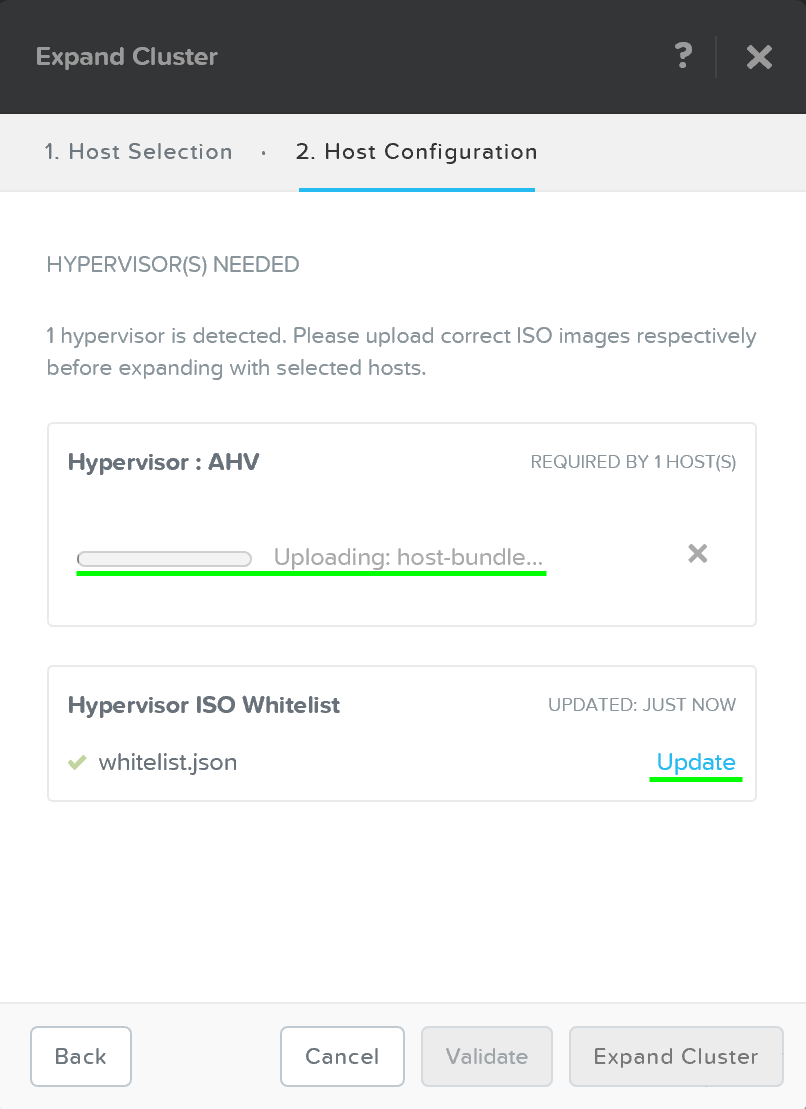 클러스터 확장 – 호스트 설정 (Expand Cluster - Host Configuration)
클러스터 확장 – 호스트 설정 (Expand Cluster - Host Configuration)
업로드가 완료되면 “Expand Cluster”를 클릭하여 이미징 및 확장 프로세스를 시작한다.
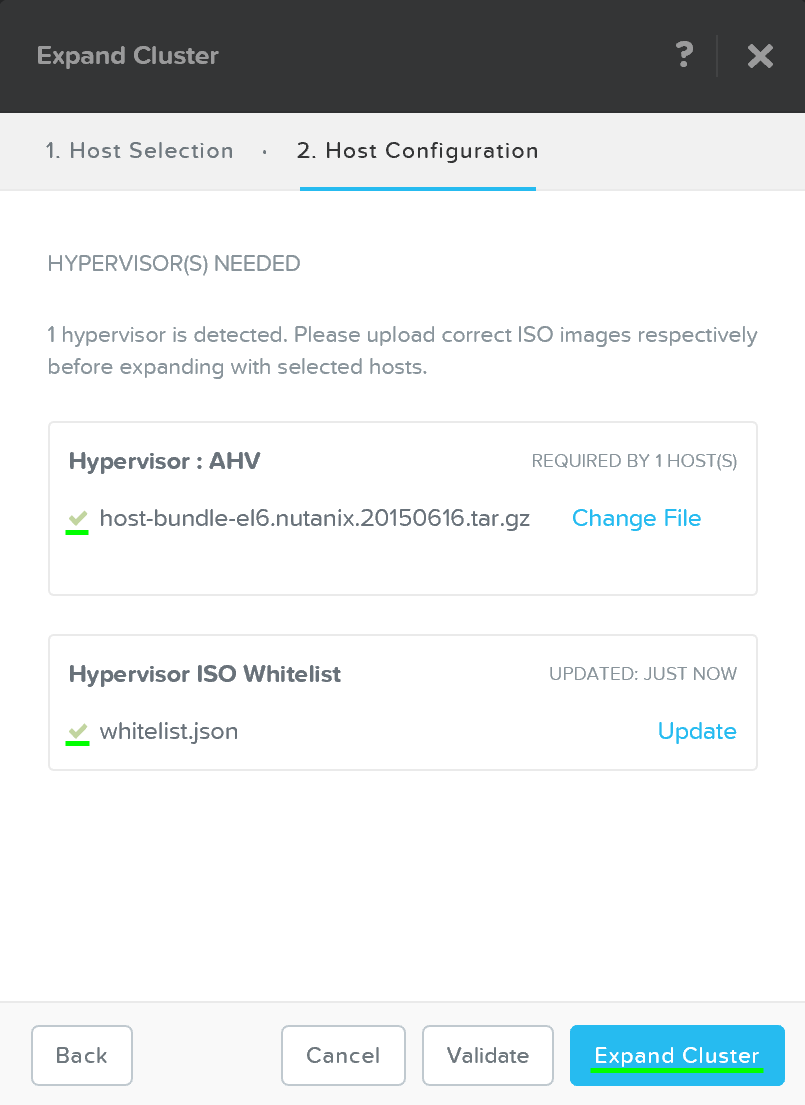 클러스터 확장 – 작업 시작 (Expand Cluster - Execution)
클러스터 확장 – 작업 시작 (Expand Cluster - Execution)
잡(Job)이 제출되고 해당 태스크 아이템이 나타난다.
 클러스터 확장 – 작업 수행 (Expand Cluster - Execution)
클러스터 확장 – 작업 수행 (Expand Cluster - Execution)
자세한 태스크 상태는 태스크를 확장하여 볼 수 있다.
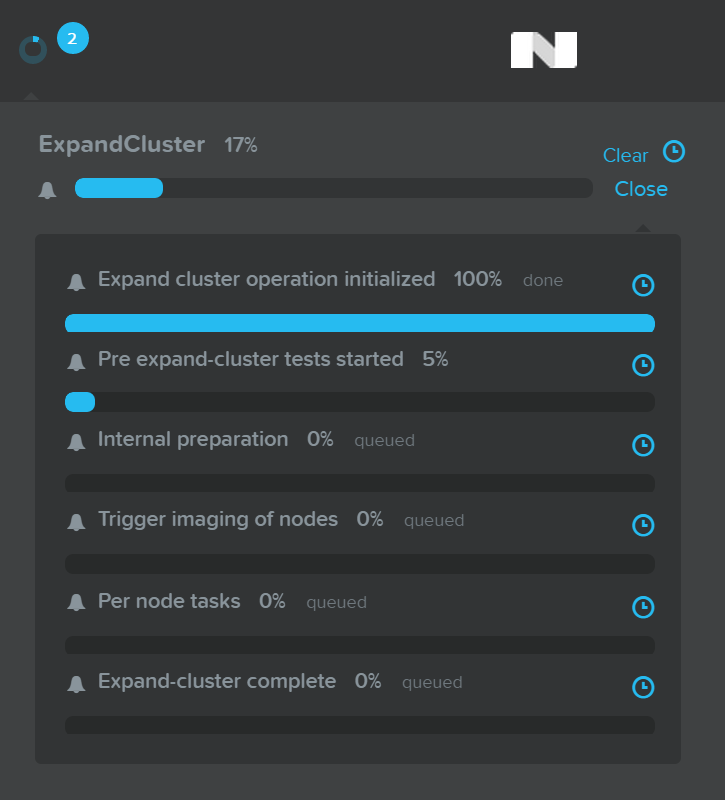 클러스터 확장 – 상세 작업 상태 (Expand Cluster - Execution)
클러스터 확장 – 상세 작업 상태 (Expand Cluster - Execution)
이미징 및 노드 추가 프로세스가 완료되면 업데이트된 클러스터 크기와 자원을 확인할 수 있다.
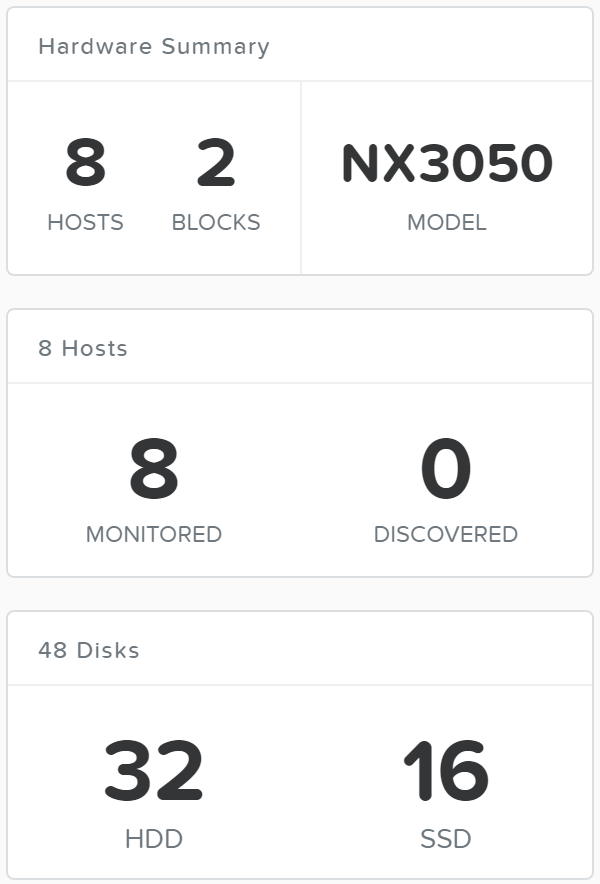 클러스터 확장 – 노드 추가 작업 완료 (Expand Cluster - Execution)
클러스터 확장 – 노드 추가 작업 완료 (Expand Cluster - Execution)
I/O 메트릭스
병목현상을 파악하는 것은 성능 문제 해결 프로세스의 매우 중요한 부분이다. 이 프로세스를 돕기 위해 뉴타닉스는 VM 페이지에 "I/O 메트릭스(I/O Metrics)" 섹션을 도입했다.
레이턴시는 여러 변수(큐 깊이, I/O 크기, 시스템 조건, 네트워크 속도 등)에 따라 달라진다. 이 페이지는 I/O 크기, 레이턴시, 소스 및 패턴에 대한 통찰력을 제공하는 것을 목표로 한다.
새로운 섹션을 사용하려면 VM 페이지로 이동하여 테이블에서 원하는 VM을 선택한다. 여기에서 높은 수준의 사용량 메트릭스를 확인할 수 있다.
 VM 페이지 - 상세 (VM Page - Details)
VM 페이지 - 상세 (VM Page - Details)
'I/O Metrics' 탭은 테이블 아래 섹션에서 찾을 수 있다.
 VM 페이지 - I/O 메트릭스 탭 (VM Page - I/O Metrics Tab)
VM 페이지 - I/O 메트릭스 탭 (VM Page - I/O Metrics Tab)
'I/O Metrics' 탭을 선택하면 상세 뷰가 표시된다. 본 섹션에서 이 페이지를 세분화하고 그것을 어떻게 사용하는지를 설명한다.
첫 번째 뷰는 지난 3시간 동안의 평균 레이턴시를 보여주는 “Avg I/O Latency” 섹션이다. 기본적으로 가장 최근에 보고된 값이 해당 시점에 상응하는 세부 메트릭스와 함께 표시된다.
플롯 위로 마우스를 가져가면 과거 레이턴시 값을 볼 수 있고 플롯의 시간을 클릭하여 아래와 같은 세부 메트릭스를 볼 수 있다.
 I/O 메트릭스 - 레이턴시 플롯 (I/O Metrics - Latency Plot)
I/O 메트릭스 - 레이턴시 플롯 (I/O Metrics - Latency Plot)
이것은 갑작스러운 스파이크가 보일 때 유용할 수 있다. 스파이크가 보이고 추가 조사가 필요하면 스파이크를 클릭하고 아래의 세부 정보를 분석한다.
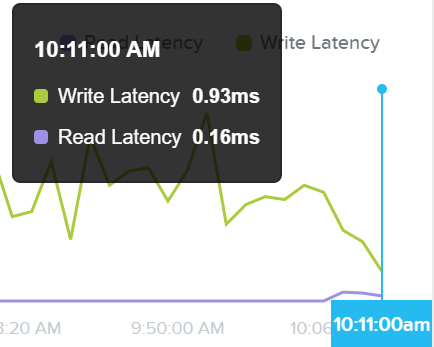 I/O 메트릭스 - 레이턴시 플롯 (I/O Metrics - Latency Plot)
I/O 메트릭스 - 레이턴시 플롯 (I/O Metrics - Latency Plot)
레이턴시가 모두 정상이면 추가 분석을 진행할 필요가 없다.
다음 섹션은 읽기 및 쓰기 I/O에 대한 I/O 크기 막대 그래프를 보여준다.
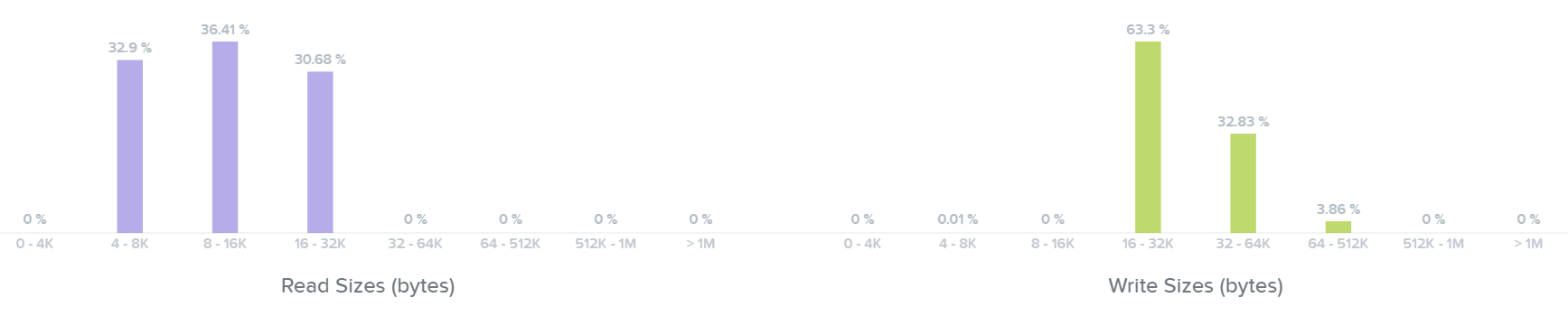 I/O 메트릭스 - I/O 크기 막대 그래프 (I/O Metrics - I/O Size histogram)
I/O 메트릭스 - I/O 크기 막대 그래프 (I/O Metrics - I/O Size histogram)
여기에서 읽기 I/O 범위가 크기 기준으로 4K에서 32K까지인 것을 볼 수 있다.
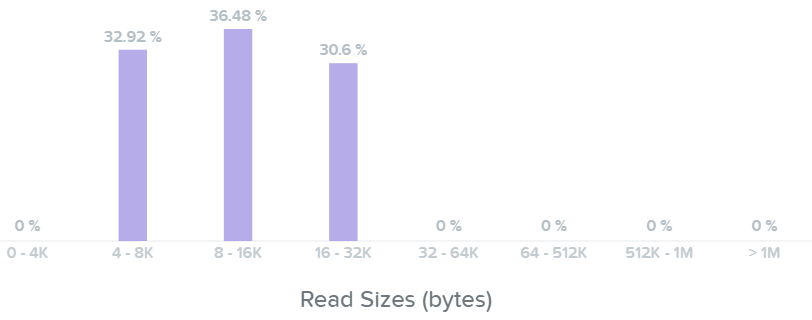 I/O 메트릭스 - 읽기 I/O 크기 막대 그래프 (I/O Metrics - Read I/O Size histogram)
I/O 메트릭스 - 읽기 I/O 크기 막대 그래프 (I/O Metrics - Read I/O Size histogram)
여기에서 쓰기 I/O 범위가 크기 기준으로 16K에서 64K까지이며 최대 512K까지인 것을 볼 수 있다.
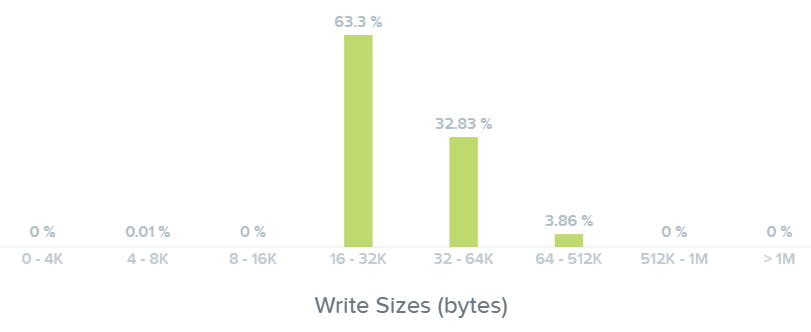 I/O 메트릭스 - 쓰기 I/O 크기 막대 그래프 (I/O Metrics - Write I/O Size histogram)
I/O 메트릭스 - 쓰기 I/O 크기 막대 그래프 (I/O Metrics - Write I/O Size histogram)
Note
Pro tip
레이턴시에서 스파이크를 보았을 때 첫 번째로 확인해야 할 것은 I/O 크기이다. 일반적으로 큰 I/O(64K~1MB)가 작은 I/O(4K~32K) 보다 레이턴시가 더 높다.
다음 섹션에서는 읽기 및 쓰기 I/O에 대한 I/O 레이턴시 막대 그래프를 보여준다.
 I/O 메트릭스 – 레이턴시 막대 그래프 (I/O Metrics - Latency histogram)
I/O 메트릭스 – 레이턴시 막대 그래프 (I/O Metrics - Latency histogram)
읽기 레이턴시 막대 그래프를 보면 대부분의 읽기 I/O가 최대 2~5ms 이하의 sub-ms(<1ms)인 것을 볼 수 있다.
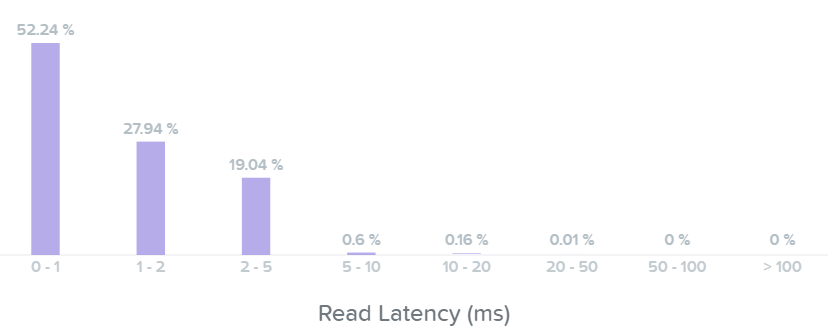 I/O 메트릭스 – 읽기 레이턴시 막대 그래프 (I/O Metrics - Read Latency histogram)
I/O 메트릭스 – 읽기 레이턴시 막대 그래프 (I/O Metrics - Read Latency histogram)
아래의 "읽기 소스"를 살펴보면 대부분의 I/O가 SSD 계층에서 서비스되는 것을 볼 수 있다.
 I/O 메트릭스 - SSD에서 읽기 (I/O Metrics - Read Source SSD)
I/O 메트릭스 - SSD에서 읽기 (I/O Metrics - Read Source SSD)
데이터가 읽힐 때 데이터는 실시간으로 유니파이드 캐시로 적재된다 (“I/O 경로 및 캐시” 섹션 참조). 여기에서 데이터가 캐시에 저장되어 있고 DRAM에서 서비스되는 것을 볼 수 있다.
 I/O 메트릭스 - DRAM에서 읽기 (I/O Metrics - Read Source DRAM)
I/O 메트릭스 - DRAM에서 읽기 (I/O Metrics - Read Source DRAM)
기본적으로 모든 읽기 I/O 레이턴시가 sub-ms(< 1ms)인 것을 볼 수 있다.
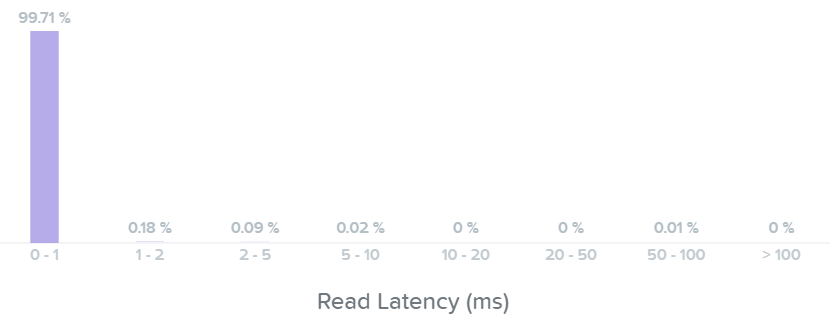 I/O 메트릭스 - 읽기 레이턴시 막대 그래프 (I/O Metrics - Read Latency histogram)
I/O 메트릭스 - 읽기 레이턴시 막대 그래프 (I/O Metrics - Read Latency histogram)
여기에서 대부분의 쓰기 I/O 레이턴시가 1~2ms인 것을 볼 수 있다.
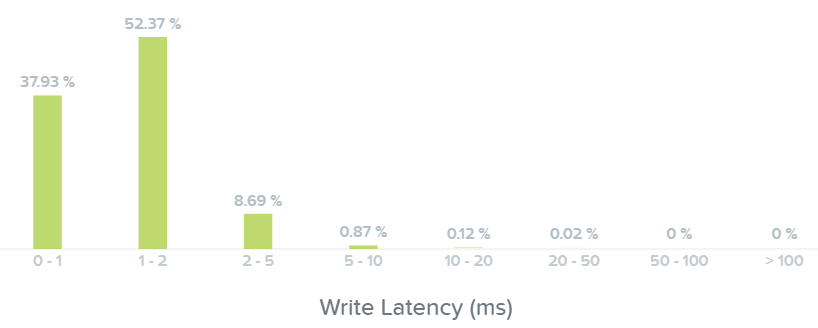 I/O 메트릭스 - 쓰기 레이턴시 막대 그래프 (I/O Metrics - Write Latency histogram)
I/O 메트릭스 - 쓰기 레이턴시 막대 그래프 (I/O Metrics - Write Latency histogram)
Note
Pro tip
읽기 레이턴시에서 스파이크가 보이고 I/O 크기가 크지 않다면 읽기 I/O가 어디에서 서비스되고 있는지를 확인하여야 한다. HDD에서 초기 읽기는 DRAM 캐시보다 레이턴시가 높지만 캐시에 저장된 이후의 모든 읽기는 DRAM에서 서비스되므로 레이턴시가 향상된 것을 볼 수 있다.
마지막 섹션에서는 I/O 패턴과 랜덤 대 순차가 얼마나 되는지를 보여준다.
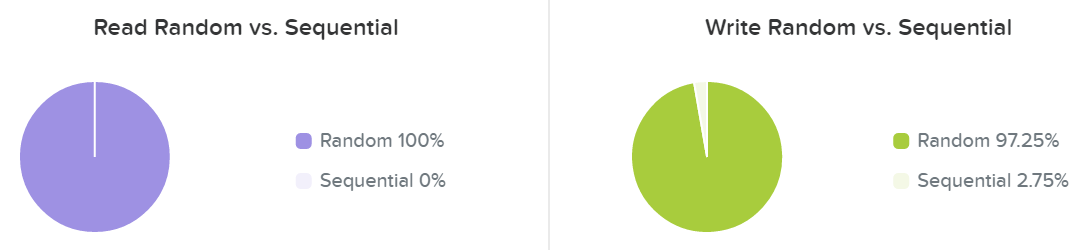 I/O 메트릭스 – RW 랜덤 데이터 vs 순차 데이터 (I/O Metrics - RW Random vs. Sequential)
I/O 메트릭스 – RW 랜덤 데이터 vs 순차 데이터 (I/O Metrics - RW Random vs. Sequential)
일반적으로 I/O 패턴은 애플리케이션 또는 워크로드에 따라 다르다 (e.g. VDI는 주로 랜덤 데이터인 반면에 하둡은 기본적으로 순차 데이터임). 다른 워크로드는 두 가지가 혼합되어 있다. 예를 들어 데이터베이스에서 입력 및 일부 조회는 랜덤일 수 있지만 ETL 중에는 순차이다.
용량 계획
자세한 용량 계획 세부 정보를 얻으려면 프리즘 센트럴의 'Cluster Runway' 섹션에서 특정 클러스터를 클릭하면 자세한 내용을 불 수 있다.
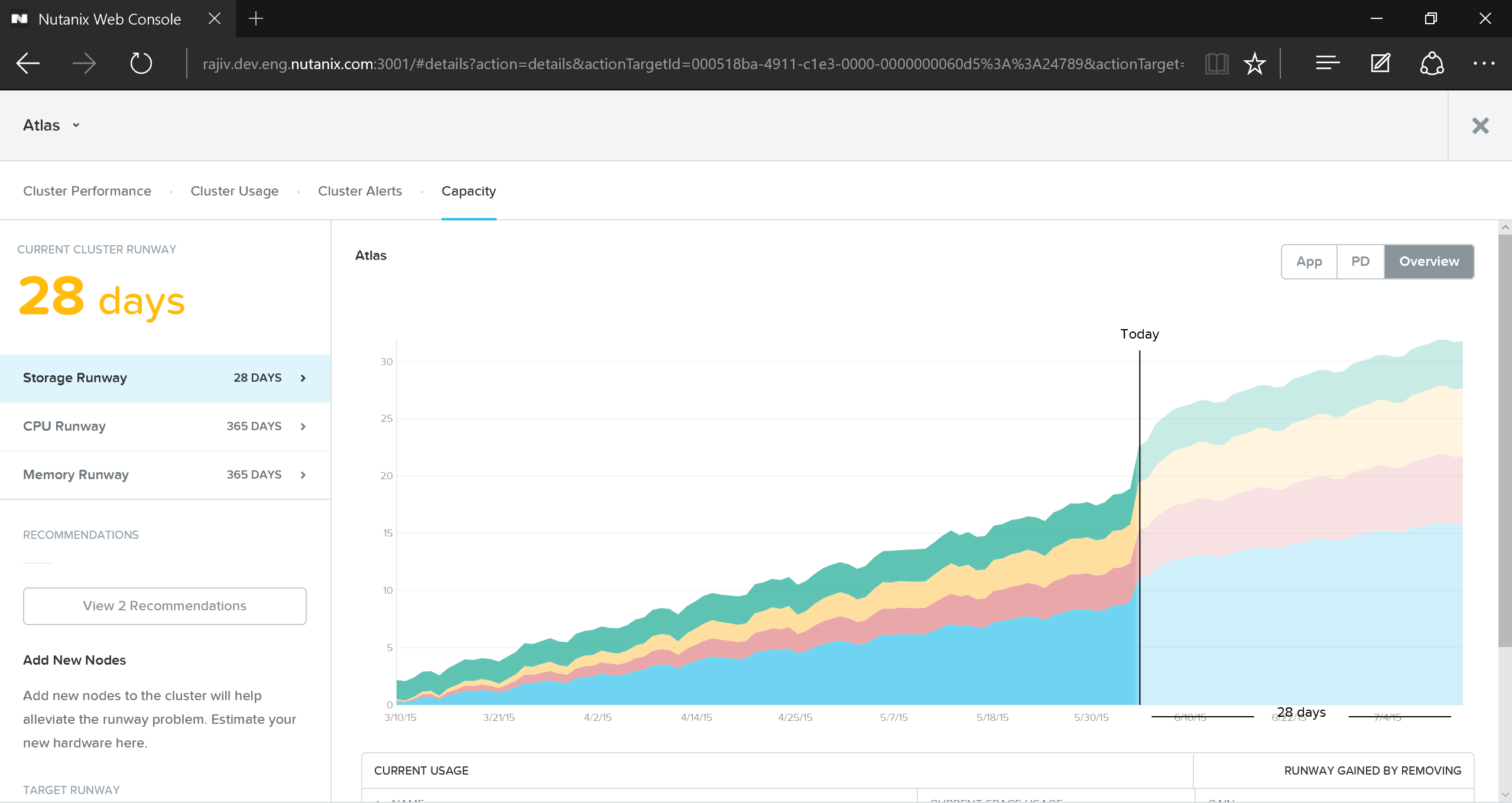 프리즘 센트럴 – 용량 계획 (Prism Central - Capacity Planning)
프리즘 센트럴 – 용량 계획 (Prism Central - Capacity Planning)
이 뷰는 클러스터 런웨이에 대한 자세한 정보를 제공하며 가장 제약된 자원(제한 자원)을 식별한다. 또한 상위 자원 소비자가 무엇인지에 대한 자세한 정보는 물론 클러스터 확장을 위한 추가 용량 또는 이상적인 노드 유형을 정리할 수 있는 몇 가지 잠재적 옵션을 얻을 수 있다.
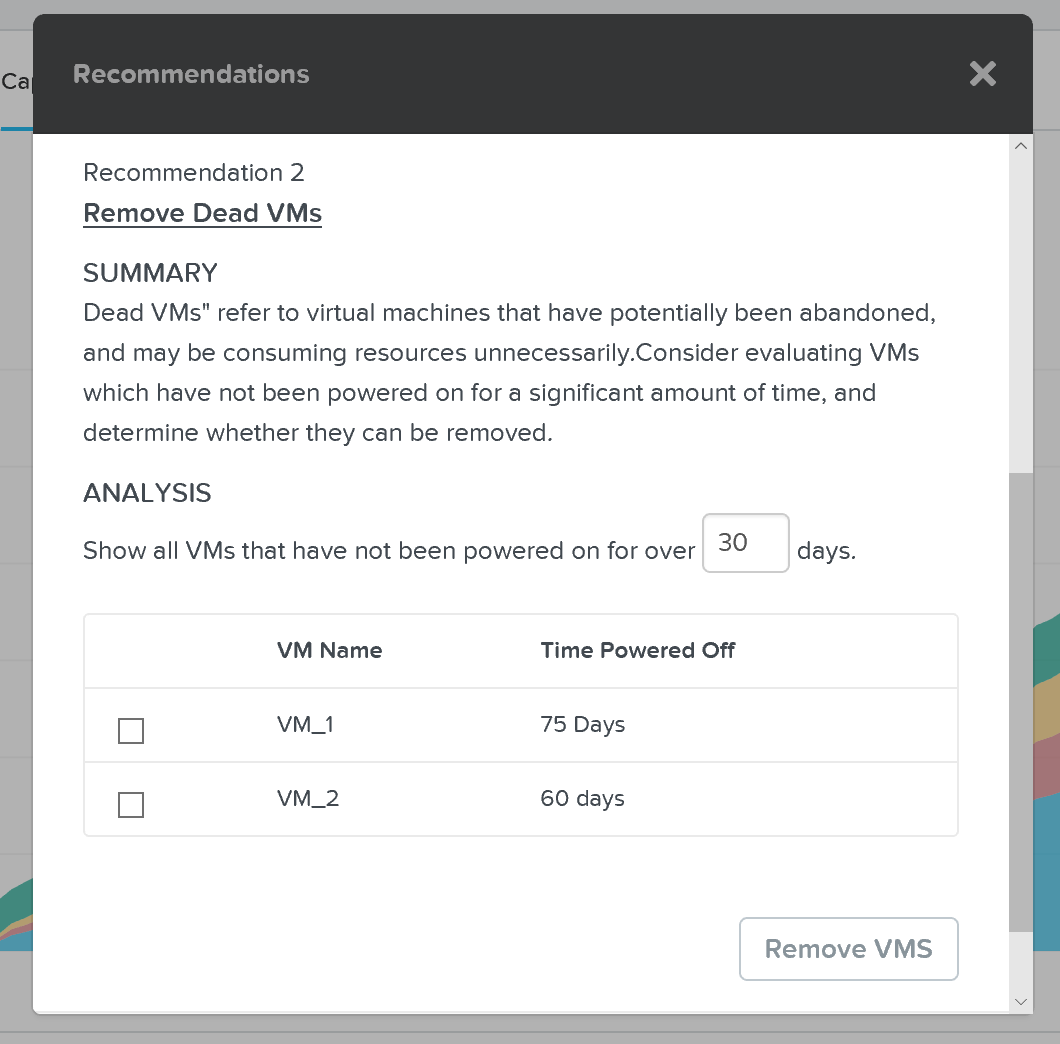 프리즘 센트럴 – 용량 계획 – 권고 사항 (Prism Central - Capacity Planning - Recommendations)
프리즘 센트럴 – 용량 계획 – 권고 사항 (Prism Central - Capacity Planning - Recommendations)
X-Play
우리가 일상 활동에 대해 생각할 때, 우리가 자동화를 많이 하면 할수록 좋다. 우리는 일상생활의 반복적인 업무에서 자동화를 끊임없이 하고 있으며, 기술을 통해 다른 분야에서도 똑같이 자동화를 할 수 있다. 프리즘 프로 X-Play를 사용하면 프리즘을 통해 일반적인 활동을 자동화할 수 있다. 그러나, 제품을 설명하기 전에 먼저 우리가 하려는 일을 다루고자 한다.
이벤트 기반의 자동화는 다음과 같은 방식으로 동작한다.
event(s) → logic → action(s)
이 시나리오에는 일련의 액션을 트리거하는 일종의 이벤트(또는 캐스캐이딩 이벤트)가 발생한다. 이와 관련된 좋은 예는 IFTTT로, 이벤트를 가져 와서 일부 논리('if this then that'와 같은 방식)를 적용한 다음 액션을 수행한다.
예를 들어, 일반적으로 우리는 외출하기 전에 집의 전등을 끈다. 시스템이 모든 전등을 자동으로 끄도록 트리거하는 이벤트를 프로그래밍할 수 있다면(e.g. 외출 / 모든 전등 소등), 생활이 보다 편리해질 것이다.
이를 IT 운영 활동과 비교하면 유사한 패턴을 볼 수 있다. 이벤트가 발생하면(e.g. VM에 더 많은 디스크 공간이 필요함) 일련의 액션을 수행한다 (e.g. 티켓 생성, 스토리지 추가, 티켓 닫기 등). 이러한 반복적인 액티비티는 자동화의 가치를 극대화하고 우리가 좀 더 가치 있는 일에 집중할 수 있게 하는 아주 좋은 예이다.
X-Play를 사용하면 일련의 이벤트/경고가 발생하였을 때 시스템이 이를 가로채어 일련의 액션을 수행할 수 있다.
X-Play를 사용하려면 프리즘 센트럴의 'Operations -> Plays' 메뉴로 이동한다.
 X-Play - 내비게이션 (X-Play - Navigation)
X-Play - 내비게이션 (X-Play - Navigation)
X-Play 메인 페이지가 나타난다.
 X-Play - 플레이북 개요 (X-Play - Playbooks Overview)
X-Play - 플레이북 개요 (X-Play - Playbooks Overview)
'Get Started'를 클릭하여 현재 Plays를 보거나 새로운 Plays를 생성한다.
 X-Play - 플레이북 (X-Play - Playbooks)
X-Play - 플레이북 (X-Play - Playbooks)
여기에서 먼저 트리거를 정의하여 새로운 플레이북을 생성할 수 있다.
 X-Play - 트리거 (X-Play - Trigger)
X-Play - 트리거 (X-Play - Trigger)
다음은 사용자 정의 경고에 기반한 트리거의 예를 보여준다.
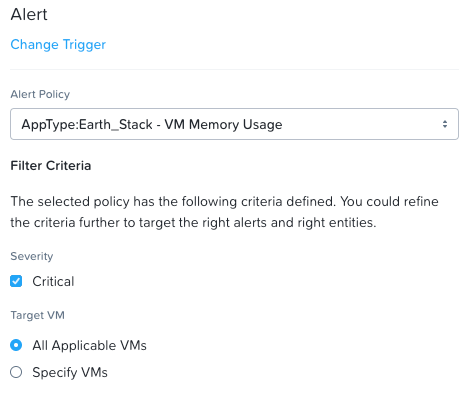 X-Play - 트리거 - 사용자 정의 경고 (X-Play - Trigger - Custom Alert)
X-Play - 트리거 - 사용자 정의 경고 (X-Play - Trigger - Custom Alert)
트리거가 정의한 후에 일련의 액션을 설정할 수 있다. 다음은 몇 가지 샘플 액션을 보여준다.
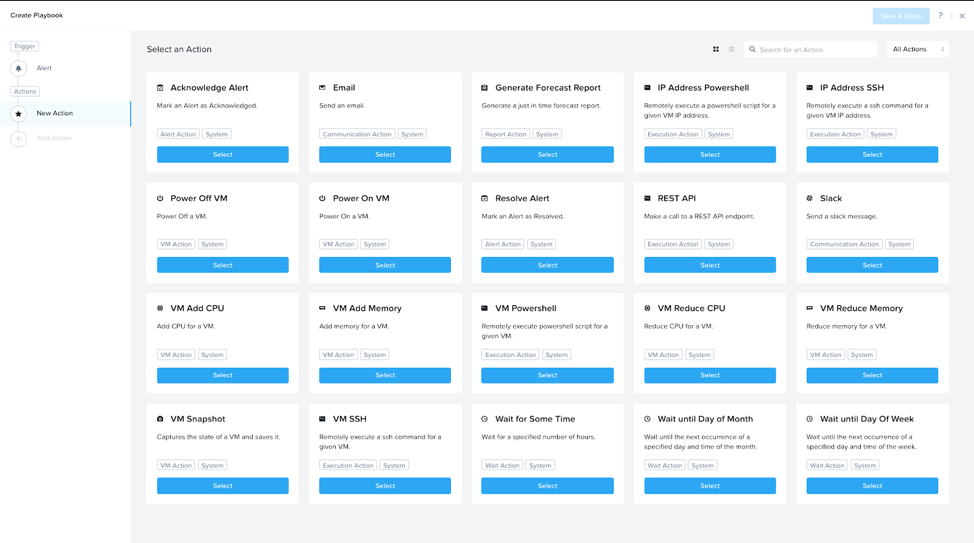 X-Play- 액션 (X-Play - Actions)
X-Play- 액션 (X-Play - Actions)
그런 다음 액션의 세부 사항을 입력한다. 다음은 샘플 REST API 호출을 보여준다.
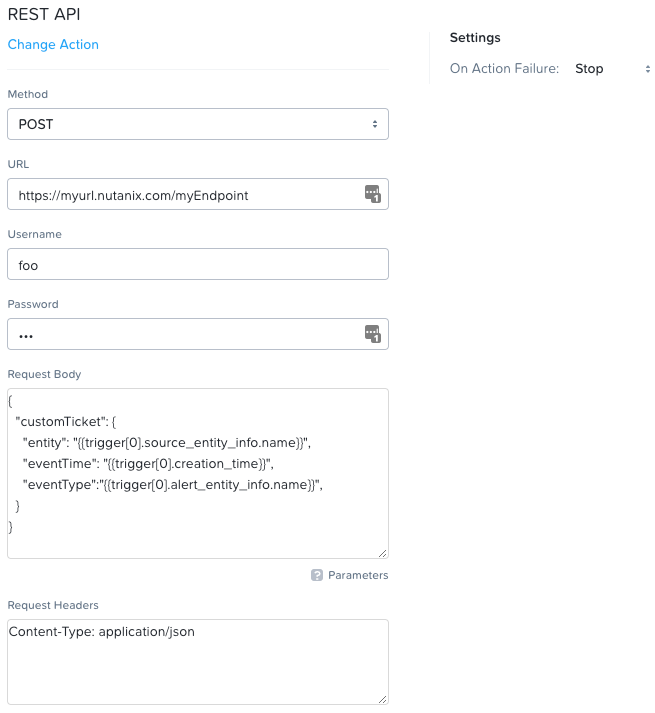 X-Play - 샘플 REST 액션 (X-Play - Sample REST Action)
X-Play - 샘플 REST 액션 (X-Play - Sample REST Action)
Note
REST API 액션 및 외부 시스템 (Actions and External Systems)
X-Play는 이메일 전송, 슬랙 메시지 전송 및 REST API 호출 수행 등과 같은 다양한 기본 작업을 제공한다.
이것은 CMDB 또는 다른 티케팅/자동화 도구와 같은 외부 시스템과의 인터페이스를 고려할 때 매우 중요하다. REST API 액션을 사용하여 티켓 생성/해결, 다른 워크플로우 시작 등을 수행할 수 있다. 이는 모든 시스템을 동기화할 수 있는 매우 강력한 옵션이다.
엔티티/이벤트 특정 세부 사항의 경우 이벤트, 엔티티 및 기타에 대한 세부 사항을 제공하는 'parameter' 변수를 사용할 수 있다.
 X-Play - 액션 파라미터 (X-Play - Action Parameters)
X-Play - 액션 파라미터 (X-Play - Action Parameters)
완료되면 Play를 저장한다. Plays는 정의된 대로 실행한다.
다음은 수행된 여러 개의 액션을 갖는 샘플 플레이를 보여준다:
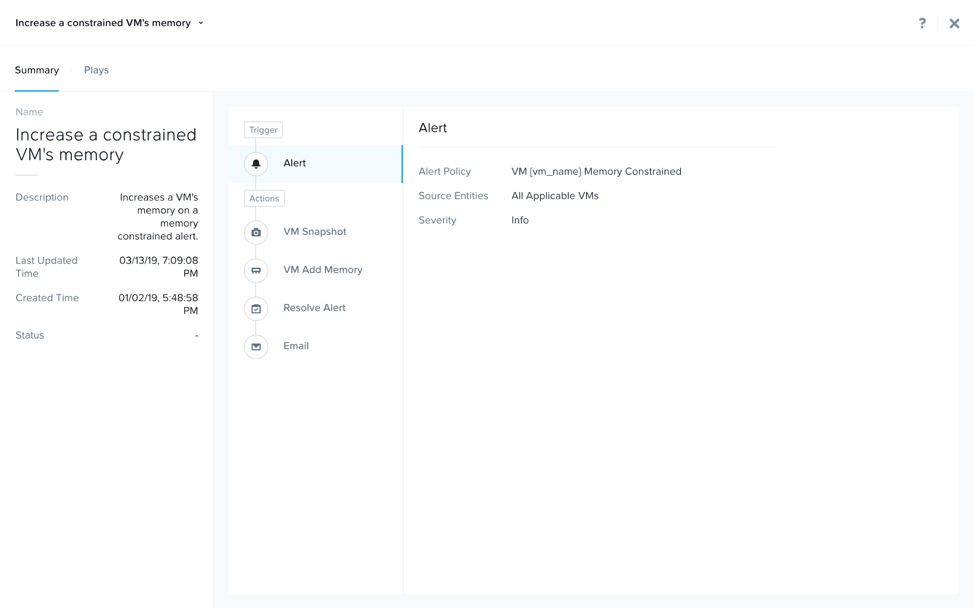 X-Play - 샘플 플래이북 (X-Play - Sample Playbook)
X-Play - 샘플 플래이북 (X-Play - Sample Playbook)
'Plays' 탭에는 Plays 실행 시간과 상태가 표시된다.
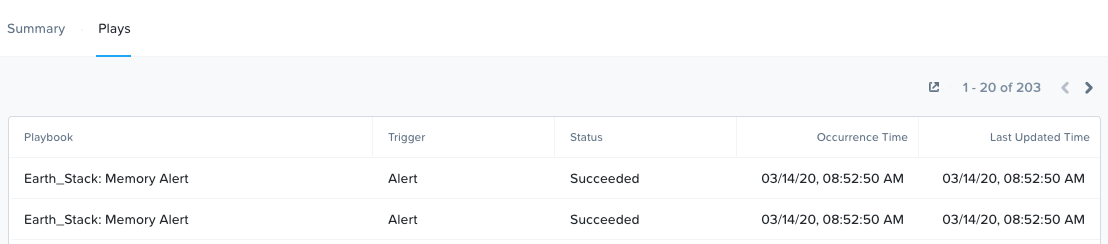 X-Play - Plays 실행 (X-Play - Plays Executed)
X-Play - Plays 실행 (X-Play - Plays Executed)
모든 것을 자동화할 수 있다는 것을 기억하세요!
APIs 및 인터페이스
HTML5 UI는 프리즘의 핵심적인 부분으로 간단하고 사용하기 쉬운 관리 인터페이스를 제공한다. 또 다른 핵심 기능은 자동화에 사용할 수 있는 API이다. 프리즘 UI에 노출된 모든 기능은 뉴타닉스 플랫폼과 프로그래밍 방식으로 인터페이스 할 수 있도록 풀 세트의 REST API를 통해 제공된다. 이를 통해 고객과 파트너는 자동화 및 3rd 파티 툴의 사용이 가능하고 자체 UI를 만들 수 있다.
동적 또는 "소프트웨어-정의" 환경의 핵심인 뉴타닉스는 간단한 프로그래밍 및 인터페이스가 가능하도록 광범위한 인터페이스를 제공한다. 메인 인터페이스는 다음과 같다.
- REST API
- CLI - ACLI & NCLI
- 스크립트 인터페이스 (Scripting interfaces)
Note
Nutanix.dev - 뉴타닉스 개발자 포탈
사용 가능한 뉴타닉스 프리즘 및 제품 API에 대해 자세히 알아보려면 샘플 코드를 검토하고 자습형 실습을 살펴보고 다음을 확인한다: https://www.nutanix.dev!
이것의 핵심은 프리즘 UI의 모든 기능과 데이터 포인트를 노출하고 오케스트레이션 또는 자동화 도구가 뉴타닉스 작업을 쉽게 수행할 수 있도록 해주는 REST API이다. 이를 통해 Saltstack, Puppet, vRealize Operations, System Center Orchestrator, Ansible 등과 같은 툴을 사용하여 뉴타닉스를 위한 사용자 정의 워크플로우를 쉽게 만들 수 있다. 또한 이것은 3rd 파티 개발자가 자체 사용자 정의 UI를 만들고 REST를 통해 뉴타닉스 데이터를 가져올 수 있다는 것을 의미한다.
다음 그림은 개발자가 API와 상호 작용하고 예상되는 데이터 포맷을 볼 수 있는 뉴타닉스 REST API Explorer의 작은 스니펫을 보여준다.
 프리즘 REST API 익스플로러 (Prism REST API Explorer)
프리즘 REST API 익스플로러 (Prism REST API Explorer)
오퍼레이션을 확장하여 REST 호출의 세부 정보 및 예제를 표시할 수 있다:
 프리즘 REST API 호출 예제 (Prism REST API Sample Call)
프리즘 REST API 호출 예제 (Prism REST API Sample Call)
Note
API 인증 스킴 (API Authentication Scheme)
AOS 4.5 버전부터 HTTPS를 통한 기본 인증이 클라이언트 및 HTTP 호출 인증에 활용된다.
ACLI
AOS CLI(ACLI)는 뉴타닉스 제품의 AOS 부분을 관리하기 위한 CLI이다. 본 기능은 AOS 4.1.2 이상의 버전에서 지원된다.
NOTE: 이러한 모든 액션은 HTML5 GUI 및 REST API를 통해 수행할 수 있다. 아래 명령들은 태스크를 자동화하는 추가적인 방법이다.
ACLI 쉘 실행
설명: ACLI 쉘로 진입 (CVM에서 동작)
acli
또는
설명: Linux 쉘에서 ACLI 명령어 실행
ACLI Command
ACLI 결과 값을 JSON 포멧으로 출력
설명: ACLI 결과 값을 JSON 포맷으로 출력
acli –o json
호스트 목록 출력
설명: 클러스터에서 AOS 노드 목록 출력
host.list
네트워크 생성
설명: VLAN 기반 네트워크 생성
net.create TYPE.ID[.VSWITCH] ip_config=A.B.C.D/NN
Example: net.create vlan.133 ip_config=10.1.1.1/24
네트워크 목록 출력
설명: 네트워크 목록 출력
net.list
DHCP 범위 생성
설명: DHCP 범위 생성
net.add_dhcp_pool NET NAME start=START IP A.B.C.D end=END IP W.X.Y.Z
Note: 만약 AOS DHCP 서버의 주소가 네트워크 생성 중에 설정되지 않는 경우에 .254는 아크로폴리스 DHCP 서버에 의해 예약되어 사용된다.
Example: net.add_dhcp_pool vlan.100 start=10.1.1.100 end=10.1.1.200
기존 네트워크 상세 정보 가져오기
설명: VM 이름 / UUID, MAC 주소 및 IP를 포함한 네트워크의 VM 및 세부 정보 가져오기
net.list_vms NETNAME
Example: net.list_vms vlan.133
네트워크에 DHCP 및 DNS 서버 설정
설명: DHCP 및 DNS 설정
net.update_dhcp_dns NETNAME servers=COMMA SEPARATED DNS IPs domains=COMMA SEPARATED DOMAINS
Example: net.set_dhcp_dns vlan.100 servers=10.1.1.1,10.1.1.2 domains=splab.com
VM 생성
설명: VM 생성
vm.create COMMA SEPARATED VM NAMES memory=NUM MEM MB num_vcpus=NUM VCPU num_cores_per_vcpu=NUM CORES ha_priority=PRIORITY INT
Example: vm.create testVM memory=2G num_vcpus=2
대량의 VM 생성
설명: 대량의 VM 생성
vm.create CLONEPREFIX[STARTING INT..END INT] memory=NUM MEM MB num_vcpus=NUM VCPU num_cores_per_vcpu=NUM CORES ha_priority=PRIORITY INT
Example: vm.create testVM[000..999] memory=2G num_vcpus=2
기존 VM으로부터 VM 복제
설명: 기존 VM으로부터 VM 복제
vm.clone CLONE NAME(S) clone_from_vm=SOURCE VM NAME
Example: vm.clone testClone clone_from_vm=MYBASEVM
기존 VM으로부터 대량의 VM 복제
설명: 기존 VM으로부터 대량의 VM 복제
vm.clone CLONEPREFIX[STARTING INT..END INT] clone_from_vm=SOURCE VM NAME
Example: vm.clone testClone[001..999] clone_from_vm=MYBASEVM
디스크를 생성하고 VM에 추가
설명: OS를 위한 디스크 생성
vm.disk_create VM NAME create_size=Size and qualifier, e.g. 500G container=CONTAINER NAME
Example: vm.disk_create testVM create_size=500G container=default
VM에 NIC 추가
설명: NIC을 생성하고 추가
vm.nic_create VM NAME network=NETWORK NAME model=MODEL
Example: vm.nic_create testVM network=vlan.100
VM의 부트 디바이스를 디스크로 설정
설명: VM 부트 디바이스 설정
지정된 디스크 ID로 부트 디바이스 설정
vm.update_boot_device VM NAME disk_addr=DISK BUS
Example: vm.update_boot_device testVM disk_addr=scsi.0
VM의 부트 디바이스를 CD-DROM으로 설정
설명: VM 부트 디바이스를 CD-ROM으로 설정
vm.update_boot_device VM NAME disk_addr=CD-ROM BUS
Example: vm.update_boot_device testVM disk_addr=ide.0
ISO를 CD-ROM에 마운트
설명: ISO를 VM의 CD-ROM으로 마운트
단계:
- ISO 이미지를 컨테이너에 업로드
- 클라이언트 IP에 대한 화이트리스트 설정
- ISO를 공유에 업로드
ISO를 갖는 CD-ROM 생성
vm.disk_create VM NAME clone_nfs_file=PATH TO ISO CD-ROM=true
Example: vm.disk_create testVM clone_nfs_file=/default/ISOs/myfile.iso CD-ROM=true
만약 CD-ROM을 이미 생성하였다면 ISO만 마운트
vm.disk_update VM NAME CD-ROM BUS clone_nfs_file=PATH TO ISO
Example: vm.disk_update atestVM1 ide.0 clone_nfs_file=/default/ISOs/myfile.iso
ISO를 CD-ROM으로부터 분리
설명: ISO를 CD-ROM으로부터 제거
vm.disk_update VM NAME CD-ROM BUS empty=true
VM의 전원 켜기
설명: VM의 전원 켜기
vm.on VM NAME(S)
Example: vm.on testVM
모든 VM의 전원 켜기
Example: vm.on *
접두사와 매칭되는 모든 VM의 전원 켜기
Example: vm.on testVM*
특정 범위 내에 있는 VM의 전원 켜기
Example: vm.on testVM[0-9][0-9]
NCLI
NOTE: 이러한 모든 액션은 HTML5 GUI 및 REST API를 통해 수행할 수 있다. 아래 명령들은 태스크를 자동화하는 추가적인 방법이다.
NFS 화이트리스트에 서브넷 추가
설명: NFS 화이트리스트에 특정 서브넷을 추가
ncli cluster add-to-nfs-whitelist ip-subnet-masks=10.2.0.0/255.255.0.0
뉴타닉스 버전 출력
설명: 뉴타닉스 소프트웨어의 현재 버전 출력
ncli cluster version
숨겨진 NCLI 옵션 출력
설명: 숨겨진 NCLI 명령어 또는 옵션 출력
ncli helpsys listall hidden=true [detailed=false|true]
스토리지 풀 목록 출력
설명: 스토리지 풀 목록 출력
ncli sp ls
컨테이너 목록 출력
설명: 컨테이너 목록 출력
ncli ctr ls
컨테이너 생성
설명: 새로운 컨테이너 생성
ncli ctr create name=NAME sp-name=SP NAME
VM 목록 출력
설명: VM 목록 출력
ncli vm ls
퍼블릭 키 목록 출력
설명: 기존에 등록되어 있는 퍼블릭 키 목록 출력
ncli cluster list-public-keys
퍼블릭 키 추가
설명: 클라이언트 액세스를 위한 퍼블릭 키 추가
퍼블릭 키를 CVM으로 복사
퍼블릭 키를 클러스터에 추가
ncli cluster add-public-key name=myPK file-path=~/mykey.pub
퍼블릭 키 제거
설명: 클라이언트 액세스를 위한 퍼블릭 키 제거
ncli cluster remove-public-keys name=myPK
보호 도메인 생성
설명: PD(Protection Domain) 생성
ncli pd create name=NAME
원격 사이트 생성
설명: 복제를 위한 원격 사이트 생성
ncli remote-site create name=NAME address-list=Remote Cluster IP
컨테이너의 모든 VM을 위한 PD 생성
설명: 컨테이너에 존재하는 모든 VM을 보호
ncli pd protect name=PD NAME ctr-id=Container ID cg-name=NAME
지정된 VM을 갖는 PD 생성
설명: 지정된 VM 보호
ncli pd protect name=PD NAME vm-names=VM Name(s) cg-name=NAME
DSF 파일(vDisk로 알려진)를 위한 PD 생성
설명: 지정된 DSF 파일 보호
ncli pd protect name=PD NAME files=File Name(s) cg-name=NAME
PD 스냅샷 생성
설명: PD의 One-Time 스냅샷 생성
ncli pd add-one-time-snapshot name=PD NAME retention-time=seconds
원격 사이트로 스냅샷 및 복제 스케줄 생성
설명: 스냅샷을 생성하고, n개의 원격 사이트로의 복제 스케줄 생성
ncli pd set-schedule name=PD NAME interval=seconds retention-policy=POLICY remote-sites=REMOTE SITE NAME
복제 상태 출력
설명: 복제 상태 모니터링
ncli pd list-replication-status
PD를 원격 사이트로 마이그레이션
설명: PD를 원격 사이트로 페일오버
ncli pd migrate name=PD NAME remote-site=REMOTE SITE NAME
PD 활성화
설명: 원격 사이트에서 PD 활성화
ncli pd activate name=PD NAME
DSF 쉐도우 클론 활성화
설명: DSF 쉐도우 클론 기능 활성화
ncli cluster edit-params enable-shadow-clones=true
vDisk의 데이터 중복제거 활성화
설명: 데이터 중복제거 활성화 및 특정 vDisk에 대한 On-Disk 데이터 중복제거 활성화k
ncli vdisk edit name=VDISK NAME fingerprint-on-write=true/false on-disk-dedup=true/false
클러스터 리질리언시 상태 체크
# 노드 상태 (Node status) ncli cluster get-domain-fault-tolerance-status type=node
# 블록 상태 (Block status) ncli cluster get-domain-fault-tolerance-status type=rackable_unit
PowerShell CMDlets
아래에서 뉴타닉스 PowerShell CMDlets, 사용 방법 및 Windows PowerShell의 몇 가지 일반적인 배경에 대해 다룬다.
기본 설명
윈도우즈 PowerShell은 .NET 프레임워크 기반의 강력한 쉘 및 스크립트 언어이다. 언어를 사용하기가 매우 간단하며 직관적인 인터액티브 방식으로 제작되었다. PowerShell에는 몇 가지 주요 컨스트럭트/아이템이 있다.
CMDlets
CMDlets은 특정 오퍼레이션을 수행하는 명령 또는 .NET 클래스이다. 이들은 대개 Getter/Setter 방법론을 따르며 일반적으로 <Verb>-<Noun> 기반 구조를 사용한다. 예를 들어 Get-Process, Set-Partition 등과 같다.
파이핑 또는 파이프라이닝 (Piping or Pipelining)
파이핑(Piping)은 PowerShell에서 매우 중요한 컨스트럭트로(Linux에서 사용하는 것과 유사) 정확하게 사용하면 작업을 크게 단순화할 수 있다. 파이핑을 사용하면 기본적으로 파이프라인의 한 섹션의 결과를 파이프라인의 다음 섹션의 입력으로 사용할 수 있다. 파이프라인은 필요한 만큼 길어질 수 있다 (파이프의 다음 섹션으로 공급되는 출력이 남아 있다고 가정). 아주 간단한 예제는 현재 프로세스를 가져와서 특정 특성이나 필터와 일치하는 프로세스를 찾아서 정렬하는 것이다.
Get-Service | where {$_.Status -eq "Running"} | Sort-Object Name
for-each 대신에 파이핑을 사용할 수 있다. 예를 들면 다음과 같다.
# For each item in my array
$myArray | %{
# Do something
}
주요 오브젝트 유형 (Key Object Types)
다음은 PowerShell의 주요 오브젝트 유형의 일부이다. getType() 메소드를 사용하여 오브젝트 유형을 쉽게 얻을 수 있다. 예를 들어 $someVariable.getType()은 오브젝트 유형을 반환한다.
변수 (Variable)
$myVariable = "foo"
Note: 변수를 일련의 명령 또는 명령 파이프라인의 출력으로 설정할 수 있다:
$myVar2 = (Get-Process | where {$_.Status -eq "Running})
이 예제에서 괄호 안의 명령이 먼저 수행되고 그 결과가 변수에 저장된다.
배열 (Array)
$myArray = @("Value","Value")
Note: 배열, 해시 테이블 또는 사용자 정의 오브젝트의 배열을 가질 수 있다.
해시 테이블 (Hash Table)
$myHash = @{"Key" = "Value";"Key" = "Value"}
유용한 명령
특정 CMDlet에 대한 도움말 내용 가져오기 (Linux에서 man 페이지와 유사).
Get-Help CMDlet Name
Example: Get-Help Get-Process
명령 또는 오브젝트의 속성 및 메소드를 나열한다.
Some expression or object | Get-Member
Example: $someObject | Get-Member
핵심 뉴타닉스 CMDlets 및 사용법
뉴타닉스 CMDlets은 프리즘 UI(AOS 4.0.1 이상의 버전)에서 직접 다운로드할 수 있으며 오른쪽 상단의 드롭-다운 메뉴에서 찾을 수 있다.
 프리즘 CMDlets 인스톨러 링크 (Prism CMDlets Installer Link)
프리즘 CMDlets 인스톨러 링크 (Prism CMDlets Installer Link)
뉴타닉스 Snappin 로드
Snappin이 로드되어 있는지 확인하고 그렇지 않으면 로드한다.
if ( (Get-PSSnapin -Name NutanixCmdletsPSSnapin -ErrorAction SilentlyContinue) -eq $null )
{
Add-PsSnapin NutanixCmdletsPSSnapin
}
뉴타닉스 CMDlets 목록 출력
Get-Command | Where-Object{$_.PSSnapin.Name -eq "NutanixCmdletsPSSnapin"}
뉴타닉스 클러스터에 연결
Connect-NutanixCluster -Server $server -UserName "myuser" -Password (Read-Host "Password: " -AsSecureString) -AcceptInvalidSSLCerts
특정 검색 문자열과 일치하는 뉴타닉스 VM 가져오기
Set to variable
$searchString = "myVM"
$vms = Get-NTNXVM | where {$_.vmName -match $searchString}
Interactive
Get-NTNXVM | where {$_.vmName -match "myString"}
Interactive and formatted
Get-NTNXVM | where {$_.vmName -match "myString"} | ft
뉴타닉스 vDisk 가져오기
Set to variable
$vdisks = Get-NTNXVDisk
Interactive
Get-NTNXVDisk
Interactive and formatted
Get-NTNXVDisk | ft
뉴타닉스 컨테이너 가져오기
Set to variable
$containers = Get-NTNXContainer
Interactive
Get-NTNXContainer
Interactive and formatted
Get-NTNXContainer | ft
뉴타닉스 PD 가져오기
Set to variable
$pds = Get-NTNXProtectionDomain
Interactive
Get-NTNXProtectionDomain
Interactive and formatted
Get-NTNXProtectionDomain | ft
뉴타닉스 컨시스턴시 그룹 가져오기
Set to variable
$cgs = Get-NTNXProtectionDomainConsistencyGroup
Interactive
Get-NTNXProtectionDomainConsistencyGroup
Interactive and formatted
Get-NTNXProtectionDomainConsistencyGroup | ft
리소스 및 스크립트:
- Nutanix Github - https://github.com/nutanix
- NutanixDev Github - https://github.com/nutanixdev
- NutanixDev Code Samples - https://github.com/nutanixdev/code-samples
- nutanix.dev blog - https://www.nutanix.dev/blog/
Disclaimer: All code samples are © Nutanix, Inc., and are provided as-is under the MIT license (https://opensource.org/licenses/MIT).
Book of AOS
a·crop·o·lis - /ɘ ‘ kräpɘlis/ - noun - data plane
스토리지, 컴퓨트 및 가상화 플랫폼.
AOS(Acropolis Operating System)는 하이퍼바이저(온-프레미스 또는 클라우드에서 실행)와 실행 중인 워크로드 간의 추상화 계층을 제공하는 핵심 소프트웨어 스택이다. 스토리지 서비스, 보안, 백업 및 재해 복구 등과 같은 기능을 제공한다. 본 BOOK에서는 AOS의 아키텍처 및 기능을 설명한다.
AOS 아키텍처
AOS(Acropolis Operating System)는 플랫폼에서 실행되는 워크로드 및 서비스가 활용하는 핵심 기능을 제공한다. 여기에는 스토리지 서비스, 업그레이드 등과 같은 것들이 포함되지만 이에 국한되지는 않는다.
이 그림은 다양한 레이어에서 AOS의 개념적 특성을 보여주는 이미지를 강조 표시한다.
하이-레벨 AOS 아키텍처 (High-level AOS Architecture)
뉴타닉스의 모든 분산 특성을 기반으로 이를 가상화 및 리소스 관리 공간으로 확장하고 있다. AOS는 워크로드 및 리소스 관리, 프로비저닝 및 운영을 지원하는 백엔드 서비스이다. AOS의 목표는 실행 중인 워크로드에서 촉진 리소스(e.g. 하이퍼 바이저, 온-프레미스, 클라우드 등)를 추상화하고 운영을 위해 단일 "플랫폼"을 제공하는 것이다.
이를 통해 워크로드를 하이퍼바이저, 클라우드 공급자 및 플랫폼 간에 원활하게 이동할 수 있다.
Note
VM 관리를 위해 지원하는 하이퍼바이저
AOS 4.7 현재 AHV와 ESXi가 VM 관리를 지원하는 하이퍼바이저이지만 향후 확대될 수 있다. 볼륨 API 및 읽기 전용 오퍼레이션은 여전히 모두에서 지원된다.
아크로폴리스 서비스
아크로폴리스 워커(Acropolis Worker)는 태스크 스케줄링, 실행, IPAM 등을 담당하는 선출된 아크로폴리스 리더와 함께 모든 CVM에서 실행된다. 리더가 있는 다른 컴포넌트와 마찬가지로 아크로폴리스 리더가 실패하면 새로운 리더가 선출된다.
각각의 역할 구분은 다음과 같다.
- 아크로폴리스 리더 (Acropolis Leader)
- 태스크 스케줄링 및 실행
- 통계 정보 수집 및 퍼블리싱
- 네트워크 컨트롤러 (하이퍼바이저 용)
- VNC 프록시 (하이퍼바이저 용)
- HA (하이퍼바이저 용)
- 아크로폴리스 워커 (Acropolis Worker)
- 통계 정보 수집 및 퍼블리싱
- VNC 프록시 (하이퍼바이저 용)
다음은 아크로폴리스 리더/워커 관계의 개념적 뷰를 보여준다.
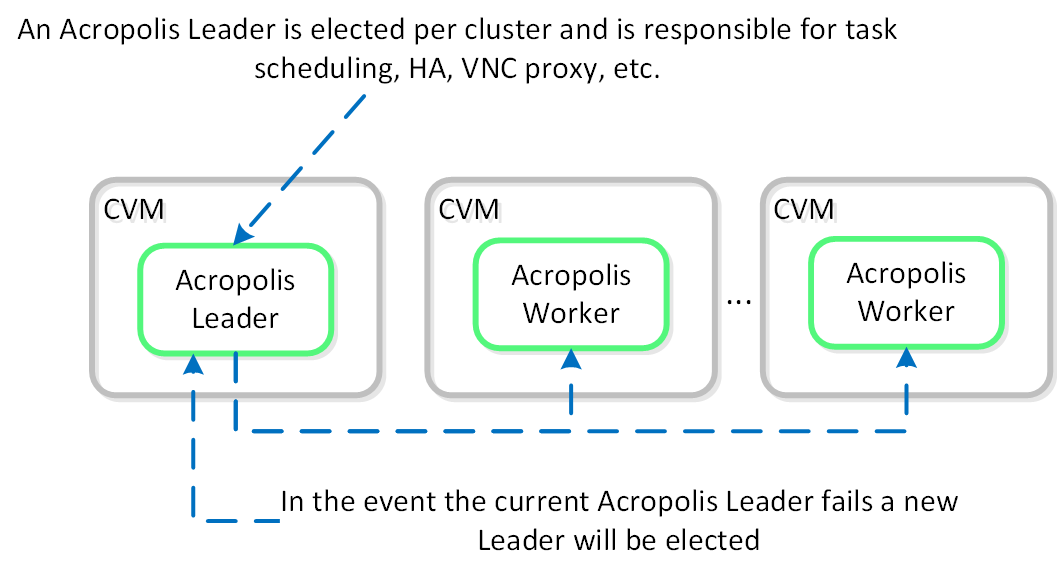 아크로폴리스 서비스 (Acropolis Services)
아크로폴리스 서비스 (Acropolis Services)
동적 스케줄러
자원을 효과적으로 소비하기 위해서는 효율적인 자원 스케줄링이 필수적이다. AOS 동적 스케줄러(AOS Dynamic Scheduler)는 배치 결정을 위해 컴퓨팅 활용률(CPU/MEM)에 의존하는 전통적인 스케줄링 방법을 확장한다. VM 및 볼륨(ABS) 배치 결정을 위해 컴퓨팅뿐만 아니라 스토리지와 다른 요소를 활용한다. 이를 통해 자원이 효과적으로 소비되고 최종 사용자 성능이 최적화된다.
자원 스케줄링은 두 가지 핵심 영역으로 나눌 수 있다.
- 초기 배치 (Initial Placement)
- 전원을 켤 때 항목이 스케줄링되는 위치
- 런타임 최적화 (Runtime Optimization)
- 런타임 메트릭스 기반으로 워크로드 이동
오리지널 AOS 스케줄러는 출시 이후 초기 배치 결정을 담당했었다. AOS 5.0에서 출시된 AOS 동적 스케줄러는 이를 바탕으로 런타임 자원 최적화를 제공한다.
그림은 스케줄러 아키텍처의 하이-레벨 뷰를 보여준다.
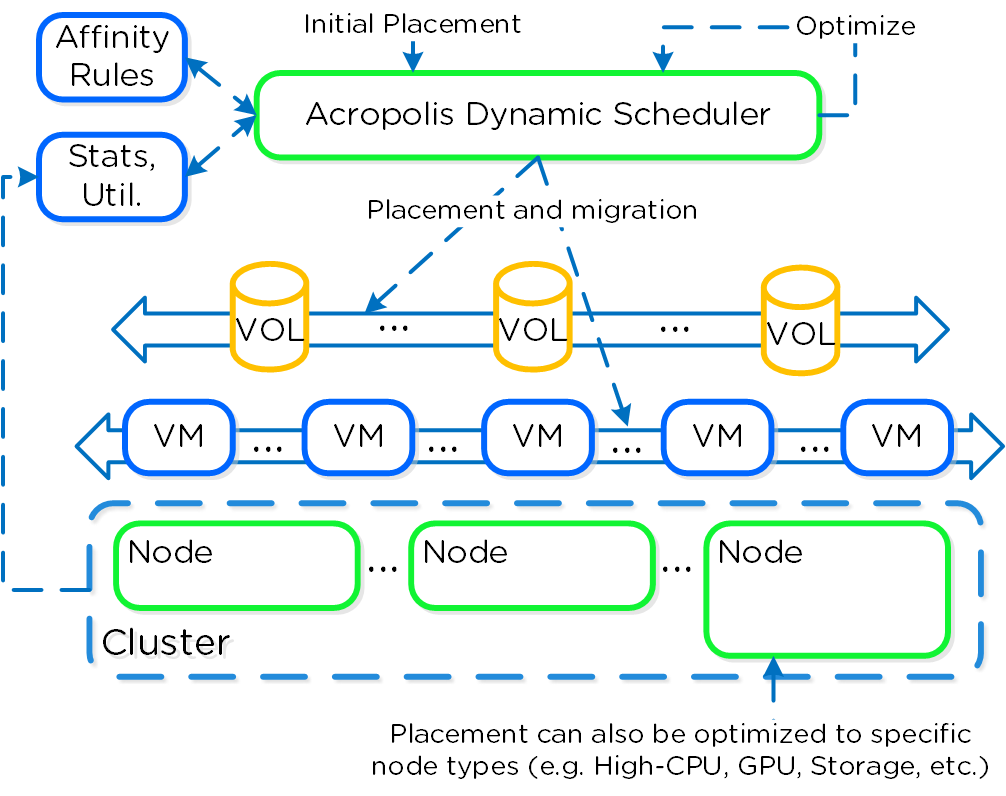 AOS 동적 스케줄러 (AOS Dynamic Scheduler)
AOS 동적 스케줄러 (AOS Dynamic Scheduler)
| 동적 스케줄러는 배치 최적화를 위해 하루 종일 지속적으로 실행된다 (현재 매 15분 마다). | Gflag: lazan_anomaly_detection_period_secs. 예상 수요는 과거 활용률 값을 사용하여 계산되고 스무딩 알고리즘에 제공된다. 이 예상 수요는 이동을 결정하기 위해 사용되며 갑작스러운 스파이크가 결정을 왜곡하지 않도록 한다. |
Note
자원 최적화에 대한 다른 접근 방식 (A different approach towards resource optimization)
기존 스케줄링/최적화 플랫폼(VMware DRS, Microsoft PRO)을 살펴보면 클러스터 자원 전체에서 워크로드/VM의 균형을 균일하게 맞추는데 중점을 둔다. NOTE: 왜곡을 제거하기 위해 얼마나 적극적으로 시도하는가는 밸런싱 설정에 따라 결정된다 (e.g. manual -> none, conservative -> some, aggressive -> more).
예를 들어 클러스터에 3개의 호스트가 있으며 각 호스트의 사용률이 50%, 5%, 5%이다. 일반적인 솔루션은 각 호스트 활용률이 ~20%가 되도록 워크로드를 재조정하려고 한다. 그런데 왜?
우리가 실제로 하려고 하는 것은 왜곡을 제거하는 것이 아니라 자원에 대한 경합을 제거/무효화하는 것이다. 자원에 대한 경합이 없으면 워크로드 밸런싱으로 얻을 수 있는 이득은 없다. 사실 불필요한 이동을 강요함으로써 우리는 자원을 소비하는 필수적인 추가 작업(e.g. 메모리 전송, 캐시 리로컬라이제이션 등)을 유발한다.
AOS 동적 스케줄러는 왜곡 때문이 아니라 자원에 대한 예상 경합이 있는 경우에만 워크로드 이동을 호출한다. NOTE: 아크로폴리스 DSF는 다른 방식으로 동작하고 클러스터 전체에서 데이터의 균일한 분산을 보장하여 핫스팟을 제거하고 재구축 속도를 높인다. DSF에 대한 자세한 내용은 “디스크 밸런싱” 섹션을 참조한다.
전원을 켤 때 ADS는 클러스터 전체에서 VM 초기 배치의 균형을 맞춘다.
배치 결정
배치 결정은 다음 항목을 기반으로 한다:
- 컴퓨트 사용률 (Compute Utilization)
-
각 개별 노드의 컴퓨트 활용도를 모니터링한다. 노드의 예상 CPU 할당이 임계값을 초과하는 경우 (현재 호스트 CPU의 85%) Gflag: lazan_host_cpu_usage_threshold_fraction. 워크로드의 균형을 재조정하기 위해 해당 호스트에서 VM을 마이그레이션한다. 여기서 언급해야 할 핵심 사항은 경합이 있을 때만 마이그레이션이 수행된다는 것이다. 노드 간 사용률에 차이가 있는 경우(예: 3개 노드는 10%, 1개 노드는 50%), 자원에 대한 경합이 없을 때 마이그레이션을 수행하면 아무런 이점이 없으므로 마이그레이션을 수행하지 않는다.
-
- 스토리지 성능 (Storage Performance)
-
하이퍼컨버지드 플랫폼이기 때문에 컴퓨트 및 스토리지 자원을 모두 관리한다. 스케줄러는 각 노드의 스타게이트 프로세스 사용률을 모니터링한다. 특정 스타게이트가 할당 임계값 (현재 스타게이트에 할당된 CPU의 85%)을 초과하는 경우 Gflag: lazan_stargate_cpu_usage_threshold_pct. 핫스팟을 제거하기 위해 호스트 간에 자원을 마이그레이션한다. VM과 ABS 볼륨을 모두 마이그레이션하여 핫 스타게이트를 제거할 수 있다.
-
- [Anti-]Affinity rules
- 선호도(Affinity) 또는 반선호도(Anti-Affinity) 제약조건은 환경의 다른 자원에 기반하여 특정 자원이 스케줄링되는 위치를 결정한다. 라이선스 상의 이유로 VM이 동일한 노드에서 실행되기를 원하는 경우가 있다. 이러한 경우에 VM들은 동일 호스트에 배치된다. 다른 경우에는 가용성을 위해 VM들이 서로 다른 노드에서 실행되도록 할 수 있다. 이러한 경우에 VM들은 서로 다른 호스트에 배치된다.
스케줄러는 이전 항목을 토대로 워크로드 배치의 최적화를 위해 최선을 다할 것이다. 시스템은 너무 많은 마이그레이션이 발생하지 않도록 하기 위해 자원의 이동에 대한 패널티를 부과한다. 이것은 이동이 워크로드에 부정적인 영향을 미치지 않도록 하기 위한 핵심 항목이다.
마이그레이션 후 시스템은 "효과성"을 판단하고 실제 이득이 무엇인지 확인한다. 이 학습 모델은 마이그레이션 결정에 유효한 근거가 있는지 확인하기 위해 자체 최적화할 수 있다.
보안
보안은 뉴타닉스 플랫폼의 핵심 부분으로 개발 초기 단계에서부터 적용되었다. 뉴타닉스 SecDL(Security Development Lifecycle)은 개발 프로세스의 모든 단계에 보안을 통합한다. 이 시스템은 최종 사용자가 사후에 플랫폼의 보안을 "강화(Harden)"하도록 요구하는 것이 아닌 공장에서 안전하게 배송된다.
보안에 대해 생각할 때, 뉴타닉스는 실제로 3가지 핵심 목표(CIA 트라이어드라고도 함)를 달성하려고 한다.
- 기밀성 (Confidentially)
- 무단 액세스를 방지하여 데이터 보호 및 보안
- 무결성 (Integrity)
- 무단 변경을 방지하여 데이터의 일관성 및 정확성 보장
- 가용성 (Availability)
- 인증된 사용자가 탄력성과 중복성을 통해 데이터에 액세스할 수 있도록 보장
이것은 간단한 진술로 단순화될 수 있다: 사용자가 나쁜 사람들을 멀리하면서 업무를 수행할 수 있다. 보안을 설계할 때는 다음 다이어그램에서 강조할 몇 가지 핵심 영역을 살펴보아야 한다.
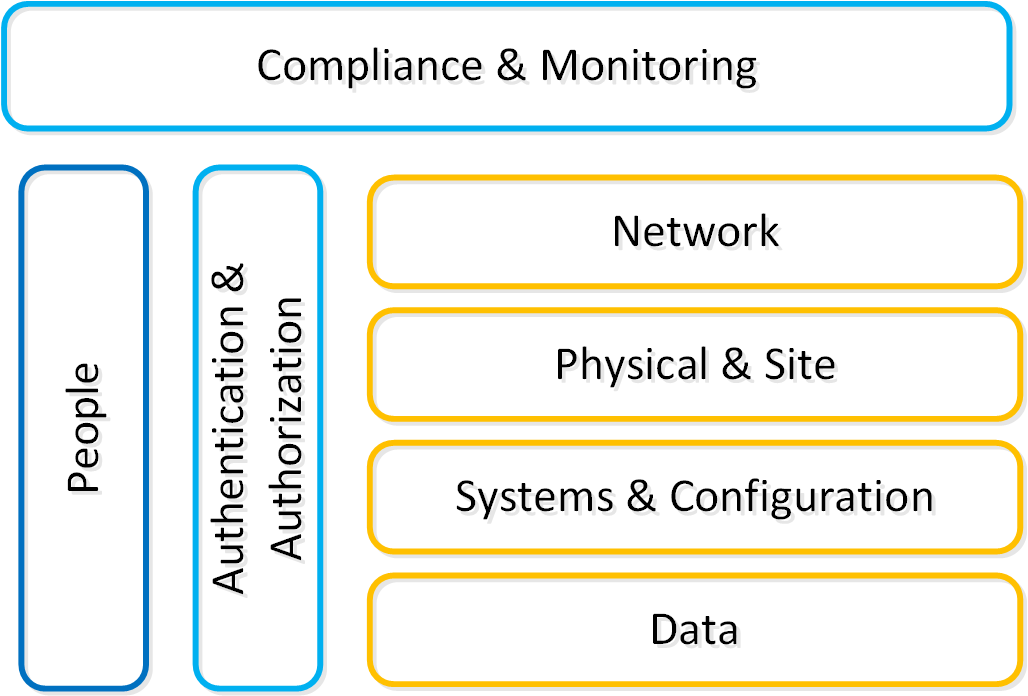 보안 계층 (Security Layers)
보안 계층 (Security Layers)
상기 그림의 각 주제에 대해 다음 섹션에서 자세히 기술한다.
시스템 및 설정 (System & Configuration)
Note
요약:
- 알려진 취약성 패치 및 제거
- 강력한 암호를 적용하고 기본 계정 제거
- 퍼미션 및 사용자 권한 설정
- 사용하지 않는 포트/프로토콜 닫기
- 자동화를 사용하여 기준선(Baseline) 보장
일반적으로 사람들은 "강화(Hardening)"라는 방법을 사용하여 시스템(OS + 앱) 보안을 말한다. 이것은 기준선이라고 하는 특정 표준으로 구성하여 시스템을 보호하는 프로세스이다.
DoD의 IT 조직 (DISA)에는 STIG라고 하는 샘플 강화 안내서가 있다 (자세한 내용은 SCMA 섹션 참조). 여기에는 디렉토리 권한, 사용자 계정 관리, 비밀번호 복잡성, 방화벽 및 기타 여러 구성 설정이 포함된다.
시스템이 해당 표준으로 구성되면 "보안"으로 간주되지만 이것은 프로세스의 시작일뿐이다. 시스템 보안은 수명 기간 동안 유지되어야 하는 것이다. 예를 들어, 표준 강화 기준을 충족하려면 구성 자동화 도구를 사용해야 한다. 이를 통해 시스템은 항상 기준선 "원하는 상태"를 충족하게 된다.
뉴타닉스는 이 섹션의 뒷부분에서 다루는 SCMA라는 툴을 사용하여 CVM 및 AHV 하이퍼바이저에서 이를 보장한다.
데이터 (Data)
Note
요약:
- 데이터에 대한 안전한 액세스 제어
- 항상 백업을 수행
- 데이터 암호화 및 키 보안
데이터는 모든 비즈니스의 핵심이며 회사의 가장 소중한 자산이다. 보안을 고려할 때 데이터 접근성, 품질 및 도난 방지를 보장하는 데 중점을 두어야 한다.
접근성의 개념에서 의사 결정을 내리려면 시스템과 데이터에 지속적으로 액세스해야 한다. 랜섬웨어(Ransomware)라고 하는 최근의 공격 방법 중 하나는 데이터를 암호화한 다음 사용자가 랜섬을 통해 다시 액세스할 수 있도록 하여 데이터에 액세스하는 기능을 위협한다. 이것은 다양한 방법으로 피할 수 있지만 백업의 중요성을 강조한다.
많은 의사 결정 또는 액션이 데이터에 의존하기 때문에 데이터 품질도 중요한 항목이다. 예를 들어 공격자는 시스템에 액세스하여 악의적인 주문을 하거나 상품을 자신의 위치로 우회하는 배송 주소를 업데이트할 수 있다. 데이터를 깨끗하게 유지하려면 로깅 및 체크섬이 매우 중요하다.
마지막으로 데이터를 보호하거나 강화하는 방법은 무엇입니까? 일반적으로 암호화를 사용하여 데이터를 해독할 키가 없는 데이터를 쓸모없게 만든다. 이 경우 누군가 암호화된 파일이나 디스크 디바이스를 훔치면 기본 데이터에 액세스할 수 없게 된다.
네트워크 (Network)
Note
요약:
- 신뢰할 수 있는 네트워크와 신뢰할 수 없는 네트워크 분리
- 경계 및 세그먼트 간의 방화벽 설정
- IDPS를 활용하여 이상 징후 탐지
네트워크는 일반적으로 공격자가 시스템에 액세스하기 위해 사용하는 통신 벡터이다. 여기에는 경계 보안(e.g. 외부 방화벽) 및 내부 침입 방지/검출이 포함된다.
좋은 디자인과 마찬가지로 항상 보안 계층이 있어야 한다: 네트워크에서도 마찬가지다. 높은 보안 네트워크를 신뢰할 수 있는 네트워크에서 분리하고 신뢰할 수 없는 네트워크(e.g. 비즈니스/WiFi 네트워크)에서 네트워크를 보호해야 한다. 사무실의 로컬 네트워크가 안전하다고 가정해도 안전하지 않다.
네트워크의 여러 계층을 가짐으로써 우리는 가장 신뢰할 수 없는 네트워크에 액세스하는 사람이 보안 네트워크를 향해 일하는 것이 더 어려워질 수 있다. 이 과정에서 우수한 IDPS 시스템은 액세스 이상 징후 또는 nmap과 같은 검색 도구를 감지할 수 있다.
인증 및 권한 (Authentication and Authorization)
Note
요약:
- 가능한 경우 MFA/2FA를 사용
- 세분화된 권한 사용
인증은 Active Directory 또는 다른 IDP(Identity provider)와 같은 신뢰할 수 있는 정보로 사용자 ID를 인증하는 것이다. MFA(Multi-Factor Authentication) 또는 2FA와 같은 도구는 2단계 또는 여러 단계를 통해 사용자 인증을 진행한다.
신원이 확인되면 다음은 그들이 할 수 있는 권한이나 액세스 가능한 것을 결정하는 것이다; 이것은 인증의 한 부분이다. foo 사용자는 bar에서 x, y를 수행하고 bas에서 y, z를 수행할 수 있다.
컴플라이언스 및 모니터링 (Compliance & Monitoring)
Note
요약:
- 컴플라이언스는 지속적인 활동이다.
- 이상 징후 모니터링
컴플라이언스는 일반적으로 PCI, HIPAA 등과 같은 특정 인증을 볼 때 사람들이 참조하는 것이다. 그러나 이것은 강화 지침이나 설정된 표준을 준수하도록 더욱 확장된다. 예를 들어 STIG는 샘플 강화 기준이지만 각 회사에는 추가 정책/규칙이 있을 수 있다. 안전한 시스템을 보장하기 위해 시스템은 이러한 정책을 준수하고 준수 상태에 있는지 확인해야 한다.
일반적으로 컴플라이언스는 소급 적용되며 상당히 수동적인 프로세스이다. 나는 이것이 절대적으로 잘못된 접근법이라고 생각한다. 컴플라이언스는 잠재적 위협 벡터를 제한하거나 열린 위협 요소를 닫을 수 있는 유일한 방법이므로 지속적으로 확인해야 한다.
구성 관리 자동화(일명 원하는 상태 구성-DSC)를 처리하는 도구는 여기서 중요한 부분이다. 이를 통해 구성/설정이 항상 기준 또는 원하는 상태로 설정된다.
모니터링 및 침투 테스트는 이러한 컴플라이언스를 검증하고 보장하는 데 중요하다. Nessus, Nmap 또는 metasploit와 같은 도구를 사용하여 시스템의 보안을 테스트할 수 있다. 이러한 테스트 중에 모니터링 및 감지 시스템은 이를 감지하고 경고해야 한다.
사람 (People)
Note
요약:
- 교육, 교육, 교육
- 강력한 관행 및 습관 강화 (e.g. 컴퓨터 잠금)
어느 시스템에서나 사람은 일반적으로 가장 약한 연결 고리이다. 사용자가 피싱 공격이나 사회적 조작에 취약하지 않도록 하려면 교육 및 교육이 중요하다. 우리는 사용자가 무엇을 찾아야 하는지 잘 알고 있어야 하며, 확실하지 않은 경우 알려진 리소스로 에스컬레이션 해야 한다.
한 가지 교육 방법은 실제로 피싱 공격을 시뮬레이션하여 사물에 의문을 제기하고 무엇을 찾아야 하는지 배울 수 있다. 또한 컴퓨터를 잠금 해제 상태로 두지 않거나 암호를 기록하지 않는 등 다른 정책을 시행해야 한다
인증 및 자격 (Certifications & Accreditations)
뉴타닉스는 스택의 일부(온-프레미스 및 오프-프레미스)에 대해 다음과 같은 보안 인증/자격을 보유하고 있다.
- 공통 평가 기준 (Common Criteria)*
- 공통 평가 기준은 주로 공공 시장(주로 국방 및 인텔리전스 용)에 컴퓨터 제품을 판매하는 회사가 한 세트의 표준에 대해서만 평가받도록 하기 위해 만들어졌다. CC는 캐나다, 프랑스, 독일, 네덜란드, 영국 및 미국 정부에 의해 개발되었다.
- *2020년 3월 현재 재인증 중이다.
- Security Technical Implementation Guides (STIGs)
- DOD IA 및 IA-활성화된 디바이스/시스템에 대한 설정 표준. 1998년부터 DISA FSO(Field Security Operations)가 보안 기술 구현 안내서(STIGs)를 제공함으로써 DoD(국방부) 보안 시스템의 보안 상태를 향상시키는 중요한 역할을 수행하였다. STIGs에는 악의적인 컴퓨터 공격에 취약할 수 있는 정보시스템/소프트웨어를 "잠금"할 수 있는 기술 지침이 포함되어 있다.
- FIPS 140-2
- FIPS 140-2 표준은 민감하지만 기밀이 아닌 정보를 수집, 저장, 전송, 공유 및 보급하는 정부 부처 및 규제 산업(금융 및 헬스-케어 기관과 같은)에서 사용할 수 있도록 제품을 인증받으려는 민간 부분 벤더가 제작한 암호화 모듈을 위한 정보 기술 보안 인증 프로그램이다.
- NIST 800-53
- NIST 800-131a
- ISO 27001
- ISO 27017
- ISO 27018
SCMA (Security Configuration Management Automation)
뉴타닉스 보안 엔지니어링은 이제 고객에게 특정 시점의 보안 기준 점검에서 지속적인 모니터링/자체-교정 기준으로 발전하여 클러스터의 모든 CVM/AHV가 배포 수명주기 동안 기준 준수를 유지할 수 있도록 한다. 이 새로운 혁신은 문서화된 보안 기준(STIGs)의 모든 컴포넌트를 검사하고, 준수하지 않은 것으로 발견되면 고객의 개입 없이 지원되는 보안 기준으로 재설정하도록 한다. SCMA는 디폴트로 활성화되어 있으므로 활성화하는 데 필요한 작업이 없습니다.
Note
애드 혹 SCMA 실행 (Ad-hoc SCMA execution)
SCMA는 설정된 스케줄(디폴트 값: HOURLY)에 기반하여 실행되지만 온-디멘드로도 실행할 수 있다. SCMA 툴을 실행하려면 CVM에서 다음 명령어를 수행한다.
###### Run on a single CVMsudo salt-call state.highstate###### Run on all CVMs
allssh "sudo salt-call state.highstate"
뉴타닉스 nCLI를 통해 고객은 보다 엄격한 보안 요구 사항을 지원하기 위해 다양한 구성 설정을 제어할 수 있다.
CVM 보안 설정 (CVM Security Settings)
SCMA 정책의 클러스터 전체 설정을 지원하기 위해 nCLI에 다음 명령이 추가되었다. 아래 목록은 모든 명령과 기능을 제공한다.
CVM 보안 설정 가져오기
ncli cluster get-cvm-security-config
이 명령은 현재 클러스터 설정을 출력한다. 기본 출력은 다음과 같이 표시된다.
Enable Aide : false Enable Core : false Enable High Strength P... : false Enable Banner : false Enable SNMPv3 Only : false Schedule : DAILY
이들 각각은 다음과 같이 정의된다.
- Aide
- 고급 침입 감지 환경('Advanced Intrusion Detection Environment')이 주기적으로 실행되도록 활성화한다.
- 핵심 (Core)
- 문제가 있거나 SCMA가 치료할 수 없는 경우에 스택 추적을 생성한다.
- 강력한 암호 (High Strength Passwords)
- 강력한 암호(minlen=15,difok=8,remember=24)를 적용한다.
- 배너 (Banner)
- 커스텀 로그인 배너를 활성화한다.
- SNMPv3 전용
- SNMPv2 대신에 SNMPv3를 강제한다.
CMV 로그인 배너 설정 (Set CVM login banner)
이 명령은 뉴타닉스 CVM에 로그인할 때 동의 로그인 배너의 국방부(DoD) 지식을 활성화 또는 비활성화한다.
ncli cluster edit-cvm-security-params enable-banner=[yes|no] #Default:no
Note
사용자 정의 로그인 배너 (Custom login banner)
기본적으로 동의 로그인 배너의 국방부 지식이 사용된다. 사용자 정의 배너를 활용하려면 다음 단계를 수행한다 (CVM에서 Nutanix user로 실행).
- 기존 배너의 백업 생성
- sudo cp -a /srv/salt/security/KVM/sshd/DODbanner /srv/salt/security/KVM/sshd/DODbannerbak
- vi를 사용하여 기존 배너를 수정
- sudo vi /srv/salt/security/KVM/sshd/DODbanner
- 모든 CVM에서 단계를 반복하거나 수정된 배너를 모든 CVM으로 복사
- 우의 명령을 사용하여 배너 활성화
CVM 패스워드 강도 설정 (Set CVM password strength)
이 명령은 고강도 패스워드 정책을 활성화 또는 비활성화한다 (minlen=15, difok=8, remember=24).
ncli cluster edit-cvm-security-params enable-high-strength-password=[yes|no] #Default:no
AIDE(Advanced Intrusion Detection Environment) 설정 (Set Advanced Intrusion Detection Environment (AIDE))
이 명령은 AIDE 서비스의 주 단위 실행을 활성화 또는 비활성화한다.
ncli cluster edit-cvm-security-params enable-aide=true=[yes|no] #Default:no
SNMPv3 전용 설정 (Set SNMPv3 only)
이 명령은 SNMPv3 전용 트랩을 활성화 또는 비활성화한다.
ncli cluster edit-cvm-security-params enable-snmpv3-only=[true|false] #Default:false
SCMA 스케줄 설정 (Set SCMA schedule)
이 명령은 SCMA 실행 주기를 설정한다.
ncli cluster edit-cvm-security-params schedule=[HOURLY|DAILY|WEEKLY|MONTHLY] #Default:HOURLY
하이퍼바이저 보안 설정 (Hypervisor Security Settings)
SCMA 정책의 클러스터 전체 설정을 지원하기 위해 nCLI에 다음 명령이 추가되었다. 아래 목록은 모든 명령과 기능을 제공한다.
하이퍼바이저 보안 설정 가져오기 (Get hypervisor security settings)
ncli cluster get-hypervisor-security-config
이 명령은 현재 클러스터 설정을 출력한다. 기본 출력은 다음과 같이 표시된다.
Enable Aide : false Enable Core : false Enable High Strength P... : false Enable Banner : false Schedule : DAILY
하이퍼바이저 로그인 배너 설정 (Set hypervisor login banner)
이 명령은 뉴타닉스 AHV에 로그인할 때 동의 로그인 배너의 국방부(DoD) 지식을 활성화 또는 비활성화한다.
ncli cluster edit-hypervisor-security-params enable-banner=[yes|no] #Default:no
하이퍼바이저 패스워드 강도 설정 (Set hypervisor password strength)
이 명령은 고강도 패스워드 정책을 활성화 또는 비활성화한다 (minlen=15, difok=8, remember=24).
ncli cluster edit-hypervisor-security-params enable-high-strength-password=[yes|no] #Default:no
AIDE(Advanced Intrusion Detection Environment) 설정 (Set Advanced Intrusion Detection Environment (AIDE))
이 명령은 AIDE 서비스의 주 단위 실행을 활성화 또는 비활성화한다.
ncli cluster edit-hypervisor-security-params enable-aide=true=[yes|no] #Default:no
SCMA 스케줄 설정 (Set SCMA schedule)
이 명령은 SCMA 실행 주기를 설정한다.
ncli cluster edit-hypervisor-security-params schedule=[HOURLY|DAILY|WEEKLY|MONTHLY] #Default:HOURLY
클러스터 잠금 (Cluster Lockdown)
클러스터 잠금은 패스워드 기반 CVM 액세스를 비활성화하고 키 기반 액세스만 허용하는 기능이다.
클러스터 잠금 설정은 프리즘의 설정 메뉴에서 찾을 수 있다.
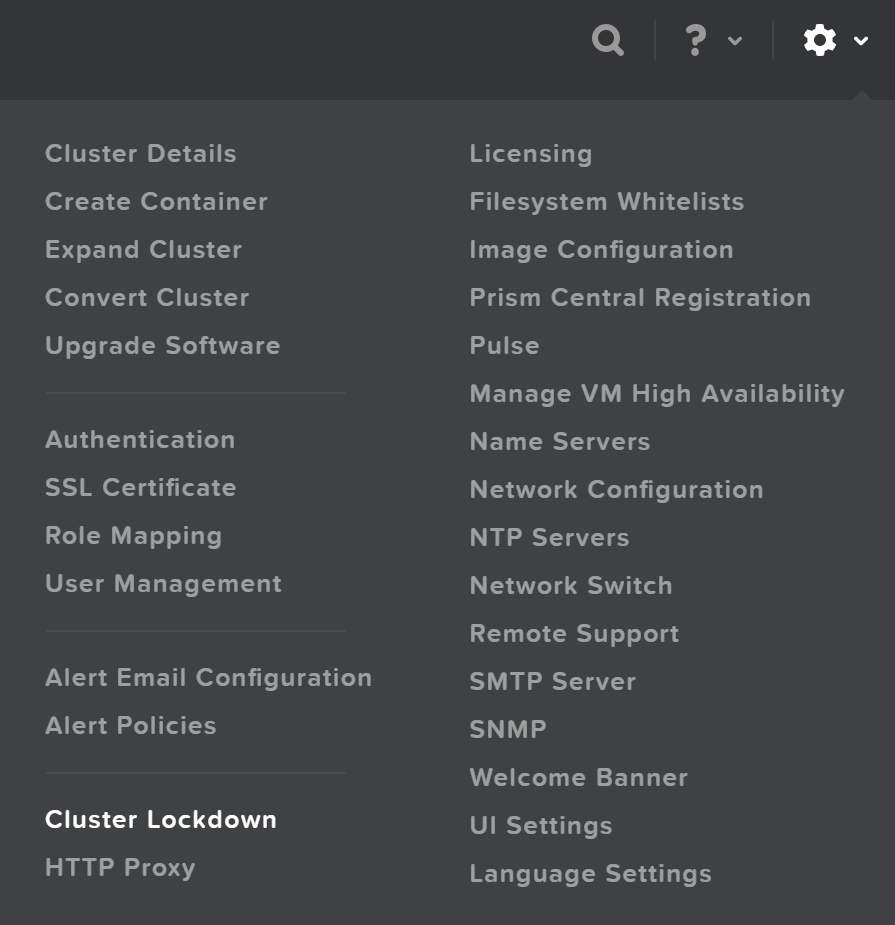 클러스터 잠금 메뉴 (Cluster Lockdown Menu)
클러스터 잠금 메뉴 (Cluster Lockdown Menu)
현재 설정이 표시되고 액세스를 위해 SSH 키를 추가/제거할 수 있다.
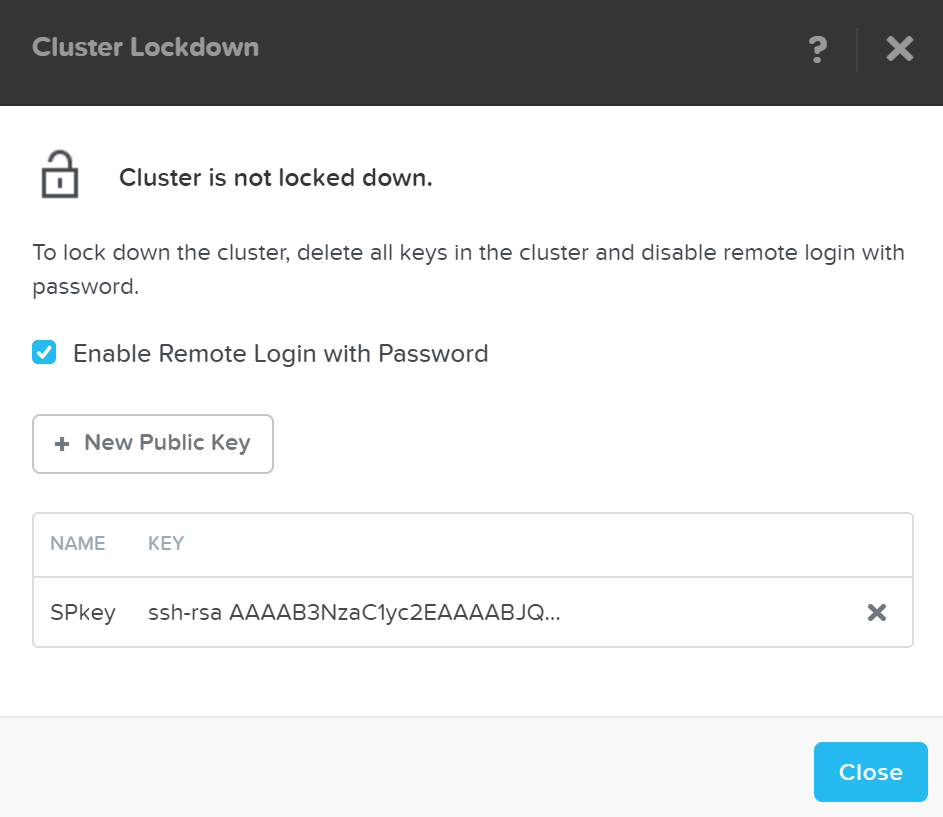 클러스터 잠금 페이지 (Cluster Lockdown Page)
클러스터 잠금 페이지 (Cluster Lockdown Page)
새로운 키를 추가하려면 “New Public Key” 버튼을 클릭하고 공개 키 세부 사항을 입력한다.
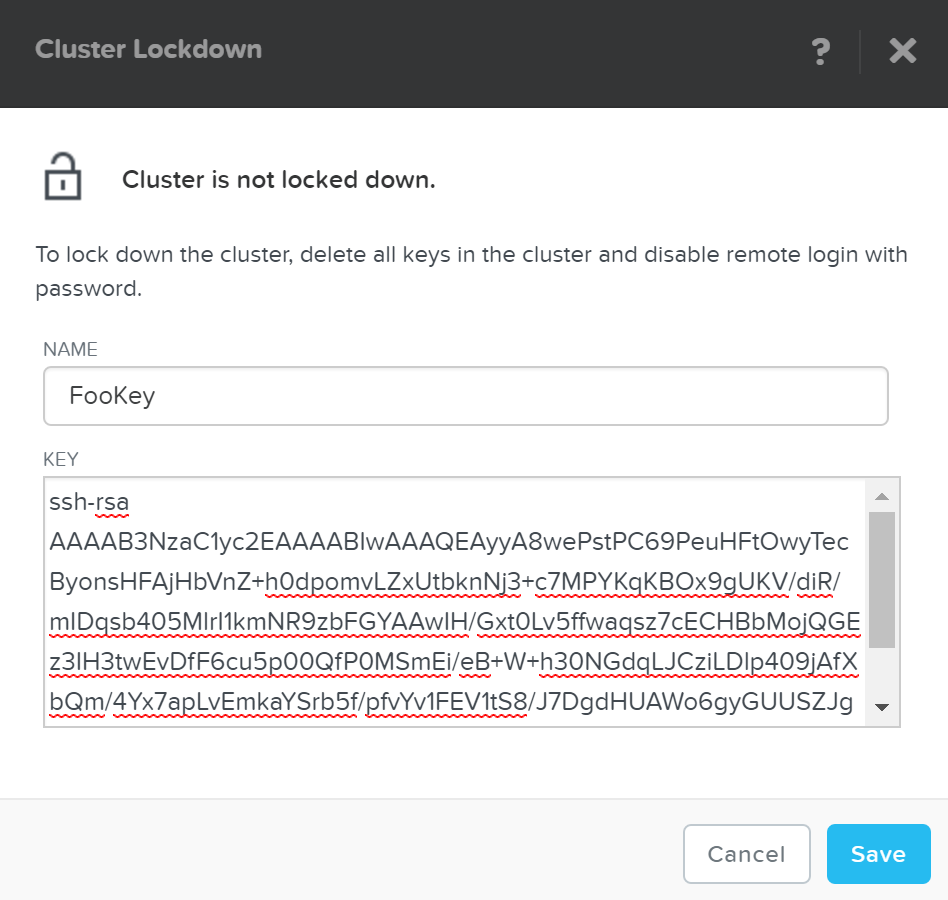 클러스터 잠금 – 키 추가 Cluster Lockdown - Add Key)
클러스터 잠금 – 키 추가 Cluster Lockdown - Add Key)
Note
SSH 키 작업 (Working with SSH keys)
SSH 키를 생성하려면 다음 명령을 실행한다:
ssh-keygen -t rsa -b 2048
그러면 키 쌍이 만들어지고 두 개의 파일이 생성된다:
- id_rsa (private key)
- id_rsa.pub (public key - this one is used when adding a key to the cluster)
일부 키를 추가하고 액세스 권한을 확인한 후에 “Enable Remote Login with Password”을 선택 해제하여 패스워드 기반 로그인을 비활성화할 수 있다. 작업을 확인하는 팝업이 나타나면 “OK”를 클릭하여 잠금을 진행한다.
데이터 암호화 및 키 관리
데이터 암호화는 권한이 있는 사람만 데이터를 이해할 수 있는 방식으로 당사자들이 데이터를 인코딩할 수 있도록 허용하는 방법으로 권한이 없는 사람은 이해할 수 없다.
예를 들어, 한 사람에게만 메시지를 보내야 하는 경우 메시지(평문)를 암호(키)로 암호화하여 암호화된 메시지(암호문)를 보낼 수 있다. 이 메시지를 도난당하거나 가로채면 공격자는 메시지를 해독할 암호 없이 대부분 쓸모없는 암호문만 볼 수 있다. 원하는 당사자가 메시지를 받으면 우리가 제공한 키를 사용하여 메시지를 해독할 수 있다.
데이터를 암호화하는 몇 가지 주요 방법이 있다:
- 대칭 암호화 (개인 키 암호화)
- 데이터 암호화 및 복호화를 위해 동일 키 사용
- 예: AES, PGP*, Blowfish, Twofish, etc.
- 비대칭 암호화 (공개 키 암호화)
- 하나의 키는 암호화(공개 키)를 위해 사용하고 다른 키는 복호화(개인 키)를 위해 사용
- 예: RSA, PGP*, etc.
NOTE: PGP(또는 GPG)는 대칭 키와 비대칭 키를 모두 사용한다.
데이터 암호화에 대해 이야기할 때, 암호화는 일반적으로 두 가지 주요 컨텍스트에서 수행된다.
- 전송 중인 데이터(In-transit): 두 당사자 간에 전송 중인 데이터 (e.g. 네트워크를 통해 데이터 전송)
- 정적 데이터(At-Rest): 정적 데이터 (e.g. 디바이스에 저장된 데이터)
네이티브 소프트웨어 기반 암호화(SED 유무에 관계없이), 뉴타닉스는 전송 중인 데이터(In-transit* Data) 및 정적 데이터(Data-at-Rest Data) 암호화를 모두 해결한다. SED 기반 암호화만으로 뉴타닉스는 정적 데이터(Data-at-Rest Data) 암호화를 해결한다. *NOTE: 전송 중인 데이터 암호화는 현재 뉴타닉스 클러스터 내에서 데이터 RF에 적용할 수 있다.
다음 섹션에서 뉴타닉스가 데이터 암호화 및 키 관리 옵션을 관리하는 방법에 대해 설명한다.
데이터 암호화
뉴타닉스는 다음과 같은 세 가지 주요 옵션을 통해 데이터 암호화를 제공한다.
- 네이티브 소프트웨어 기반 암호화(FIPS-140-2 Level-1) * AOS 5.5에서 출시
- 자체 암호화 드라이브(SED) 사용 (FIPS-140-2 Level-2)
- 소프트웨어 + 하드웨어 암호화
암호화는 클러스터 또는 컨테이너 레벨에서 설정하며 하이퍼바이저 유형에 따라 다르다.
- 클러스터 레벨 암호화:
- AHV, ESXi, Hyper-V
- 컨테이너 레벨 암호화:
- ESXi, Hyper-V
NOTE: SED 기반 암호화를 사용하여 배포하는 경우 물리 디바이스가 자체적으로 암호화되므로 클러스터 레벨이 된다.
설정 메뉴(기어 아이콘)에서 'Data-at-Rest Encryption'로 이동하여 클러스터의 암호화 상태를 볼 수 있다. 현재 상태를 제공하고 암호화를 설정할 수 있다 (현재 활성화되어 있지 않은 경우).
이 예에서는 클러스터 레벨의 암호화가 설정되어 있음을 알 수 있다.
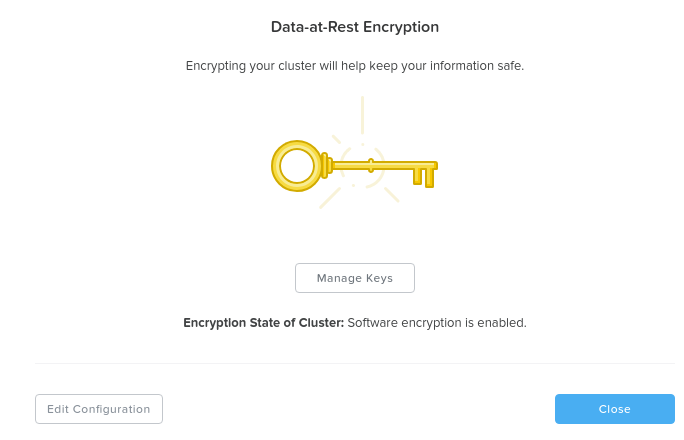 데이터 암호화 – 활성화 (클러스터 레벨) (Data Encryption - Enabled (cluster level))
데이터 암호화 – 활성화 (클러스터 레벨) (Data Encryption - Enabled (cluster level))
이 예제에서는 다음과 같은 특정 컨테이너에 대해 암호화가 사용되었다.
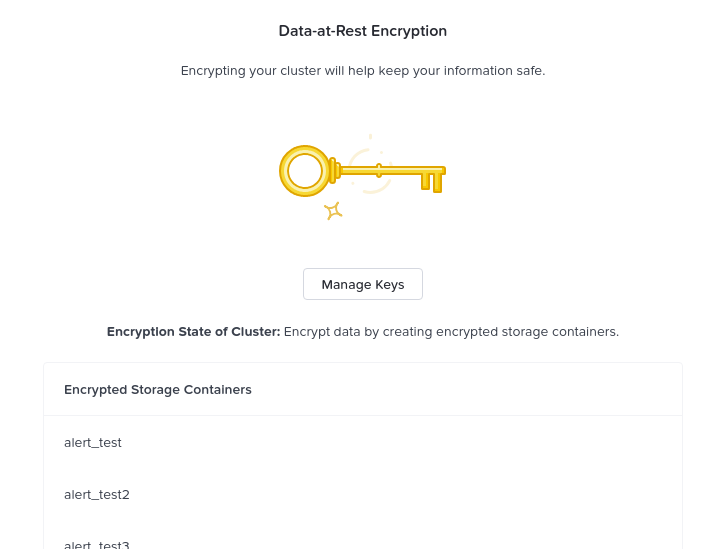 데이터 암호화 – 활성화 (컨테이너 레벨) (Data Encryption - Enabled (container level))
데이터 암호화 – 활성화 (컨테이너 레벨) (Data Encryption - Enabled (container level))
“Edit Configuration” 버튼을 클릭하여 설정을 활성화/수정할 수 있다. 암호화에 사용되는 KMS 또는 현재 활용 중인 KMS 유형을 설정할 수 있는 메뉴가 나타난다.
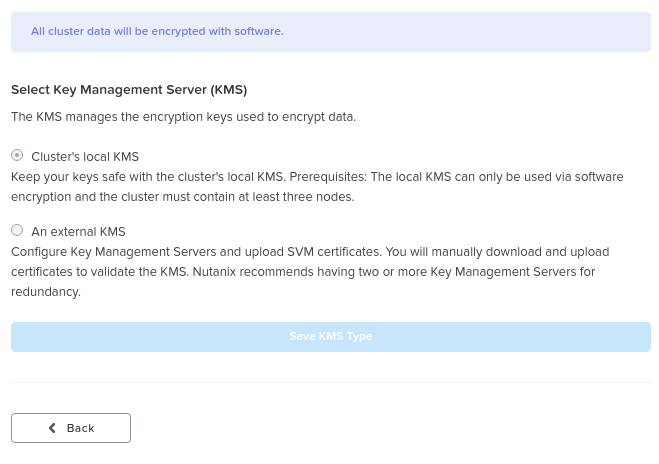 데이터 암호화 – 설정 (Data Encryption - Configure)
데이터 암호화 – 설정 (Data Encryption - Configure)
외부 KMS인 경우 메뉴는 서명을 위해 CA에 제공할 수 있는 CSR 요청 프로세스로 안내한다.
네이티브 소프트웨어 기반 암호화 (Native Software-based Encryption)
뉴타닉스 소프트웨어 암호화는 네이티브 AES-256 정적 데이터 암호화를 제공한다. 이는 모든 KMIP 또는 TCG 호환 외부 KMS 서버(Vormetric, SafeNet 등) 또는 AOS 5.8에서 도입된 뉴타닉스 네이티브 KMS(아래에서 자세히 설명)와 상호 작용할 수 있다. 암호화/복호화를 위해 시스템은 인텔 AES-NI 가속을 활용하여 소프트웨어로 이 작업을 수행할 때의 잠재적 성능 영향을 최소화한다.
데이터가 쓰일 때 (OpLog 및 익스텐트 스토어) 데이터는 체크섬을 제외하고 디스크에 쓰이기 전에 암호화된다. 이는 데이터가 로컬로 암호화된 다음 암호화된 데이터가 RF를 위해 원격 CVM에 복제됨을 의미한다.
암호화는 디스크에 쓰기 전에 데이터에 마지막으로 적용되는 변환이다.
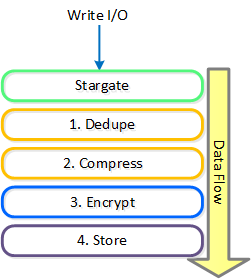 데이터 암호화 – 애플리케이션 변환 (Data Encryption - Transform Application)
데이터 암호화 – 애플리케이션 변환 (Data Encryption - Transform Application)
Note
암호화 및 데이터 효율성 (Encryption and Data Efficiency)
중복제거 또는 압축을 적용한 후에 데이터를 암호화하므로 이러한 방법을 통한 모든 스토리지 용량 절감 가능이 유지된다. 간단히 말해 중복제거 및 압축 비율은 암호화되거나 암호화되지 않은 데이터에 대해 정확히 동일하다.
데이터를 읽을 때 체크섬 경계에서 데이터를 읽고 복호화 작업을 수행한 후에 게스트 VM에 데이터를 반환한다. 체크섬 경계에서 암호화/복호화 작업을 수행하므로 읽기 증폭이 발생하지 않는다. 인텔 AES NI 오프로드 기능을 활용하기 때문에 성능/레이턴시에 미치는 영향은 거의 없다.
SED 기반 암호화 (SED Based Encryption)
이 그림은 아키텍처의 하이-레벨 개요를 보여준다.
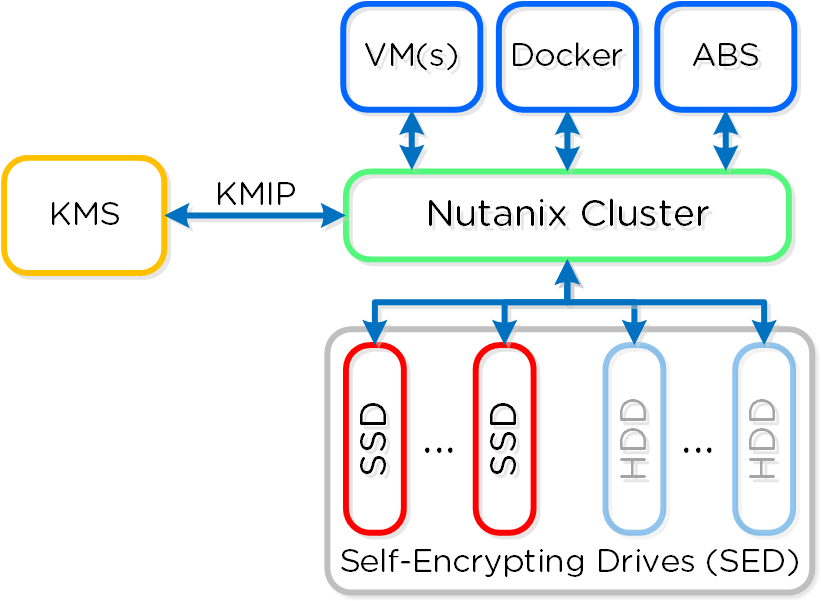 데이터 암호화 - SED (Data Encryption - SED)
데이터 암호화 - SED (Data Encryption - SED)
SED 암호화는 스토리지 디바이스를 보안 또는 보안되지 않은 상태를 갖는 “데이터 밴드"로 분할하여 동작한다. 뉴타닉스의 경우 부트 및 뉴타닉스 홈 파티션은 간단하게 암호화된다. 모든 디바이스 및 밴드는 Level-2 표준에 따라 빅 키로 강력하게 암호화된다.
클러스터가 시작되면 KMS 서버를 호출하여 드라이브 잠금 해제 키를 얻는다. 보안을 위해 클러스터에서 키는 캐싱 되지 않는다. 콜드 부트 및 IPMI 리셋인 경우 노드는 드라이브 잠금 해제를 위해 KMS 서버를 다시 호출할 필요가 있다. CVM을 소프트 리부트 하는 경우에 이러한 과정은 발생하지 않는다.
키 관리 (KMS) [Key Management (KMS)]
뉴타닉스는 다른 전용 KMS 솔루션의 대안으로 네이티브 키 관리(로컬 키 관리자 - LKM) 및 스토리지 기능(AOS 5.8에서 도입)을 제공한다. 이는 전용 KMS 솔루션의 필요성을 없애고 환경을 단순화하기 위해 도입되었지만 외부 KMS는 여전히 지원된다.
이전 섹션에서 언급했듯이 키 관리는 모든 데이터 암호화 솔루션에서 매우 중요한 부분이다. 안전한 키 관리 솔루션을 제공하기 위해 스택 전체에서 여러 개의 키가 사용된다.
솔루션에 세 가지 유형의 키가 사용된다.
- 데이터 암호화 키 (DEK: Data Encryption Key)
- 데이터 암호화에 사용되는 키
- 키 암호화 키 (KEK: Key Encryption Key)
- DEK 암호화에 사용되는 암호화 키
- 마스터 암호화 키 (MEK: Master Encryption Key)
- KEK 암호화에 사용되는 암호화 키
- 로컬 키 관리자를 사용할 때만 적용 가능
다음 그림은 다양한 키와 KMS 옵션 간의 관계를 보여준다.
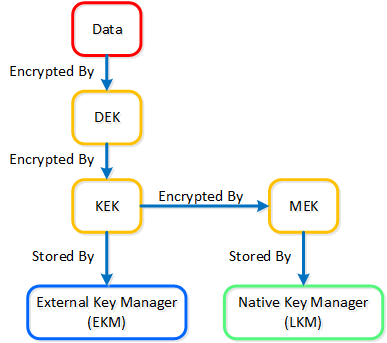 데이터 암호화 – 키 관리 (Data Encryption - Key Management)
데이터 암호화 – 키 관리 (Data Encryption - Key Management)
LKM(로컬 키 매니저) 서비스는 모든 뉴타닉스 노드에 분산되며 각 CVM에서 기본적으로 실행된다. 이 서비스는 FIPS 140-2 Crypto 모듈(현재 인증 작업 진행 중)을 사용하며, 키 관리는 키 관리 활동(e.g. re-key, backup keys 등) 외에 최종 사용자에게 투명하다.
데이터 암호화를 설정할 때 'Cluster’s local KMS'를 선택하면 네이티브 KMS를 활용할 수 있다.
데이터 암호화 - 설정 (Data Encryption - Configure)
마스터 키(MEK: Master Encryption Key)는 키의 리질리언시 및 보안을 위해 Shamir의 Secret Sharing 알고리즘을 사용하여 클러스터의 모든 노드에 분할되어 저장된다. 키를 다시 구성하려면 최소 ROUNDUP (N / 2) 노드를 사용할 수 있어야 한다. 여기서 N은 클러스터의 노드 수다.
Note
키 백업 및 키 로테이션 (Key Backups and Key Rotation)
시스템은 KEK와 MEK를 모두 로테이션(re-key)할 수 있는 기능을 제공한다. 시스템은 매년 마스터 키(MEK)를 자동으로 로테이션하지만 필요에 따라 이 작업을 수행할 수도 있다. 노드 추가/제거의 경우 마스터 키도 로테이션 한다.
분산 스토리지 패브릭
분산 스토리지 패브릭(Distributed Storage Fabric: DSF)은 중앙 집중식 스토리지 어레이처럼 하이퍼바이저에게 보이지만 모든 I/O는 로컬에서 처리되어 최고의 성능을 제공한다. 이러한 노드들이 분산 시스템을 구성하는 방법에 대한 자세한 내용은 다음 섹션에서 확인할 수 있다.
데이터 구조
뉴타닉스 분산 스토리지 패브릭(Distributed Storage Fabric: DSF)은 다음과 같은 하이-레벨 스트럭트로 구성되어 있다.
스토리지 풀 (Storage Pool)
- 주요 역할: 물리적 디바이스의 그룹 (Group of physical devices)
- 설명: 스토리지 풀은 클러스터의 PCIe SSD, SSD 및 HDD 디바이스를 포함하는 물리적 스토리지 디바이스의 그룹이다. 스토리지 풀은 여러 개의 뉴타닉스 노드에 걸쳐있을 수 있으며 클러스터가 확장됨에 따라 스토리지 풀도 확장된다. 대부분의 설정에서는 단일 스토리지 풀만 활용된다.
컨테이너 (Container)
- 주요 역할: VM/파일의 그룹 (Group of VMs/files)
- 설명: 컨테이너는 스토리지 풀의 논리적 세그먼트이며 VM 또는 파일(vDisk) 그룹을 포함한다. 일부 설정 옵션(e.g. RF)은 컨테이너 레벨에서 설정되지만 개별 VM/파일 레벨에서 적용된다. 컨테이너는 일반적으로 데이터스토어(NFS/SMB인 경우)와 1:1 매핑을 가진다.
vDisk
- 주요 역할: vDisk
- 설명: vDisk는 .vmdk, VM 하드 디스크를 포함하여 DSF에서 512KB가 넘는 파일이다. vDisk는 논리적으로 "블록 맵(block map)"을 구성하는 vBlock으로 구성되어 있다.
Note
최대 DSF vDisk 크기 (Maximum DSF vDisk Size)
DSF/스타게이트 측면에서 vDisk 크기에 부과된 인위적인 제한은 없다. AOS 4.6에서 vDisk 크기는 크기를 바이트 단위로 저장하는 부호 있는 64비트 정수로 저장된다. 이는 이론상 최대 vDisk 크기가 2^63-1 or 9E18(9 Exabytes) 일 수 있음을 의미한다. 이 값 미만의 제한은 ESXi의 최대 vmdk 크기와 같은 클라이언트 측의 제한 때문이다.
다음 그림은 DSF와 하이퍼바이저 간의 매핑 관계를 보여준다.
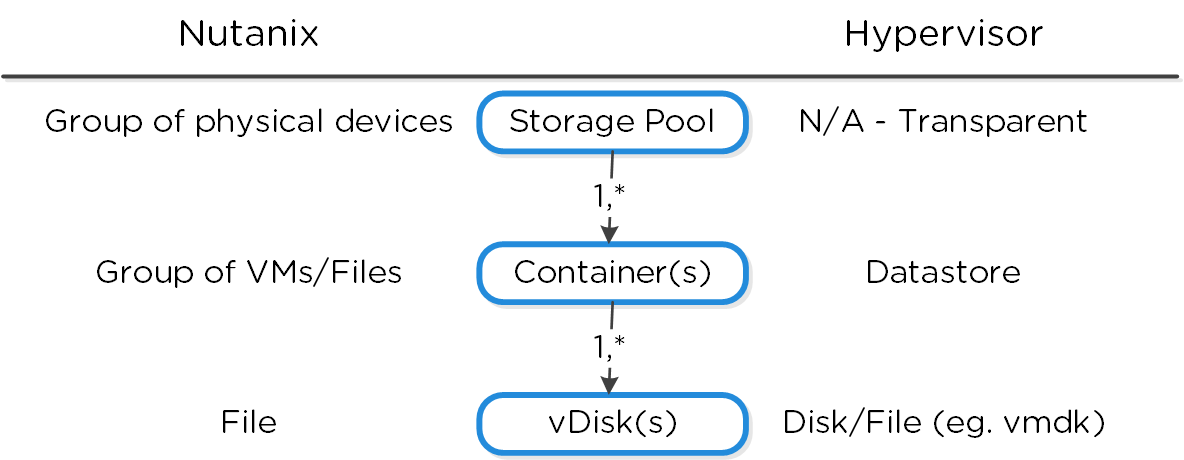 하이-레벨 파일시스템 분해 (High-level Filesystem Breakdown)
하이-레벨 파일시스템 분해 (High-level Filesystem Breakdown)
vBlock
- 주요 역할: 1MB의 vDisk 주소 공간 (1MB chunk of vDisk address space)
- 설명: vBlock은 vDisk를 구성하는 1MB 청크의 가상 주소 공간이다. 예를 들어 100MB의 vDisk는 100x1MB vBlock이 있고, vBlock 0은 0-1MB, vBlock 1은 1-2MB이다. 이 vBlock은 익스텐트 그룹으로 디스크에 파일로 저장되는 익스텐트에 매핑된다.
익스텐트 (Extent)
- 주요 역할: 논리적으로 연속적인 데이터 (Logically contiguous data)
- 설명: 익스텐트는 n개의 연속적인 블록(게스트 OS의 블록 크기에 따라 달라짐)으로 구성된 1MB의 논리적으로 연속적인 데이터이다. 익스텐트는 세분화 및 효율성을 위해 서브-익스텐트(슬라이스로 알려진) 기준으로 쓰기/읽기/수정된다. 익스텐트의 슬라이스는 캐시로 이동될 때 읽기/캐시되는 데이터의 양에 따라 트림된다.
익스텐트 그룹 (Extent Group)
- 주요 역할: 물리적으로 연속되어 저장되는 데이터 (Physically contiguous stored data)
- 설명: 익스텐트 그룹은 1MB 또는 4MB의 물리적으로 연속되어 저장되는 데이터이다. 이 데이터는 CVM이 소유한 스토리지 디바이스에 파일로 저장된다. 익스텐트는 성능 향상을 목적으로 노드/디스크 간에 데이터 스트라이핑을 제공하기 위해 익스텐트 그룹 간에 동적으로 분산된다. NOTE: AOS 4.0 현재 익스텐트 그룹은 중복제거에 따라 1MB 또는 4MB가 될 수 있다.
다음 그림은 이러한 스트럭트와 다양한 파일 시스템 간의 관계를 보여준다.
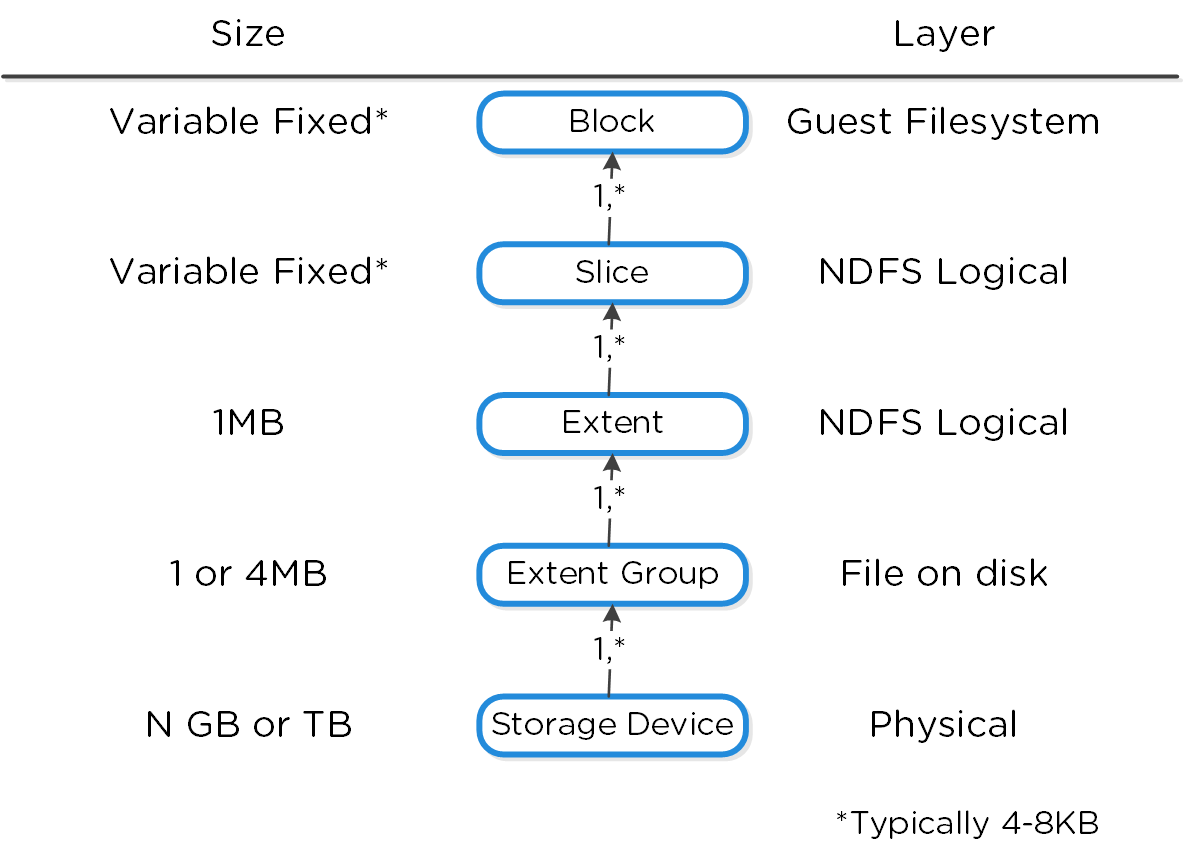 로우-레벨 파일시스템 분해 (Low-level Filesystem Breakdown)
로우-레벨 파일시스템 분해 (Low-level Filesystem Breakdown)
다음은 이러한 유닛이 어떻게 관련되어 있는지를 보여주는 다른 그래픽 표현이다.
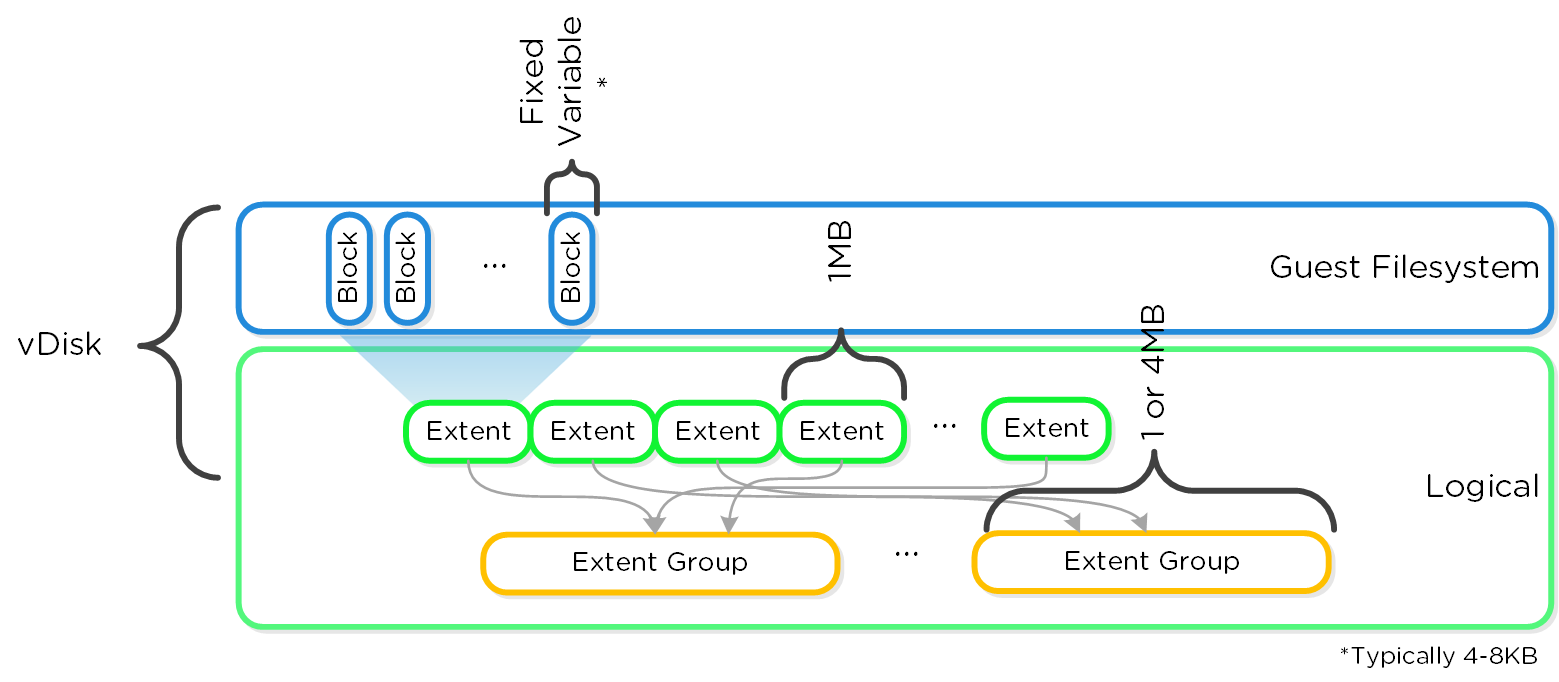 그래픽컬 파일시스템 분해 (Graphical Filesystem Breakdown)
그래픽컬 파일시스템 분해 (Graphical Filesystem Breakdown)
I/O 경로 및 캐시
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
일반적인 하이퍼컨버지드 스토리지 I/O 경로는 다음과 같은 핵심 계층으로 분류할 수 있다.
- 가상 디스크에 대한 게스트 OS(UVM)
- 이것은 뉴타닉스와 변함없이 유지된다. 하이퍼바이저에 따라 게스트 OS는 디바이스 드라이버를 사용하여 가상 디스크 디바이스와 통신한다. 하이퍼바이저에 따라 이는 virtio-scsi(AHV), pv-scsi(ESXi) 등이 될 수 있다. 가상 디스크는 하이퍼바이저에 따라 다르다 (e.g. vmdk, vhd 등).
- DSF에 대한 하이퍼바이저 (CVM을 통해)
- 하이퍼바이저와 뉴타닉스 간의 통신은 CVM과 하이퍼바이저의 로컬 인터페이스를 통한 표준 스토리지 프로토콜(e.g. iSCSI, NFS, SMBv3)을 통해 이루어진다. 이 시점에서 모든 통신은 호스트의 로컬에서 발생한다 (I/O가 원격인 시나리오가 있다 (e.g. 로컬 CVM 다운 등)).
- 뉴타닉스 I/O 경로
- 이것은 하이퍼바이저와 UVM에 모두 투명하며 뉴타닉스 플랫폼에서 기본으로 제공된다.
다음 이미지는 이러한 계층에 대한 하이-레벨 개요를 보여준다.
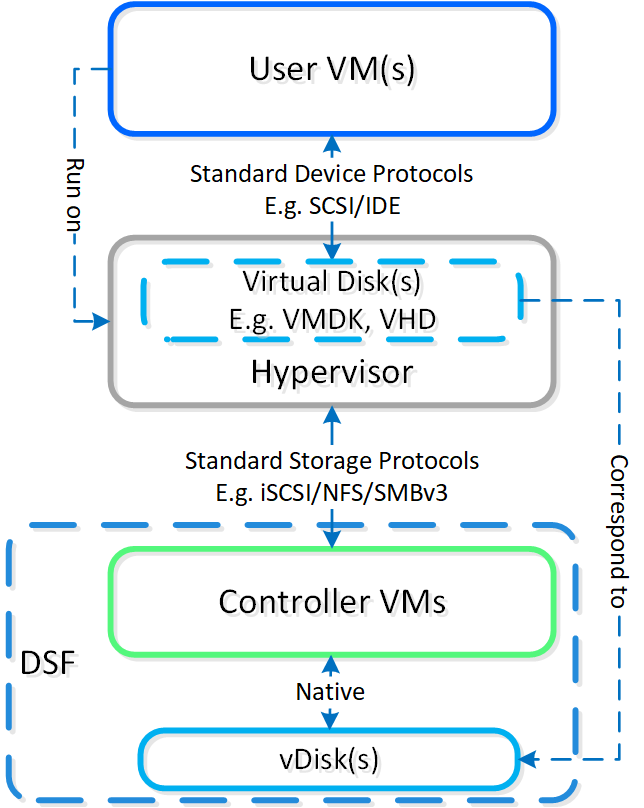 하이-레벨 I/O 경로 - 기존 방식 (High-level I/O Path - Traditional)
하이-레벨 I/O 경로 - 기존 방식 (High-level I/O Path - Traditional)
통신 및 I/O (Communication and I/O)
CVM 내에서 스타게이트 프로세스는 모든 스토리지 I/O 요청을 처리하고 다른 CVM/물리적 디바이스와의 상호 작용을 담당한다. 스토리지 디바이스 컨트롤러는 CVM으로 직접 전달되므로 모든 스토리지 I/O가 하이퍼바이저를 우회한다.
다음 이미지는 기존 I/O 경로에 대한 하이-레벨 개요를 보여준다.
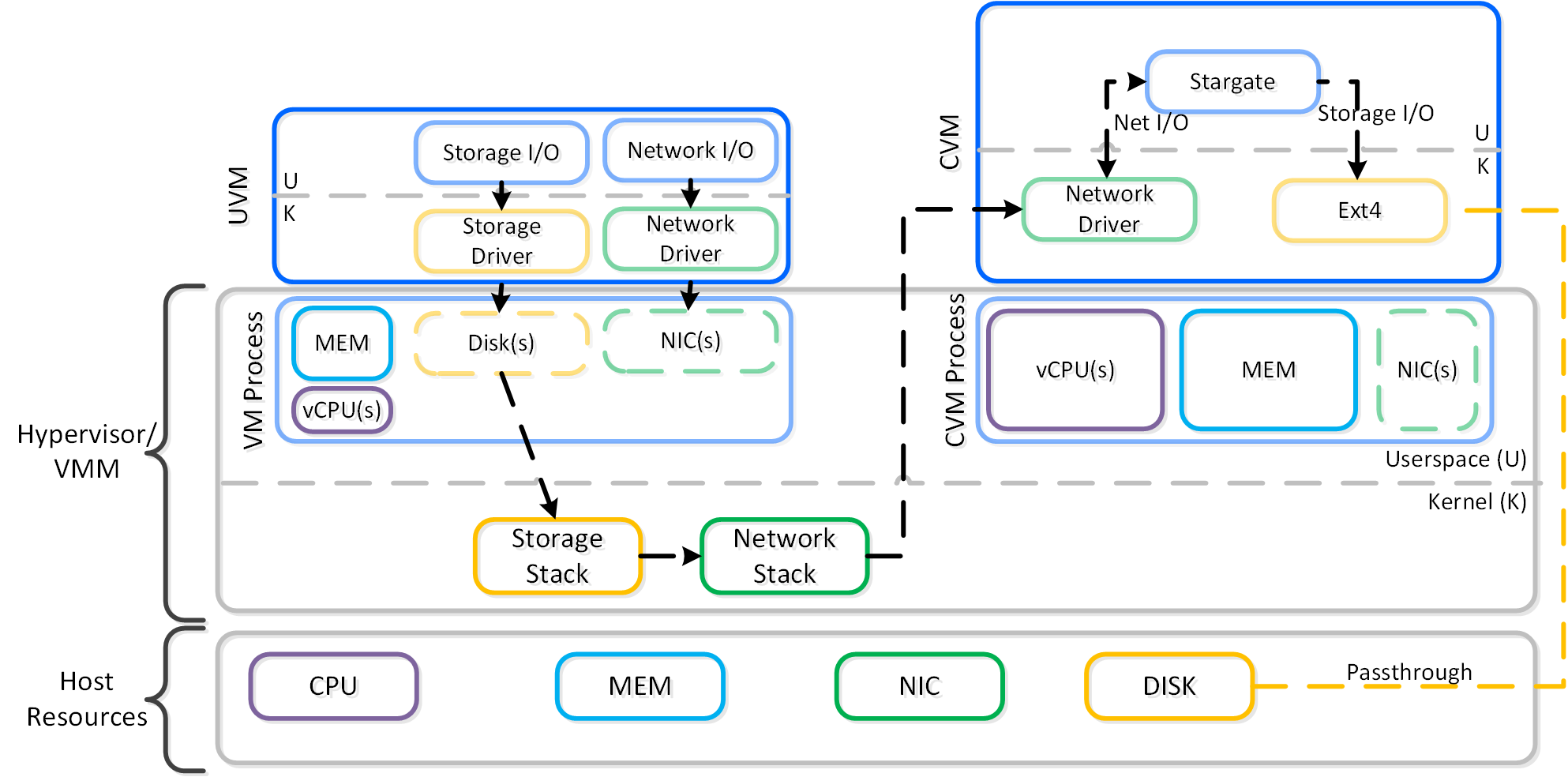 하이-레벨 I/O 경로 (High-level I/O Path)
하이-레벨 I/O 경로 (High-level I/O Path)
뉴타닉스 BlockStore(AOS 5.18버전부터 릴리즈됨)는 AOS 기능으로 유저 스페이스에서 처리되는 확장 가능한 파일 시스템 및 블록 관리 계층을 생성한다. 이를 통해 디바이스에서 파일 시스템이 제거되고 파일 시스템 커널 드라이버의 호출이 제거된다. 최신 스토리지 미디어(e.g. NVMe)가 도입된 디바이스에는 이제 유저 스페이스 라이브러리가 제공되어 디바이스 I/O를 직접 처리(e.g. SPDK)하여 시스템 호출(컨텍스트 전환)이 필요하지 않다. BlockStore + SPDK의 조합으로 모든 스타게이트 디바이스 상호 작용은 컨텍스트 전환이나 커널 드라이버 호출을 제거하면서 유저 스페이스로 이동했다.
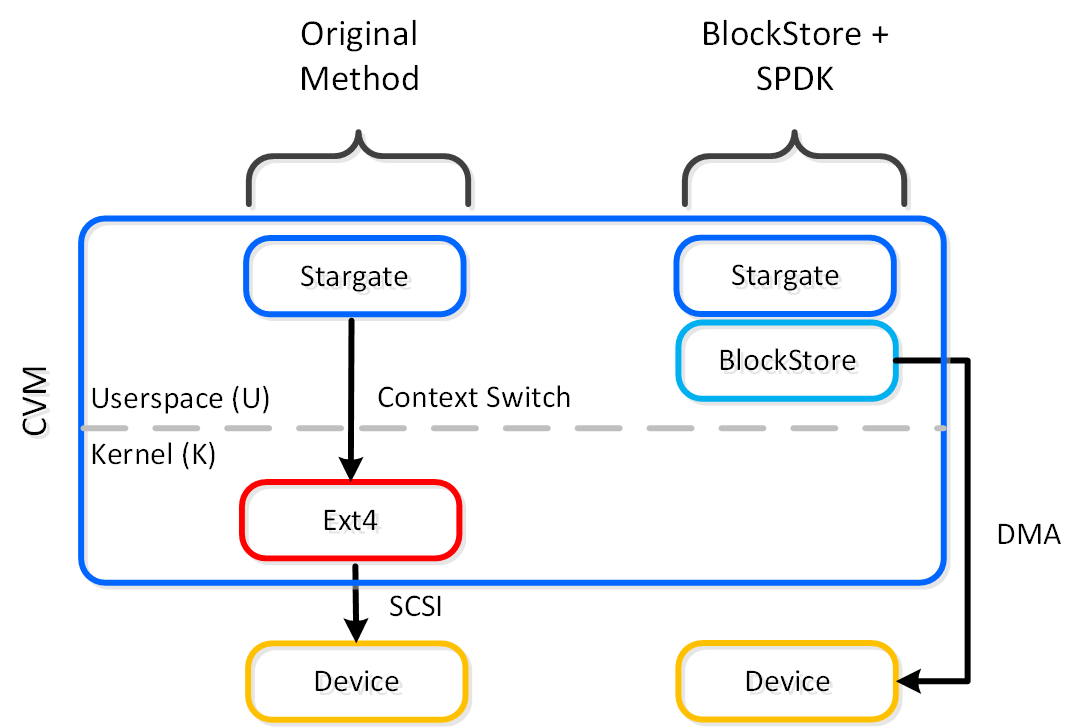 스타게이트 - 디바이스 I/O 경로 (Stargate - Device I/O Path)
스타게이트 - 디바이스 I/O 경로 (Stargate - Device I/O Path)
다음 이미지는 BlockStore + SPDK를 사용하여 업데이트된 I/O 경로의 하이-레벨 개요를 보여준다.
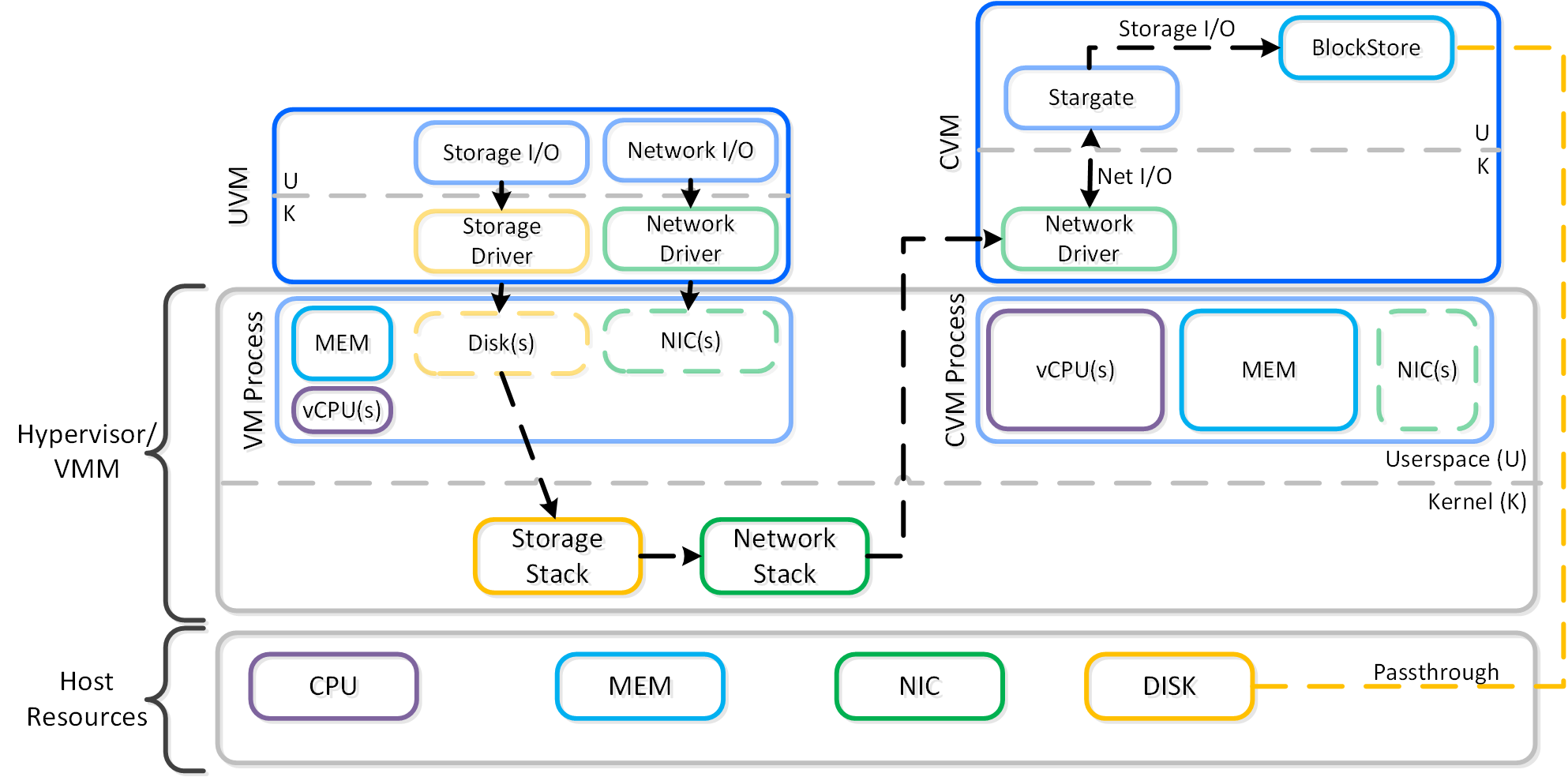 하이-레벨 I/O 경로 - BlockStore (High-level I/O Path - BlockStore)
하이-레벨 I/O 경로 - BlockStore (High-level I/O Path - BlockStore)
데이터 복제를 수행하기 위해 CVM은 네트워크를 통해 통신한다. 기본 스택을 사용하면 커널 레벨 드라이버가 호출된다.
그러나, RDMA를 사용하면 이러한 NIC이 하이퍼바이저의 모든 것을 바이패스하여 CVM으로 전달된다. 또한, CVM 내에서 RDMA를 사용하는 모든 네트워크 트래픽은 제어 경로에 커널 레벨 드라이버만 사용하므로 모든 실제 데이터 I/O는 컨텍스트 스위치 없이 유저 스페이스에서 수행된다.
다음 이미지는 RDMA를 사용한 I/O 경로에 대한 하이-레벨 개요를 보여준다.
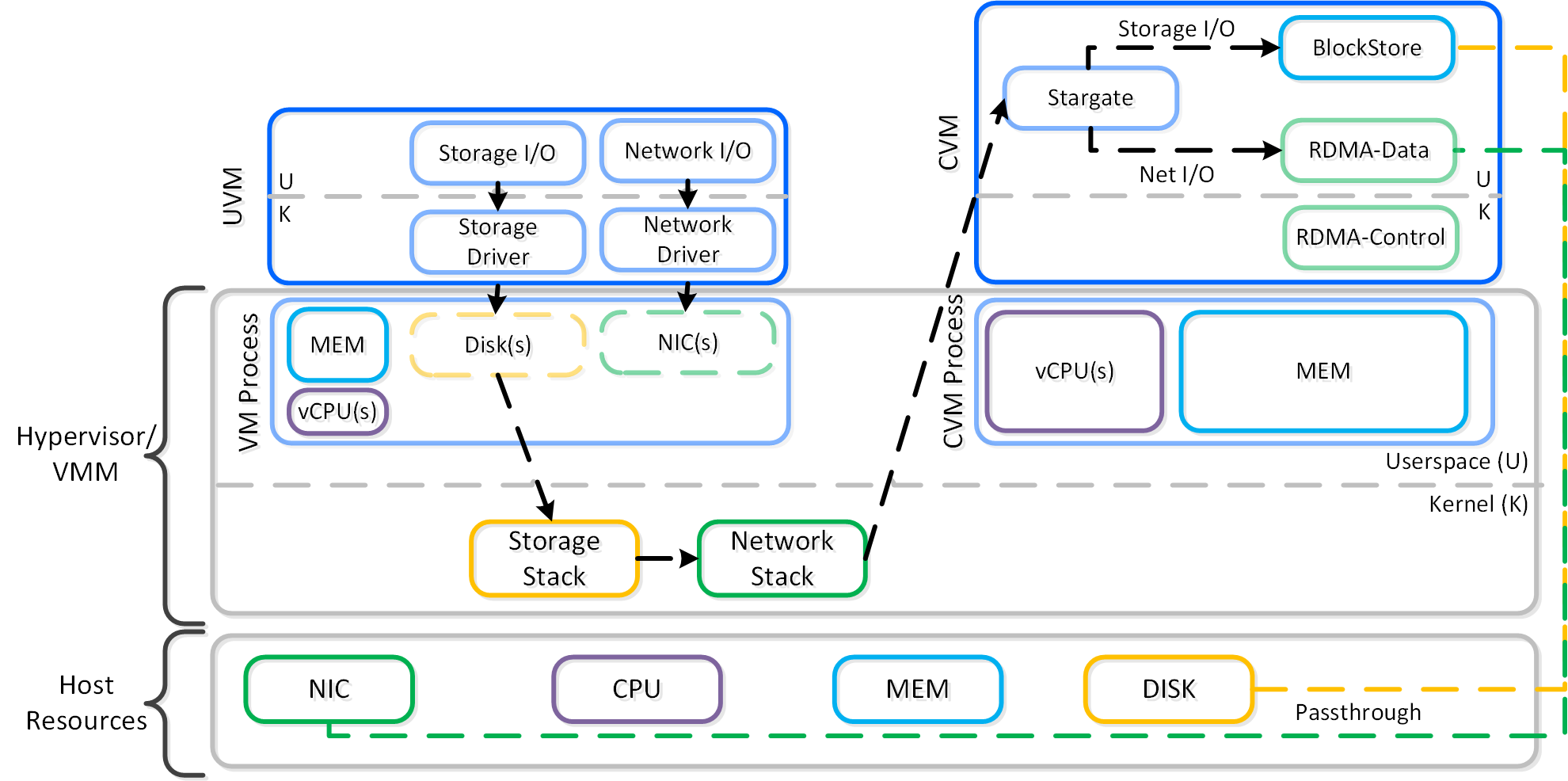 하이-레벨 I/O 경로 - RDMA (High-level I/O Path - RDMA)
하이-레벨 I/O 경로 - RDMA (High-level I/O Path - RDMA)
요약하면 다음과 같은 개선 사항이 최적화된다.
- PCI 패스스루는 디바이스 I/O를 위해 하이퍼바이저를 바이패스한다.
- SPDK + Blockstore는 커널 스토리지 드라이버 상호 작용을 제거하고 유저 스페이스로 옮긴다.
- RDMA는 하이퍼바이저를 바이패스하고 모든 데이터 전송은 CVM 유저 스페이스에서 수행된다.
스타게이트 I/O 로직 (Stargate I/O Logic)
CVM 내에서 스타게이트 프로세스는 사용자 VM(UVM) 및 지속성 목적(RF 등)으로 들어오는 모든 I/O를 처리한다. 쓰기 요청이 스타게이트로 들어올 때, 쓰기가 버스트 랜덤 쓰기를 위해 OpLog에 저장되는지 또는 지속되는 랜던 및 순차 쓰기를 위해 Extent Store에 저장되는지를 결정하는 쓰기 특성화가 있다. 읽기 요청은 요청 시 데이터가 있는 위치에 따라 Oplog 또는 Extent Store에서 처리된다.
뉴타닉스 I/O 경로는 다음과 같은 하이-레벨 컴포넌트로 구성되어 있다.
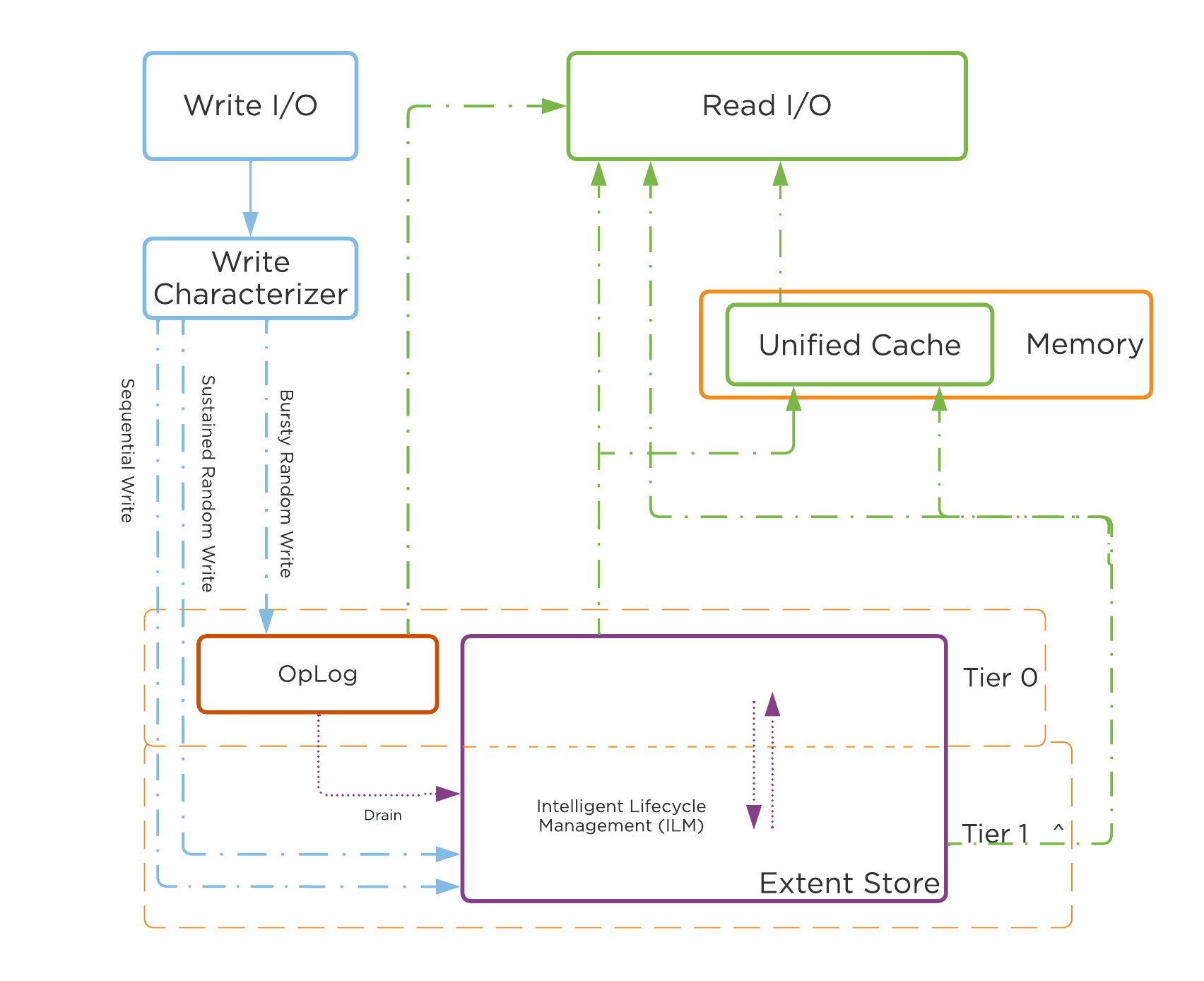 DSF I/O 경로 (DSF I/O Path)
DSF I/O 경로 (DSF I/O Path)
*AOS 5.10부터 AES(Autonomous Extent Store)를 사용하여 필요조건이 만족될 때 지속적인 랜덤 워크로드를 처리할 수 있다.
^:
- 올-플래시 노드 설정(All NVMe SSD, All SATA/SAS SSD, NVMe+SATA/SAS SSD)에서 익스텐트 스토어는 SSD 디바이스로만 구성되며, 단일 플래시 계층만 존재하므로 계층 ILM이 발생하지 않는다.
- Optane이 사용되는 경우(예: Intel Optane + NVMe/SATA SSD) 최고 성능 미디어는 계층 0가 되고 저성능 미디어는 계층 1이 된다.
- 올-플래시가 아닌 하이브리드 시나리오의 경우 플래시는 계층 0가 되고 HDD는 계층 1이 된다.
- OpLog는 하이브리드 클러스터의 SSD와 Optane+NVMe 클러스터의 Optane 및 NVMe SSD 모두에 항상 있다.
- 데이터는 액세스 패턴을 기반으로 하는 ILM(Intelligent Lifecycle Management)에 의해 계층 간에 이동된다.
OpLog
- 주요 역할: 영구 쓰기 버퍼 (Persistent write buffer)
- 설명: OpLog는 파일 시스템 저널과 유사하며 랜덤 쓰기의 버스트를 처리하고 이를 병합한 다음 데이터를 순차적으로 익스텐트 스토어로 배수하는 스테이징 영역으로 구축된다. 쓰기 시에 OpLog는 데이터의 가용성을 위해 쓰기를 승인하기 전에 다른 n개의 CVM OpLog에 동기적으로 복제한다. 모든 CVM OpLog는 복제에 참여며 부하에 따라 동적으로 선택된다. OpLog는 매우 빠른 쓰기 I/O 성능을 제공하기 위해, 특히 랜덤 I/O 워크로드의 경우, CVM의 SSD 티어에 저장된다. 모든 SSD 디바이스가 참여하여 OpLog 스토리지의 일부를 처리한다. 순차 워크로드의 경우 OpLog를 바이패스하고 쓰기는 익스텐트 스토어로 직접 이동한다. 데이터가 현재 OpLog에 있고 배수되지 않은 경우 모든 읽기 요청은 배수될 때까지 직접적으로 OpLog에서 수행되며, 데이터가 배수되면 익스텐트 스토어/유니파이드 캐시에서 서비스된다. 지문(중복제거로 알려진)이 활성화한 컨테이너의 경우 모든 쓰기 I/O는 해시 알고리즘을 사용하여 지문을 생성하며 유니파이드 캐시에서 지문을 기반으로 중복제거를 가능하게 한다.
Note
동적 OpLog 사이징 (Dynamic OpLog Sizing)
OpLog는 공유 자원이지만 할당은 각 vDisk가 활용할 수 있는 동등한 기회를 보장하기 위해 vDisk 별로 수행된다. AOS 5.19 이전에는 Oplog 크기가 vdisk 당 6GB로 제한되었다. AOS 5.19부터 개별 vDisk에 대한 OpLog는 노드당 사용되는 OpLog 인덱스 메모리에 대한 한도에 도달할 때까지 IO 패턴을 기반으로 필요한 경우 6GB 이상으로 계속 커질 수 있다. 이러한 설계 변경을 통해 I/O 관점에서 I/O가 많지만 적은 수의 vDisk를 갖는 VM이 있는 경우 I/O가 적은 다른 vDisk를 희생시키면서 필요에 따라 OpLog를 계속 늘릴 수 있는 유연성을 제공한다.
익스텐트 스토어 (Extent Store)
- 주요 역할: 영구 데이터 스토리지 (Persistent data storage)
- 설명: 익스텐트 스토어는 DSF의 영구 대용량 스토리지로 모든 디바이스 계층(Optane SSD, PCIe SSD, SATA SSD, HDD)에 걸쳐 있으며, 추가 디바이스/계층을 용이하게 하기 위해 확장 가능하다. 익스텐트 스토어에 저장되는 데이터는 A) OpLog에서 배수되거나 B) 본질적으로 순차적/지속적인 데이터로 OpLog를 직접 우회했다. 뉴타닉스 ILM은 I/O 패턴, 데이터 액세스 수 및 개별 계층에 부여된 가중치를 기반으로 계층 배치를 동적으로 결정하고 계층 간에 데이터를 이동한다.
Note
순차 쓰기 특징 (Sequential Write Characterization)
쓰기 IO는 vDisk에 1.5MB 이상의 처리되지 않은 쓰기 IO가 있는 경우에 순차 쓰기로 인식된다 (AOS 4.6 현재). 이를 충족하는 IO는 이미 장렬된 데이터가 크고 병합의 이점을 활용할 수 없기 때문에 OpLog를 바이패스하여 직접 익스텐트 스토어로 이동한다.
이것은 다음 Gflag: vdisk_distributed_oplog_skip_min_outstanding_write_bytes에 의해 제어된다.
큰 IO(e.g. >64K)를 포함한 다른 모든 IO는 OpLog에 의해 처리된다.
AES (Autonomous Extent Store)
- 주요 역할: 영구 데이터 스토리지 (Persistent data storage)
- 설명: AES(Autonomous Extent Store)는 AOS 5.10에 도입된 익스텐트 스토어에서 데이터를 쓰거나 저장하는 새로운 방법이다. 주로 로컬 + 글로벌 메타데이터('메타데이터 확장성' 섹션에서 자세히 설명)를 혼합하여 메타데이터 로컬리티로 인해 훨씬 더 효율적인 성능을 유지할 수 있다. 지속적인 랜덤 쓰기 워크로드의 경우 OpLog를 바이패스하고 AES를 사용하여 익스텐트 스토어에 직접 쓴다. 버스트 랜덤 워크로드의 경우 일반적인 OpLog I/O 경로를 사용하고 가능한 경우 AES를 사용하여 익스텐트 스토어로 배수한다. AOS 5.20(LTS)부터 AES는 올-플래시 클러스터의 새로운 컨테이너에 대해 기본적으로 활성화되며 AOS 6.1(STS)부터 요구 사항이 충족되면 하이브리드(SSD+HDD) 클러스터에서 생성된 새로운 컨테이너에 AES가 활성화된다.
유니파이드 캐시 (Unified Cache)
- 주요 역할: 동적 읽기 캐시 (Dynamic read cache)
- 설명: 유니파이드 캐시는 데이터, 메타데이터 및 데이터 중복 제거에 사용되며 CVM의 메모리에 저장되는 읽기 캐시이다. 캐시에 없는 데이터의 읽기 요청이 있을 경우(또는 특정 지문을 기반으로 하는), 익스텐트 스토어에서 데이터를 읽어 완전히 메모리에 존재하는 유니파이드 캐시의 싱글-터치 풀에 배치되며, 캐시에서 제거될 때까지 LRU(Least Recently Used)를 사용한다. 이후의 모든 읽기 요청은 데이터를 멀티-터치 풀로 “이동(Move)”한다 (실제로 데이터가 이동되는 것은 아니고, 메타데이터의 캐시만 수행). 멀티-터치 풀의 데이터에 대한 모든 읽기 요청은 데이터가 멀티-터치 풀의 최고점으로 이동하여 새로운 LRU 카운터가 제공된다. 캐시 크기는 ((CVM 메모리-12GB) * 0.45) 공식을 사용하여 계산할 수 있다. 예를 들어, 32GB CVM의 캐시 크기는 ((32-12) * 0.45) == 9GB이다.
다음 그림은 유니파이드 캐시에 대한 하이-레벨 개요를 보여준다.
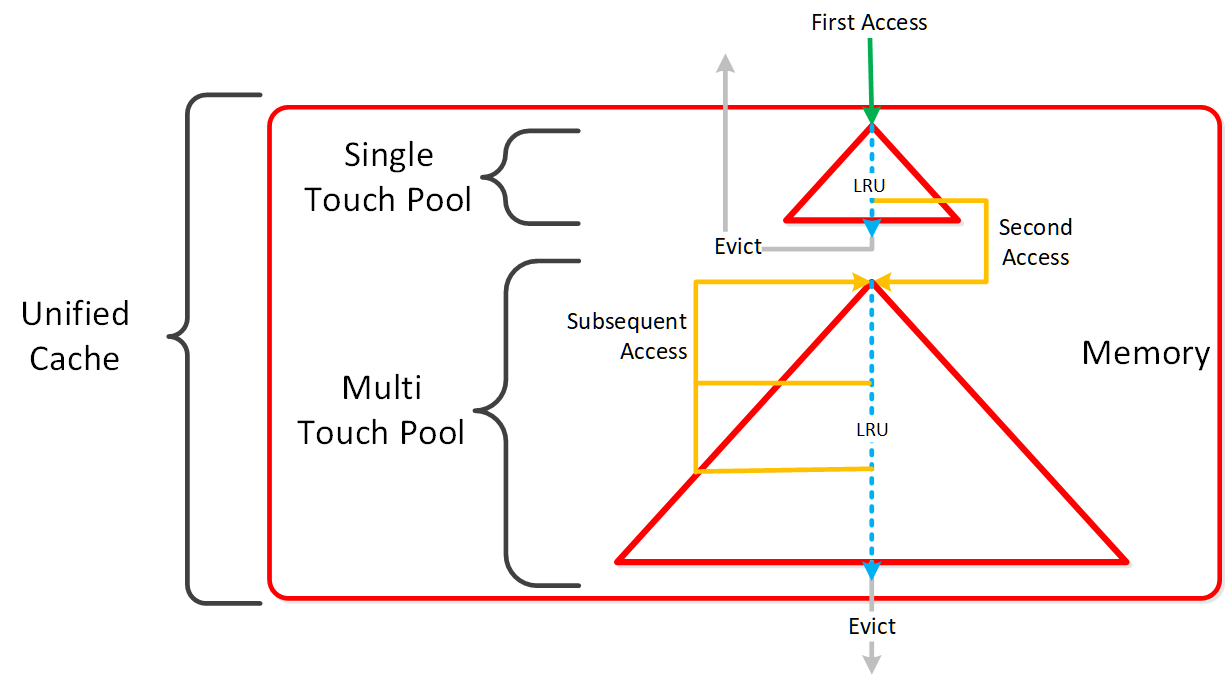 DSF 유니파이드 캐시 (DSF Unified Cache)
DSF 유니파이드 캐시 (DSF Unified Cache)
Note
캐시 세분화 및 로직 (Cache Granularity and Logic)
데이터는 4K 단위로 캐시로 가져오고 모든 캐싱 작업은 실시간으로 수행된다 (e.g. 데이터를 캐시로 가져오기 위한 지연 또는 배치 프로세스 데이터가 없음).
각 CVM에는 호스팅 하는(e.g. 동일 노드에서 실행 중인 VM) vDisk의 관리를 위한 자체 로컬 캐시가 있다. vDisk가 복제될 때 (e.g., 새로운 클론, 스냅샷 등) 각 새로운 vDisk는 자신의 블록 맵을 가지며 원본 vDisk는 “변경 불가(Immutable)”로 표시된다. 이를 통해 각 CVM은 캐시 일관성을 갖는 베이스 vDisk의 자체 캐시 복사본을 보유할 수 있다.
덮어쓰기의 경우 VM의 자체 블록 맵에서 새로운 익스텐트로 리다이렉트된다. 이렇게 하면 캐시 손상이 없다.
단일 vDisk 분할 (Single vDisk Sharding)
AOS는 대규모 애플리케이션에 대한 높은 성능을 제공하도록 설계되었다. 스타케이트 내에서 I/O는 vDisk 컨트롤러라는 것으로 생성된 모든 vDisk에 대한 스레드에 의해 처리된다. 모든 vDisk는 해당 vDisk에 대한 I/O를 담당하는 스타케이트 내부에 자체 vdisk 컨트롤러를 갖는다. 워크로드 및 애플리케이션은 시스템이 제공할 수 있는 고성능을 구동할 수 있도록 자체 vDisk 컨트롤러 스레드를 있는 여러 개의 vDisk를 갖는다.
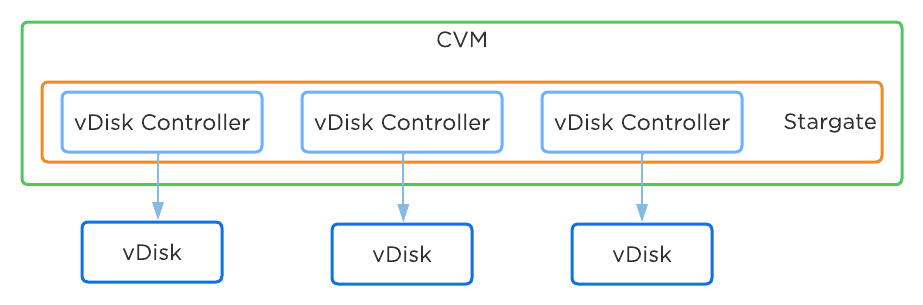
본 아키텍처는 VM이 단일 대형 vDisk를 갖는 기존 애플리케이션 및 워크로드의 경우를 제외하고는 잘 동작했다. 이러한 VM은 AOS의 기능을 최대한 활용할 수 없었다. AOS 6.1부터 vDisk 컨트롤러가 향상되어 각각 고유한 스레드가 있는 컨트롤러의 샤드(shard)를 생성하여 단일 vdisk에 대한 요청이 이제 여러 vdisk 컨트롤러에 분산된다. 여러 컨트롤러에 대한 I/O 배포는 기본 컨트롤러에서 수행하므로 외부 상호 작용의 경우 여전히 단일 vDisk처럼 보인다. 결과적으로 단일 vDisk를 효과적으로 분할하여 다중 스레드로 만든다. Blockstore와 같이 위에서 언급한 다른 기술과 함께 이러한 개선 사항을 통해 AOS는 단일 vDisk를 사용하는 기존 애플리케이션에 대해서도 규모에 맞게 일관된 고성능을 제공할 수 있다.
메타데이터 확장성
동영상 시청을 원하시면 다음 YouTube 링크를 클릭하세요: Tech TopX by Nutanix University: Scalable Metadata
메타데이터는 모든 인텔리전트 시스템의 핵심이며 모든 파일시스템 또는 스토리지 어레이에 훨씬 더 중요하다. '메타데이터(Metadata)'라는 용어에 대해 확신이 없는 사람들을 위해; 기본적으로 메타데이터는 '데이터에 대한 데이터'이다. DSF와 관련하여 성공에 중요한 몇 가지 주요 원칙이 있다.
- 시간이 100% 정확해야 한다 (“엄격한 일관성”으로 알려짐).
- ACID를 준수해야 한다.
- 무제한으로 확장할 수 있어야 한다.
- 규모에 관계없이 병목현상이 없어야 한다 (선형적인 확장성을 제공해야 한다).
AOS 5.10부터 메타데이터는 글로벌 메타데이터와 로컬 메타데이터(이전에는 모든 메타데이터가 글로벌 메타데이터 이었음)로 구분된다. 이에 대한 동기는 "메타데이터 로컬리티"를 최적화하고 메타데이터 조회를 위해 시스템의 네트워크 트래픽을 제한하는 것이다.
이러한 변경의 근거는 모든 데이터가 글로벌일 필요는 없다는 것이다. 예를 들어 모든 CVM이 특정 익스텐트가 어느 물리 디스크에 있는지 알 필요가 없으며, 어떤 노드가 그 데이터를 보유하고 있는지만 알면 되고, 단지 그 노드만 데이터가 어느 디스크에 있는지를 알면 된다.
이를 통해 시스템에 저장된 메타데이터의 양을 제한하고(로컬 전용 데이터에 대해서는 메타데이터 RF 제거) "메타데이터 로컬리티"를 최적화할 수 있다.
다음 이미지는 로컬 매타데이터와 글로벌 메타데이터의 차이점을 보여준다.
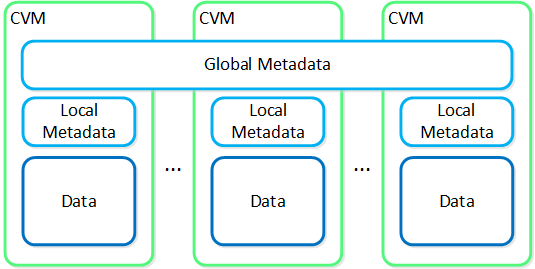 글로벌 vs. 로컬 메타데이터 (Global vs. Local Metadata)
글로벌 vs. 로컬 메타데이터 (Global vs. Local Metadata)
로컬 메타데이터 (Local Metadata)
- 설명 (Description):
- 로컬 노드에서만 필요한 정보를 포함하는 CVM 당 로컬 메타데이터 저장소. 이것은 AOS 5.10에서 도입된 AES(Autonomous Extent Store)에 의해 활용된다.
- 스토리지 매커니즘 (Storage Mechanism):
- AES DB (Rocksdb 기반)
- 저장되는 데이터 유형 (Types of data stored):
- 물리적 익스텐트/익스텐트 그룹의 배치 (e.g. egroup to disk mapping) 등
글로벌 메타데이터 (Global Metadata)
- 설명 (Description):
- 모든 CVM에서 전역적으로 사용할 수 있고 클러스터의 CVM에서 분할된 메타데이터. AOS 5.10 이전의 모든 메타 데이터.
- 스토리지 매커니즘 (Storage Mechanism):
- 메두사 저장소 (카산드라 기반)
- 저장되는 데이터 유형 (Types of data stored):
- vDisk 블록 맵, 익스텐트와 노드 매핑, 시계열 통계, 설정 등
아래 섹션에서 글로벌 매타데이터의 관리 방법을 다룬다.
위의 아키텍처 섹션에서 언급했듯이 DSF는 필수적인 메타데이터뿐만 아니라 다른 플랫폼 데이터(e.g. 통계 등)를 저장하는 키-값 스토어로 "링과 같은(ring-like)" 구조를 활용한다. 글로벌 메타데이터 가용성 및 리던던시를 보장하기 위해 홀수 노드(e.g. 3, 5 등)로 구성된 복제계수(RF)를 사용한다. 글로벌 메타데이터 쓰기 또는 갱신 시에 ROW는 해당 키를 소유한 링의 노드에 기록된 다음 n개의 피어(n은 클러스터 크기에 의존)로 복제된다. 대부분의 노드는 어떤 것이 커밋되기 전에 동의해야 하며, 이는 PAXOS 알고리즘을 사용하여 수행된다. 이를 통해 플랫폼의 일부로 저장되는 모든 데이터 및 글로벌 메타데이터의 “엄격한 일관성(Strict Consistency)”를 보장한다.
다음 그림은 4노드 클러스터에 대한 글로벌 메타데이터 삽입/업데이트의 예를 보여준다.
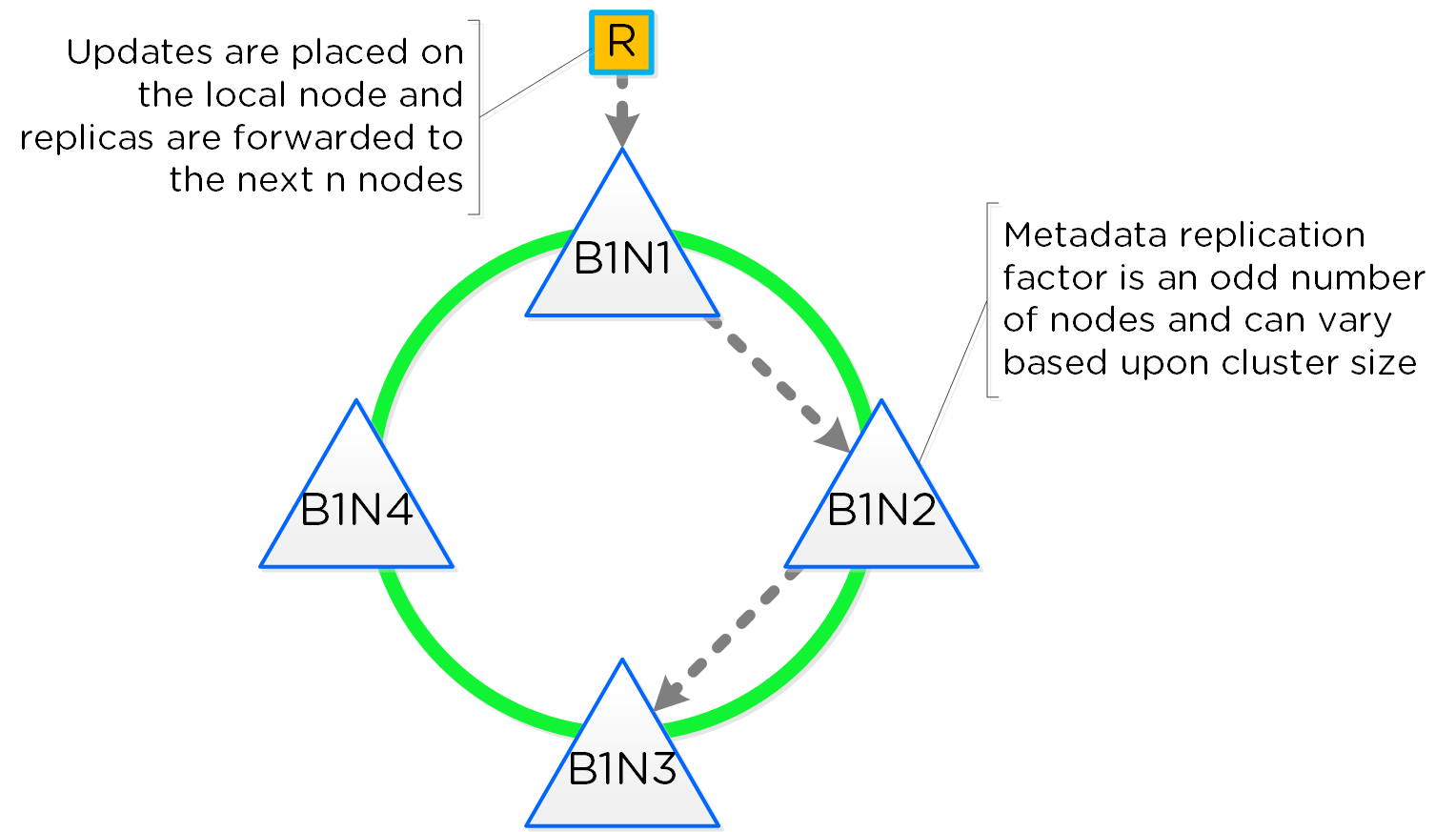 카산드라 링 구조 (Cassandra Ring Structure)
카산드라 링 구조 (Cassandra Ring Structure)
규모에 따른 성능 또한 DSF 글로벌 메타데이터의 또 다른 중요한 구조이다. 기존의 듀얼 컨트롤러 또는 “리더/워커(Leader/Worker)” 모델과 달리 각 뉴타닉스 노드는 전체 플랫폼 메타데이터의 서브셋을 담당한다. 이를 통해 클러스터의 모든 노드에서 글로벌 메타데이터를 서비스하고 조작할 수 있으므로 기존 병목현상이 제거된다. 클러스터 크기 변경(노드 "추가/제거"라고도 함) 동안 키의 재분배를 최소화하기 위해 키 파티셔닝에 일관된 해싱 스키마를 활용한다. 클러스터가 확장될 때(e.g. 4노드에서 8노드로) “블록 인식(Block Awareness)” 및 신뢰성을 위해 노드 사이의 링 전체에 노드가 삽입된다.
다음 그림은 글로벌 메타데이터 "링"의 예와 확장 방법을 보여 준다.
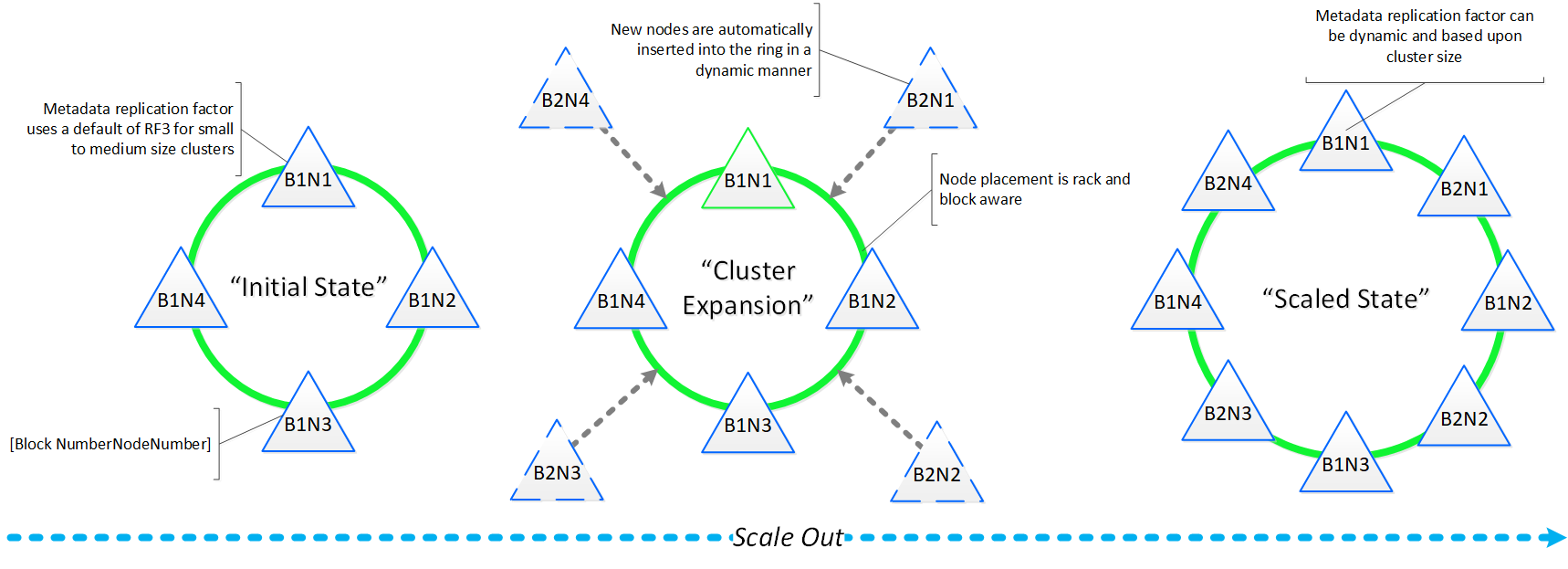 카산드라 스케일-아웃 (Cassandra Scale Out)
카산드라 스케일-아웃 (Cassandra Scale Out)
데이터 보호
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
뉴타닉스 플랫폼은 현재 복제계수(Replication Factor: RF)로 알려진 리질리언시 팩터(Resiliency Factor)와 체크섬을 사용하여 노드나 디스크 장애 또는 손상 시 데이터 리던던시와 가용성을 보장한다. 위에서 설명한 바와 같이 OpLog는 들어오는 쓰기를 레이턴시가 짧은 SSD 티어에 흡수하기 위한 스테이징 영역의 역할을 한다. 로컬 OpLog에 쓰면 데이터는 호스트에 상공적인 쓰기로 승인(ACK) 되기 전에 다른 하나 또는 두 개의 뉴타닉스 CVM의 OpLog(RF에 의존)에 동기적으로 복제된다. 이를 통해 데이터가 적어도 두 개 또는 세 개의 독립적인 위치에 존재하므로 폴트 톨러런트를 지원한다. NOTE: RF3인 경우 메타데이터가 RF5이므로 최소 5개의 노드가 필요하다.
OpLog 피어는 모든 에피소드(1GB의 vDisk 데이터)에 대해 선택되며 모든 노드가 적극적으로 참여한다. 피어를 선택하기 위해 다양한 변수(응답 시간, 업무량, 용량 사용률 등)가 고려된다. 이렇게 하면 단편화를 제거하고 모든 CVM/OpLog의 동시에 사용할 수 있다.
데이터 RF는 프리즘에서 설정하며 컨테이너 레벨에서 수행된다. 모든 노드가 OpLog 복제에 참여하여 “핫 노드”를 제거하고 확장 시 선형적인 성능을 보장한다. 데이터를 쓰는 동안 체크섬이 계산되고 메타데이터의 일부로 저장된다. 그런 다음 데이터는 RF가 절대적으로 유지되는 익스텐트 스토어로 비동기적으로 배수된다. 노드 또는 디스크 장애의 경우 데이터는 RF를 유지하기 위해 클러스터의 모든 노드 간에 재복제된다. 데이터를 읽을 때마다 데이터가 유효한지 확인하기 위해 체크섬이 계산된다. 체크섬과 데이터가 일치하지 않으면 데이터의 복제본을 읽고 유효하지 않는 복사본을 대체한다.
액티브 I/O가 발생하지 않는 경우에도 데이터는 무결성을 보장하기 위해 지속적으로 모니터링된다. 스타게이트의 스크라버(Scrubber) 오퍼레이션은 디스크를 많이 사용하지 않을 경우 익스텐트 그룹을 지속적으로 스캔하고 체크섬 유효성 검사를 수행한다. 이것은 비트 부패(Bit Rot) 또는 손상된 섹터와 같은 것을 방지한다.
다음 그림은 이것이 논리적으로 어떻게 보이는지에 대한 예를 보여준다.
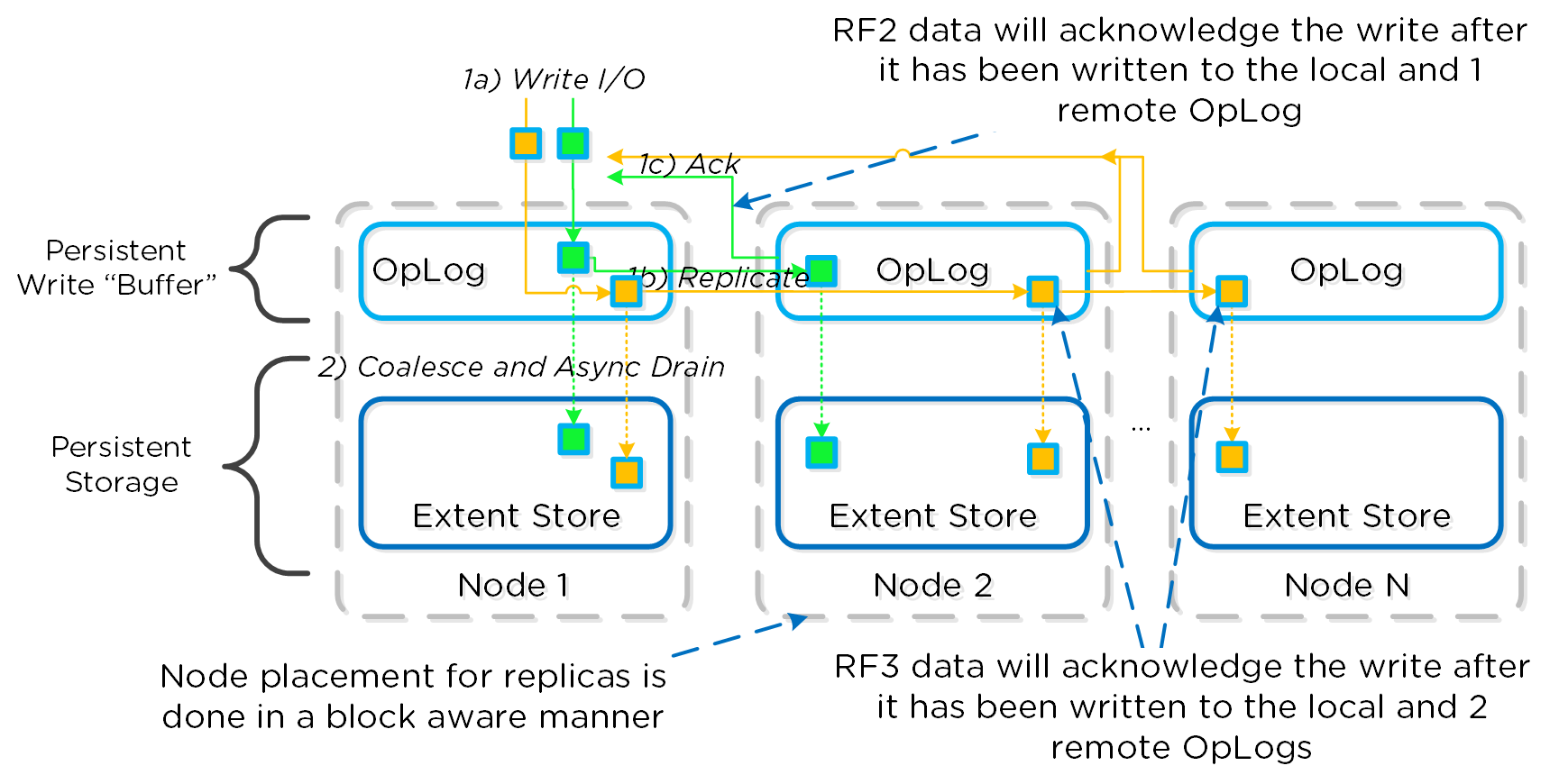 DSF 데이터 보호 (DSF Data Protection)
DSF 데이터 보호 (DSF Data Protection)
가용성 도메인
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
가용성 도메인(노드/블록/랙 인식으로 알려진)은 분산 시스템이 컴포넌트 및 데이터 배치를 결정하기 위해 준수해야 하는 핵심 구조이다. 뉴타닉스에서 "블록(Block)"은 한 개, 두 개 또는 네 개의 서버 "노드(Node)"를 포함하는 섀시를 의미하고, "랙(Rack)"은 한 개 이상의 "블록"을 포함하는 물리적 유닛이다. NOTE: 블록 인식(Block Awareness)을 활성화하려면 최소 3개 이상의 블록을 사용하어야 하고, 그렇지 않으면 노드 인식(Node Awareness) 기능이 사용된다.
뉴타닉스는 현재 다음 레벨 또는 인식 기능을 지원한다.
- 디스크 (항상)
- 노드 (항상)
- 블록 (AOS 4.5 기준)
- 랙 (AOS 5.9 기준)
인식 기능을 활성화하고 불균형이 발생하지 않도록 하기 위해서는 동일 사양의 블록/랙을 사용하는 것이 좋다. 일반적인 시나리오와 활용되는 인식 레벨은 본 세션의 맨 아래에서 설명한다. 3블록 요구 사항은 쿼럼을 보장하기 위한 것이다. 예를 들어 3450은 4개의 노드를 갖는 블록이다. 블록에 역할 또는 데이터를 분산하는 이유는 블록 장애가 발생하거나 유지보수가 필요한 경우 시스템이 중단 없는 계속 실행될 수 있도록 하기 위한 것이다. NOTE: 블록 내에서 리던던트 PSU와 팬이 유일한 공유 컴포넌트이다.
NOTE: 랙 인식 기능을 사용하려면 관리자가 블록을 배치할 "랙"을 정의해야 한다.
다음은 이것이 프리즘에서 어떻게 설정되는지 보여준다.
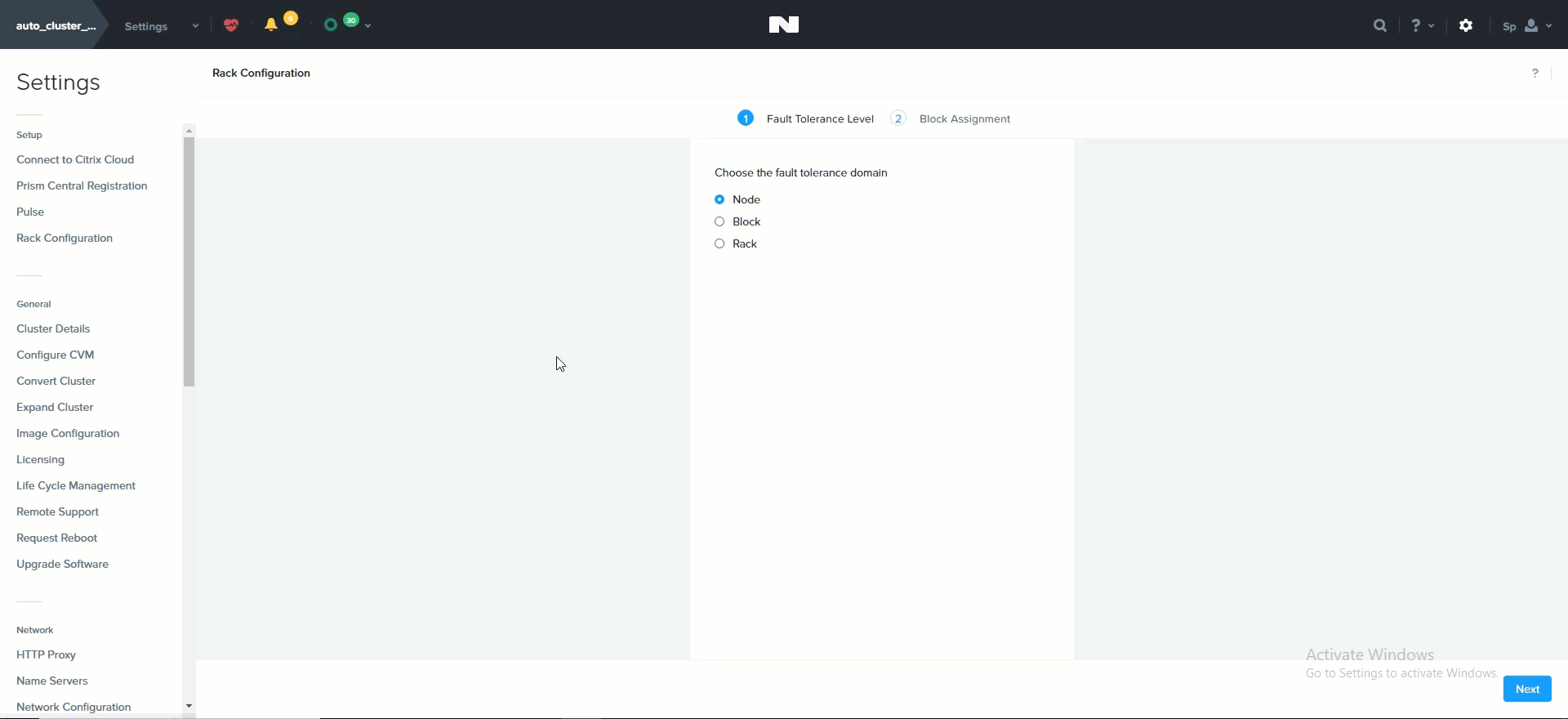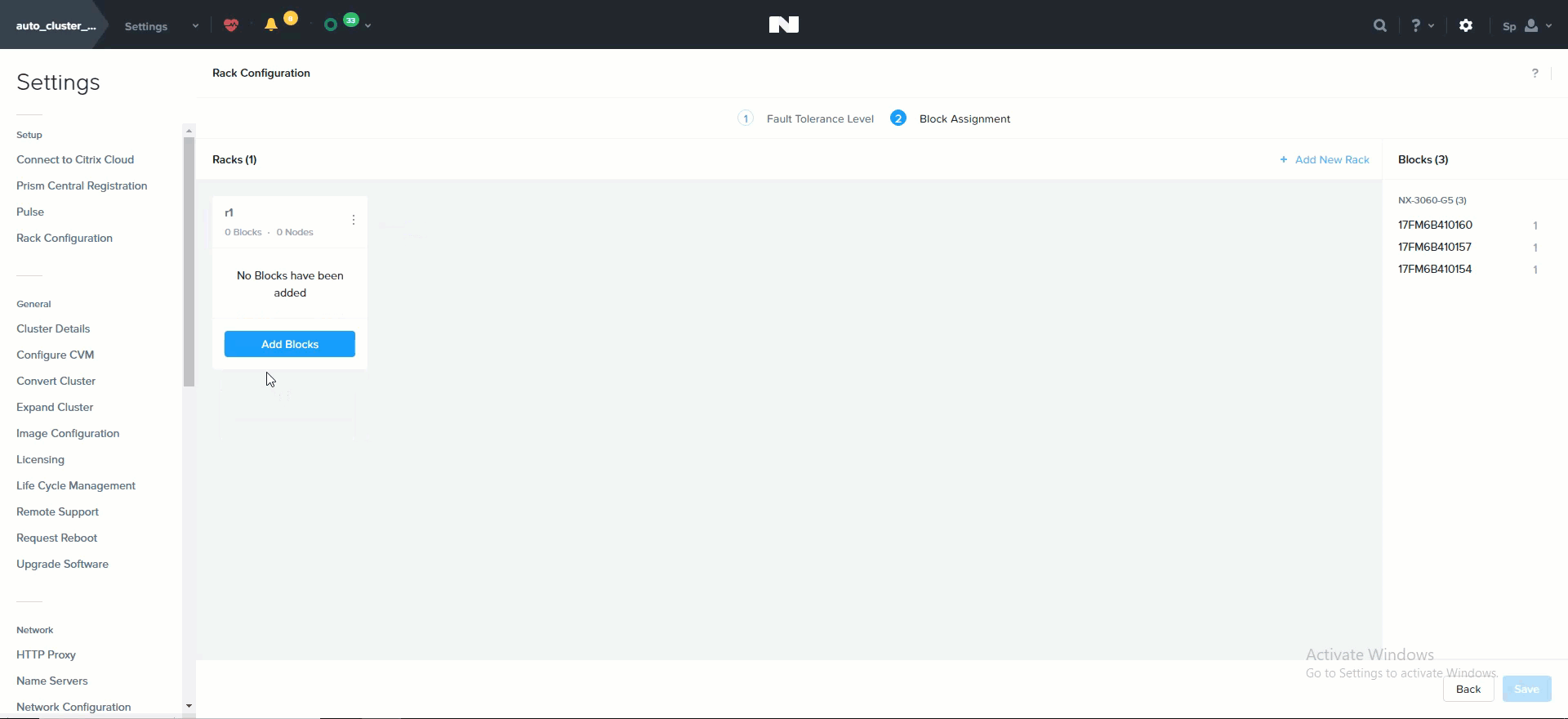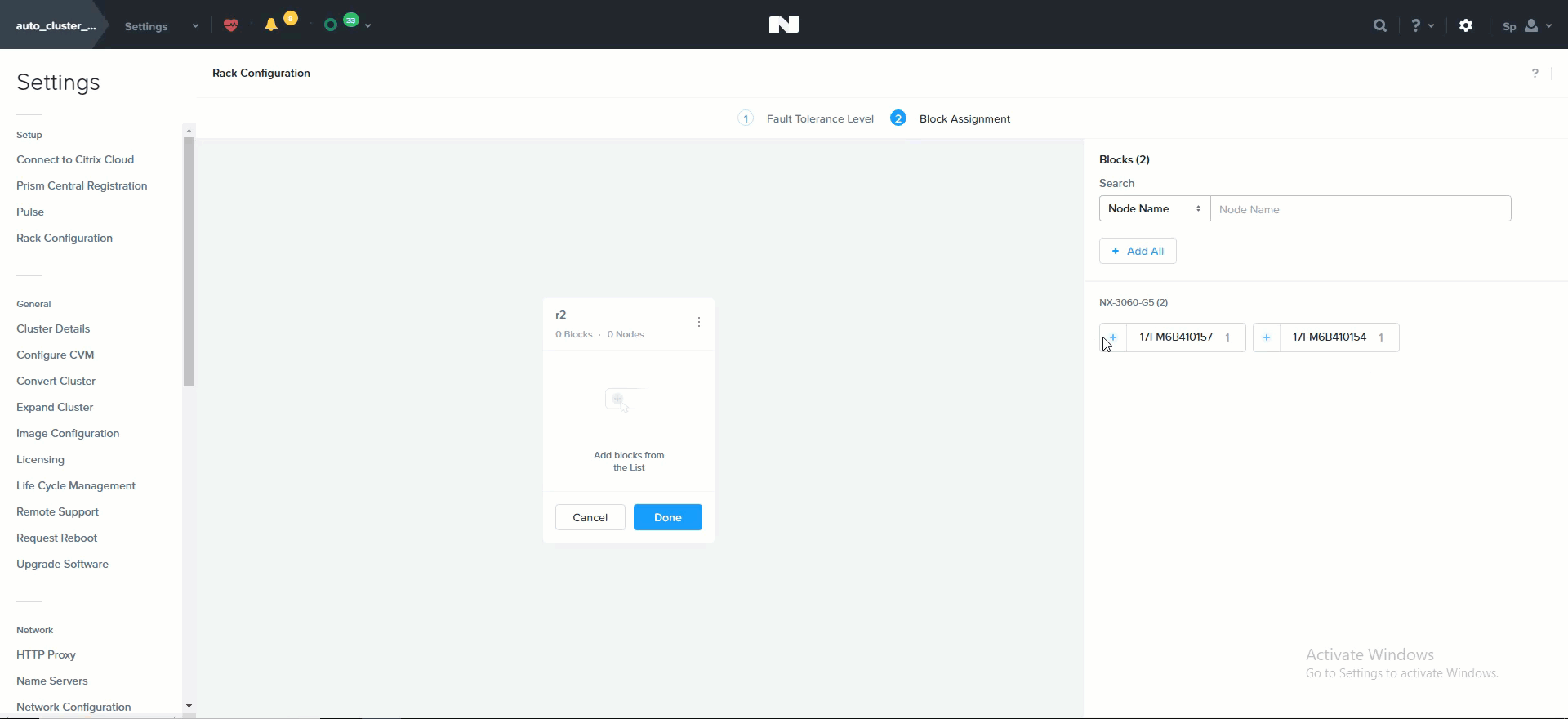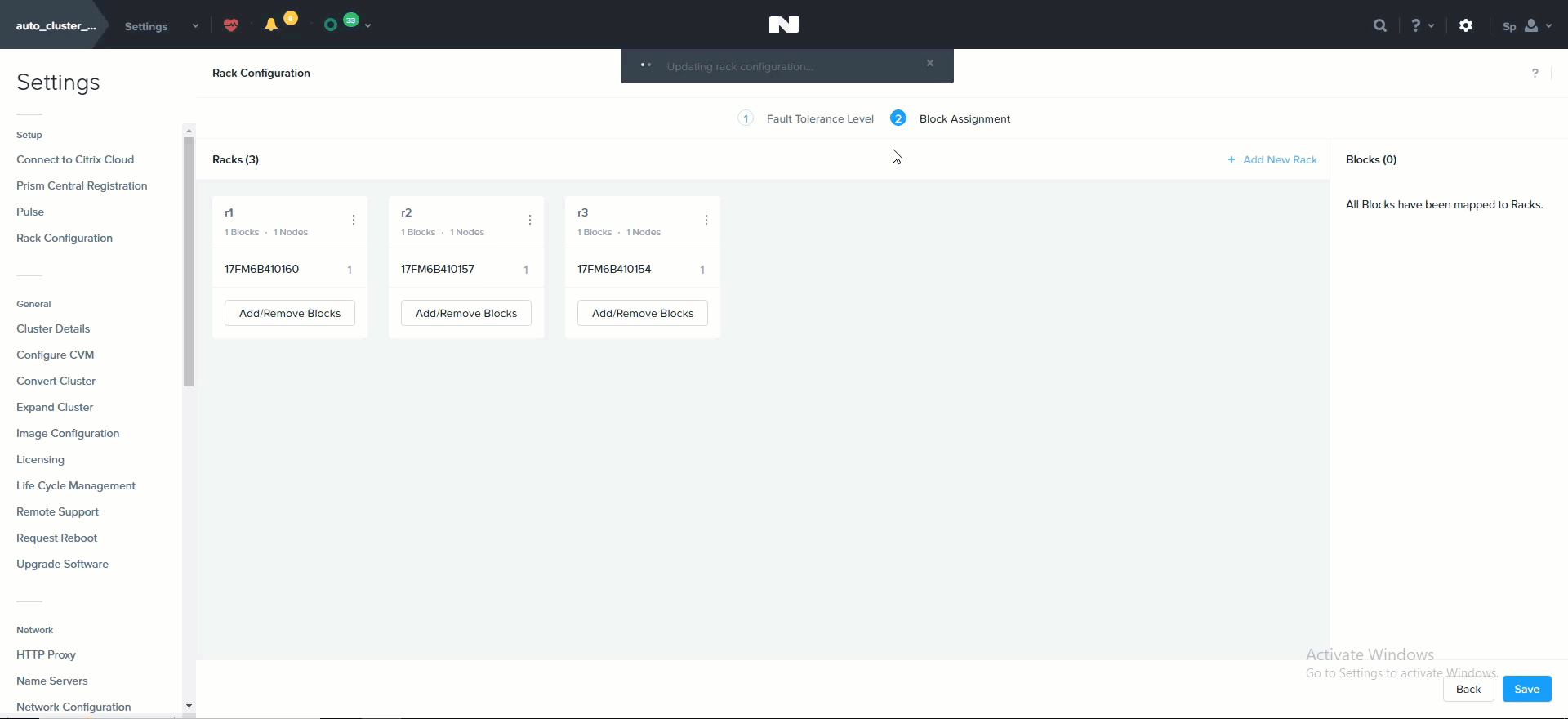 랙 설정 (Rack Configuratioon)
랙 설정 (Rack Configuratioon)
인식 기능은 몇 가지 주요 중점 영역으로 나눌 수 있다.
- 데이터 (VM 데이터)
- 메타데이터 (카산드라)
- 설정 데이터 (주키퍼)
데이터 (Data)
DSF를 사용하면 데이터 복제본이 클러스터의 다른 [블록/랙]에 저장되어 [블록/랙] 장애 또는 계획된 다운타임의 경우에도 데이터를 계속 사용할 수 있다. 이는 [블록/랙] 장애의 경우뿐만 아니라 RF2 및 RF3 시나리오 모두에 적용된다. 쉽게 비교할 수 있는 “노드 인식 기능”은 복제본을 다른 노드로 복제하여 노드 장애 시 데이터 보호 기능을 제공한다. 블록 및 랙 인식 기능은 노드 인식 기능을 향상하여 [블록/랙] 중단 시에 데이터 가용성을 보장한다.
다음 그림은 3블록 배포에서 복제본 배치가 동작하는 방식을 보여준다.
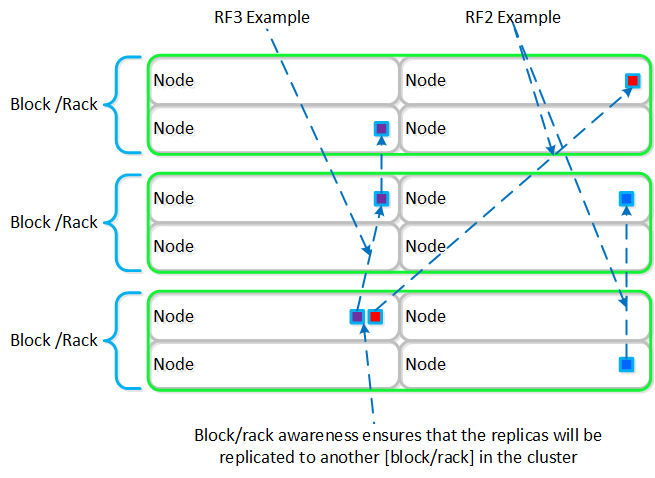 블록/랙 인식 기반 복제본 배치 (Block/Rack Aware Replica Placement)
블록/랙 인식 기반 복제본 배치 (Block/Rack Aware Replica Placement)
[블록/랙] 장애의 경우 [블록/랙] 인식 기능이 유지되고(가능한 경우에) 데이터는 클러스터 내의 다른 [블록/랙]에 복제된다.
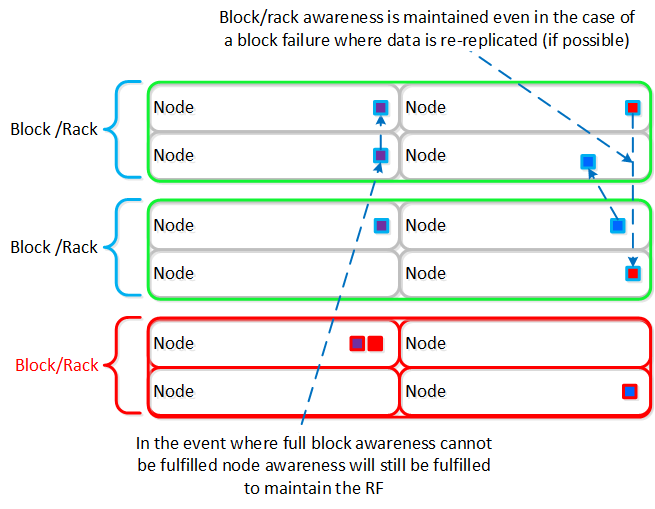 블록/랙 장애 시의 복제본 배치 (Block/Rack Failure Replica Placement)
블록/랙 장애 시의 복제본 배치 (Block/Rack Failure Replica Placement)
Note
랙/블록 인식 및 메트로 클러스터링 (Rack/Block Awareness vs. Metro clustering)
일반적인 질문은 두 위치 (방, 건물 등)에 걸쳐 클러스터를 확장하고 블록/랙 인식을 사용하여 위치 장애에 대한 리질리언시를 제공할 수 있는가 하는 것이다.
이론적으로는 가능하지만 권장되는 방법은 아니다. 먼저 우리가 달성하려고 하는 것에 대해 생각해 보아야 한다.
- 낮은 RPO
- 낮은 RTO (DR 이벤트 대신에 HA 이벤트)
RPO ~0을 달성하려는 첫 번째 경우를 고려하면 동기식 또는 NearSync 복제를 사용하는 것이 좋다. 이는 적은 위험을 가지면서도 동일한 RPO를 제공한다.
RTO를 최소화하기 위해서는 동기식 복제를 기반으로 메트로 클러스터를 활용하고 DR 복구를 수행하는 대신 장애를 HA 이벤트로 처리할 수 있다.
요약하면 다음과 같은 이유로 동기식 복제/메트로 클러스터링을 사용하는 것이 좋다.
- 동기 복제/메트로 클러스터링으로 동일한 결과를 얻을 수 있으므로 위험을 회피하고 격리된 장애 도메인 유지
- 지원되지 않는 "확장된(Stretched)" 배포에서 두 위치 간에 네트워크 연결이 끊어지면 쿼럼을 유지 관리해야 하므로 한쪽이 다운된다(e.g. 큰 쪽은 계속 유지됨). 메트로 클러스터 시나리오에서 양쪽 모두 독립적으로 계속 동작할 수 있다.
- 데이터의 가용성 도메인 배치는 왜곡된(Skewed) 시나리오에서 최선의 방법으로 동작한다.
- 두 사이트 간의 추가적인 레이턴시/네트워크 대역폭 감소는 "확장된" 배포에서 성능에 영향을 줄 수 있다.
인식 조건 및 톨러런스 (Awareness Conditions and Tolerance)
아래에서 일반적인 시나리오 및 톨러런스 레벨을 분석한다.
| 원하는 인식 유형 (Desired Awareness Type) | FT 레벨 (FT Level) | EC 활성화 여부 (EC Enabled?) | 최소 유닛 (Min. Units) | 동시 장애 허용 (Simultaneous failure tolerance) |
|---|---|---|---|---|
| Node | 1 | No | 3 Nodes | 1 Node |
| Node | 1 | Yes | 4 Nodes | 1 Node |
| Node | 2 | No | 5 Nodes | 2 Node |
| Node | 2 | Yes | 6 Nodes | 2 Nodes |
| Block | 1 | No | 3 Blocks | 1 Block |
| Block | 1 | Yes | 4 Blocks | 1 Block |
| Block | 2 | No | 5 Blocks | 2 Blocks |
| Block | 2 | Yes | 6 Blocks | 2 Blocks |
| Rack | 1 | No | 3 Racks | 1 Rack |
| Rack | 1 | Yes | 4 Racks | 1 Rack |
| Rack | 2 | No | 5 Racks | 2 Racks |
| Rack | 2 | Yes | 6 Racks | 2 Racks |
AOS 베이스 소프트웨어 4.5 이상의 버전에서 블록 인식은 최선의 노력이며 사용에 대한 엄격한 요구 사항이 없다. 이는 왜곡된 스토리지 자원(e.g. 스토리지 중심의 노드)을 갖는 클러스터가 기능을 비활성화하지 않도록 하기 위한 것이다. 그러나 명시된 바와 같이 스토리지 왜곡을 최소화하기 위해 동일한 사양의 블록을 사용하는 것이 가장 좋다.
AOS 4.5 이전 버전에서 블록 인식을 위해서는 다음 조건이 충족되어야 한다.
- 블록 간의 SSD 또는 HDD 티어의 분산 > 최대 분산: 노드 인식 기능
- 블록 간의 SSD 또는 HDD 티어의 분산 < 최대 분산: 블록 + 노드 인식 기능
최대 티어 분산은 100 / (RF + 1)로 계산한다.
- RF2인 경우에는 33%, RF3인 경우에는 25%
메타데이터 (Metadata)
메타데이터 확장성 섹션에서 설명한 것과 같이 뉴타닉스는 대폭 수정된 카산드라 플랫폼을 사용하여 메타데이터 및 기타 필수 정보를 저장한다. 카산드라는 “링과 같은(Ring-like)” 구조를 활용하고 링 내에서 n개의 피어에 복제하여 데이터 일관성 및 가용성을 보장한다.
다음 그림은 12노드 클러스터에 대한 카산드라 링의 예를 보여준다.
 12노드 카산드라 링 (Node Cassandra Ring)
12노드 카산드라 링 (Node Cassandra Ring)
카산드라 피어 복제는 링 전체에서 시계 방향으로 노드에 반복된다. [블록/랙] 인식을 통해 피어를 [블록/랙] 사이에 분산시켜 두 피어가 동일 [블록/랙]에 있지 않도록 한다.
다음 그림은 위의 링을 [블록/랙] 기반 레이아웃으로 변환하는 노드 레이아웃 예를 보여준다.
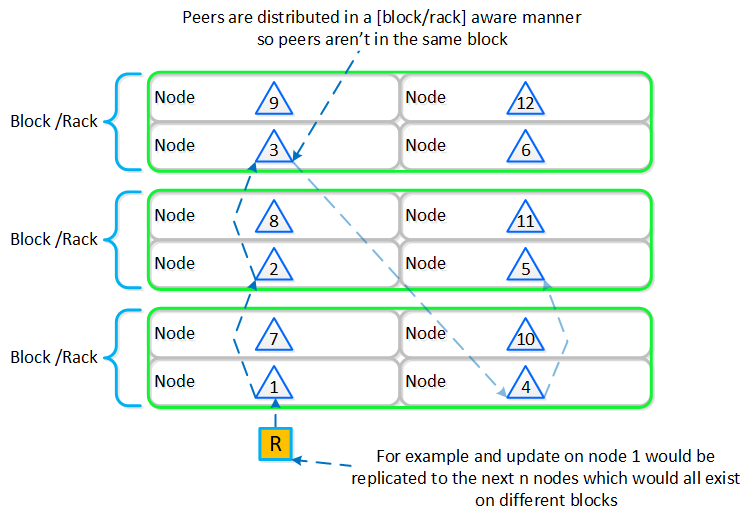 블록/랙 인식 기능을 반영한 카산드라 노드 배치 (Cassandra Node Block/Rack Aware Placement)
블록/랙 인식 기능을 반영한 카산드라 노드 배치 (Cassandra Node Block/Rack Aware Placement)
이러한 [블록/랙] 인식 특성을 통해 [블록/랙]에 장애가 발생해도 적어도 두 개의 데이터 복사본이 존재한다 (메타데이터 RF3인 경우 – 대규모의 클러스터에서는 RF5를 사용할 수 있다).
다음 그림은 링을 구성하기 위한 모든 노드 복제 토폴로지의 예를 보여준다 (조금 복잡하다).
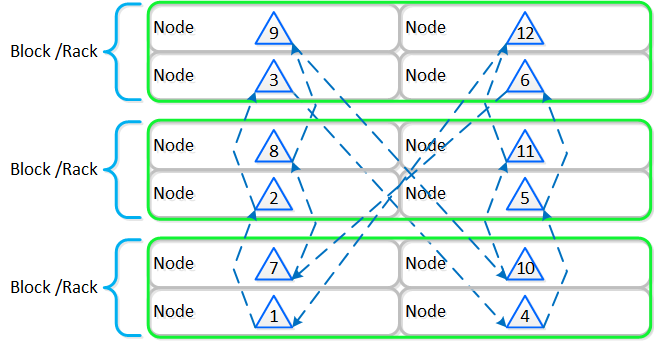 블록/랙 인식 기능을 반영한 전체 카산드라 노드 배치 (Full Cassandra Node Block/Rack Aware Placement)
블록/랙 인식 기능을 반영한 전체 카산드라 노드 배치 (Full Cassandra Node Block/Rack Aware Placement)
Note
메타데이터 인식 조건 (Metadata Awareness Conditions)
아래에서 몇 가지 일반적인 시나리오 및 어떤 레벨의 인식 기능이 활용되는지 알아본다.
- FT1 (Data RF2 / Metadata RF3) will be block aware if:
- >= 3 blocks
- Let X be the number of nodes in the block with max nodes. Then, the remaining blocks should have at least 2X nodes.
-
Example: 4 blocks with 2,3,4,2 nodes per block respectively.
- The max node block has 4 nodes which means the other 3 blocks should have 2x4 (8) nodes. In this case it WOULD NOT be block aware as the remaining blocks only have 7 nodes.
-
Example: 4 blocks with 3,3,4,3 nodes per block respectively.
- The max node block has 4 nodes which means the other 3 blocks should have 2x4==8 nodes. In this case it WOULD be block aware as the remaining blocks have 9 nodes which is above our minimum.
-
Example: 4 blocks with 2,3,4,2 nodes per block respectively.
- FT2 (Data RF3 / Metadata RF5) will be block aware if:
- >= 5 blocks
- Let X be the number of nodes in the block with max nodes. Then, the remaining blocks should have at least 4X nodes.
-
Example: 6 blocks with 2,3,4,2,3,3 nodes per block respectively.
- The max node block has 4 nodes which means the other 3 blocks should have 4x4==16 nodes. In this case it WOULD NOT be block aware as the remaining blocks only have 13 nodes.
-
Example: 6 blocks with 2,4,4,4,4,4 nodes per block respectively.
- The max node block has 4 nodes which means the other 3 blocks should have 4x4==16 nodes. In this case it WOULD be block aware as the remaining blocks have 18 nodes which is above our minimum.
-
Example: 6 blocks with 2,3,4,2,3,3 nodes per block respectively.
설정 데이터 (Configuration Data)
뉴타닉스는 주키퍼를 활용하여 클러스터에 대한 필수 설정 데이터를 저장한다. 이 역할은 [블록/랙] 인식 방식으로 분산되어 [블록/랙] 장애 시 가용성을 보장한다.
다음 그림은 [블록/랙] 인식 방식으로 분산된 3개의 주키퍼 노드를 보여주는 예제 레이아웃을 보여준다.
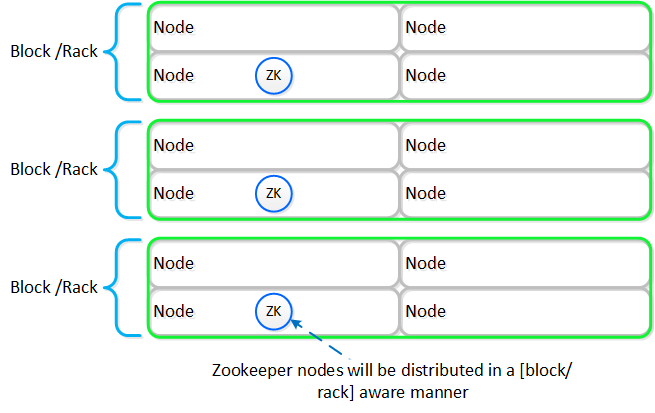 블록/랙 인식 기능을 적용한 주키퍼 노드의 배치 (Zookeeper Block/Rack Aware Placement)
블록/랙 인식 기능을 적용한 주키퍼 노드의 배치 (Zookeeper Block/Rack Aware Placement)
[블록/랙] 장애가 발생하면 주키퍼 노드 중의 하나가 없어지고, 주키퍼 역할이 아래와 같이 클러스터의 다른 노드로 전송된다.
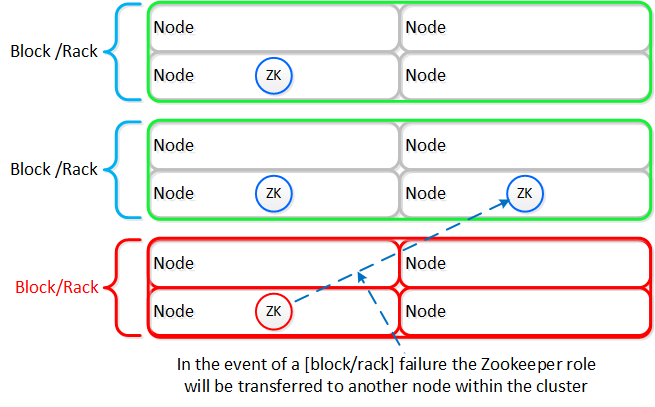 블록/랙 장애 시에 주키퍼 노드의 배치 (Zookeeper Placement Block/Rack Failure)
블록/랙 장애 시에 주키퍼 노드의 배치 (Zookeeper Placement Block/Rack Failure)
[블록/랙]이 다시 온라인 상태가 되면 [블록/랙] 인식을 유지하기 주키퍼 역할이 원래 노드로 복원된다.
NOTE: AOS 4.5 이전 버전에서는 이 마이그레이션이 자동이 아니므로 수동으로 수행해야 한다.
데이터 경로 리질리언시
DSF 또는 기본 스토리지 플랫폼에서 가장 중요한 개념은 아니더라도 안정성과 리질리언시가 핵심이다.
하드웨어가 안정적이라는 아이디어를 기반으로 구축된 기존 아키텍처와 달리 뉴타닉스는 다른 접근 방법을 취한다: 하드웨어는 결국 고장 날 것으로 예상한다. 그렇게 함으로써 시스템은 우아하고 중단 없는 방식으로 이러한 장애를 처리하도록 설계되었다.
NOTE: 이것은 하드웨어 품질이 좋지 않다는 것이 아니라 개념이 바뀌었다는 것을 의미한다. 뉴타닉스 하드웨어 및 QA 팀은 매우 철저한 인증 및 심사 프로세스를 수행한다.
이전 섹션에서 언급했듯이 메타데이터 및 데이터는 클러스터 FT 레벨을 기반으로 하는 RF를 사용하여 보호된다. AOS 5.0 현재 지원되는 FT 레벨은 메타데이터 RF3 및 데이터 RF2에 대응되는 FT1과 메타데이터 RF5 및 데이터 RF3에 대응되는 FT2이다.
메타데이터 분할 방법에 대한 자세한 내용은 “메타데이터 확장성” 섹션을 참조한다. 데이터 보호 방법에 대한 자세한 내용은 “데이터 보호” 섹션을 참조한다.
정상 상태에서 클러스터 데이터 레이아웃은 다음과 유사하다.
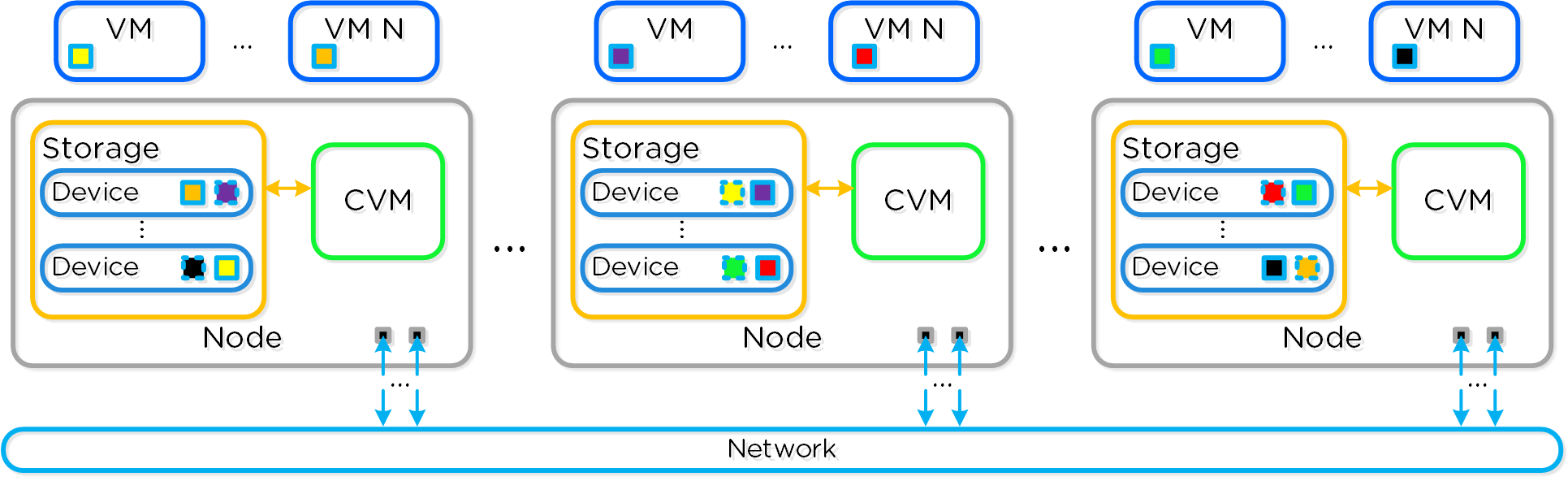 데이터 패스 리질리언시 – 정상 상태 (Data Path Resiliency - Normal State)
데이터 패스 리질리언시 – 정상 상태 (Data Path Resiliency - Normal State)
VM/vDisk 데이터는 노드와 관련 스토리지 디바이스에 분산되어 있는 디스크에 2개 또는 3개의 복사본을 가지고 있다.
Note
데이터 분산의 중요성 (Importance of Data Distribution)
메타데이터와 데이터가 모든 노드 및 모든 디스크 디바이스에 분산되도록 하여 정상적인 데이터 수집 및 재보호 시 가능한 최고의 성능을 보장할 수 있다.
데이터가 시스템에 수집되면 기본 및 복제본 복사본이 로컬 및 다른 모든 원격 노드에 분산된다. 이렇게 하면 잠재적인 핫스팟(e.g. 노드 또는 디스크 성능이 느림)을 제거하고 일관된 쓰기 성능을 보장할 수 있다.
데이터를 재보호하여야 할 디스크 또는 노드 장애가 발생한 경우 클러스터의 모든 자원을 재구축에 사용할 수 있다. 이 경우 메타데이터 스캔(장애 발생 디바이스의 데이터와 복제본의 존재 위치를 찾기 위해)이 모든 CVM에 균등하게 분산된다. 데이터 복제본이 발견되면 모든 정상 CVM, 디스크 디바이스(SSD + HDD) 및 호스트 네트워크 업링크를 동시에 사용하여 데이터 재구축할 수 있다.
예를 들어 디스크가 고장 난 4노드 클러스터에서 각 CVM은 메타데이터 스캔 및 데이터 재구축의 25%를 처리한다. 10노드 클러스터에서 각 CVM은 메타데이터 스캔 및 데이터 재구축의 10%를 처리한다. 50노드 클러스터에서 각 CVM은 메타데이터 스캔 및 데이터 재구축의 2%를 처리한다.
Key Point: 뉴타닉스를 사용하여 데이터의 균일한 분산을 보장함으로써 일관된 쓰기 성능과 훨씬 우수한 재보호 기간을 보장할 수 있다. 이것은 클러스터 전체 액티비티에도 적용된다 (e.g. Erasure Coding, 압축, 중복제거 등).
HA 쌍이 사용되거나 단일 디스크가 모든 데이터 사본을 가지고 있는 다른 솔루션과 비교할 때, 미러링 된 노드/디스크가 과중한 경우(과중한 IO 또는 자원 제약에 직면한 경우) 프런트엔드 성능 이슈에 직면하게 된다.
또한 데이터를 재보호해야 하는 장애가 발생한 경우 단일 스토리지 컨트롤러, 단일 노드의 디스크 자원 및 단일 노드의 네트워크 업링크에 의해 제한된다. 테라바이트의 데이터를 재복제해야 하는 경우 로컬 노드의 디스크 및 네트워크 대역폭에 의해 심각하게 제한되어 다른 장애가 발생할 경우 시스템이 잠재적인 데이터 손실 상태에 있는 시간이 증가한다.
잠재적인 장애 레벨 (Potential levels of failure)
분산 시스템인 DSF는 몇 가지 레벨로 특성화할 수 있는 컴포넌트, 서비스 및 CVM 장애를 처리하도록 설계되었다.
- 디스크 장애 (Disk Failure)
- CVM 장애 (CVM Failure)
- 노드 장애 (Node Failure)
Note
재구축은 언제 시작되는가? (When does a rebuild begin?)
계획되지 않은 장애가 발생하면(어떤 경우에 올바르게 동작하지 않을 경우 사전에 오프라인 상태로 전환) 재구축 프로세스는 즉시 시작된다.
재구축을 위해 60분을 기다리고 그 기간 동안 하나의 복사본만 유지(매우 위험하고 어떠한 종류의 장애가 발생하면 데이터가 손실될 수 있음)하는 다른 벤더와 달리, 뉴타닉스는 잠재적으로 더 높은 스토리지 활용률을 희생하면서 그러한 위험을 감수할 용의가 없다.
뉴타닉스는 다음과 같은 이유로 재구축을 즉시 시작할 수 있다: a) 메타 데이터의 세분성 b) 쓰기 RF를 위해 동적으로 피어 선택(장애 발생 동안 모든 새로운 데이터(e.g. 새로운 쓰기/덮어쓰기)는 설정된 RF를 유지) c) 뉴타닉스는 재구축 중에 온라인으로 돌아오는 것을 처리할 수 있으며 유효성이 검증된 데이터는 다시 승인할 수 있다. 이 시나리오에서 큐레이터 스캔이 시작되어 과복제된 복사본을 제거하는 데이터가 과복제될 수 있다.
디스크 장애 (Disk Failure)
디스크 장애는 제거되었거나 장애가 발생하였거나 응답하지 않거나 I/O 에러가 있는 디스크로 특징지을 수 있다. 스타게이트가 I/O 에러를 확인하거나 디바이스가 특정 임계 값 이내에 응답하지 않으면 디스크가 오프라인 상태로 표시된다. 그런 일이 발생하면 하데스(Hades)는 S.M.A.R.T를 실행하고 디바이스 상태를 체크한다. 스타게이트가 디스크를 여러 번 (현재 1시간에 3번) 오프라인으로 표시하면 하데스는 S.M.A.R.T 테스트를 통과하더라도 디스크를 온라인으로 표시하는 것을 중단한다.
VM에 미치는 영향은 다음과 같다.
- HA 이벤트: 없음
- I/O 실패: 없음
- 레이턴시: 영향 없음
디스크 장애가 발생하면 큐레이터 스캔(맵리듀스 프레임워크)이 즉시 시작된다. 메타데이터(카산드라)를 스캔하여 이전에 장애가 발생한 디스크에 있었던 데이터와 복제본이 있는 노드/디스크를 찾는다.
"재복제" 해야 하는 데이터가 발견되면 복제 태스크가 클러스터의 전체 노드에 분산된다.
이 프로세스 동안 불량 디스크에 대한 드라이브 자체 테스트(DST)가 시작되고 SMART 로그에서 에러가 모니터링된다.
다음 그림은 디스크 장애 및 재보호의 예를 보여준다.
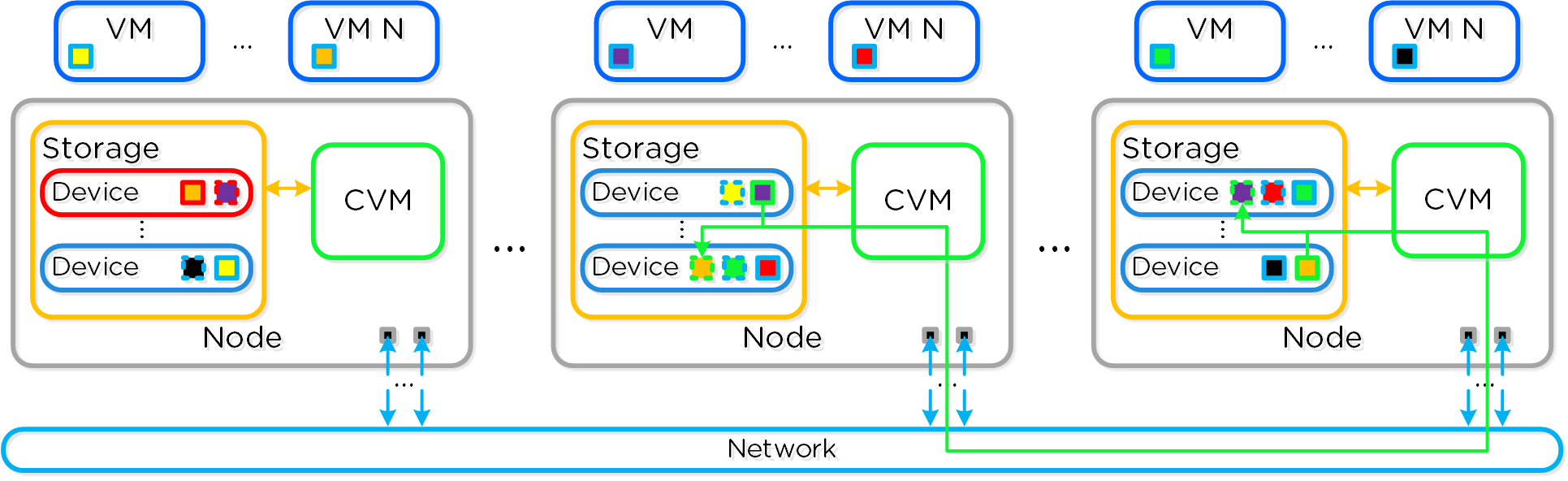 데이터 경로 리질리언시 – 디스크 장애 (Data Path Resiliency - Disk Failure)
데이터 경로 리질리언시 – 디스크 장애 (Data Path Resiliency - Disk Failure)
여기서 강조해야 할 중요한 사항은 뉴타닉스가 모든 노드/CVM/디스크에 데이터 및 복제본을 분산하는 방법이다: 모든 노드/CVM/디스크가 재복제에 참여한다.
전체 클러스터의 자원을 활용할 수 있으므로 재보호에 필요한 시간을 크게 줄여준다: 클러스터가 클수록 재보호 속도가 빨라진다.
노드 장애 (Node Failure)
VM에 미치는 영향은 다음과 같다.
- HA 이벤트: 발생
- I/O 실패: 없음
- 레이턴시: 영향 없음
노드 장애가 발생하면 가상화 클러스터 전체의 다른 노드에서 VM을 재시작하는 VM HA 이벤트가 발생한다. 재시작하면 VM은 평소처럼 로컬 CVM에서 처리하는 I/O를 수행한다.
위의 디스크 장애와 마찬가지로 큐레이터 스캔은 이전 노드에 있던 데이터 및 복제본을 찾는다. 복제본이 발견되면 모든 노드가 재보호에 참여한다.
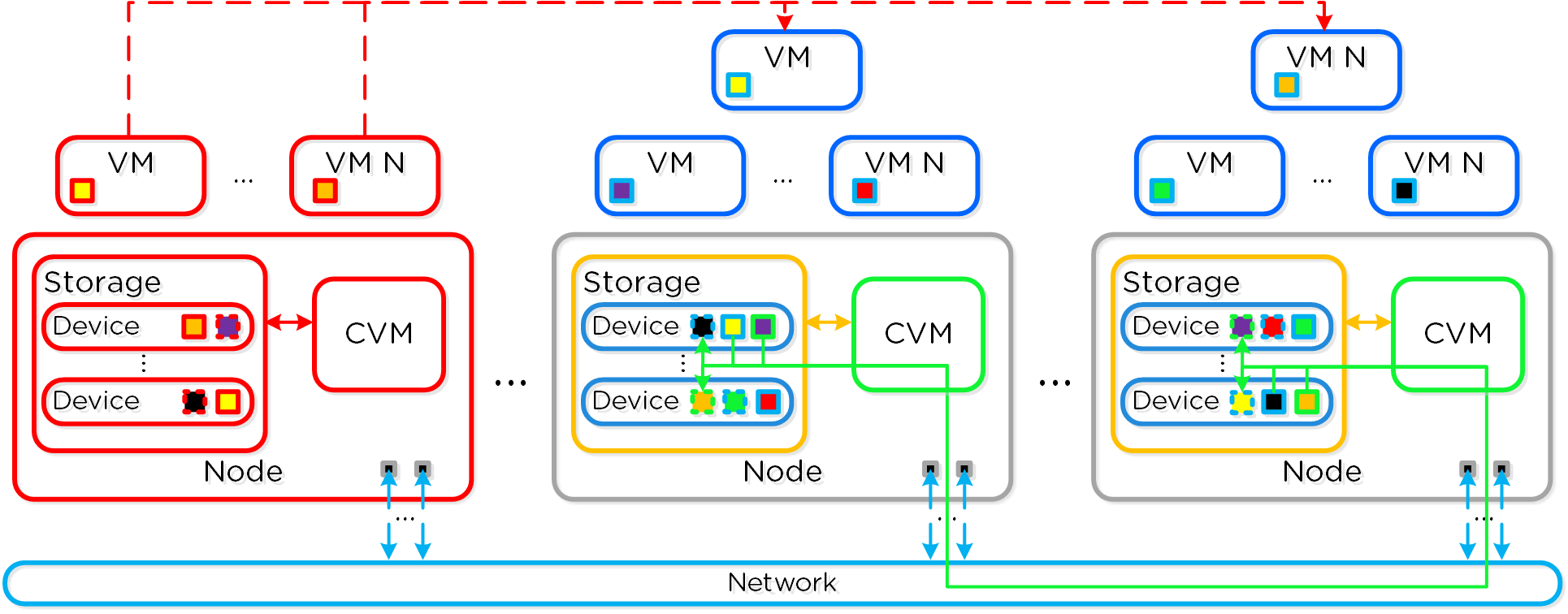 데이터 경로 리질리언시 – 노드 장애 (Data Path Resiliency - Node Failure)
데이터 경로 리질리언시 – 노드 장애 (Data Path Resiliency - Node Failure)
노드가 장시간 (AOS 4.6에서 30분) 동안 다운된 경우 다운된 CVM은 메타데이터 링에서 제거된다. 노드가 복구되고 일정 시간 동안 안정된 상태로 유지되면 다시 링에 조인된다.
Note
Pro tip
데이터 리질리언시 상태는 프리즘의 대시보드 페이지에 표시된다.
물론 CLI로 데이터 리질리언시 상태를 체크할 수 있다.
###### 노드 상태 (Node status)ncli cluster get-domain-fault-tolerance-status type=node###### 블록 상태 (Block status)
ncli cluster get-domain-fault-tolerance-status type=rackable_unit
이들은 항상 최신 상태여야 하지만 데이터의 새로 고침을 위해 큐레이터 부분 스캔을 시작할 수 있다.
CVM 장애 (CVM “Failure”)
CVM 장애는 CVM 전원 동작으로 인해 CVM을 일시적으로 사용할 수 없는 것으로 특징지을 수 있다. 시스템은 이것을 우아하게 처리하도록 투명하게 설계되었다. 장애가 발생한 경우 I/O는 클러스터 내의 다른 CVM으로 리다이렉트된다. 이것에 대한 메커니즘은 하이퍼바이저에 따라 다르다.
롤링 업그레이드 프로세스는 클러스터를 반복하면서 한 번에 하나의 CVM을 업그레이드하기 때문에 실제로 이 기능을 활용한다.
VM에 미치는 영향은 다음과 같다.
- HA 이벤트: 없음
- I/O 실패: 없음
- 레이턴시: 네트워크를 통한 I/O가 증가하기 때문에 잠재적으로 높을 수 있음
CVM 장애의 경우 다운된 CVM에서 이전에 서비스되었던 I/O는 클러스터 전체의 다른 CVM으로 전달된다. ESXi와 Hyper-V는 HA.py(like "happy")을 활용하여 클러스터 전체에서 내부 주소(192.168.5.2)로 이동하는 트래픽 전달 경로를 다른 CVM의 외부 IP로 수정하는 CVM 오토패싱 프로세스를 통해 이것을 처리한다. 이를 통해 데이터스토어를 그래로 유지할 수 있으며 I/O 서비스를 담당하는 CVM만 원격이다.
로컬 CVM이 복구되어 안정적인 상태가 되면 라우트 정보가 삭제되고 로컬 CVM이 모든 새로운 I/O를 인계받는다.
AHV의 경우 기본 경로가 로컬 CVM이고 다른 두 경로가 원격인 iSCSI 다중 경로가 활용된다. 기본 경로에 장애가 발생하면 다른 경로 중 하나가 활성화된다.
ESXi 및 Hyper-V의 오토패싱과 유사하게 로컬 CVM이 다시 온라인 상태가 되면 기본 경로로 인계된다.
탄력적인 용량 (Resilient Capacity)
사용된 용어에 대한 몇 가지 복습:
- 장애/가용성 도메인(FD: Failure/Availability Domain): 복제본이 배치되는 엔티티의 논리적 그룹이다. 노드 개수가 3보다 많은 경우 노드는 뉴타닉스 클러스터의 기본 도메인이다. 가용성 도메인 섹션을 참조한다.
- 복제 계수(RF: Replication Factor): 데이터 가용성을 위해 클러스터에서 유지 관리할 데이터 복사본의 수이다.
- 폴트 톨러런스(FT: Fault Tolerance): 클러스터에서 처리할 수 있는 설정된 FD의 엔터티 장애 개수로, 장애가 발생한 엔터티의 데이터가 완전히 재구축되도록 한다.
탄력적인 용량(Resilient Capacity)은 설정된 가용성/장애 도메인에서 FT 장애 발생 후 셀프-힐링 및 원하는 복제 계수(RF)로 복구하는 클러스터 기능을 유지하면서 가장 낮은 가용성/장애 도메인에서 사용할 수 있는 클러스터의 스토리지 용량이다. 간단히 말해서 탄력적 용량 = 총 클러스터 용량 - FT 장애로부터 재구축하는 데 필요한 용량이다.
Note
탄력적인 용량 예제 (Resilient Capacity Examples)
균일한 클러스터 용량
- 설정된 가용성 도메인: 노드
- 가장 낮은 가용성 도메인: 노드
- FT=1
- RF=2
- 노드 용량: 10TB,10TB,10TB,10TB
- 탄력적인 용량(Resilient Capacity) = (40-10)*0.95 = 28.5TB. 95%는 스타게이트가 더 이상 사용자 쓰기를 수행하지 않는 읽기 전용 모드가 되는 임계값이다.
균일하지 않은 클러스터 용량
- 설정된 가용성 도메인: 블록(1노드/블록)
- 가장 낮은 가용성 도메인: 노드
- FT=1
- RF=2
- 노드 용량: 10TB,10TB,40TB,40TB
- 탄력적인 용량(Resilient Capacity) = 40*0.95 = 38TB. 95%는 스타게이트가 더 이상 사용자 쓰기를 수행하지 않는 읽기 전용 모드가 되는 임계값이다
이 경우에 탄력적 용량은 60TB가 아니라 40TB인데, 40TB 블록의 장애가 발생한 후 클러스터에 노드 가용성 도메인이 있기 때문이다. 2개의 데이터 복제본을 유지하기 위한 이 수준에서 사용 가능한 용량은 40TB이므로 이 경우애 전체 용량은 40TB가 된다.
용량 및 장애 도메인 관점에서 클러스터를 균일하고 균질하게 유지하는 것이 좋다.
AOS 5.18부터 탄력적 용량은 회색 선으로 프리즘 엘리먼트 스토리지 요약 위젯에 표시된다. 클러스터 사용량이 탄력적인 용량에 도달할 때 최종 사용자에게 경고하도록 임계값을 설정할 수 있다. 디폴트로 75%로 설정되어 있다.
프리즘은 또한 관리자가 노드 별로 리질리언시를 이해하는 데 도움이 되는 노드 별로 자세한 스토리지 활용도를 표시할 수 있다. 이것은 균일하지 않는 스토리지 분포가 있는 클러스터에서 유용하다.
클러스터 사용량이 해당 클러스터의 탄력적 용량보다 크면 클러스터가 더 이상 장애를 허용하지 않고 복구하지 못할 수 있다. 탄력적인 용량은 설정된 장애 도메인을 위한 것이므로 클러스터는 더 낮은 장애 도메인에서 장애를 여전히 복구하고 허용할 수 있다. 예를 들어, 노드 장애 도메인으로 설정된 클러스터는 디스크 장애에 대해 여전히 셀프-힐링 및 복구가 가능하지만, 노드 장애에 대해서는 셀프-힐링 및 복구를 할 수 없다.
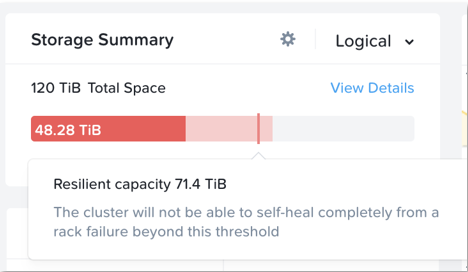
클러스터의 적절한 기능을 보장하고 셀프-힐링 및 장애 복구 능력을 유지하기 위해 어떤 상황에서도 클러스터의 탄력적 용량을 초과하지 않는 것이 좋다.
용량 최적화
뉴타닉스 플랫폼은 모든 워크로드를 위해 가용 용량을 효율적으로 사용할 수 있도록 함께 동작하는 다양한 스토리지 최적화 기술을 통합한다. 이러한 기술은 지능적이고 워크로드 특성에 적응하므로 수동 설정 및 세부 튜닝이 필요하지 않다.
다음과 같은 최적화가 활용된다.
- Erasure Coding (EC-X)
- 압축 (Compression)
- 중복제거 (Deduplication)
이러한 기능 각각에 대한 자세한 내용은 다음 섹션에서 확인할 수 있다.
이 표는 워크로드에 적용할 수 있는 최적화 방법에 대해 설명한다.
| 데이터 변환 (Data Transform) | 가장 적합한 애플리케이션 (Best suited Application(s)) | 비고 (Comments) |
|---|---|---|
| Erasure Coding | 대부분, 뉴타닉스 파일/오브젝트에 적합 | 기존 RF 보다 오버헤드를 줄이면서 더 높은 가용성을 제공한다. 정상적인 쓰기 또는 읽기 I/O 성능에 영향을 미치지 않는다. 데이터를 디코드 해야 하는 디스크/노드/블록 장애의 경우 약간의 읽기 오버헤드가 있다. |
| 인라인 압축 (Inline Compression) | 모두 (All) | 랜덤 I/O에 영향을 미치지 않으며 스토리지 티어 활용률을 높이는 데 도움을 준다. 디스크에서 복제 및 읽을 데이터를 줄임으로써 대규모 또는 순차 I/O 성능을 향상시킨다. |
| 오프라인 압축 (Offline Compression) | 없음 (None) | 인라인 압축은 큰 또는 순차 쓰기만 인라인으로 압축하므로 랜덤 또는 작은 I/O는 후처리를 수행하므로 대신 사용해야 한다. |
| 성능 티어 중복제거 (Performance Tier Deduplication) | P2V/V2V, Hyper-V(ODX), 크로스 컨테이너 복제 | 효율적인 AOS 클론을 사용하여 생성되거나 클론 되지 않은 데이터의 캐시 효율성을 향상되었다. |
| 용량 티어 중복제거 (Capacity Tier Deduplication) | 성능 티어 중복제거와 동일 | 위의 장점 외에 디스크 오버헤스가 감소됨 |
Erasure Coding
뉴타닉스 플랫폼은 데이터 보호 및 가용성을 위해 복제계수(RF)를 활용한다. 이 방법은 둘 이상의 스토리지 우치에서 읽거나 장애 시 데이터 재계산이 필요하지 않기 때문에 최고 수준의 가용성을 제공한다. 그러나 전체 복사본이 필요하기 때문에 스토리지 자원의 비용이 발생한다.
가용성 간의 균형을 유지하면서 필요한 스토리지 용량을 줄이기 위해 DSF는 EC(Erasure Codes)를 사용하여 데이터를 인코딩할 수 있는 기능을 제공한다.
패리티가 계산되는 RAID (레벨 4, 5, 6 등) 개념과 유사하게 EC는 여러 노드에서 데이터 블록 스트립을 인코딩하고 패리티를 계산한다. 호스트 및/또는 디스크 장애가 발생하면 패리티를 사용하여 손상된 데이터 블록(디코딩)을 계산할 수 있다. DSF의 경우 데이터 블록은 익스텐트 그룹이다. 데이터의 읽기 특성(읽기 콜드 대 읽기 핫)에 따라 시스템은 스트립에서 블록의 배치를 결정한다.
읽기 콜드 데이터의 경우 동일 vDisk의 데이터 블록을 노드에 분산하여 스트립(동일 vDisk 스트립)을 형성하는 것이 좋다. 이렇게 하면 vDisk가 삭제된 경우 전체 스트립을 제거할 수 있으므로 가비지 콜렉션이 간단해진다. 핫 데이터 읽기의 경우 vDisk 데이터 블록을 노드에 로컬로 유지하고 다른 vDisk(크로스 vDisk 스트립)의 데이터로 스트립을 구성하는 것이 좋다. 로컬 vDisk의 데이터 블록이 로컬일 수 있고 다른 VM/vDisk가 스트립의 다른 데이터 블록을 작성할 수 있으므로 원격 읽기가 최소화된다. 읽기 콜드 스트립이 핫으로 변경되면 시스템은 스트립을 재계산하고 데이터 블록을 로컬화한다.
스트립의 데이터 및 패리티 블록의 수는 허용 가능한 장애 수준에 기반하여 설정할 수 있다. 설정은 일반적으로 <데이터 블록의 수> / <패리티 블록의 수>이다.
예를 들어 “RF2 like)” 가용성(e.g. N+1)은 스트립에 3개 또는 4개의 데이터 블록과 1개의 패리티 블록(e.g. 3/1 or 4/1)으로 구성될 수 있다. “RF3 like” 가용성(e.g. N+2)은 스트립에 3개 또는 4개의 데이터 블록과 2개의 패리티 블록(e.g. 3/2 or 4/2)으로 구성될 수 있다.
Note
EC + 블록 인식 (EC + Block Awareness)
AOS 5.8부터 EC는 블록 인식 방식으로 데이터와 패리티 블록을 배치할 수 있다 (AOS 5.8 이전에는 노드 레벨에서 수행).
기존 EC 컨테이너는 AOS 5.8로 업그레이드한 후 블록 인식 배치로 즉시 변경되지 않는다. 클러스터에서 가용한 블록(스트립 크기 (k + n) + 1)이 충분하면 이전의 노드 인식 스트립이 블록 인식으로 이동한다. 새로운 EC 컨테이너는 블록 인식 EC 스트립을 구축한다.
예상 오버헤드는 <패리티 블록의 수> / <데이터 블록의 수>로 계산할 수 있다. 예들 들어 1/4 스트립은 RF2의 2배와 비교하여 1.25배 또는 25%의 오버헤드를 가진다. 4/2 스트립은 RF3의 3배와 비교하여 1.5배 또는 50%의 오버헤드를 가진다.
다음 표는 인코딩된 스트립 크기와 예제 오버헤드를 나타낸다.
| FT1 (RF2와 동일) | FT2 (RF3와 동일) | |||
|---|---|---|---|---|
| 클러스터 사이즈 (노드) |
EC 스트립 크기 (데이터/패리티) |
EC 오버헤드 (RF2의 2배와 비교) |
EC 스트립 크기 (데이터/패리티) |
EC 오버헤드 (RF3의 3배와 비교) |
| 4 | 2/1 | 1.5X | N/A | N/A |
| 5 | 3/1 | 1.33X | N/A | N/A |
| 6 | 4/1 | 1.25X | 2/2 | 2X |
| 7 | 4/1 | 1.25X | 3/2 | 1.6X |
| 8+ | 4/1 | 1.25X | 4/2 | 1.5X |
Note
Pro tip
노드 또는 블록 장애의 경우 스트립의 재구축을 위해 결합된 스트립 크기(데이터 + 패리티) 보다 최소 하나 이상의 노드(또는 블록 인식 데이터/패리티 배치를 위한 블록)가 있는 클러스터 크기를 항상 권장한다. 이것은 스트립이 재구축되면(큐레이터를 통해 자동화된) 읽기에 대한 계산 오버헤드를 제거한다. 예들 들어 4/1 스트립은 노드 인식 EC 스트립의 경우 클러스터에 최소 6개의 노드가 있거나 블록 인식 EC 스트립의 경우 6개의 블록이 있어야 한다. 위의 표는 이 모범 사례를 따른다.
인코딩은 후처리 작업으로 수행되며 태스크의 분산을 위해 큐레이터 맵리듀스 프레임워크를 활용한다. 이것은 후처리 프레임워크이므로 기존 쓰기 I/O 경로에 영향을 미치지 않는다.
RF를 사용하는 일반적인 환경은 다음과 같다.
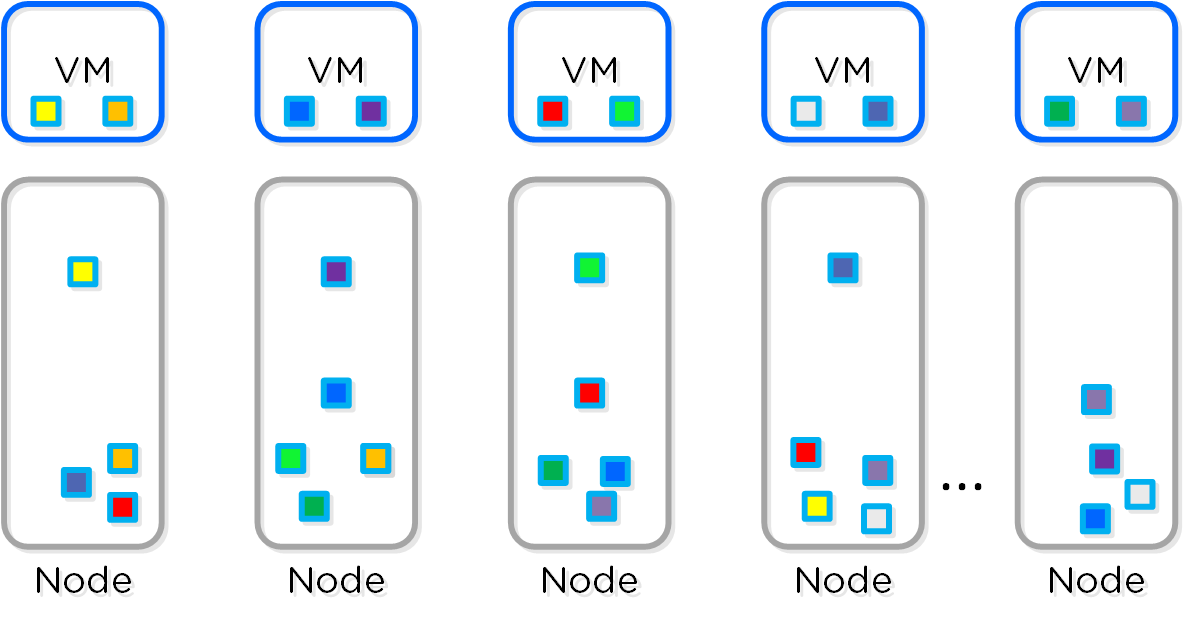 일반적인 DSF RF 데이터 레이아웃 (Typical DSF RF Data Layout)
일반적인 DSF RF 데이터 레이아웃 (Typical DSF RF Data Layout)
이 시나리오에서는 기본 복사본이 로컬이고 복제본이 클러스터 전체의 다른 노드에 분산된 RF2와 RF3 데이터가 혼합되어 있다.
큐레이터 전체 스캔이 실행되면 인코딩할 수 있는 적격 익스텐트 그룹을 찾는다. 적격 익스텐트 그룹은 일정 시간 동안 쓰기 작업이 없었다는 것을 의미하는 “Write-Cold”이여야 한다. 이것은 다음 큐레이터 Gflag : curator_erasure_code_threshold_seconds에 의해 제어된다. 적격 후보를 찾은 후에 인코딩 태스크는 크로노스(Chronos)를 통해 분산되고 조정된다.
다음 그림은 예제 4/1 및 3/2 스트립을 보여준다.
 DSF 인코딩 스트립 – 용량 증가 전 (DSF Encoded Strip - Pre-savings)
DSF 인코딩 스트립 – 용량 증가 전 (DSF Encoded Strip - Pre-savings)
데이터가 성공적으로 인코딩되면(스트립 및 패리티 계산) 복제본 익스텐트 그룹은 삭제된다.
다음 그림은 스토리지 절감을 위해 EC가 실행된 후의 환경을 보여준다.
 DSF 인코딩 스트립 – 용량 증가 후 (DSF Encoded Strip - Post-savings)
DSF 인코딩 스트립 – 용량 증가 후 (DSF Encoded Strip - Post-savings)
Note
Pro tip
Erasure Coding은 인라인 압축과 완벽하게 쌍을 이루어 스토리지 절감 효고를 높인다.
압축 (Compression)
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
뉴타닉스 용량 최적화 엔진(COE)은 디스크의 데이터 효율성을 높이기 위해 데이터 변환을 수행한다. 현재 압축은 데이터 최적화를 수행하기 위한 COE의 주요 기능 중 하나이다. DSF는 고객의 요구와 데이터 유형에 가장 적합한 인라인 및 오프라인 압축을 모두 제공한다. AOS 5.1부터 오프라인 압축이 기본적으로 활성화되어 있다.
인라인 압축은 익스텐트 스토어(SSD+HDD)에 쓸 때 순차 스트림 데이터 또는 큰 I/O 크기(> 64K)를 압축한다. 여기에는 OpLog에서 배수되는 데이터와 이를 건너뛰는 순차 데이터가 포함된다.
Note
OpLog 압축 (OpLog Compression)
AOS 5.0부터 OpLog는 이제 4K를 초과하여 들어오는 모든 쓰기를 압축하여 압축률이 우수하다 (Gflag: vdisk_distributed_oplog_enable_compression). 이를 통해 OpLog 용량을 보다 효율적으로 활용하고 지속적인 성능을 유도할 수 있다.
OpLog에서 익스텐트 스토어로 배수될 때 데이터는 압축 해제되고 정렬된 다음 32K 정렬 단위 크기(AOS 5.1 기준)로 다시 압축된다.
이 기능은 기본적으로 켜져 있으며 사용자 설정이 필요하지 않다.
오프라인 압축은 처음에 데이터를 평문(압축하지 않은 상태)으로 쓴 다음 큐레이터 프레임워크를 활용하여 클러스터 전체에서 데이터를 압축한다. 인라인 압축을 활성화되어 있지만 I/O가 랜덤인 경우 데이터는 압축되지 않은 상태로 OpLog에 쓰이고 병합된 후에 익스텐트 스토어에 쓰기 전에 메모리에서 압축된다.
뉴타닉스는 AOS 5.0 이상에서 데이터 압축을 위해 LZ4 및 LZ4HC를 활용한다. AOS 5.0 이전에는 최소한의 계산 오버헤드와 매우 빠른 압축/압축 해제 속도로 우수한 압축률을 제공하는 구글 Snappy 압축 라이브러리가 활용되었다.
일반 데이터는 압축과 성능 간에 매우 좋은 조합을 제공하는 LZ4를 사용하여 압축된다. 콜드 데이터의 경우 향상된 압축률을 제공하기 위해 LZ4HC가 활용된다.
콜드 데이터는 두 가지 주요 카테고리로 특징지을 수 있다.
- 일반 데이터: 3일 동안 RW 액세스 없음 (Gflag: curator_medium_compress_mutable_data_delay_secs)
- 변경할 수 없는 데이터(스냅샷): 1일 동안 RW 액세스 없음 (Gflag: curator_medium_compress_immutable_data_delay_secs)
다음 그림은 인라인 압축이 DSF 쓰기 I/O 경로와 상호 작용하는 방법의 예를 보여준다.
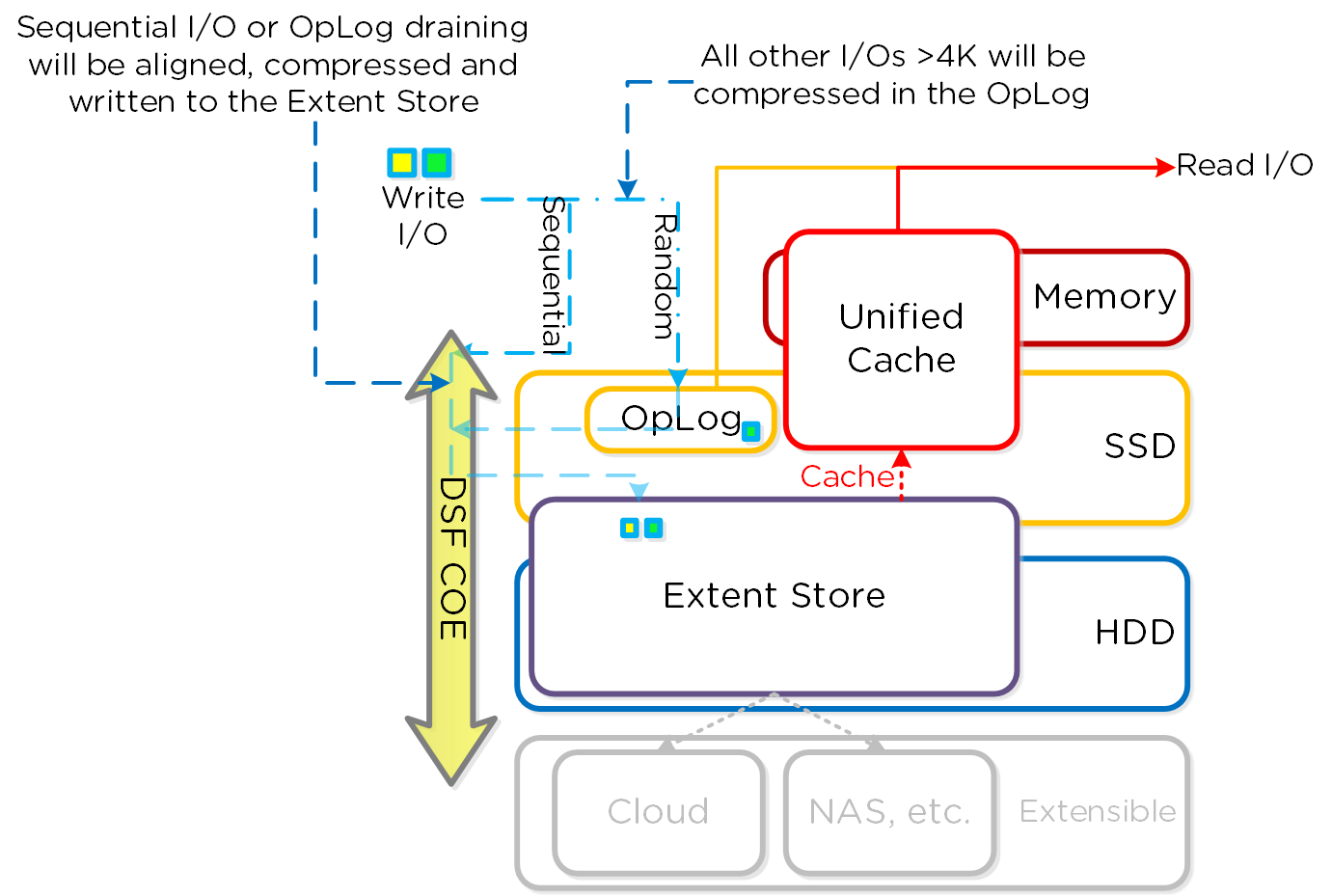 인라인 압축 I/O 경로 (Inline Compression I/O Path)
인라인 압축 I/O 경로 (Inline Compression I/O Path)
Note
Pro tip
인라인 압축(compression delay=0)은 큰/순차 쓰기만 압축하고 랜덤 쓰기 성능에 영향을 미치지 않기 때문에 대부분의 경우에 인라인 압축을 사용한다.
또한 SSD 티어의 가용 용량을 증가시키기 때문에 효과적인 성능이 향상되고 더 많은 데이터를 SSD 티어에 저장할 수 있다. 또한 인라인으로 쓰이고 압축되는 큰 또는 순차 데이터의 경우 RF를 위한 복제는 압축된 데이터를 전달하는데, 이것은 네트워크를 통해 전송되는 데이터의 양이 적기 때문에 성능이 더욱 향상된다.
인라인 압축은 Erasure Coding과 완벽하게 쌍을 이룬다.
오프라인 압축인 경우 모든 새로운 쓰기 I/O는 압축되지 않은 상태로 쓰이며 일반적인 DSF I/O 경로를 따른다. 압축 지연(설정 가능한 정보)이 충족되면 데이터를 압축할 수 있다. 압축은 익스텐트 스토어의 어느 곳에서나 발생할 수 있다. 오프라인 압축은 큐레이터 맵리듀스 프레임워크를 사용하고 모든 노드가 압축 작업을 수행한다. 압축 작업은 크로노스에 의해 조정된다.
다음 그림은 오프라인 압축이 DSF 쓰기 I/O 경로와 상호 작용하는 방법의 예를 보여준다.
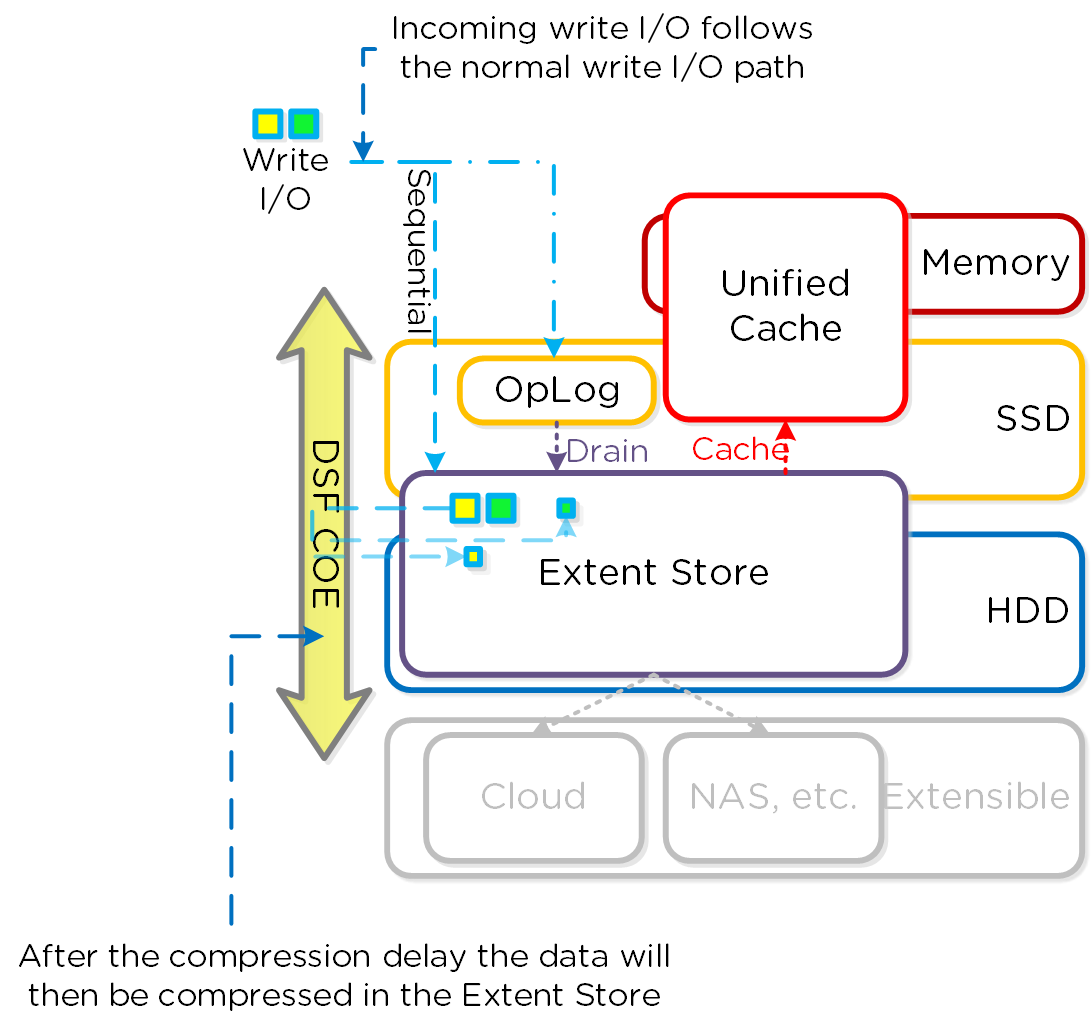 오프라인 압축 I/O 경로 (Offline Compression I/O Path)
오프라인 압축 I/O 경로 (Offline Compression I/O Path)
읽기 I/O의 경우 데이터는 먼저 메모리에서 압축 해제된 다음 I/O가 서비스된다.
프리즘의 “Storage > Dashboard” 페이지에서 현재 압축률을 확인할 수 있다.
탄력적인 중복제거 엔진 (Elastic Dedupe Engine)
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
탄력적인 중복제거 엔진은 DSF의 소프트웨어 기반 기능으로 용량(익스텐트 스토어) 및 성능(유니파이드 캐시) 티어에서 중복제거를 수행한다. 데이터 스트림은 8K 단위로 SHA-1 해시를 사용하여 수집 중에 지문 생성한다 (stargate_dedup_fingerprint에 의해 제어됨). 이 지문은 데이터 수집 시에만 수행되며 저장된 블록의 메타데이터의 일부로 영구히 저장된다. 중복제거된 데이터는 4K 단위로 유니파이드 캐시로 가져온다.
데이터 다시 읽어야 하는 백그라운드 스캔을 사용하는 기존 접근 방식과 달리 뉴타닉스는 수집 시에 지문을 인라인으로 수행한다. 용량 티어에서 중복제거될 수 있는 중복 데이터인 경우 데이터를 스캔하거나 다시 읽을 필요가 없으며 기본적으로 중복된 복사본을 삭제할 수 있다.
메타데이터 오버헤드를 좀 더 효율적으로 만들기 위해 지문 참조 횟수를 모니터링하여 중복제거 가능성을 추적한다. 참조 횟수가 낮은 지문은 메타데이터 오버헤드를 최소화하기 위해 폐기된다. 단편화를 최소화하기 위해 용량 티어 중복제거는 전체 익스텐트를 대상으로 수행된다.
Note
Pro tip
유니파이드 캐시의 장점을 활용하기 위해 베이스 이미지(vdisk_manipulator를 사용하여 수동으로 지문을 생성할 수 있음)에 성능 티어 데이터 중복제거 기능을 사용한다.
Hyper-V를 사용하는 경우 ODX가 전체 데이터 복사를 수행하거나 크로스-컨테이너 클론(단일 컨테이너를 선호하므로 일반적으로 권장되지 않음)을 수행할 때 P2V/V2V에 용량 티어 중복제거를 사용한다.
대부분의 다른 경우 압축은 최대 용량 절감을 제공하므로 대신 사용해야 한다.
다음 그림은 탄력적인 중복제거 엔진의 확장성 및 로컬 VM I/O 요청 처리 방법의 예를 보여준다.
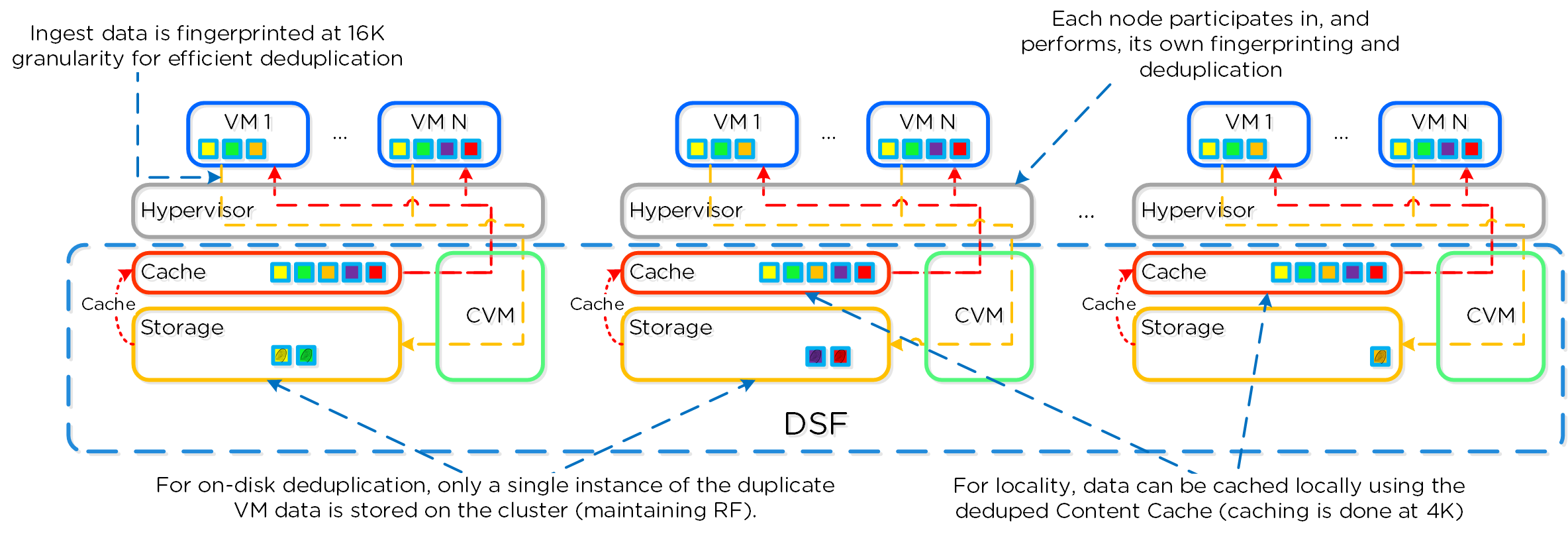 탄력적인 중복제거 엔진 – 확장 (Elastic Dedupe Engine - Scale
탄력적인 중복제거 엔진 – 확장 (Elastic Dedupe Engine - Scale
지문 생성은 I/O 크기가 64K 이상인 데이터(초기 I/O 또는 OpLog로부터 배수될 때)의 데이터 수집 시에 수행된다. SHA-1 계산을 위해 최소한의 CPU 오버헤드를 제공하는 인텔 가속 기능을 활용한다. 수집 시에 지문 생성이 수행되지 않은 경우(e.g. 작은 I/O 크기) 지문 생성은 백그라운드 프로세스에 의해 수행될 수 있다. 데이터 중복제거 엔진은 용량 티어(익스텐트 스토어)와 성능 티어(유니파이드 캐시) 모두에 걸쳐 있다. 동일한 지문의 여러 사본을 기반으로 하여 중복 데이터가 결정되면 백그라운드 프로세스는 DSF 맵리듀스 프레임워크(큐레이터)를 사용하여 중복 데이터를 삭제한다. 읽고 있는 데이터의 경우 데이터는 멀티-티어/풀 캐시인 DSF 유니파이드 캐시로 가져온다. 동일 지문을 갖는 데이터에 대한 후속 요청은 캐시에서 직접 가져온다. 유니파이드 캐시 및 풀 구조에 대한 자세한 내용은 I/O 경로 개요의 “유니파이드 캐시” 하위 섹션을 참조한다.
Note
지문 vDisk 오프셋 (Fingerprinted vDisk Offsets)
AOS 4.6.1부터 제한이 없으며 전체 vDisk를 지문처리/중복제거할 수 있다.
AOS 4.6.1 이전에 높은 메타데이터 효율성으로 인해 24GB로 증가했다. AOS 4.5 이전에는 vDisk의 처음 12GB만 지문을 사용할 수 있었다. 이는 OS가 일반적으로 가장 보편적인 데이터이기 때문에 보다 작은 메타데이터 공간을 유지하기 위해 수행되었다.
다음 그림은 탄력적인 중복제거 엔진이 DSF I/O 경로와 상호 작용하는 방법의 예를 보여준다.
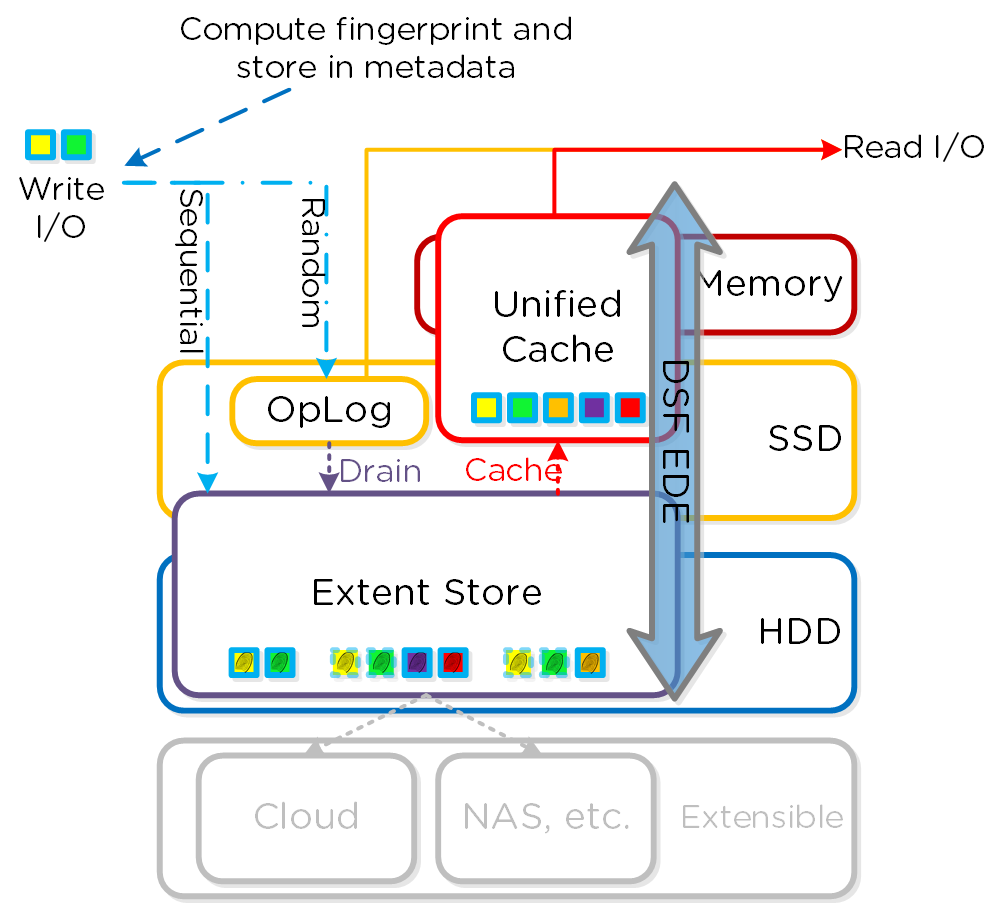 EDE I/O 경로 (EDE I/O Path)
EDE I/O 경로 (EDE I/O Path)
프리즘의 “Storage > Dashboard” 페이지에서 현재 중복제거 비율을 볼 수 있다.
Note
중복제거 + 압축 (Dedup + Compression)
AOS 4.5부터 동일 컨테이너에서 중복제거와 압축을 동시에 사용할 수 있다. 그러나 데이터를 중복제거할 수 없으면(섹션의 앞부분에서 설명한 조건) 압축을 사용한다.
스토리지 티어링 및 우선순위
아래 디스크 밸런싱 섹션에서 뉴타닉스 클러스터의 모든 노드에서 스토리지 용량이 풀링되는 방식과 ILM을 사용하여 핫 데이터를 로컬로 유지하는 방법에 대해 설명했다. 비슷한 개념이 디스크 티어링에 적용되는데, 클러스터의 SSD 및 HDD 티어가 클러스터 전체이고 DSF ILM이 데이터 이동 이벤트를 트리거한다. 로컬 노드의 SSD 티어는 해당 노드에서 실행 중인 VM에 의해 요청된 모든 I/O에 대한 최우선 순위 티어이지만 모든 클러스터 SSD 자원은 클러스터 내의 모든 노드에서 사용할 수 있다. SSD 티어는 항상 최고의 성능을 제공하며 하이브리드 어레이를 관리하는 데 매우 중요하다.
티어 우선순위는 다음 그림과 같은 하이-레벨로 분류할 수 있다.
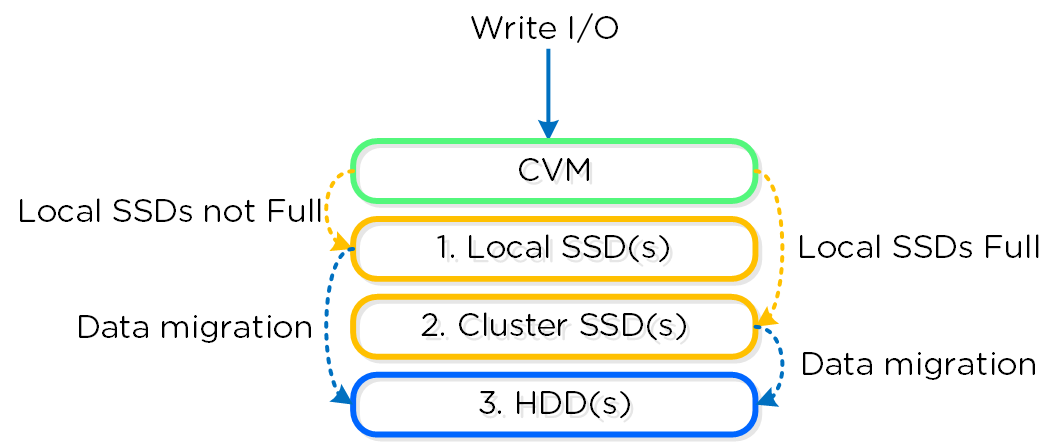 DSF 티어 우선순위 (DSF Tier Prioritization)
DSF 티어 우선순위 (DSF Tier Prioritization)
특정 유형의 자원(e.g. SSD, HDD 등)이 함께 풀링되어 클러스터 전체 스토리지 티어를 형성한다. 이는 클러스터의 모든 노드는 로컬 여부에 관계없이 전체 티어 용량을 활용할 수 있다는 것을 의미한다.
다음 그림은 풀링된 티어가 어떻게 보이는지에 대한 하이 레벨의 예를 보여준다.
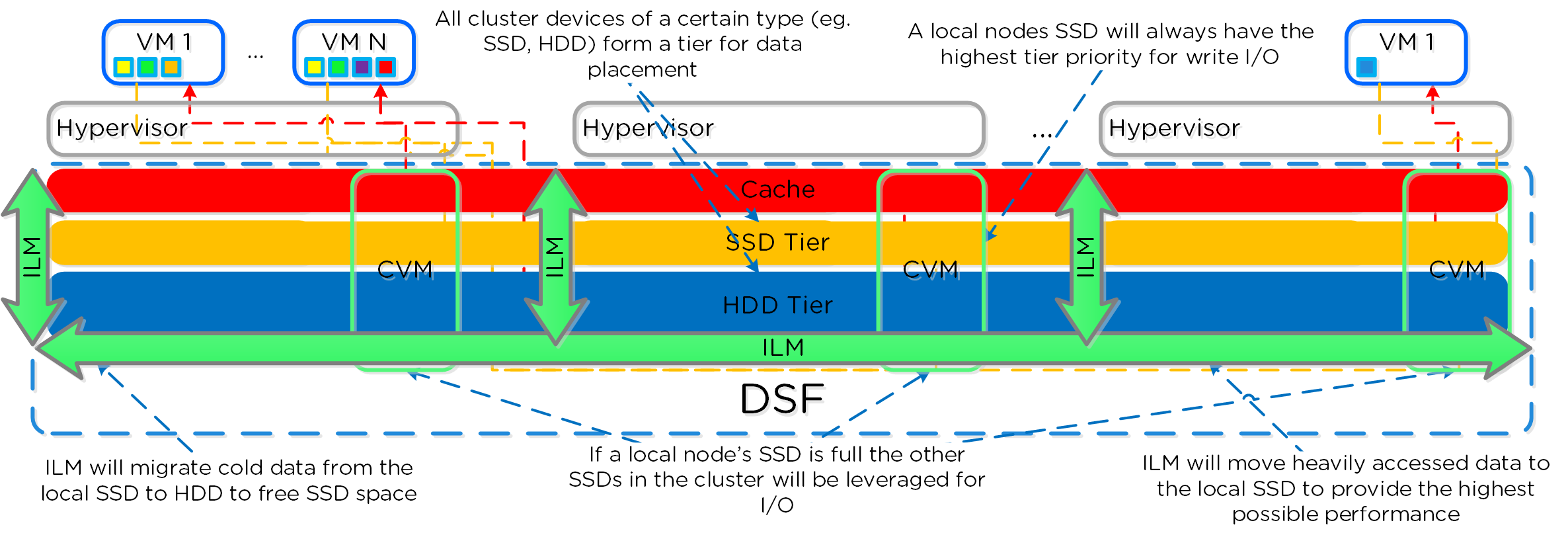 DSF 클러스터 전체의 티어링 (DSF Cluster-wide Tiering)
DSF 클러스터 전체의 티어링 (DSF Cluster-wide Tiering)
일반적인 질문은 "로컬 노드의 SSD가 가득 차면 어떻게 되는가?" 이다. 디스크 밸런싱 섹션에서 언급했듯이 핵심 개념은 디스크 티어에서 디바이스의 사용률을 균일하게 유지하는 것이다. 로컬 SSD의 사용률이 높은 경우 로컬 SSD에서 콜드 데이터를 클러스터 전체의 다른 SSD로 이동하기 위해 디스크 밸런싱이 시작된다. 이렇게 하면 로컬 SSD 공간이 확보되어 로컬 노드가 네트워크를 통하지 않고 로컬로 SSD에 쓸 수 있다. 언급해야 할 중요한 점은 모든 CVM 및 SSD가 이 원격 I/O에 사용되어 잠재적 병목현상을 제거하고 네트워크를 통해 I/O를 수행하는 오버헤드를 해결한다.
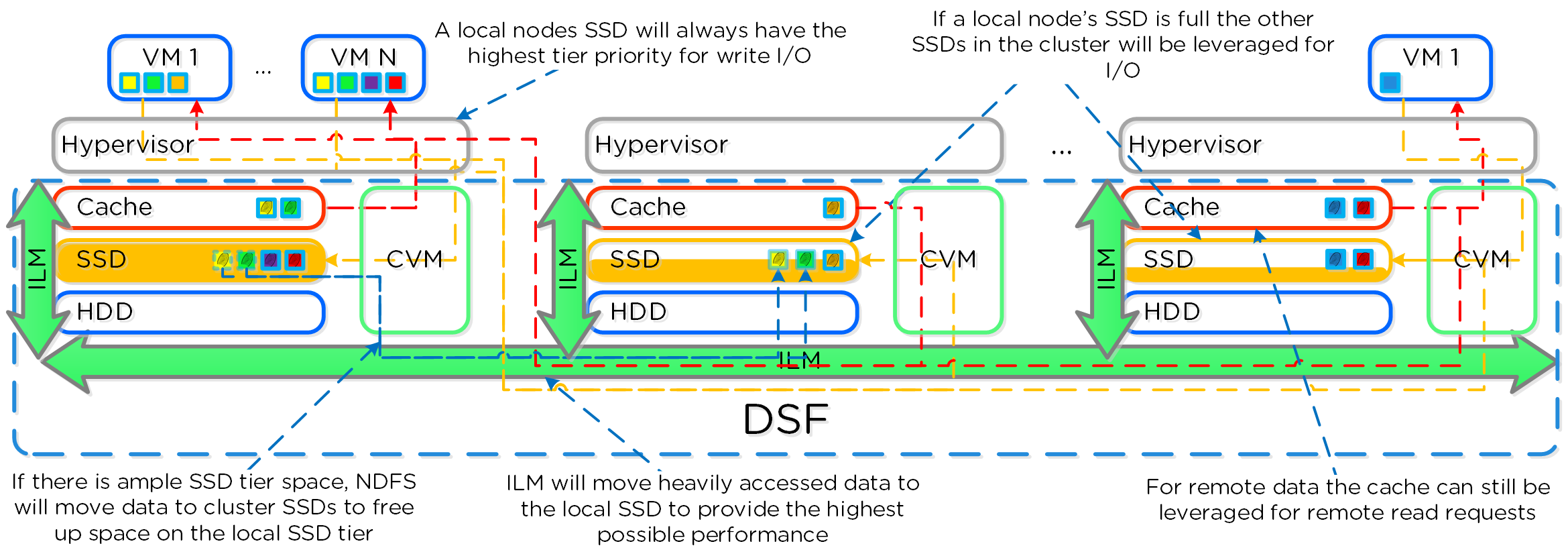 DSF 클러스터 전체의 티어 밸런싱 (DSF Cluster-wide Tier Balancingg
DSF 클러스터 전체의 티어 밸런싱 (DSF Cluster-wide Tier Balancingg
다른 경우는 전체 티어 사용률이 지정된 임계 값([curator_tier_usage_ilm_threshold_percent (Default=75)])을 위반하여 DSF ILM이 시작되고 큐레이터 잡의 일부로서 데이터를 SSD 티어에서 HDD 티어로 다운 마이그레이션하는 경우이다. 이렇게 하면 위에서 언급한 임계 값 이하로 사용률이 떨어지거나 다음 양([curator_tier_free_up_percent_by_ilm (Default=15)]) 중 더 큰 값으로 공간을 확보할 수 있다. 다운 마이그레이션 데이터는 마지막 액세스 시간을 사용하여 선택된다. SSD 티어 사용률이 95%인 경우 SSD 티어의 데이터 중 20%가 HDD 티어로 이동된다 (95% ->75%).
그러나 사용률이 85%인 경우 [curator_tier_free_up_percent_by_ilm (Default=15)]에 따라 데이터의 15%만 HDD 티어로 이동된다.
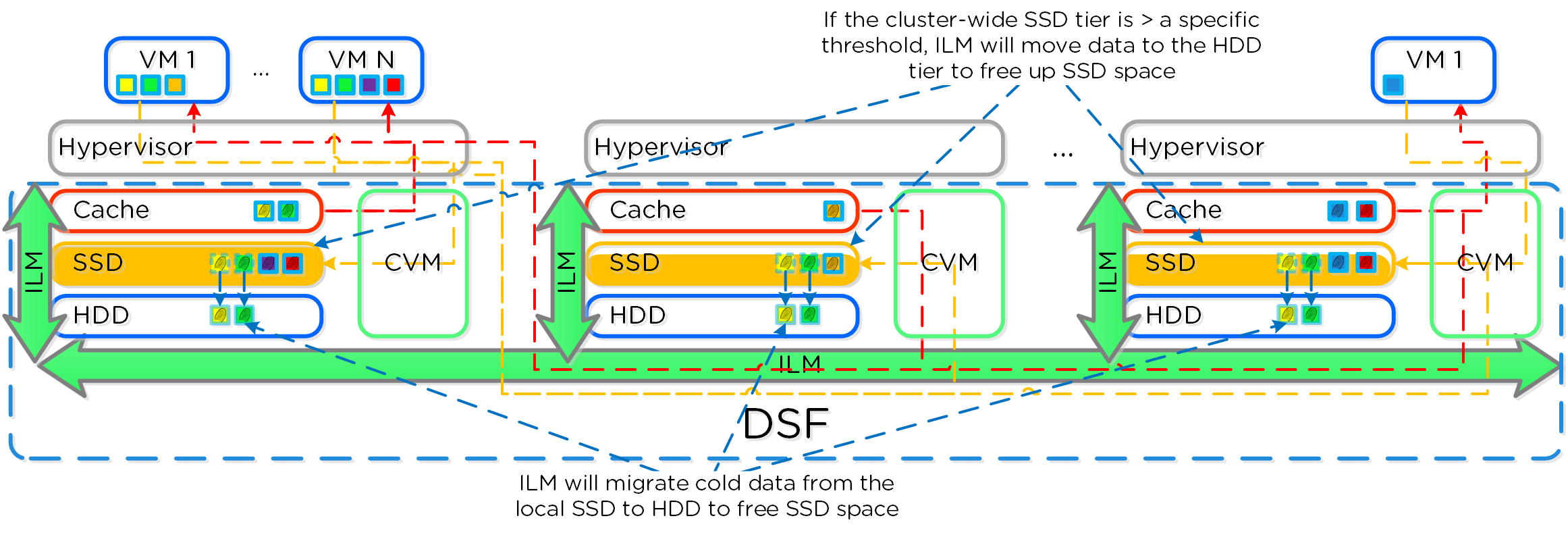 DSF 티어 ILM (DSF Tier ILM)
DSF 티어 ILM (DSF Tier ILM)
DSF ILM은 I/O 패턴을 지속적으로 모니터링하고 필요에 따라 데이터를 마이그레이션(다운/업)하고 티어에 관계없이 핫 데이터를 로컬로 가져온다. 상향 마이그레이션(또는 수평) 로직은 egroup 로컬리티에 대해 정의된 것과 동일한 로직을 사용한다: "10초마다 여러 번의 읽기가 단일 터치로 계산되는 10분 윈도우 내에서 랜덤은 3번 터치하거나 순차는 10번 터치".
디스크 밸런싱
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
DSF는 컴퓨팅 중심(3050), 스토리지 중심(60X0) 등 이기종 노드 유형을 단일 클러스터에서 혼합할 수 있을 뿐만 아니라 다양한 워크로드에 대응할 수 있는 매우 동적인 플랫폼으로 설계되었다. 노드를 더 큰 스토리지 용량과 혼합할 때 데이터의 균일한 분산을 보장하는 것은 매우 중요한 항목이다. DSF에는 디스크 밸런싱이라는 기본 기능이 있으며, 이는 클러스터 전체에 데이터의 균일한 분산을 보장하는 데 사용된다. 디스크 밸런싱은 노드의 로컬 스토리지 용량의 사용률을 기준으로 동작하며 DSF ILM과 통합된다. 사용률이 특정 임계 값을 위반했을 때 노드들 간에 사용률을 균일하게 유지하는 것이 목표이다.
NOTE: 디스크 밸런싱 잡(Jobs)은 기본 I/O (UVM I/O) 및 백그라운드 I/O (e.g. 디스크 밸런싱)에 대해 서로 다른 우선순위 큐(Queue)를 갖는 있는 큐레이터에 의해 처리된다. 이는 디스크 밸런싱 또는 기타 백그라운드 액티비티가 프런트-엔드 레이턴시/성능에 영향을 미치지 않도록 하기 위해 수행된다. 이 경우에 잡(Job)의 태스크는 태스크 실행을 조절/제어하는 크로노스에 제공된다. 또한, 디스크 밸런싱을 위해 동일한 계층 내에서 이동이 수행된다. 예를 들어, 데이터가 HDD 계층에서 왜곡된 경우 동일한 계층의 노드 간에 이동할 수 있다.
다음 그림은 "불균형"상태에 있는 혼합 클러스터 (3050 + 6050)의 예를 보여준다.
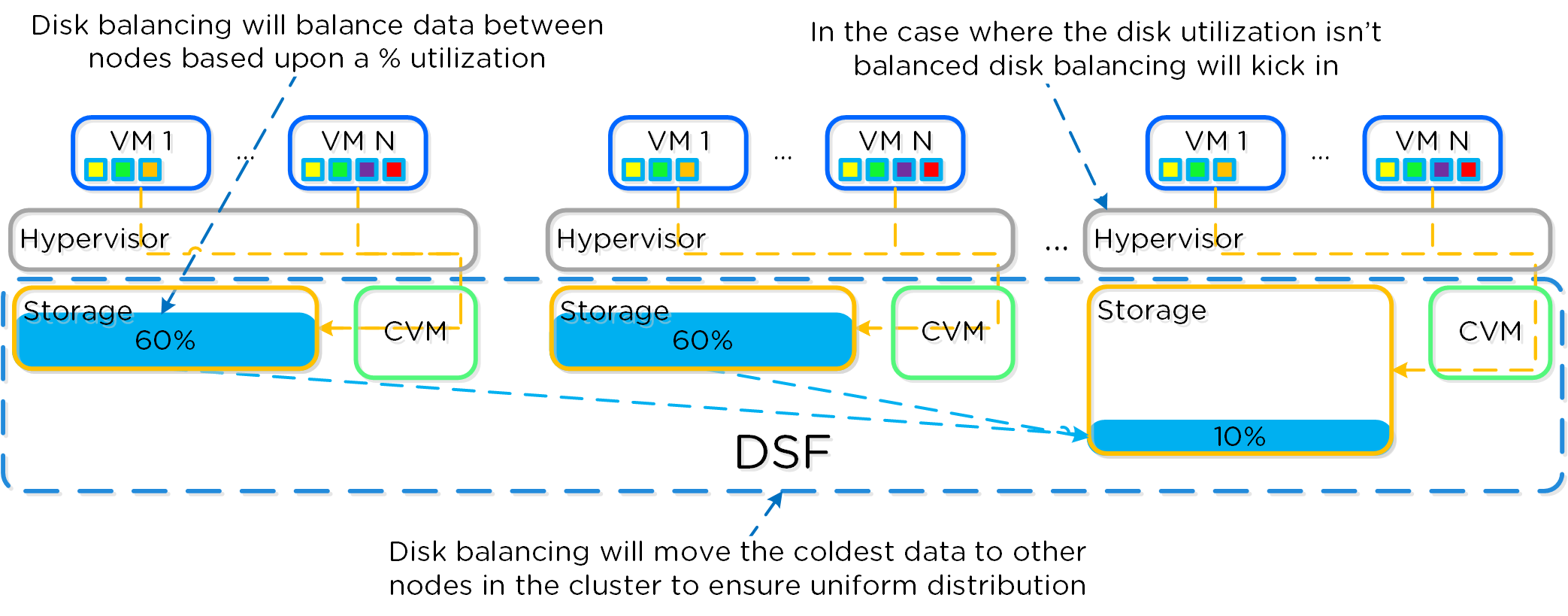 디스크 밸런싱 - 균일하지 않은 상태 (Disk Balancing - Unbalanced State)
디스크 밸런싱 - 균일하지 않은 상태 (Disk Balancing - Unbalanced State)
디스크 밸런싱은 DSF 큐레이터 프레임워크를 활용하고 스케줄링된 프로세스로 수행될 뿐만 아니라 임계 값을 위반했을 때 (e.g. 로컬 노드 용량 사용률 > n%) 실행된다. 데이터의 균형이 맞지 않는 경우 큐레이터는 이동해야 할 데이터를 결정하고 태스크를 클러스터의 노드에 분산한다. 노드 유형이 동일한 경우(e.g. 3050) 사용률은 상당히 균일해야 한다. 그러나 다른 VM 보다 훨씬 많은 데이터를 쓰는 특정 VM이 노드에서 실행 중인 경우 노드 당 용량 사용률이 왜곡될 수 있다. 이 경우 디스크 밸런싱이 실행되어 해당 노드에서 콜드 데이터를 클러스터의 다른 노드로 이동한다. 노드 유형이 이기종(e.g. 3050 + 6020/50/70)이거나 노드가 "스토리지 전용" 모드(VM을 실행하지 않음)로 사용되는 경우 데이터 이동에 대한 요구가 있을 수 있다.
다음 그림은 디스크 밸런싱이 "균형" 상태로 실행된 후 혼합된 클러스터의 예를 보여준다.
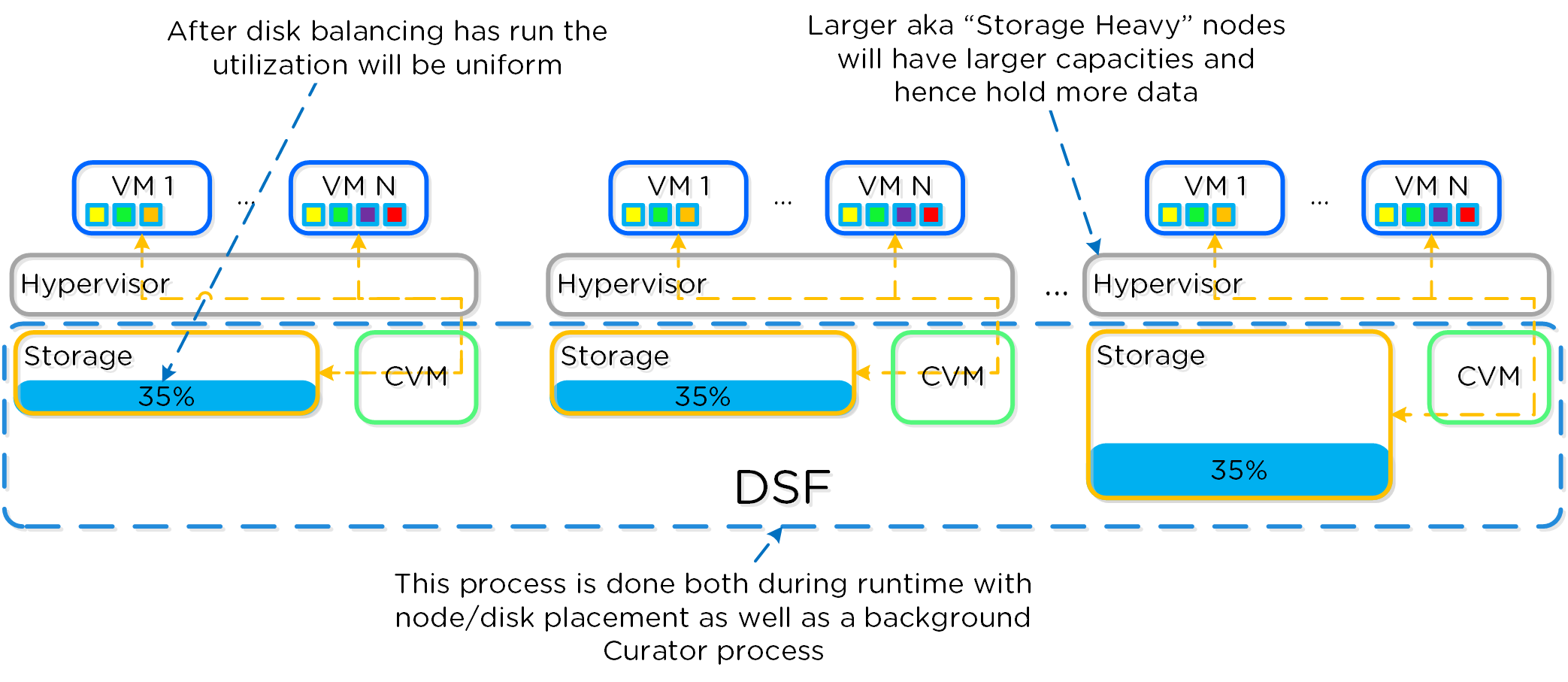 디스크 밸런싱 – 균일한 상태 (Disk Balancing - Balanced State)
디스크 밸런싱 – 균일한 상태 (Disk Balancing - Balanced State)
일부 시나리오에서 고객은 일부 노드를 노드에서 단지 CVM만 실행되고 주요 목적이 대용량 스토리지인 "스토리지 전용" 상태로 실행할 수 있다. 이 경우 훨씬 큰 읽기 캐시를 제공하기 위해 전체 노드의 메모리를 CVM에 추가할 수 있다.
다음 그림은 디스크 밸런싱이 있는 혼합 클러스터에서 데이터를 액티브 VM 노드로부터 스토리지 전용 노드로 이동하는 모습을 보여주는 예제이다.
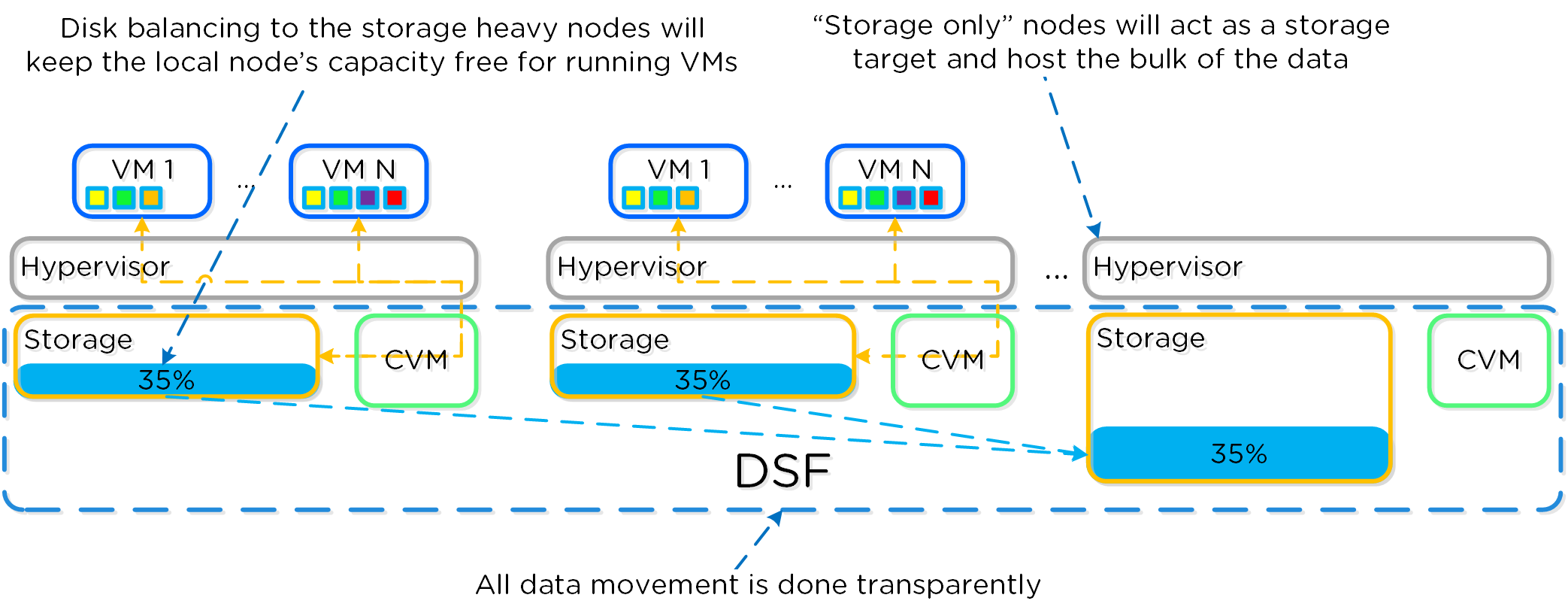 디스크 밸런싱 – 스토리지 전용 노드 (Disk Balancing - Storage Only Node)
디스크 밸런싱 – 스토리지 전용 노드 (Disk Balancing - Storage Only Node)
스냅샷 및 클론
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
DSF는 VAAI, ODX, nCLI, REST API, 프리즘 등을 통해 활용할 수 있는 오프로드된 스냅샷 및 클론을 기본적으로 지원한다. 스냅샷과 클론 모두 가장 효과적이고 효율적인 ROW(Redirect-On-Write) 알고리즘을 활용한다. 위의 데이터 구조 섹션에서 설명한 것처럼 가상 머신은 뉴타닉스 플랫폼에서 vDisk인 파일(vmdk/vhdx)로 구성된다.
vDisk는 논리적으로 연속된 데이터 청크인 익스텐트로 구성되며, 이 익스텐트는 스토리지 디바이스에 파일로 저장되는 물리적으로 연속된 데이터인 익스텐트 그룹 내에 저장된다. 스냅샷 또는 클론이 수행되면 베이스 vDisk는 변경 불가능으로 표시되고 다른 vDisk가 읽기/쓰기로 생성된다. 이 시점에서 두 vDisk는 모두 동일한 블록 맵을 가지며, 블록 맵은 해당 익스텐트에 대한 vDisk의 메타데이터 매핑이다. 스냅샷 체인의 검색(읽기 레이턴시가 추가됨)을 필요로 하는 기존 접근 방식과 달리 각 vDisk에는 자체 블록 맵이 있다. 이를 통해 큰 스냅샷 체인 깊이에서 일반적으로 나타나는 오버헤드를 제거하고 성능에 영향을 주지 않고 연속적으로 스냅샷을 생성할 수 있다.
다음 그림은 스냅샷이 생성될 때 이것이 어떻게 동작하는지에 대한 예를 보여준다 (source: NTAP):
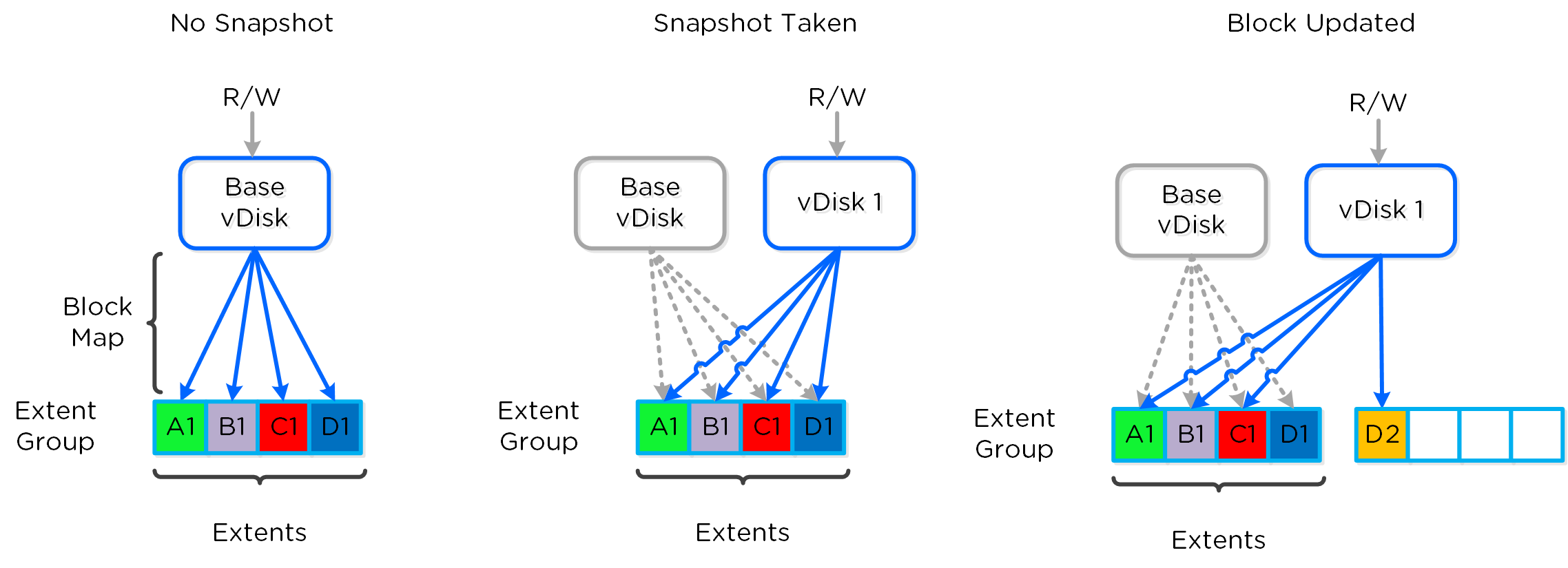 스냅샷 블록 매의 예제 (Example Snapshot Block Map)
스냅샷 블록 매의 예제 (Example Snapshot Block Map)
이전에 생성된 스냅샷 또는 클론의 vDisk에 대한 스냅샷 또는 클론이 수행될 때에도 동일한 방법이 적용된다.
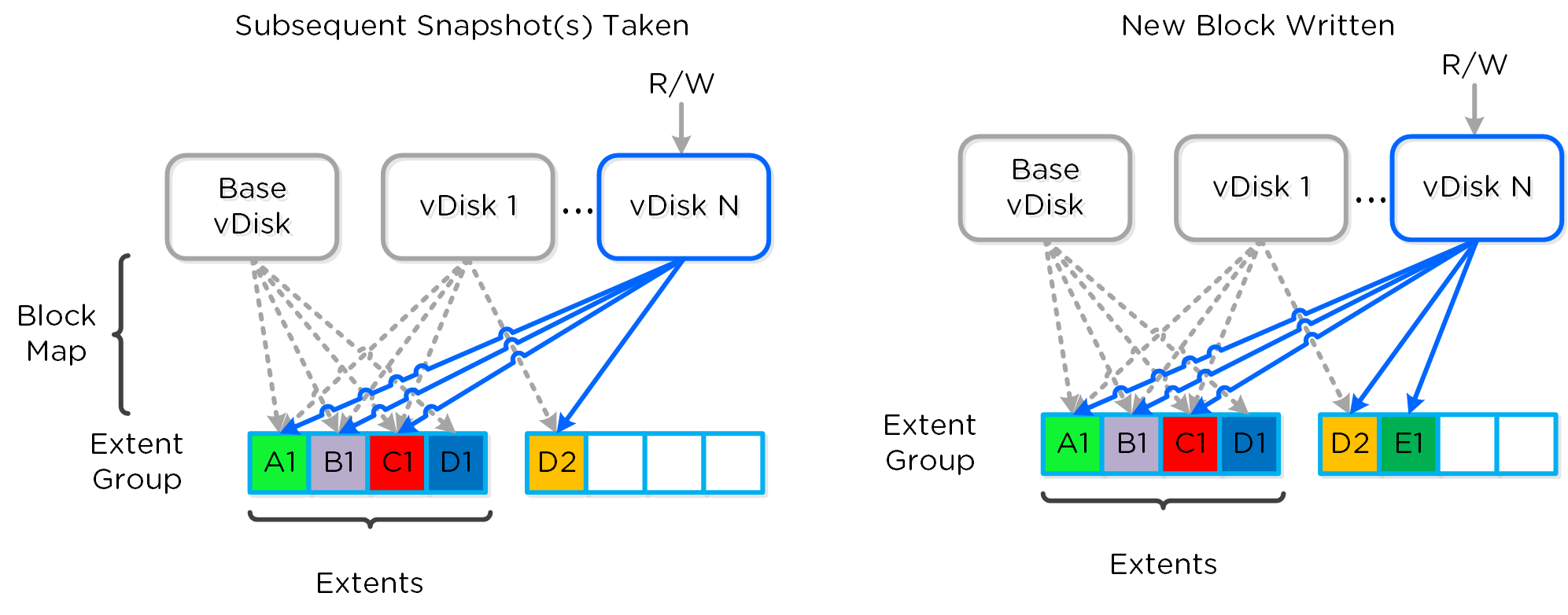 멀티-스냅샷의 블록 맵 및 신규 쓰기 (Multi-snap Block Map and New Write)
멀티-스냅샷의 블록 맵 및 신규 쓰기 (Multi-snap Block Map and New Write)
VM 또는 vDisk의 스냅샷/클론 모두에 동일한 방법이 사용된다. VM 또는 vDisk가 클론 되면 현재 블록 맵은 락킹되고 클론이 생성된다. 이러한 업데이트는 메타데이터에만 적용되므로 실제적으로 I/O는 발생하지 않는다. 클론의 클론에도 동일한 방법이 적용된다. 기본적으로 이전에 클론 된 VM이 “베이스 vDisk” 역할을 하며 클론 시에 해당 블록 맵은 락킹되고 두 개의 클론이 생성된다. 하나는 클론 될 VM을 위한 것이고 다른 하나는 새로운 클론을 위한 것이다. 클론의 최대 개수에 대한 제한은 없다.
둘 다 이전 블록 맵을 상속받으며 모든 새로운 쓰기/업데이트는 개별 블록 맵에서 발생한다.
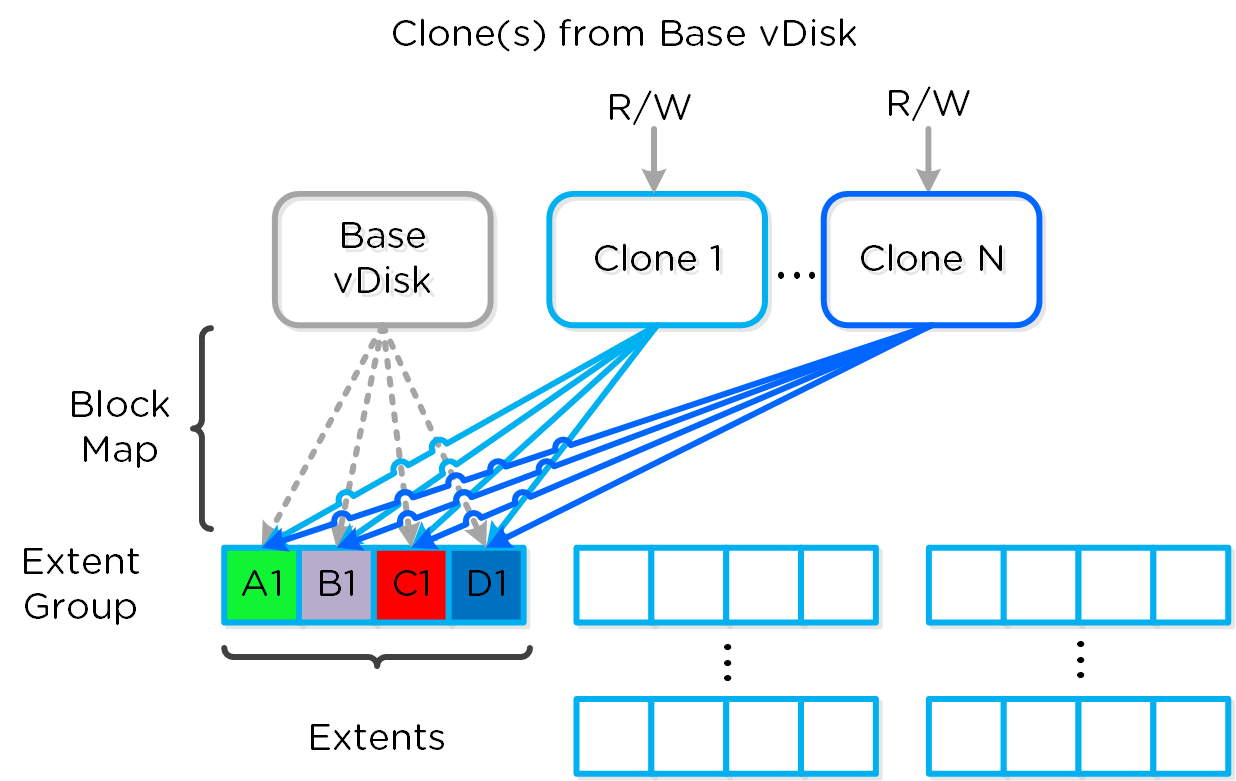 멀티-클론 블록 맵 (Multi-Clone Block Maps)
멀티-클론 블록 맵 (Multi-Clone Block Maps)
앞에서 언급한 바와 같이 각 VM/vDisk에는 고유한 개별 블록 맵이 있다. 따라서, 위의 예제에서 베이스 VM의 모든 클론은 이제 자신의 블록 맵을 가지며 모든 쓰기/업데이트는 여기에서 발생한다.
덮어쓰는 경우 데이터는 새로운 익스텐트/익스텐트 그룹으로 이동한다. 예를 들어, 데이터가 덮어쓰고 있던 익스텐트 e1의 오프셋 o1에 존재하는 경우 스타게이트는 새로운 익스텐트 e2를 생성하고, 새로운 데이터가 오프셋 o2의 익스텐트 e2에 기록되었음을 추적한다. Vblock 맵은 이를 바이트 수준까지 추적한다.
다음 그림은 이것이 어떻게 보이는지에 대한 예이다.
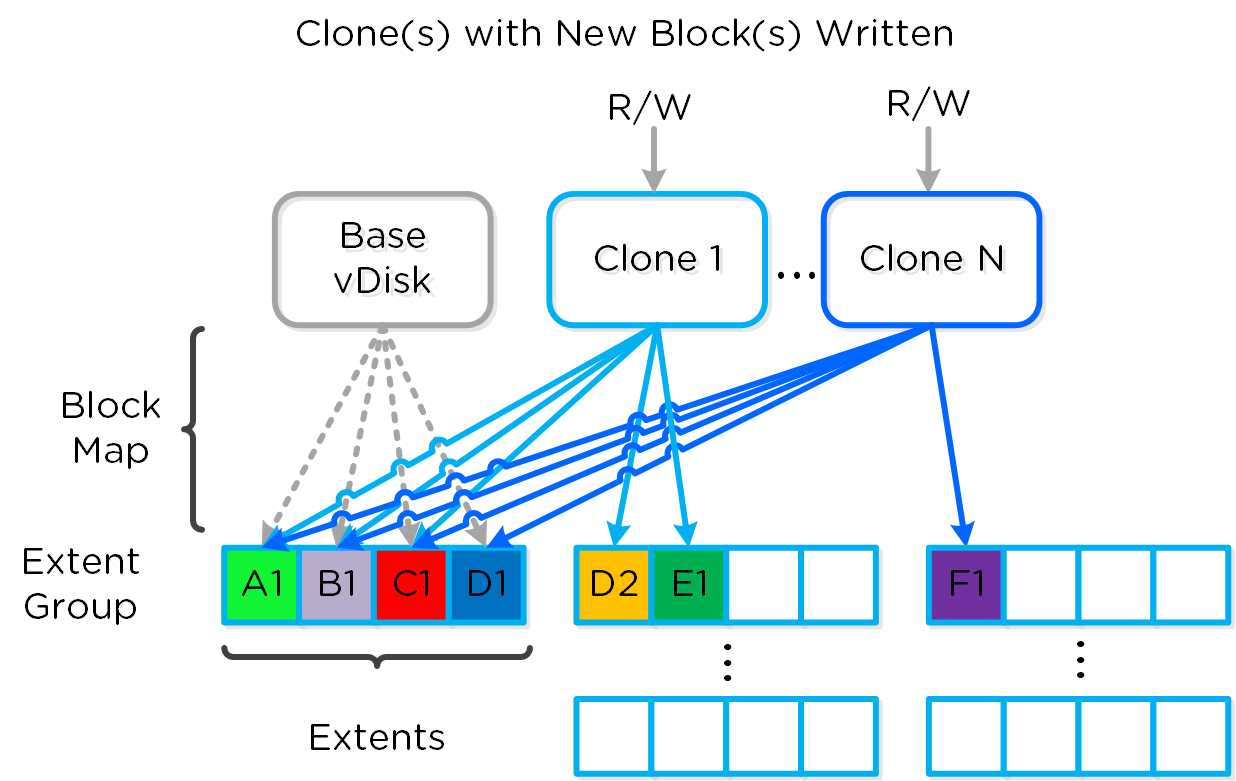 클론 블록 맵 - 새로운 쓰기 (Clone Block Maps - New Write)
클론 블록 맵 - 새로운 쓰기 (Clone Block Maps - New Write)
VM/vDisk의 후속 클론 또는 스냅샷은 오리지널 블록 맵을 락킹하고 R/W 액세스를 위한 새로운 블록 맵을 생성한다.
네트워킹 및 I/O
뉴타닉스 플랫폼은 노드 간 통신을 위해 백플레인을 활용하지 않으며 표준 10GbE 네트워크에만 의존한다. 뉴타닉스 노드에서 실행되는 VM의 모든 스토리지 I/O는 전용 사설 네트워크의 하이퍼바이저에서 처리된다. I/O 요청은 하이퍼바이저에서 처리한 다음 요청은 로컬 CVM의 사설 IP로 전달된다. 그런 다음 CVM은 공용 10GbE 네트워크를 통해 외부 IP를 사용하여 다른 뉴타닉스 노드와 원격 복제를 수행한다. 모든 읽기 요청의 경우 대부분은 로컬에서 완전히 서비스되며 10GbE 네트워크를 전혀 사용하지 않는다. 이는 공용 10GbE 네트워크를 사용하는 유일한 트래픽은 DSF 원격 복제 트래픽과 VM 네트워크 I/O라는 것을 의미한다. 그러나 CVM이 다운되거나 데이터가 원격에 있는 경우 CVM이 요청을 클러스터의 다른 CVM으로 전달하는 경우가 있다. 또한 디스크 밸런싱과 같은 클러스터 전체 작업은 10GbE 네트워크에서 일시적으로 I/O를 생성한다.
다음 그림은 VM의 I/O 경로가 사설 및 공용 10GbE 네트워크와 상호 작용하는 방법의 예를 보여준다.
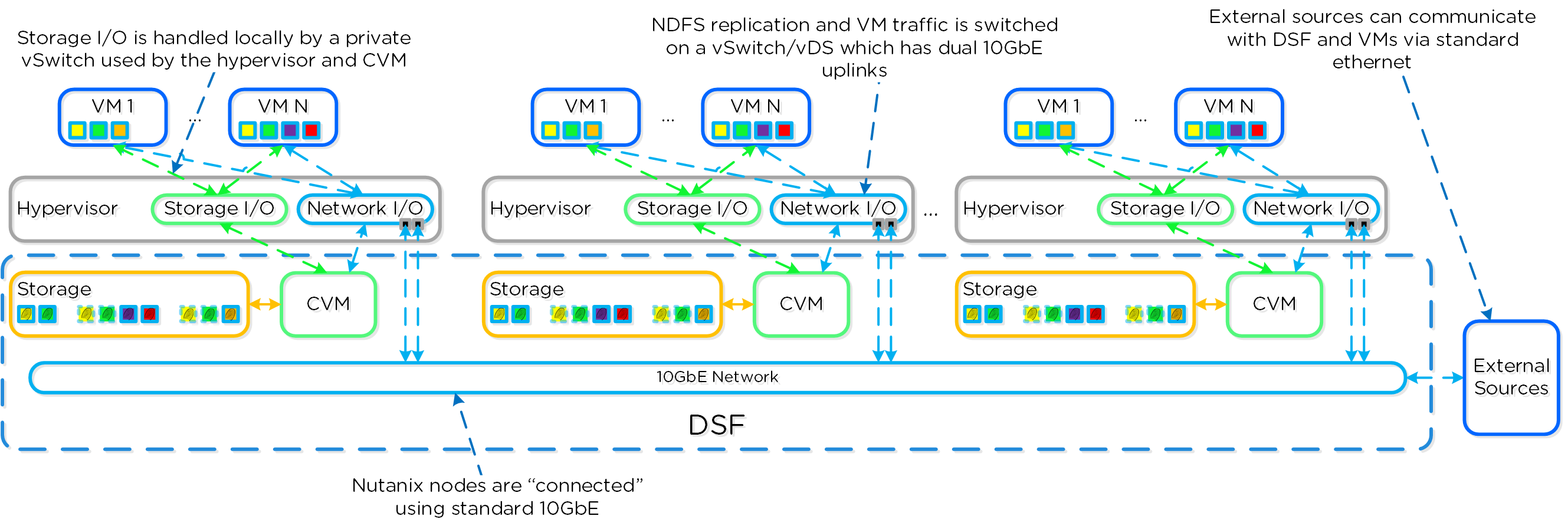 DSF 네트워킹 (DSF Networking)
DSF 네트워킹 (DSF Networking)
데이터 로컬리티
컨버지드(컴퓨트 + 스토리지) 플랫폼이므로 I/O 및 데이터 로컬리티는 뉴타닉스의 클러스터 및 VM 성능에 매우 중요하다. 위의 I/O 경로에서 설명한 바와 같이 모든 읽기/쓰기 IO는 각 하이퍼바이저에서 일반 VM과 같이 실행되는 로컬 컨트롤러 VM(CVM)에 의해 서비스된다. VM 데이터는 CVM에서 로컬로 서비스되고 CVM이 제어하는 로컬 디스크에 저장된다. VM을 한 하이퍼바이저 노드에서 다른 하이퍼바이저 노드로 이동할 때 (또는 HA 이벤트 중에) 새로 마이그레이션된 VM 데이터는 현재 로컬 CVM에 의해 서비스된다. 올드 데이터(현재는 원격 노드/CVM에 저장된)를 읽을 때 I/O는 로컬 CVM에 의해 원격 CVM으로 전달된다. 모든 쓰기 I/O는 즉시 로컬에서 발생한다. DSF는 다른 노드에서 I/O가 발생하는 것을 감지하고 백그라운드로 데이터를 로컬로 마이그레이션하여 모든 읽기 I/O가 로컬로 서비스되도록 한다. 데이터는 네트워크 플러딩이 발생하지 않도록 읽기에서만 마이그레이션된다.
데이터 로컬리티는 두 가지 주요 특징으로 발생한다.
- 캐시 로컬리티
- 원격 데이터를 로컬 스타게이트의 유니파이드 캐시로 가져온다. 이는 4K 단위로 수행된다.
- 로컬 복제본이 없는 경우 요청은 복제본이 포함된 스타게이트로 전달되어 데이터를 반환하고 로컬 스타게이트는 이를 로컬로 저장한 다음 I/O를 반환한다. 해당 데이터에 대한 모든 후속 요청은 캐시에서 리턴된다.
- 익스텐트 그룹(egroup) 로컬리티
- 로컬 스타게이트의 익스텐트 스토어에 저장될 vDisk 익스텐트 그룹(egroup) 마이그레이션
- 복제본 egroup이 이미 로컬에 존재하는 경우 이동할 필요가 없다.
- 이 시나리오에서는 특정 I/O 임계 값이 충족된 후 실제 복제본 egroup이 다시 로컬화된다. 네트워크를 효율적으로 활용하기 위해 egroup을 자동으로 Re-localize/마이그레이션하지 않는다.
- AES가 활성화된 egroup의 경우 복제본이 로컬이 아니고 패턴이 충족되면 동일한 수평 마이그레이션이 발생한다.
다음 그림은 VM이 하이퍼바이저 노드 간을 이동할 때 데이터가 VM을 따라가는 방법의 예를 보여준다.
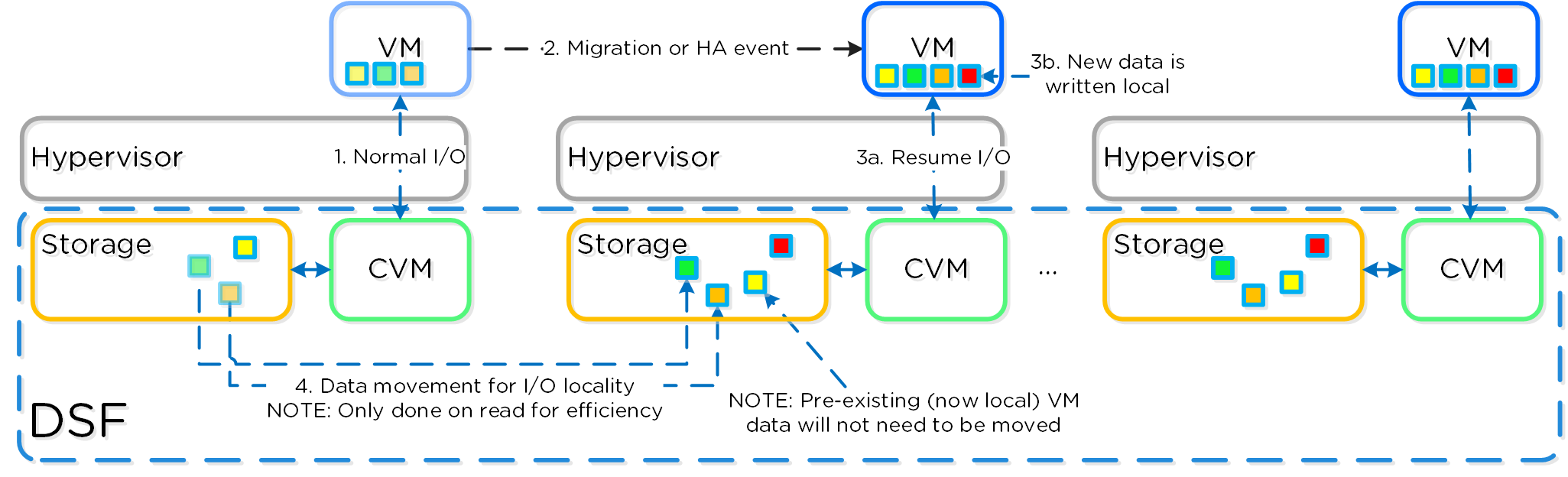 데이터 로컬리티 (Data Locality)
데이터 로컬리티 (Data Locality)
Note
데이터 마이그레이션에 대한 임계 값 (Thresholds for Data Migration)
캐시 로컬리티는 실시간으로 발생하며 vDisk 오너십에 따라 결정된다. vDisk/VM이 한 노드에서 다른 노드로 이동하면 해당 vDisk의 "오너십"이 현재 로컬 CVM으로 전송된다. 오너십이 전송되면 데이터를 유니파이드 캐시에 로컬로 캐시할 수 있다. 그동안 캐시는 오너십을 갖고 있는 곳(현재 원격 호스트)에 있다. 이전에 호스팅했던 스타게이트는 원격 I/O가 300초 이상일 때 vDisk 토큰을 포기하며 로컬 스타게이트가 토큰을 갖는다. vDisk 데이터를 캐싱하려면 오너십이 필요하므로 캐시 일관성이 적용된다.
Egroup 로컬리티는 샘플링된 오퍼레이션으로 다음과 같은 경우 익스텐트 그룹이 마이그레이션된다: 10분 단위의 윈도우에서 랜덤인 경우 3터치, 순차인 경우 10터치이고, 1터치는 매 10초 동안에 여러 번 읽기가 발생한 것을 의미한다.
쉐도우 클론
DSF에는 “멀티-리더(Multi-Reader)” 시나리오를 갖는 특정 vDisk 또는 VM 데이터를 분산 캐싱할 수 있는 “쉐도우 클론”이라는 기능이 있다. 이에 대한 가장 좋은 사례는 VDI 배포 중에 많은 “링크드 클론”의 읽기 요청을 마스터 또는 베이스 VM으로 전달되는 것이다. VMware View의 경우 이를 복제본 디스크라고 하며 모든 링크드 클론에서 읽히고, XenDesktop에서는 이를 MCS 마스터 VM이라고 한다. 이것은 "멀티-리더” 시나리오(e.g. 배포 서버, 리파지토리 등)일 수 있는 모든 시나리오에서 동작한다. 데이터 또는 I/O 로컬리티는 가능한 최고의 VM 성능을 위해 매우 중요하며 DSF의 핵심 기능이다.
쉐도우 클론을 사용하면 DSF는 데이터 로컬리티를 위해 수행했던 것과 유사하게 vDisk 액세스 트랜드를 모니터링한다. 그러나 둘 이상의 원격 CVM(로컬 CVM뿐만 아니라)에서 요청이 발생하고 모든 요청이 읽기 I/O인 경우 vDisk는 변경 불가능으로 표시된다. 디스크가 변경 불가능으로 표시되면 각 CVM은 읽기 요청을 캐시로 만들기 위해 vDisk를 로컬로 캐싱한다 (베이스 vDisk의 쉐도우 클론으로 알려진). 이렇게 하면 각 노드의 VM은 베이스 VM의 vDisk를 로컬에서 읽을 수 있다. VDI의 경우 이는 복제본 디스크가 각 노드에 의해 캐싱되고 베이스 VM에 대한 모든 읽기 요청이 로컬에서 서비스된다는 것을 의미한다. NOTE: 네트워크 플러딩을 방지하고 효율적인 캐시 사용률을 위해 데이터는 읽기 전용으로만 마이그레이션된다. 베이스 VM이 변경되면 쉐도우 클론은 삭제되고 프로세스가 다시 시작된다. 쉐도우 클론은 기본적으로 활성화(AOS 4.0.2 기준) 되어 있으며, 다음 nCLI 명령을 사용하여 활성화/비활성화할 수 있다 (ncli cluster edit-params enable-shadow-clones=<true/false>).
다음 그림은 쉐도우 클론 및 분산 캐싱 동작 방식을 보여준다.
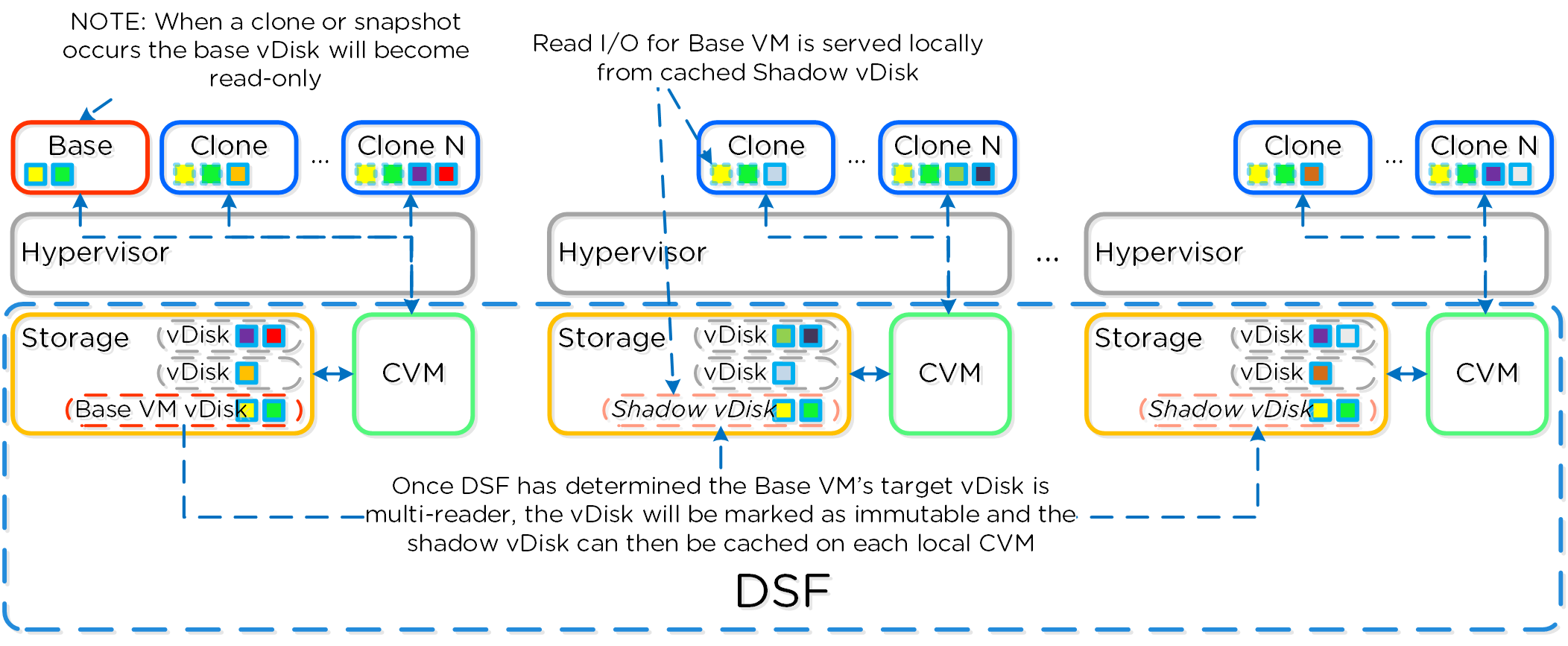 쉐도우 클론 (Shadow Clones)
쉐도우 클론 (Shadow Clones)
스토리지 계층 및 모니터링
뉴타닉스 플랫폼은 VM/게스트 OS에서 물리적 디스크 디바이스에 이르기까지 스택 전체의 다양한 계층에서 스토리지를 모니터링한다. 솔루션을 모니터링할 때마다 다양한 계층과 이러한 계층이 어떻게 관련되는지 아는 것이 중요하며, 이를 통해 운영이 어떻게 관련되는지 완벽하게 파악할 수 있다. 다음 그림은 오퍼레이션이 모니터링되는 다양한 계층과 아래에 설명될 상대적인 세분성을 보여준다.
 스토리지 계층 (Storage Layers)
스토리지 계층 (Storage Layers)
가상머신 계층 (Virtual Machine Layer)
- 주요 역할: 하이퍼바이저가 제공하는 VM에 대한 메트릭스
- 설명: VM 또는 게스트 수준의 메트릭스는 하이퍼바이저에서 직접 가져오며, VM이 보는 성능과 애플리케이션이 보는 I/O 성능을 나타낸다.
- 사용 시기: 장애 처리 또는 VM 수준의 상세 정보가 필요한 경우
하이퍼바이저 계층 (Hypervisor Layer)
- 주요 역할: 하이퍼바이저가 제공하는 메트릭스
- 설명: 하이퍼바이저 수준 메트릭스는 하이퍼바이저로부터 직접 가져오며 하이퍼바이저가 보는 가장 정확한 메트릭스이다. 이 데이터는 많은 하이퍼바이저 노드 중의 하나 또는 전체 클러스터에 대해 볼 수 있다. 이 계층은 플랫폼이 보고 있는 성능 측면에서 가장 정확한 데이터를 제공하며 대부분의 경우에 활용된다. 특정 시나리오에서 하이퍼바이저는 VM에서 오는 오퍼레이션을 결합하거나 분할하여 VM과 하이퍼바이저에서 보고하는 메트릭스의 차이를 표시할 수 있다. 이 수치에는 뉴타닉스 CVM에 의해 서비스되는 캐시 히트가 포함된다.
- 사용 시기: 가장 상세하고 가치 있는 메트릭스를 제공하므로 대부분의 경우에 필요
컨트롤러 계층 (Controller Layer)
- 주요 역할: 뉴타닉스 컨트롤러가 제공하는 메트릭스
- 설명: 컨트롤러 수준 메트릭스는 뉴타닉스 컨트롤러 VM(e.g. 스타게이트 2009 페이지)에서 직접 가져오며, 뉴타닉스 프런트엔드가 NFS/SMB/iSCSI에서 보는 정보 또는 모든 백엔드 오퍼레이션(e.g. ILM, 디스크 밸런싱 등) 정보를 제공한다. 이 데이터는 많은 컨트롤러 VM 중의 하나 또는 전체 클러스터에 대해 볼 수 있다. 컨트롤러 계층에서 불 수 있는 메트릭스는 하이퍼바이저 계층에서 볼 수 있는 것과 일반적으로 일치해야 하지만 모든 백엔드 오퍼레이션(e.g. ILM, 디스크 밸런싱 등)을 포함한다. 이 수치에는 메모리에 의해 서비스되는 캐시 히트가 포함된다. NFS/SMB/iSCSI 클라이언트가 큰 IO를 여러 개의 작은 IOPS로 분할할 수 있으므로 특정 경우 (IOPS)와 같은 메트릭스가 일치하지 않을 수 있다. 그러나 대역폭과 같은 메트릭스는 일치해야 한다.
- 사용 시기: 하이퍼바이저 계층과 유사하게 얼마나 많은 백엔드 오퍼레이션이 수행되고 있는지를 보여주는 데 사용할 수 있다.
디스크 계층 (Disk Layer)
- 주요 역할: 디스크 디바이스가 제공하는 메트릭스
- 설명: 디스크 수준 메트릭스는 물리적 디스크 디바이스에서 직접 가져오며(CVM을 통해)부터 직접 가져오며 백엔드가 보고 있는 내용을 제공한다.. 여기에는 디스크에서 I/O가 수행되는 OpLog 또는 익스텐트 스토어에 히팅하는 데이터가 포함된다. 이 데이터는 많은 디스크 중의 하나, 특정 노드의 디스크 또는 클러스터 전체 디스크에 대해 볼 수 있다. 일반적인 경우 디스크 오퍼레이션은 들어오는 쓰기 수와 캐시의 메모리 부분에서 서비스되지 않는 읽기 수와 일치해야 한다. 캐시의 메모리 부분에서 서비스되는 모든 읽기는 해당 오퍼레이션이 디스크 디바이스를 사용하지 않기 때문에 여기에서 카운트되지 않는다.
- 사용 시기: 캐시 또는 디스크에서 처리되는 오퍼레이션 수를 확인할 때
Note
메트릭스 및 통계 보존 (Metric and Stat Retention)
메트릭스 및 시계열 데이터는 프리즘 엘리먼트에서 90일 동안 저장된다. 프리즘 센트럴 및 인사이트의 경우 데이터를 무한정 저장할 수 있다 (용량이 충분하다고 가정).
서비스
뉴타닉스 게스트 툴 (NGT)
뉴타닉스 게스트 툴(Nutanix Guest Tool)은 뉴타닉스 플랫폼을 통해 고급 VM 관리 기능을 지원하는 소프트웨어 기반의 인-게스트 에이전트 프레임워크이다.
솔루션은 VM에 설치되는 NGT 인스톨러와 뉴타닉스 플랫폼과 에이전트 간의 코디네이션 기능을 수행하는 게스트 툴 프레임워크로 구성된다.
NGT 인스톨러는 다음과 같은 컴포넌트를 포함한다.
- 게스트 에이전트 서비스
- 파일-레벨 리스토어(FLR) CLI로 알려진 셀프-서비스 리스토어(SSR)
- VM 모빌리티 드라이버 (AHV 용 VritIO 드라이버)
- 윈도우즈 VM 용 VSS 에이전트 및 하드웨어 프로바이더
- 리눅스 VM을 위한 애플리케이션 컨시스턴트 스냅샷 지원 (Quiesce를 위한 스크립트를 통해)
프레임워크는 몇 개의 하이-레벨 컴포넌트로 구성되어 있다.
- 게스트 툴 서비스 (Guest Tool Service)
- AOS, 뉴타닉스 서비스, 게스트 에이전트 간의 게이트웨이다. 현재 프리즘 리더(클러스터 VIP를 호스팅)에서 실행되는 선출된 NGT 마스터와 함께 클러스터 내의 CVM에 분산된다.
- 게스트 에이전트 (Guest Agent)
- NGT 설치 프로세스의 일부로 VM의 OS에 배포되는 에이전트 및 관련된 서비스이다. 로컬 기능(e.g., VSS, 셀프-서비스 리스토어(SSR) 등)을 처리하고 게스트 툴 서비스와 상호 작용한다.
그림은 컴포넌트의 하이-레벨 매핑을 보여준다.
 게스트 툴 매핑 (Guest Tools Mapping)
게스트 툴 매핑 (Guest Tools Mapping)
게스트 툴 서비스 (Guest Tools Service)
게스트 툴 서비스는 두 가지 주요 역할로 구성된다.
- NGT 리더 (NGT Leader)
- NGT 프록시에서 오는 요청을 처리하고 AOS 컴포넌트와 인터페이스한다. 클러스터 당 단일 NGT 리더가 동적으로 선출되고 현재 리더에 장애가 발생하면 새로운 리더가 선출된다. 이 서비스는 내부적으로 포트 2073에서 수신 대기한다.
- NGT 프록시 (NGT Proxy)
- 모든 CVM에서 실행되며 원하는 액티비티를 수행하기 위해 요청을 NGT 리더로 전달한다. 프리즘 리더(VIP를 호스팅) 역할을 하는 현재 VM이 게스트 에이전트와의 통신을 처리하는 액티브 CVM이다. 외부적으로 포트 2074에서 수신 대기한다.
Note
현재 NGT 리더 (Current NGT Leader)
다음 명령을 사용하여 NGT 리더 역할을 호스팅하는 CVM의 IP를 찾을 수 있다 (CVM에서 실행).
nutanix_guest_tools_cli get_leader_location
그림은 역할의 하이-레벨 매핑을 보여준다.
 게스트 툴 서비스 (Guest Tool Service)
게스트 툴 서비스 (Guest Tool Service)
게스트 에이전트 (Guest Agent)
게스트 에이전트는 앞에서 언급한 다음과 같은 하이-레벨 컴포넌트로 구성된다.
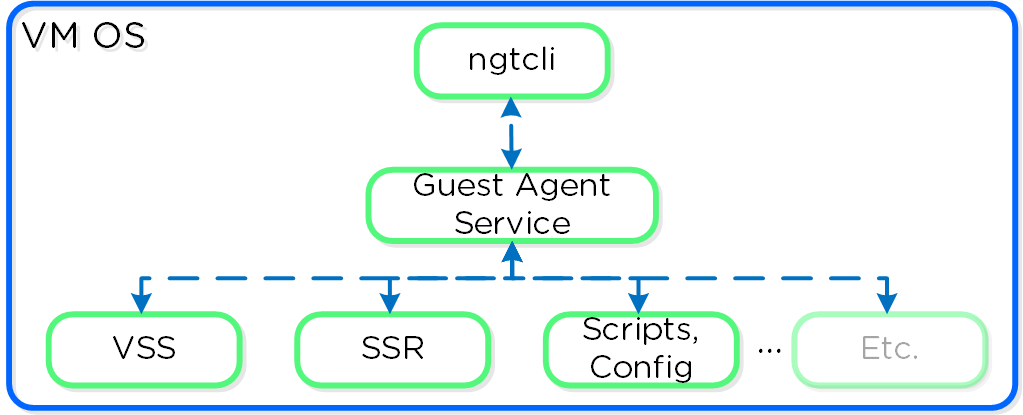 게스트 에이전트 (Guest Agent)
게스트 에이전트 (Guest Agent)
통신 및 보안 (Communication and Security)
게스트 에이전트 서비스는 SSL을 사용하여 뉴타닉스 클러스터 가상 IP를 통해 게스트 툴 서비스와 통신한다. 뉴타닉스 클러스터 컴포넌트와 UVM이 다른 네트워크(전체 모두)에 있는 경우 다음이 가능한지 확인하여야 한다.
- UVM 네트워크로부터 클러스터 가상 IP로 라우팅된 통신을 보장하거나
OR
- 포트 2074(선호)에서 클러스터 가상 IP와 통신이 가능하도록 UVM 네트워크에서 방화벽 규칙(및 관련 NAT)을 생성한다.
게스트 툴 서비스는 CA 역할을 수행하며 NGT가 활성화된 각 VUM을 위한 인증서 쌍을 생성한다. 이 인증서는 VUM 용으로 설정되고 NGT 배포 프로세스의 일부로 사용되는 ISO에 내장된다. 이러한 인증서는 설치 프로세스의 일부로 VUM 내부에 설치된다.
NGT 에이전트 설치 (NGT Agent Installation)
NGT 에이전트 설치는 프리즘 또는 CLI/Scripts(nCLI/REST/PowerShell)를 통해 수행할 수 있다.
프리즘을 통해 NGT를 설치하려면 VM 페이지로 이동하여 NGT를 설치할 VM을 선택한 후 “Enable NGT”를 클릭한다.
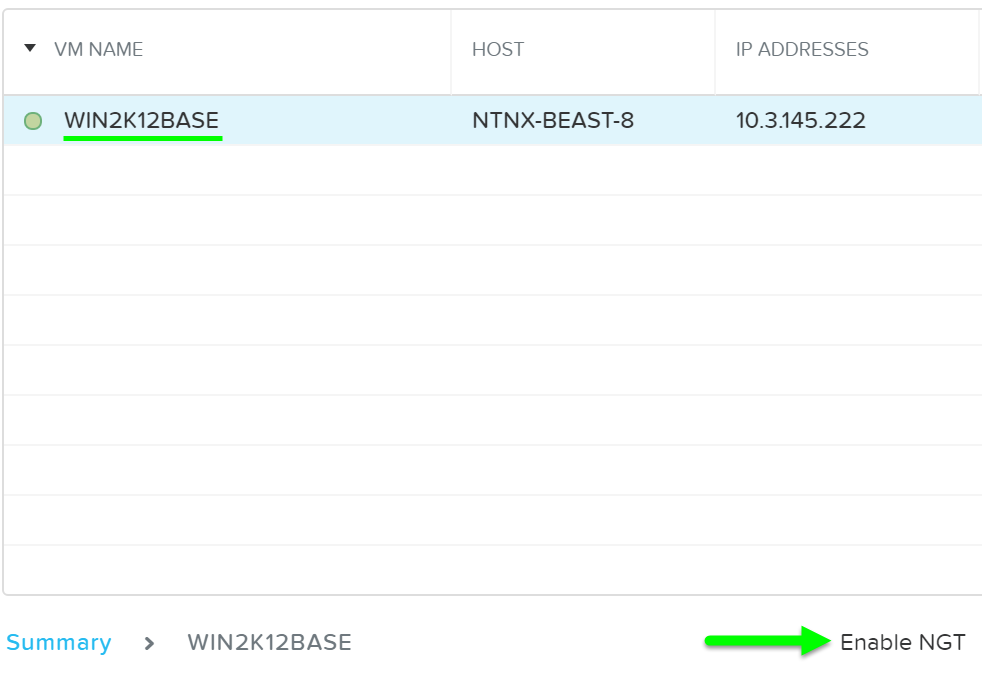 VM에서 NGT 활성화 (Enable NGT for VM)
VM에서 NGT 활성화 (Enable NGT for VM)
NGT 설치를 계속하려면 프롬프트에서 “Yes”를 클릭한다.
 NGT 프롬프트 활성화 (Enable NGT Prompt)
NGT 프롬프트 활성화 (Enable NGT Prompt)
VM은 소프트웨어와 고유한 인증서를 포함하는 생성된 인스톨러가 아래에서 보는 갓과 같이 마운트된 CD-ROM을 가져야 한다.
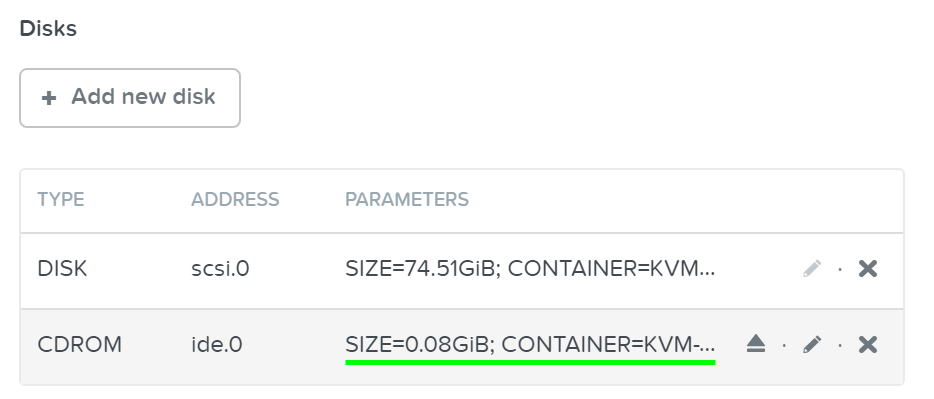 NGT 활성화 – CD-ROM (Enable NGT - CD-ROM)
NGT 활성화 – CD-ROM (Enable NGT - CD-ROM)
OS에서 NGT 인스톨러 CD-ROM을 볼 수 있다.
 NGT 활성화 – OS에서 CD-ROM (Enable NGT - CD-ROM in OS)
NGT 활성화 – OS에서 CD-ROM (Enable NGT - CD-ROM in OS)
설치 프로세스를 시작하려면 CD-ROM을 더블클릭한다.
Note
자동 설치 (Silent Installation)
다음 명령을 실행(CD-ROM 위치에서)하여 뉴타닉스 게스트 툴 자동 설치를 수행할 수 있다.
NutanixGuestTools.exe /quiet /l log.txt ACCEPTEULA=yes
프롬프트에 따라 라이선스를 수락하고 설치를 완료한다.
 NGT 활성화 – 인스톨러 (Enable NGT - Installer)
NGT 활성화 – 인스톨러 (Enable NGT - Installer)
설치 프로세스의 일부로 Python, PyWin, 뉴타닉스 모빌리티 드라이버(크로스-하이퍼바이저 호환성)가 설치된다.
설치가 완료된 후 재부팅해야 한다.
설치 및 재부팅에 성공하면 “Programs and Features”에 다음 항목이 표시된다.
 NGT 활성화 – 설치된 프로그림 (Enable NGT - Installed Programs)
NGT 활성화 – 설치된 프로그림 (Enable NGT - Installed Programs)
NGT 에이전트 및 VSS 하드웨어 프로바이더 서비스가 실행된다.
 NGT 활성화 – 서비스 (Enabled NGT - Services)
NGT 활성화 – 서비스 (Enabled NGT - Services)
이제 NGT가 설치되었으므로 사용할 수 있다.
Note
대량 NGT 배포 (Bulk NGT Deployment)
각 개별 VM에 NGT를 설치하는 대신 베이스 이미지에 NGT를 내장하고 배포하는 것이 가능하다.
베이스 이미지 내에서 NGT를 활용하려면 다음 프로세스를 따른다.
- 리더 VM에 NGT를 설치하고 통신을 보장
- 리더 VM에서 VM 클론
- 각 클론에 NGT ISO 마운트 (새로운 인증서 쌍을 가져오기 위해 필요)
- 예제: ncli ngt mount vm-id=<CLONE_ID> OR via Prism
- 자동화 방법: 곧 제공 예정
- 클론 전원 켜기
클론된 VM이 부팅하면 새로운 NGT ISO를 감지하고 관련 설정 파일 및 새 인증서를 복사하고 게스트 툴 서비스와 통신을 시작한다.
OS 커스터마이제이션
뉴타닉스는 Cloudinit 및 Sysprep을 활용한 네이티브 OS 커스터마이제이션 기능을 제공한다. CloudInit은 Linux 클라우드 서버의 부트스트랩을 처리하는 패키지이다. 이를 통해 Linux 인스턴스의 초기 초기화 및 커스터마이제이션이 가능하다. Sysprep은 Windows 용 OS 커스터마이제이션 툴이다.
몇 가지 일반적인 용도는 다음과 같다.
- 호스트 이름 설정
- 패키지 설치
- 사용자 추가 및 키 관리
- 커스텀 스크립트
지원 환경 (Supported Configurations)
솔루션은 아래 버전을 포함하여 AHV에서 실행되는 Linux 게스트에 적용할 수 있다 (목록이 완전하지 않을 수 있으니 전체 지원 목록은 별도 문서 참조).
- 하이퍼바이저
- AHV
- 운영체제
- Linux: 대부분의 최신 배포 버전
- Windows: 대부분의 최신 배포 버전
전체 조건 (Pre-Requisites)
Cloudinit을 사용하려면 다음이 필요하다.
- Cloudinit 패키지가 Linux 이미지에 설치되어야 한다.
Sysprep은 Windows 설치에서 기본적으로 사용할 수 있다.
패키지 설치 (Package Installation)
다음 명령을 사용하여 CloudInit을 설치할 수 있다 (설치되지 않은 경우).
Red Hat 기반 시스템 (CentOS, RHEL)
yum -y install CloudInit
Debian 기반 시스템 (Ubuntu)
apt-get -y update; apt-get -y install CloudInit
Sysprep은 기본 Windows 설치의 일부이다.
이미지 커스터마이제이션 (Image Customization)
OS 커스터마이제이션을 위해 커스텀 스크립트를 활용할 수 있도록 프리즘 또는 REST API에서 체크 박스와 입력을 사용할 수 있다. 이 옵션은 VM의 생성 및 클론 프로세스 중에 지정된다.
 사용자 정의 스크립트 – 입력 옵션 (Custom Script - Input Options)
사용자 정의 스크립트 – 입력 옵션 (Custom Script - Input Options)
뉴타닉스에는 커스텀 스크립트 경로 지정을 위한 몇 가지 옵션이 있다.
- ADSF 경로
- 이전에 ADSF에 업로드한 파일 사용
- 파일 업로드
- 사용될 파일 업로드
- 스크립트 입력 또는 복사
- Cloudinit 스크립트 또는 Unatttend.xml 텍스트
뉴타닉스는 스크립트가 포함된 CD-ROM을 생성하여 처음 부팅하는 동안 유저 데이터 스크립트를 Cloudinit 또는 Sysprep 프로세스로 전달한다. 프로세스가 완료되면 CD-ROM을 제거한다.
입력 포맷팅 (Input formatting)
플랫폼은 상당한 양의 유저 데이터 입력 형식을 지원한다. 일부 주요 형식은 다음과 같다:
유저-데이터 스크립트 (Cloudinit – Linux)
유저-데이터 스크립트는 부팅 프로세스에서 후반에 실행되는 간단한 쉘 스크립트이다 (e.g. “rc.local-like”).
스크립트는 bash 스크립트(“#!”)와 유사하게 시작한다.
아래는 유저-데이터 스크립트의 예이다.
#!/bin/bash touch /tmp/fooTest mkdir /tmp/barFolder
Include File (CloudInit - Linux)
Include file은 URL 목록을 포함한다 (한 줄에 하나씩). 각 URL을 읽고 다른 스크립트와 유사하게 처리한다.
스크립트는 “#include”로 시작한다.
다음은 Include 스크립트의 예이다.
#include http://s3.amazonaws.com/path/to/script/1 http://s3.amazonaws.com/path/to/script/2
클라우드 설정 데이터 (CloudInit - Linux)
cloud-config 입력 유형은 CloudInit에 가장 일반적이며 고유하다.
스크립트는 “#cloud-init”으로 시작한다.
아래는 클라우드 설정 데이터 스크립트의 예를 보여준다.
#cloud-config # Set hostname hostname: foobar # Add user(s) users: - name: nutanix sudo: ['ALL=(ALL) NOPASSWD:ALL'] ssh-authorized-keys: - ssh-rsa: PUBKEY lock-passwd: false passwd: PASSWORD # Automatically update all of the packages package_upgrade: true package_reboot_if_required: true # Install the LAMP stack packages: - httpd - mariadb-server - php - php-pear - php-mysql # Run Commands after execution runcmd: - systemctl enable httpd
Note
Cloudinit 실행 검증 (Validating CloudInit Execution)
Cloudinit 로그 파일은 /var/log/cloud-init.log 및 cloud-init-output.log에서 찾을 수 있다.
Unattend.xml (Sysprep - Windows)
Unattend.xml 파일은 부팅 시에 이미지 커스터마이제이션을 위해 Sysprep이 사용하는 입력 파일이다. 보다 자세한 정보는 다음 링크를 참조: LINK
스크립트는 “<?xml version="1.0" ?>”으로 시작한다.
첨부는 샘플 unattend.xml 파일이다
Karbon (컨테이너 서비스)
뉴타닉스는 쿠버네티스(Kubernetes) (현재)를 사용하여 뉴타닉스 플랫폼에서 영구 컨테이너를 활용할 수 있는 기능을 제공한다. 이전에 뉴타닉스 플랫폼에서 도커를 실행하는 것이 가능했지만 컨테이너의 비영구적 속성으로 인해 데이터 영속성에 대한 이슈가 있었다.
도커와 같은 컨테이너 기술은 하드웨어 가상화에 대한 다른 접근 방식이다. 기존 가상화에서 각 VM은 자신의 OS를 갖지만 기반 하드웨어를 공유한다. 애플리케이션 및 모든 해당 종속성을 포함하는 컨테이너는 기반 OS 커널을 공유하는 격리된 프로세스로 실행된다.
다음 표는 VM과 컨테이너를 간단히 비교한 것이다.
| 구분 | 가상머신 (VM) | 컨테이너 (Containers) |
|---|---|---|
| 가상화 유형 | 하드웨어-레벨 가상화 | OS 커널 가상화 |
| 오버헤드 | 많음 | 적음 |
| 프로비저닝 속도 | 느림 (수초 ~ 수분) | 실시간 / 빠름 (us ~ ms) |
| 성능 오버헤드 | 제한된 성능 | 네이티브 성능 |
| 보안 | 완전한 격리 (보안에 유리) | 프로세스 레벨의 격리 (보안 취약) |
지원 환경 (Supported Configurations)
솔루션은 아래 환경에 적용할 수 있다 (목록이 완전하지 않을 수 있으니 전체 지원 목록은 별도 문서 참조).
- 하이퍼바이저
- AHV
- 컨테이너 시스템*
- Docker 1.13
*AOS 4.7 기준으로 솔루션은 도커 기반 컨테이너와의 스토리지 통합만을 지원한다. 그러나 다른 종류의 컨테이너 시스템은 뉴타닉스 플랫폼에서 VM으로 실행할 수 있다.
컨테이너 서비스 컨스트럭트 (Container Services Constructs)
다음 엔티티는 카본 컨테이너 서비스(Karbon Container Services)를 구성한다.
- Nutanix Docker Machine Driver: 도커 머신 및 AOS 이미지 서비스를 통해 도커 컨테이너 호스트 프로비저닝을 처리한다.
- Nutanix Docker Volume Plugin: 원하는 컨테이너에 볼륨을 생성, 마운트, 포맷 및 부착하기 위해 AOS Volumes과의 인터페이스를 담당한다.
다음 엔티티는 도커를 구성한다 (Note: 모두 필요한 것은 아님).
- Docker Image: 컨테이너의 베이스 및 이미지
- Docker Registry: 도커 이미지 저장 공간
- Docker Hub: 온라인 컨테이너 마켓플레이스 (퍼블릭 도커 레지스트리)
- Docker File: 도커 이미지를 구성하는 방법을 설명하는 텍스트 파일
- Docker Container: 도커 이미지의 실행 인스턴스
- Docker Engine: 도커 컨테이너의 생성, 배포, 실행
- Docker Swarm: 도커 호스트 클러스터링/스케줄링 플랫폼
- Docker Daemon: 도커 클라이언트의 요청을 처리하고, 컨테이너의 빌드, 배포, 실행 등과 같은 작업을 수행
- Docker Store: 신뢰할 수 있는 엔터프라이즈 레벨의 컨테이너를 위한 마켓 플레이스
서비스 아키텍처 (Services Architecture)
현재 뉴타닉스 솔루션은 도커 머신을 사용하여 생성된 VM에서 실행되는 도커 엔진을 활용한다. 이러한 시스템은 플랫폼의 일반 VM과 함께 실행될 수 있다.
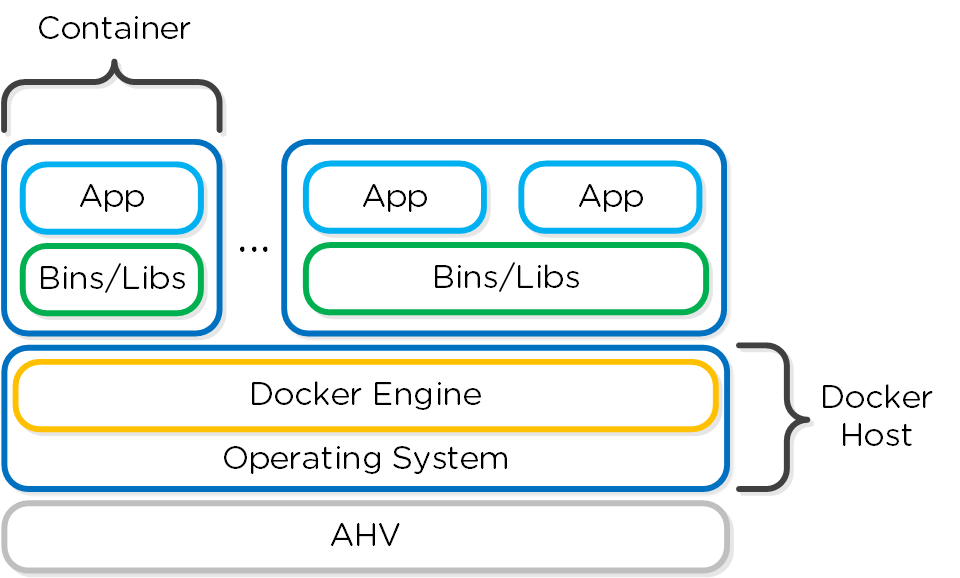 도커 – 하이 레벨 아키텍처 (Docker - High-level Architecture)
도커 – 하이 레벨 아키텍처 (Docker - High-level Architecture)
뉴타닉스는 AOS Volumes 기능을 사용하여 볼륨을 컨테이너에 생성, 포맷 및 부착할 수 있는 Docker Volume Plugin을 개발했다. 이를 통해 컨테이너의 전원을 껐다가 켜거나 이동할 때 데이터가 유지될 수 있다.
데이터 영속성은 AOS Volumes을 활용하여 호스트/컨테이너에 볼륨을 부착하는 Nutanix Volume Plugin을 사용하여 달성된다.
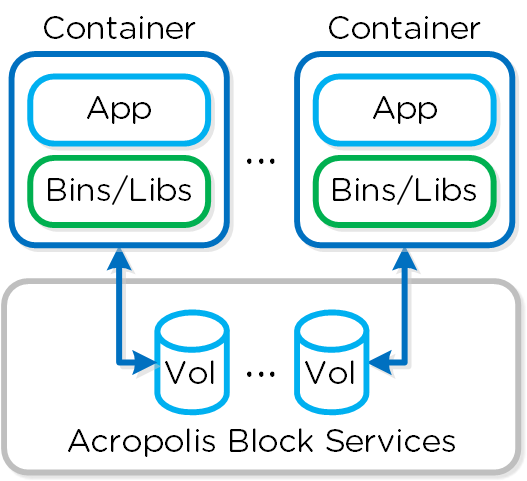 도커 - 볼륨 (Docker - Volumes)
도커 - 볼륨 (Docker - Volumes)
전제 조건 (Pre-Requisites)
컨테이너 서비스를 사용하려면 다음이 필요하다.
- 뉴타닉스 클러스터는 AOS 4.7 이상 이여야 한다.
- iscsi-initiator-utils 패키지가 설치된 CentOS 7.0+ 또는 Rhel 7.2+ OS 이미지를 다운로드하여 AOS 이미지 서비스에 이미지로 존재해야 한다
- 뉴타닉스 데이터 서비스 IP(Data Services IP)가 설정되어야 한다.
- 설정을 위해 사용되는 클라이언트 머신에 도커 툴박스가 설치되어야 한다.
- 뉴타닉스 Docker Machine Driver가 클라이언트 PATH에 있어야 한다.
도커 호스트 생성 (Docker Host Creation)
모든 전제 조건이 충족되었다고 가정하면 첫 번째 단계는 도커 머신을 사용하여 뉴타닉스 도커 호스트를 프로비저닝하는 것이다.
docker-machine -D create -d nutanix \ --nutanix-username PRISM_USER --nutanix-password PRISM_PASSWORD \ --nutanix-endpoint CLUSTER_IP:9440 --nutanix-vm-image DOCKER_IMAGE_NAME \ --nutanix-vm-network NETWORK_NAME \ --nutanix-vm-cores NUM_CPU --nutanix-vm-mem MEM_MB \ DOCKER_HOST_NAME
다음 그림은 백엔드 워크플로우의 개요를 보여준다.
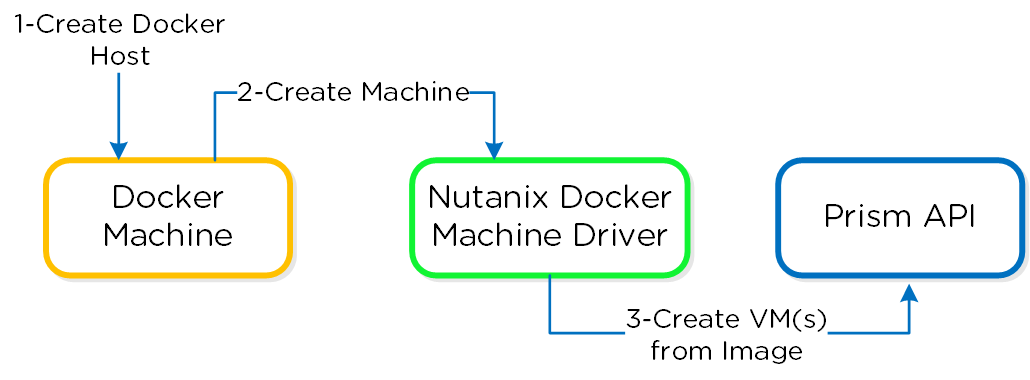 도커 – 호스트 생성 워크플로우 (Docker - Host Creation Workflow)
도커 – 호스트 생성 워크플로우 (Docker - Host Creation Workflow)
다음 단계는 docker-machine ssh를 통해 새로 프로비저닝된 도커 호스트에 SSH로 연결하는 것이다.
docker-machine ssh DOCKER_HOST_NAME
뉴타닉스 Docker Volume Plugin을 설치하려면 다음을 실행한다.
docker plugin install ntnx/nutanix_volume_plugin PRISM_IP= DATASERVICES_IP= PRISM_PASSWORD= PRISM_USERNAME= DEFAULT_CONTAINER= --alias nutanix
실행 후 플러그인이 활성화된 것을 볼 수 있다.
[root@DOCKER-NTNX-00 ~]# docker plugin ls ID Name Description Enabled 37fba568078d nutanix:latest Nutanix volume plugin for docker true
도커 컨테이너 생성 (Docker Container Creation)
뉴타닉스 도커 호스트가 배포되고 볼륨 플러그인이 활성화되면 영구 저장소를 갖는 컨테이너를 프로비저닝할 수 있다.
AOS Volumes를 사용하는 볼륨은 일반적인 Docker volume 명령 구조를 사용하고 뉴타닉스 볼륨 드라이버를 지정하여 생성할 수 있다. 사용 예는 다음과 같다.
docker volume create \ VOLUME_NAME --driver nutanix Example: docker volume create PGDataVol --driver nutanix
다음 명령 구조를 사용하여 생성된 볼륨을 사용하여 컨테이너를 생성할 수 있다. 사용 예는 다음과 같다.
docker run -d --name CONTAINER_NAME \ -p START_PORT:END_PORT --volume-driver nutanix \ -v VOL_NAME:VOL_MOUNT_POINT DOCKER_IMAGE_NAME Example: docker run -d --name postgresexample -p 5433:5433 --volume-driver nutanix -v PGDataVol:/var/lib/postgresql/data postgres:latest
다음 그림은 백엔드 워크플로우의 하이-레벨 개요를 보여준다.
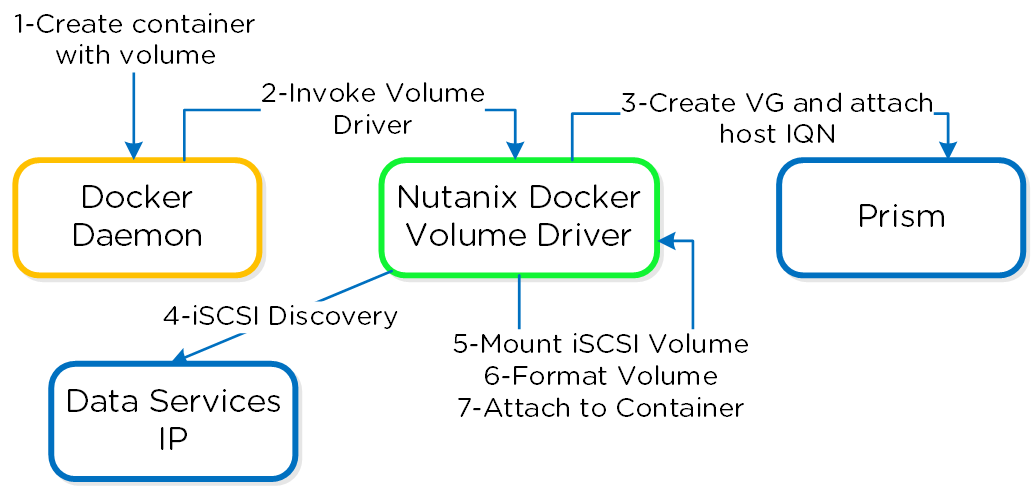 도커 – 컨테이너 생성 워크플로우 (Docker - Container Creation Workflow)
도커 – 컨테이너 생성 워크플로우 (Docker - Container Creation Workflow)
이제 영구 스토리지로 실행되는 컨테이너가 생성되었다!
백업 및 재해복구
뉴타닉스는사용자가 DSF에서 실행 중인 VM 및 오브젝트를 온-프레미스 또는 클라우드 환경(Xi)으로 백업, 복원 및 DR 할 수 있는 네이티브 백업 및 재해복구(DR) 기능을 제공한다. AOS 5.11에서 뉴타닉스는 이러한 많은 개념을 추상화한 Leap이라는 기능을 출시했다. Leap에 대한 더 자세한 정보는 'Book of Backup / DR Services'의 'Leap' 섹션을 참조한다.
다음 섹션에서 다음 항목을 다룬다.
- 구현 컨스트럭트
- 엔티티 보호
- 백업 및 복원
- 복제 및 DR
NOTE: 뉴타닉스는 백업 및 DR을 위한 네이티브 옵션을 제공하지만, 플랫폼이 제공하는 기능(VSS, 스냅샷 등)의 일부를 활용하여 기존 솔루션(e.g. Commvault, Rubrik 등)도 사용할 수 있다.
구현 컨스트럭트 (Implementation Constructs)
뉴타닉스 백업 및 DR에는 몇 가지 주요 컨스트럭트가 있다.
보호 도메인 (Protection Domain: PD)
- 주요 역할: 보호할 VM 또는 파일의 매크로 그룹
- 설명: 원하는 스케줄에 따라 함께 복제할 VM 및 파일 그룹. PD는 전체 컨테이너를 보호하거나, 개별 VM 또는 파일을 선택할 수 있다.
Note
Pro tip
원하는 RPO/RTO를 충족할 수 있도록 다양한 서비스 계층에 대해 여러 개의 PD를 생성한다. 파일 배포(e.g. 골든 이미지, ISO 등)의 경우 복제할 파일을 갖는 PD를 생성할 수 있다.
컨시스턴시 그룹 (Consistency Group: CG)
- 주요 역할: PD에서 크래시-컨시스턴트를 지원하는 VM/파일의 부분 집합
- 설명: 크래시-컨시스턴트 방식으로 스냅샷을 생성할 필요가 있는 PD의 일부인 VM/파일. VM/파일 복구될 때 일관성 있는 상태를 유지하도록 한다. PD는 여러 개의 컨시스턴시 그룹을 가질 수 있다.
Note
Pro tip
종속 애플리케이션 또는 서비스 VM을 컨시스턴시 그룹으로 그룹핑하여 일관성 있는 상태(e.g. App 및 DB)로 복구되도록 한다.
스냅샷 스케줄 (Snapshot Schedule)
- 주요 역할: 스냅샷 및 복제 스케줄
- 설명: 특정 PD 및 CG의 VM에 대한 스냅샷 및 복제 스케줄.
Note
Pro tip
스냅샷 스케줄은 원하는 RPO와 같아야 한다.
보존 정책 (Retention Policy)
- 주요 역할: 유지할 로컬 또는 원격 스냅샷 수
- 설명: 보존 정책은 보존할 로컬 및 원격 스냅샷 수를 정의한다. NOTE: 원격 보존/복제 정책을 설정하려면 원격 사이트를 먼저 설정해야 한다.
Note
Pro tip
보존 정책은 VM/파일 당 필요한 복구 지점 수와 같아야 한다.
원격 사이트 (Remote Site)
- 주요 역할: 원격 뉴타닉스 클러스터
- 설명: 백업 또는 DR 목적을 위해 타깃으로 활용될 수 있는 원격 뉴타닉스 클러스터.
Note
Pro tip
타깃 사이트에 전체 사이트 장애를 처리할 수 있는 충분한 용량(컴퓨트/스토리지)이 있는지 확인한다. 단일 사이트 내에서 랙 간 복제/DR도 의미가 있는 경우가 있다.
다음 그림은 단일 사이트에 대한 PD, CG 및 VM/파일 간의 관계를 논리적으로 나타낸 것이다.
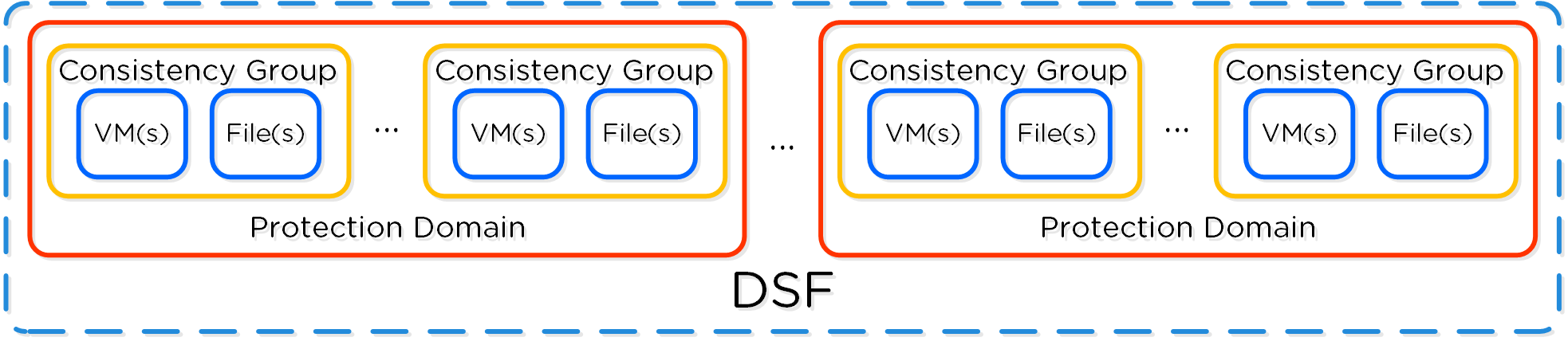 DR 컨스트럭트 매핑 (DR Construct Mapping)
DR 컨스트럭트 매핑 (DR Construct Mapping)
Note
정책 기반 DR 및 런 북 (Policy Based DR & Run Books)
정책 기반 DR 및 런 북은 VM 기반 DR(PD, CG 등)에 정의된 기능을 확장하고 작업을 정책 중심 모델로 추상화한다. 이를 통해 관심 항목(e.g. RPO, 보존 등)에 초점을 맞추고 정책을 VM에 직접 할당하는 대신 카테고리에 할당하여 설정을 단순화한다. 또한 모든 VM에 적용할 수 있는 "기본 정책(Default Policy)"을 허용한다.
NOTE: 이 정책은 프리즘 센트럴을 통해 설정한다.
보호 대상 엔티티
다음 워크플로우를 사용하여 엔터티(VM, VG, 파일)를 보호할 수 있다.
“Data Protection” 페이지에서 “+ Protection Domain > Async DR”을 선택한다.
 DR – 비동기 DR (DR - Async PD)
DR – 비동기 DR (DR - Async PD)
PD 이름을 입력하고 “Create”를 클릭한다.
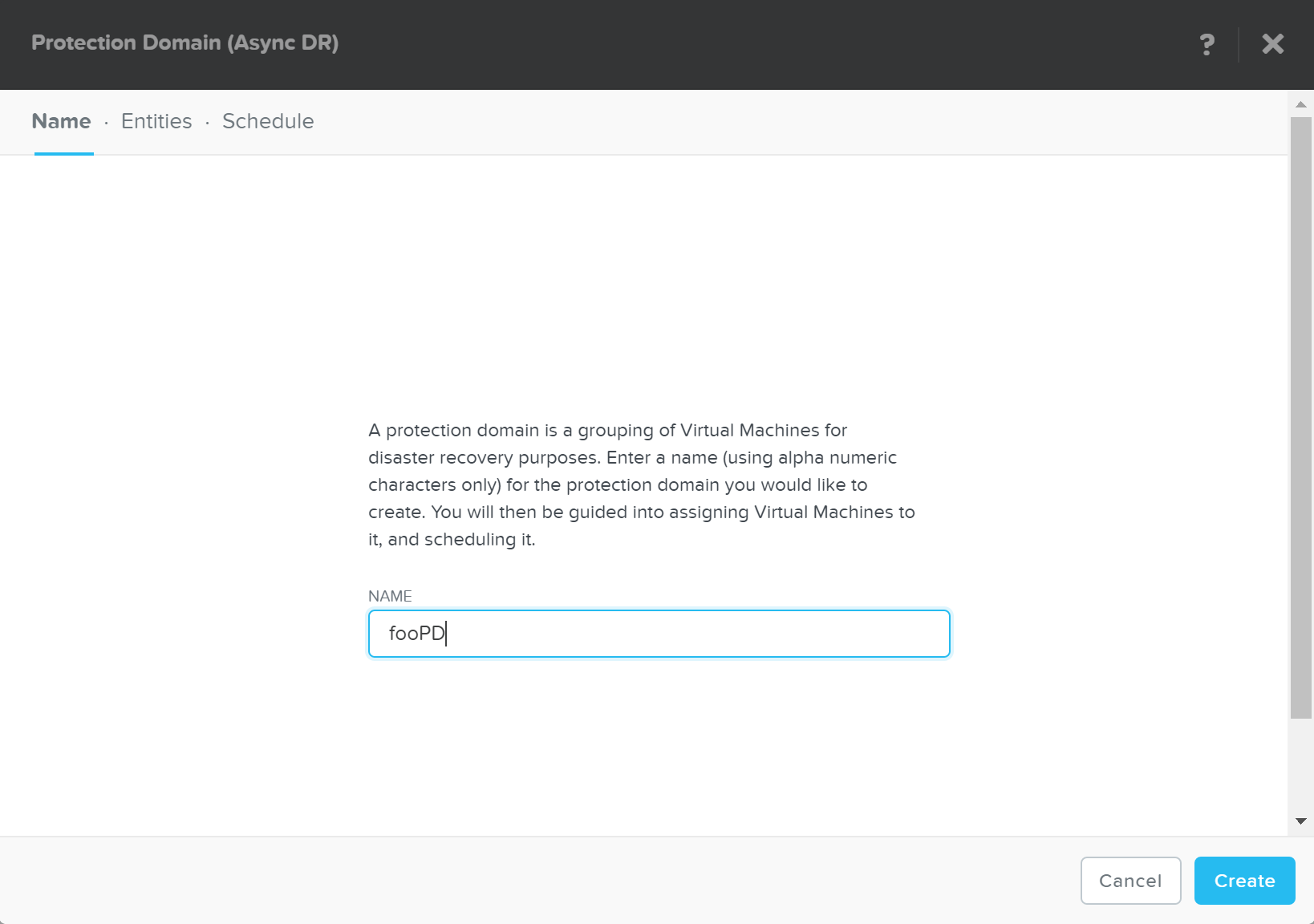 DR – PD 생성 (DR - Create PD)
DR – PD 생성 (DR - Create PD)
보호할 엔티티를 선택한다.
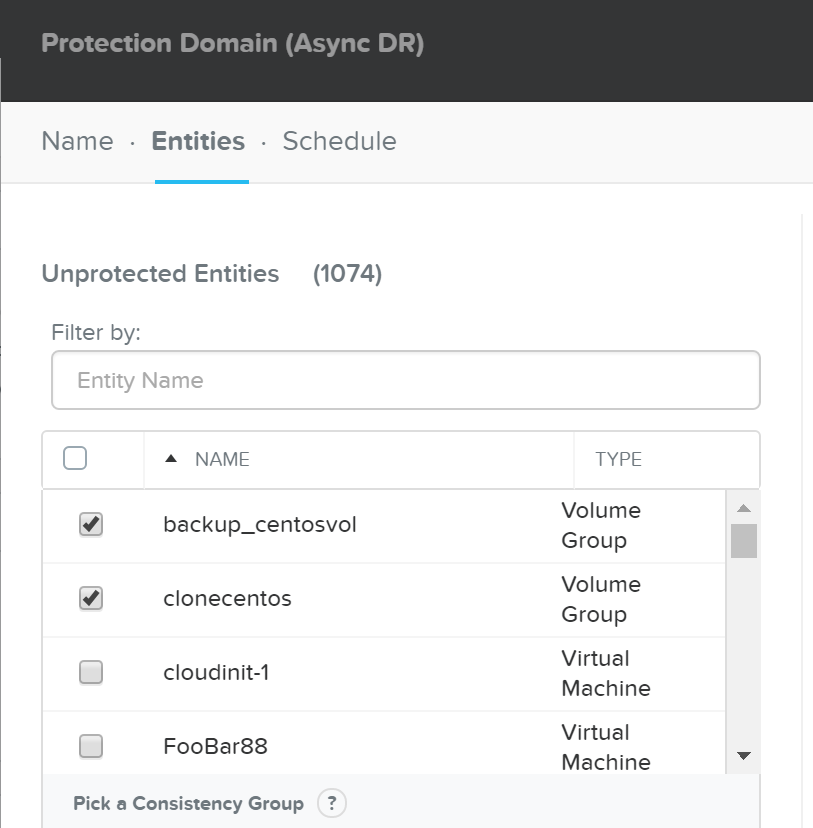 DR – 비동기 PD (DR - Async PD)
DR – 비동기 PD (DR - Async PD)
“Protect Selected Entities”를 클릭한다.
 DR – 엔티티 보호 (DR - Protect Entities)
DR – 엔티티 보호 (DR - Protect Entities)
이제 보호 엔티티가 “Protected Entities” 아래에 표시된다.
 DR – 보호될 엔티티 (DR - Protected Entities)
DR – 보호될 엔티티 (DR - Protected Entities)
“Next”를 클릭한 다음 “Next Schedule”를 클릭하여 스냅샷 및 복제 스케줄을 생성한다.
복제를 위한 원하는 스냅샷 주기, 보존 정책 및 원격 사이트를 입력한다.
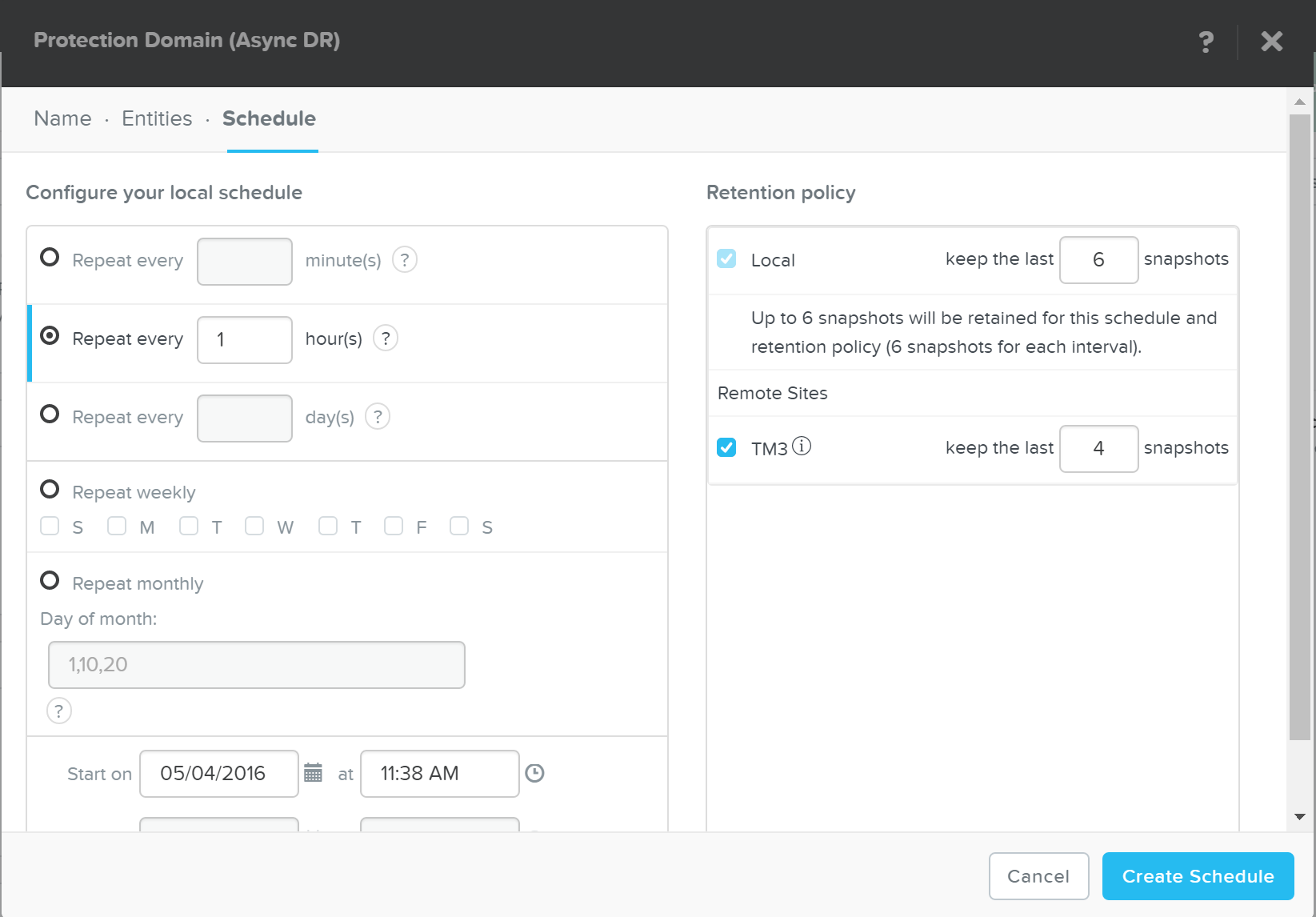 DR – 스케줄 생성 (DR - Create Schedule)
DR – 스케줄 생성 (DR - Create Schedule)
스케줄 작성을 완려하려면 “Create Schedule”을 클릭한다.
Note
다중 스케줄 (Multiple Schedules)
여러 개의 스냅샷 및 복제 스케줄을 생성하는 것이 가능하다. 예를 들어 시간 단위 로컬 백업 스케줄과 원격 사이트로 일 단위 복제 스케줄을 생성할 수 있다.
전체 컨테이너를 간단하게 보호할 수 있지만 플랫폼은 단일 VM 또는 파일 레벨의 세분화된 수준으로 보호할 수 있는 기능을 제공한다.
백업 및 복원
뉴타닉스 백업 기능은 네이티브 DSF 스냅샷 기능을 활용하며 세레브로에 의해 호출되고 스타게이트에 의해 수행된다. 이 스냅샷 기능은 효율적인 스토리지 활용 및 낮은 오버헤드를 보장하기 위해 제로 카피(Zero Copy)이다. 뉴타닉스 스냅샷에 대한 상세한 정보는 “스냅샷 및 클론” 섹션을 참조한다.
일반적인 백업 및 복원 오퍼레이션은 다음을 포함한다.
- 스냅샷 (Snapshot): 복원 지점 생성 및 복제(필요한 경우).
- 복원 (Restore): 이전 스냅샷에서 VM/파일 복원 (오리지널 오브젝트 대체).
- 클론 (Clone): 복원과 유사하지만 오리지널 오브젝트를 대체하지 않음 (원하는 스냅샷으로 새로운 오브젝트 생성).
“Data Protection” 페이지의 “Protecting Entities” 섹션에서 이전에 생성된 보호 도메인(PD)을 볼 수 있다.
 DR – PD 확인 (DR - View PDs)
DR – PD 확인 (DR - View PDs)
타킷 PD를 선택하면 다양한 옵션을 볼 수 있다.
 DR - PD 액션 (DR - PD Actions)
DR - PD 액션 (DR - PD Actions)
“Take Snapshot”을 클릭하면 선택한 PD의 임시 스냅샷을 찍고 필요한 경우 원격 사이트로 복제할 수 있다.
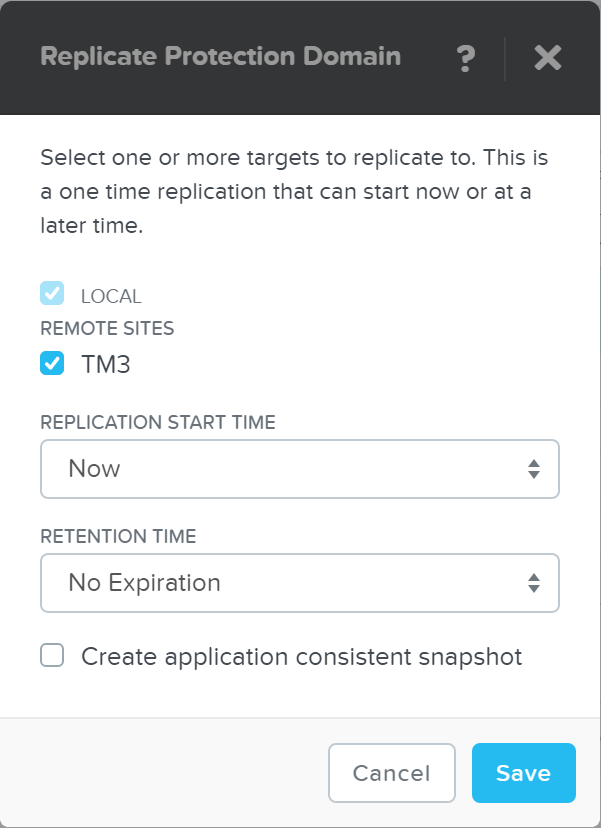 DR – 스냅샷 생성 (DR - Take Snapshot)
DR – 스냅샷 생성 (DR - Take Snapshot)
엔티티를 원격 사이트로 페일오버하도록 PD를 “Migrate” 할 수 있다.
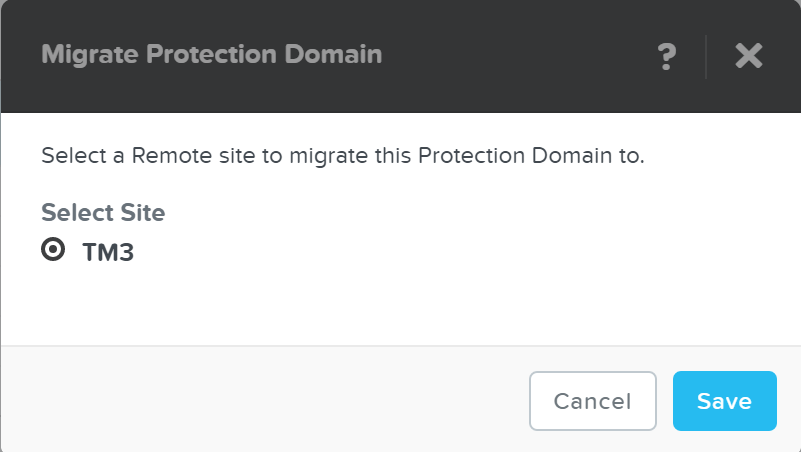 DR – 마이그레이트 (DR - Migrate)
DR – 마이그레이트 (DR - Migrate)
“Migrate”의 경우 (계획된 페일오버), 시스템은 새로운 스냅샷을 찍고 복제한 다음 새로 생성된 스냅샷으로 다른 사이트를 "Promote" 한다.
Note
Pro tip
AOS 5.0 이상에서 타깃 데이터 보호를 위해 단일 노드 복제를 활용할 수 있다.
또한 아래 표에서 PD 스냅샷을 볼 수 있다.
 DR – 로컬 스냅샷 (DR - Local Snapshots)
DR – 로컬 스냅샷 (DR - Local Snapshots)
여기서부터 PD 스냅샷을 복원하거나 클론할 수 있다.
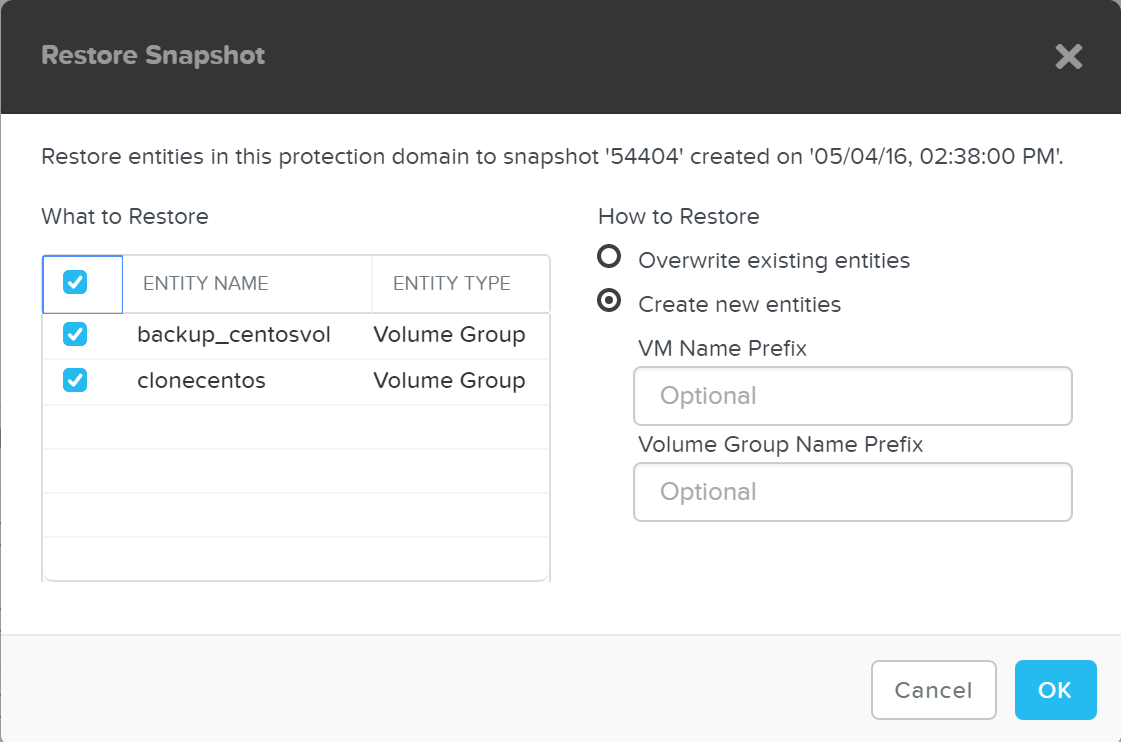 DR – 스냅샷 복원 (DR - Restore Snapshot)
DR – 스냅샷 복원 (DR - Restore Snapshot)
“Create new entities”를 선택하여 PD 스냅샷을 원하는 접두사를 갖는 새로운 엔티티로 클론할 수 있다. “Overwrite existing entities”를 선택하면 현재의 엔티티를 스냅샷 시점의 엔티티로 대체한다.
Note
스토리지 전용 백업 타깃 (Storage only backup target)
백업/아카이브 목적을 위해 백업 타깃 역할을 수행하는 스토리지 전용 클러스터를 원격 사이트로 설정할 수 있다. 이를 통해 데이터를 스토리지 전용 클러스터로/로부터 복제할 수 있다.
애플리케이션 컨시스턴트 스냅샷
뉴타닉스는 OS 및 애플리케이션의 오퍼레이션을 잠시 멈추게 하여 애플리케이션 컨시스턴트 스냅샷을 생성할 수 있는 네이티브 VSS(VmQuiesced Snapshot Service) 기능을 제공한다.
Note
VmQueisced Snapshot Service (VSS)
VSS는 일반적으로 Volume Shadow Copy Service에 대한 Windows 용어이다. 그러나, 이 솔루션은 Windows 및 Linux에 적용되므로 뉴타닉스는 용어를 VmQuiesced Snapshot Service로 수정한다.
지원 환경 (Supported Configurations)
이 솔루션은 Windows 및 Linux 게스트 모두에 적용할 수 있다. 지원되는 게스트 OS의 전체 목록은 호환성 및 상호 운용성 매트릭스에서 "NGT 호환성(NGT Compatibility)"을 참조한다: LINK
전제 조건 (Pre-Requisites)
뉴타닉스 VSS 스냅샷을 사용하려면 다음이 필요하다.
- 뉴타닉스 플랫폼
- 클러스터 가상 IP(Cluster Virtual IP)가 설정되어야 한다.
- 게스트 OS / UVM
- NGT가 설치되어 있어야 한다.
- CVM VIP가 2074 포트로 연결할 수 있어야 한다.
- DR 설정
- UVM이 “Use application consistent snapshots” 기능이 활성화된 PD에 있어야 한다.
백업 아키텍처 (Backup Architecture)
AOS 4.6 현재 이 기능은 뉴타닉스 게스트 툴 패키지의 일부로 설치된 네이티브 뉴타닉스 하드웨어 VSS 프로바이더를 사용하여 수행할 수 있다. 게스트 툴에 대한 자세한 정보는 “Nutanix Guest Tools” 섹션을 참조한다.
다음 이미지는 VSS 아키텍처의 하이-레벨 뷰를 보여준다.
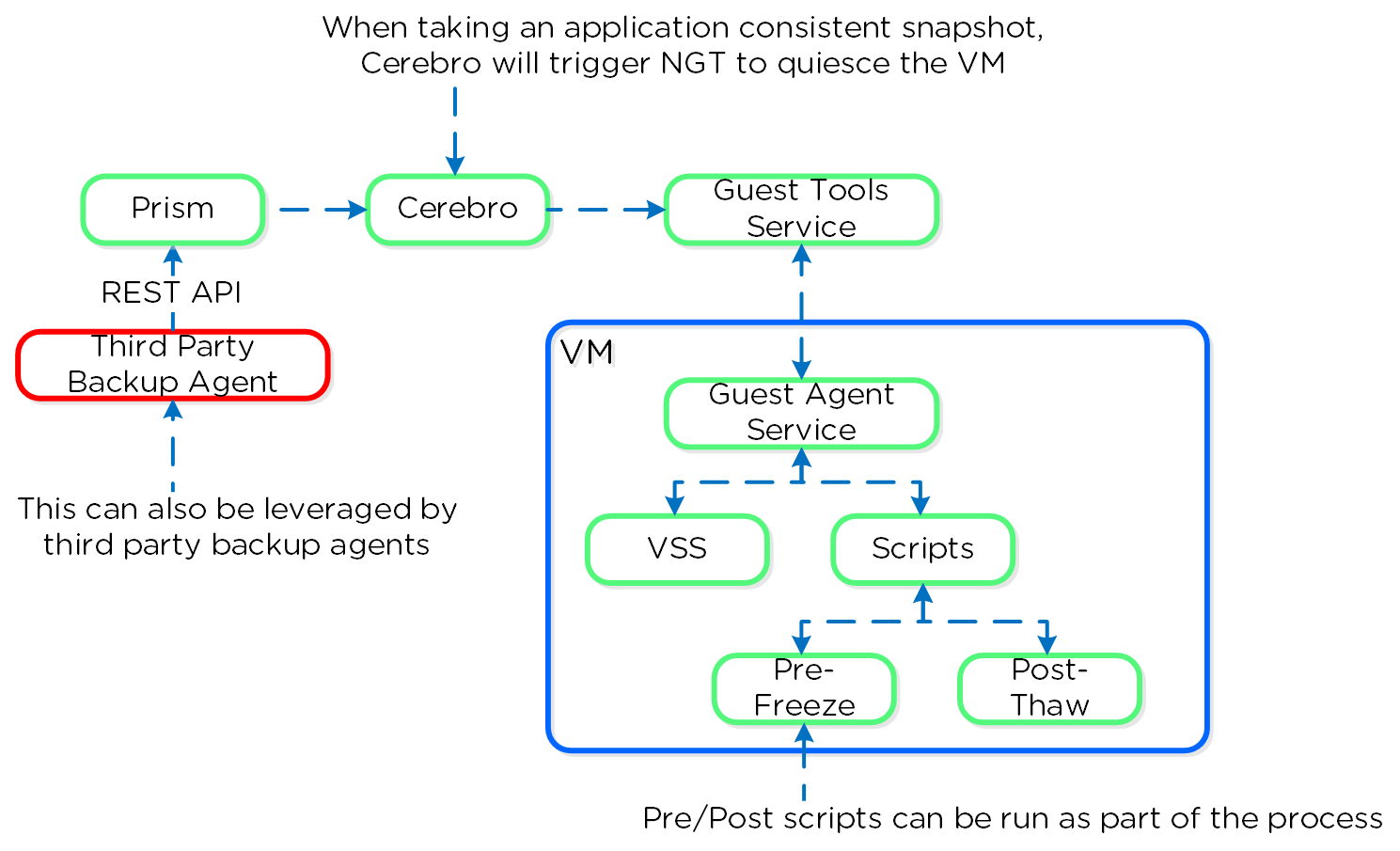
일반적인 데이터 보호 워크플로에 따라 VM을 보호할 때 “Use application consistent snapshots”을 선택하면 애플리케이션 컨시스턴트 스냅샷을 수행할 수 있다.
Note
뉴타닉스 VSS 활성화/비활성화 (Enabling/Disabling Nutanix VSS)
UVM에서 NGT를 활성화하면 뉴타닉스 VSS 기능이 기본적으로 활성화되지만 다음 명령으로 이 기능을 끌 수 있다.
ncli ngt disable-applications application-names=vss_snapshot vm_id=VM_ID
Windows VSS 아키텍처 (Windows VSS Architecture)
뉴타닉스 VSS 솔루션은 Windows VSS 프레임워크와 통합되어 있다. 다음은 아키텍처의 하이-레벨 뷰를 보여준다.
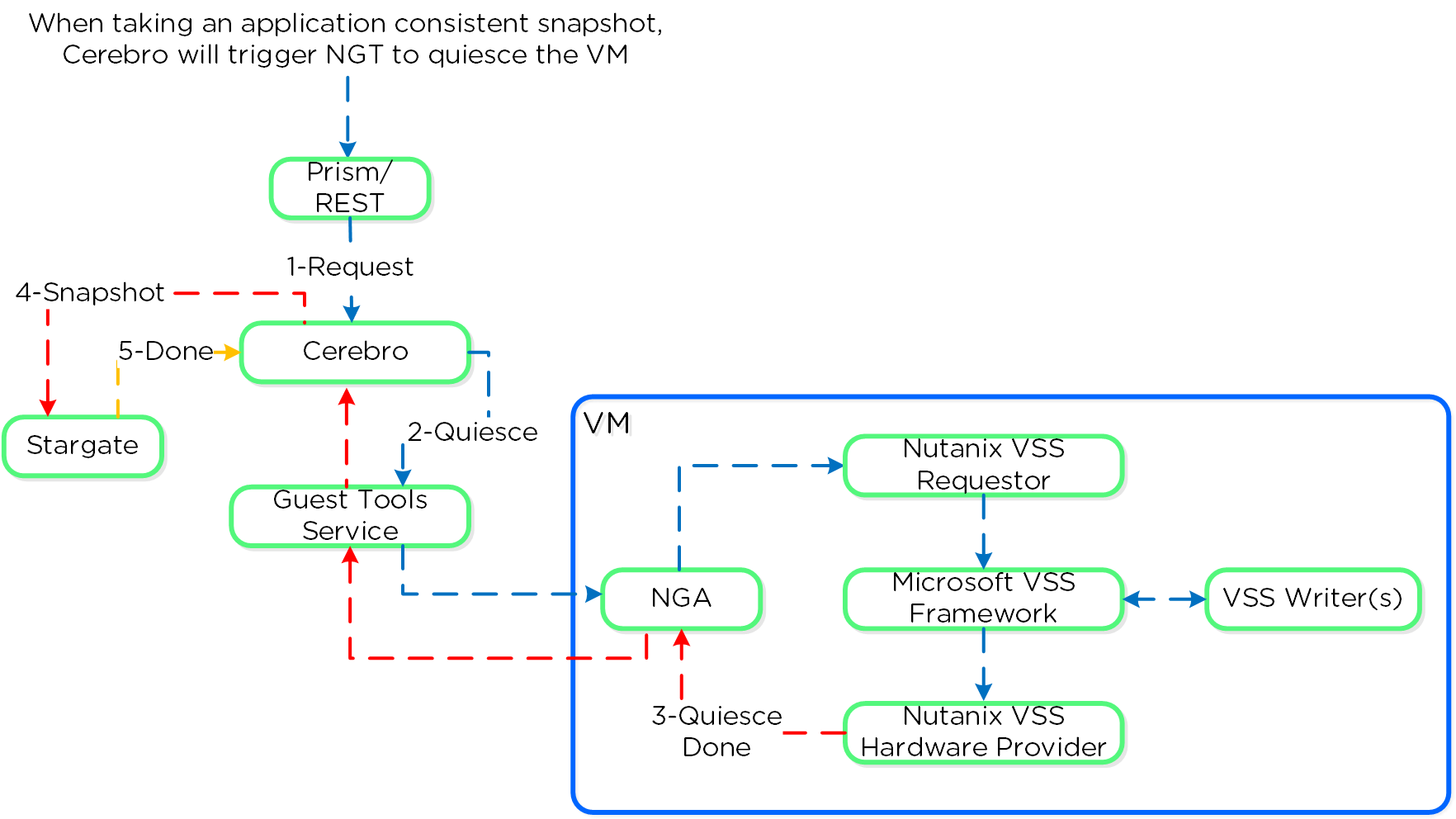 뉴타닉스 VSS – Windows 아키텍처 (Nutanix VSS - Windows Architecture)
뉴타닉스 VSS – Windows 아키텍처 (Nutanix VSS - Windows Architecture)
NGT가 설치되면 NGT 에이전트 및 VSS 하드웨어 프로바이더 서비스를 확인할 수 있다.
VSS 하드웨어 프로바이더 (VSS Hardware Provider)
Linux VSS 아키텍처 (Linux VSS Architecture)
Linux 솔루션은 Windows 솔루션과 유사하게 동작하지만 Linux 배포판에는 존재하지 않으므로 Windows VSS 프레임워크 대신 스크립트가 활용된다.
다음은 Linux VSS 아키텍처의 하이-레벨 뷰를 보여준다.
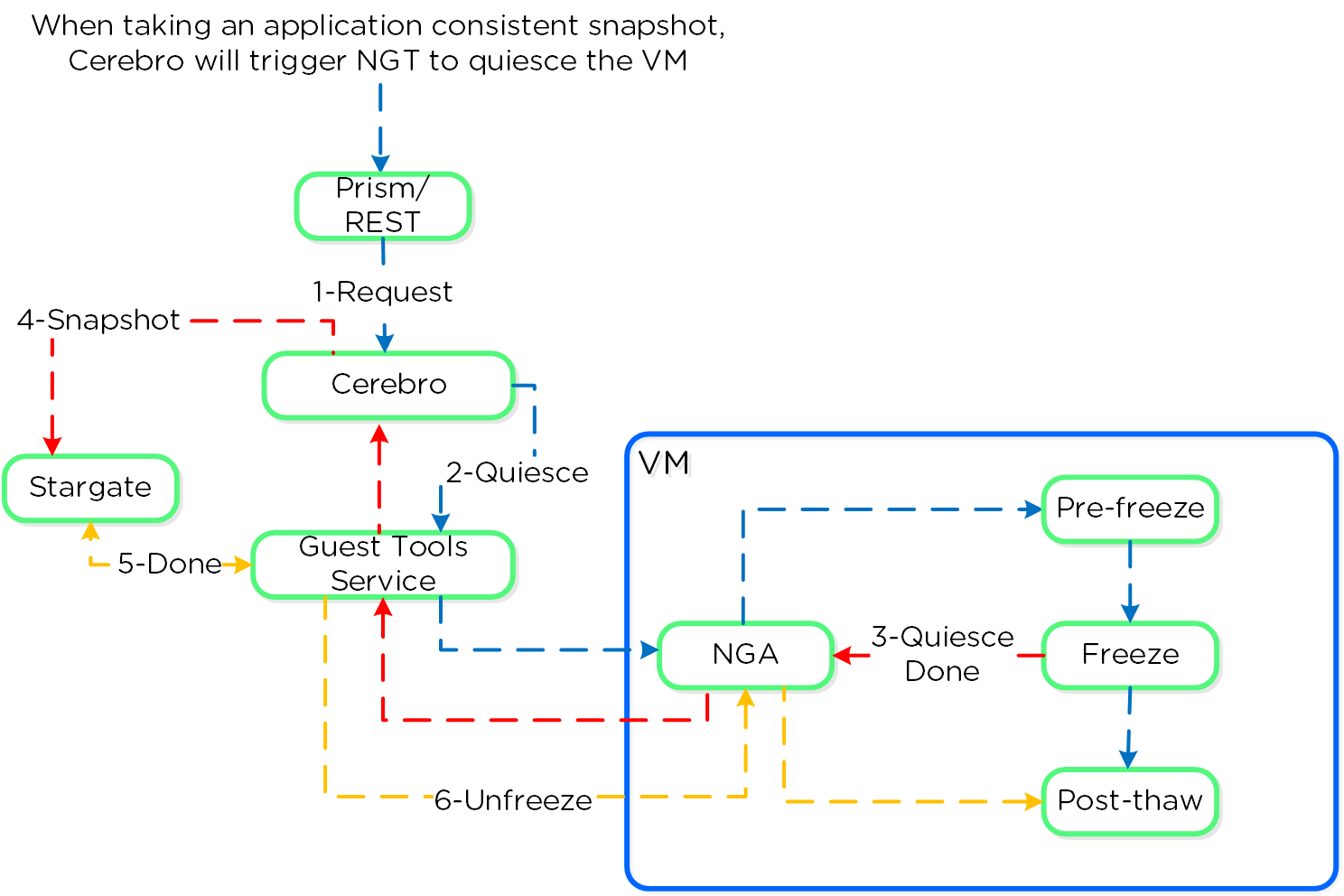 뉴타닉스 VSS – Linux 아키텍처 (Nutanix VSS - Linux Architecture)
뉴타닉스 VSS – Linux 아키텍처 (Nutanix VSS - Linux Architecture)
Pre-Freeze 및 Post-Thaw 스크립트는 다음 디렉토리에 있다.
- Pre-freeze: /sbin/pre_freeze
- Post-thaw: /sbin/post-thaw
Note
ESXi 잠시 멈춤 제거하기 (Eliminating ESXi Stun)
ESXi는 VMware Guest Tools를 사용하여 애플리케이션 컨시스턴트 스냅샷을 지원한다. 그러나, 이러한 프로세스 동안에, 델타 디스크가 생성되고, ESXi는 가상 디스크를 새로운 쓰기 IO를 처리할 새로운 델타 파일로 다시 매핑하기 위해 VM을 “잠시 멈춤(Stuns)” 시킨다. 잠시 멈춤은 VMware 스냅샷이 삭제될 경우에도 발생한다.
이러한 잠시 멈춤 프로세스 동안에 VM의 게스트 OS는 어떠한 종류의 오퍼레이션도 실행시키지 않기 때문에, 결국 멈춤 상태(Stuck state)에 있게 된다(e.g., PING 실패, IO 없음). 잠시 멈춤 시간은 vmdk의 개수와 데이터스토어 메타데이터 오퍼레이션(e.g., 새로운 델타 디스크 생성 등)의 작업 속도에 따라 달리진다.
뉴타닉스 VSS를 사용하면 VMware 스냅샷/잠시 멈춤(Snapshot/Stun) 프로세스를 바이패스 하기 때문에 성능 또는 VM/OS 가용성에 거의 양향을 미치지 않는다.
복제 및 재해복구 (DR)
동영상 시청을 원하시면 다음 링크를 클릭하세요: LINK
뉴타닉스는 "스냅샷 및 클론" 섹션에 설명된 것과 동일한 기능을 기반으로 하는 네이티브 DR 및 복제 기능을 제공한다. 세레브로는 DSF에서 DR 및 복제 관리를 담당하는 컴포넌트이다. 세레브로는 모든 노드에서 실행되며 세레브로 리더(NFS 리더와 유사)가 선출되고 복제 태스크의 관리를 담당한다. 세레브로 리더 역할을 하는 CVM에 장애가 발생하면 다른 CVM이 리더로 선출되어 역할을 맡는다. 세레브로 페이지는 <CVM IP>:2020에서 찾을 수 있다. DR 기능은 다음과 같은 몇 가지 핵심 중점 영역으로 나눌 수 있다.
- 복제 토폴로지
- 복제 생애 주기
- 글로벌 중복제거
복제 토폴로지 (Replication Topologies)
전통적으로 몇 가지 주요 토폴로지가 있다: Site to Site, Hub and Spoke, Full and/or Partial Mesh. Site to Site, Hub and Spoke 토폴로지만을 허용하는 기존 솔루션과 달리 뉴타닉스는 Full Mesh 또는 유연한 Many-to-Many 모델을 제공한다.
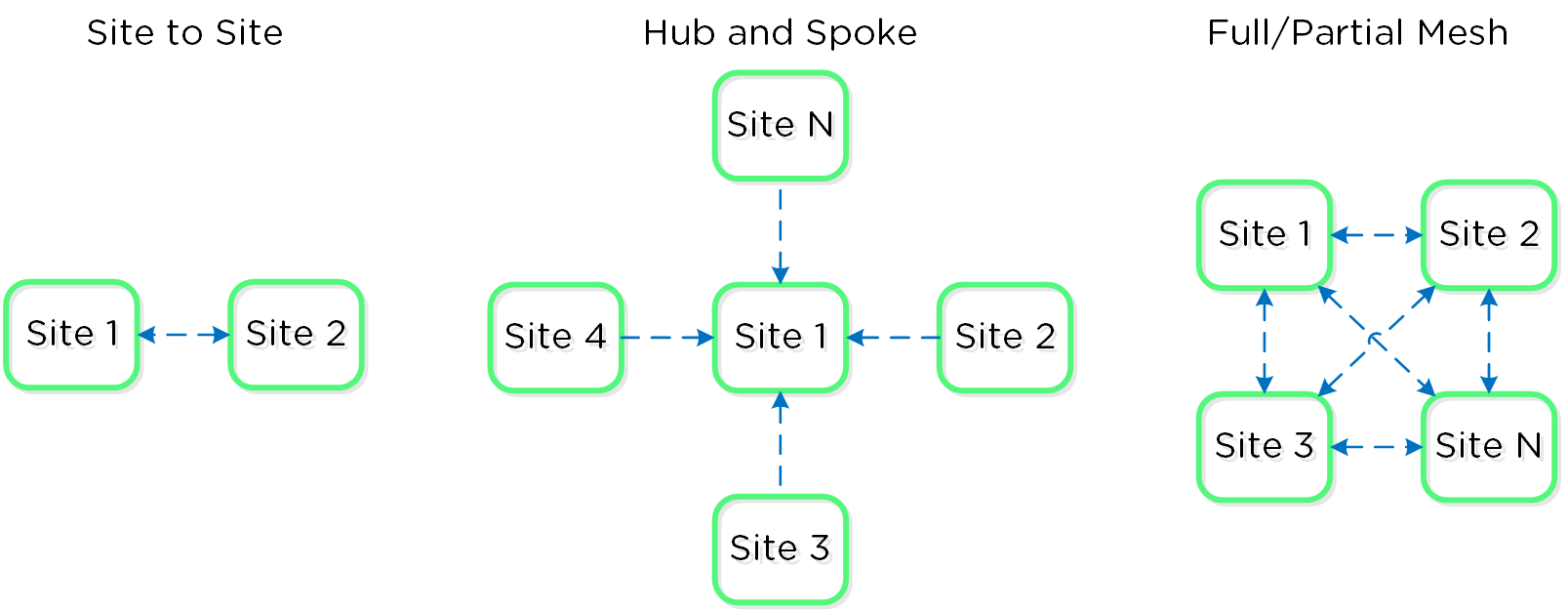 복제 토폴로지 예제 (Example Replication Topologies)
복제 토폴로지 예제 (Example Replication Topologies)
기본적으로 관리자는 회사의 요구 사항을 충족하는 복제 기능을 결정할 수 있다.
복제 생애 주기 (Replication Lifecycle)
뉴타닉스 복제는 위에서 언급한 세레브로 서비스를 활용한다. 세레브로 서비스는 동적으로 선출된 CVM인 "세레브로 리더"와 모든 CVM에서 실행되는 세레브로 워커로 나뉜다. "세레브로 리더" 역할을 하는 CVM에 장애가 발생할 경우 새로운 "리더"가 선출된다.
세레브로 리더는 로컬 세레브로 워커에 대한 태스크 위임을 관리하고 원격 복제가 발생할 때 원격 세레브로 리더와의 코디네이션을 담당한다.
복제하는 동안 세레브로 리더는 어떤 데이터를 복제해야 하는지 파악하고 복제 태스크를 스타게이트에게 복제할 데이터와 위치를 알려주는 세레브로 워커에게 위임한다.
복제된 데이터는 프로세스 전체에 걸쳐 여러 계층에서 보호된다. 소스에서 읽은 익스텐트는 소스 데이터의 일관성을 보장하기 위해 체크섬이 계산되고 (DSF 읽기가 발생하는 방식과 유사), 새 익스텐트는 타킷에서 체크섬이 계산된다 (DSF 쓰기와 유사). TCP는 네트워크 계층에서 일관성을 제공한다.
다음 그림은 이 아키텍처를 나타낸다.
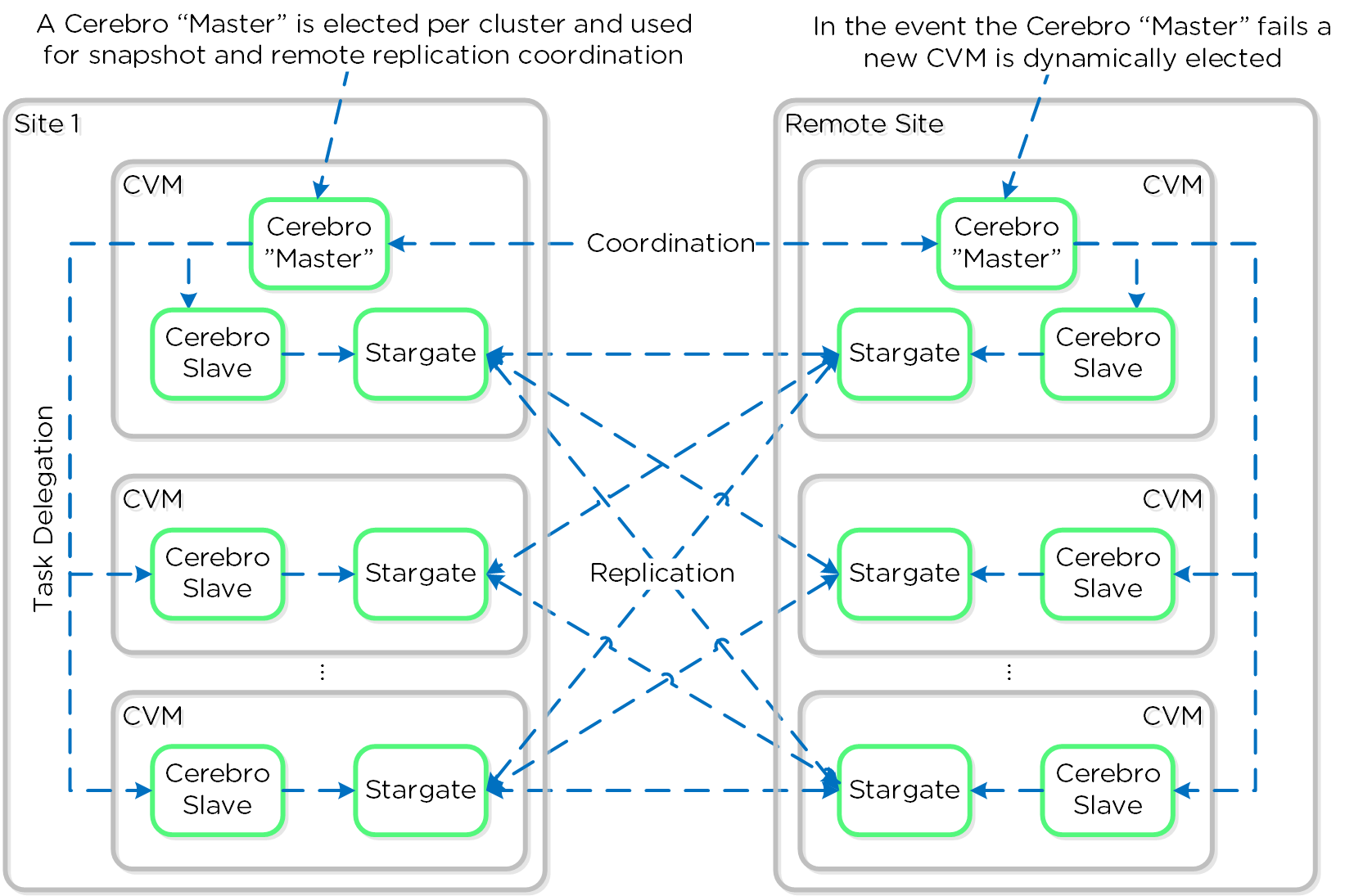 복제 아키텍처 (Replication Architecture)
복제 아키텍처 (Replication Architecture)
클러스터에서 들어오는 모든 코디네이션 및 복제 트래픽의 브리지헤드로 사용될 프록시를 사용하여 원격 사이트를 구성할 수도 있다.
Note
Pro tip
프록시로 구성된 원격 사이트를 사용하는 경우 CVM이 다운되더라도 항상 프리즘 리더가 호스팅하고 사용할 수 있는 클러스터 가상 IP를 사용한다.
다음 그림은 프록시를 사용하는 복제 아키텍처를 나타낸다.
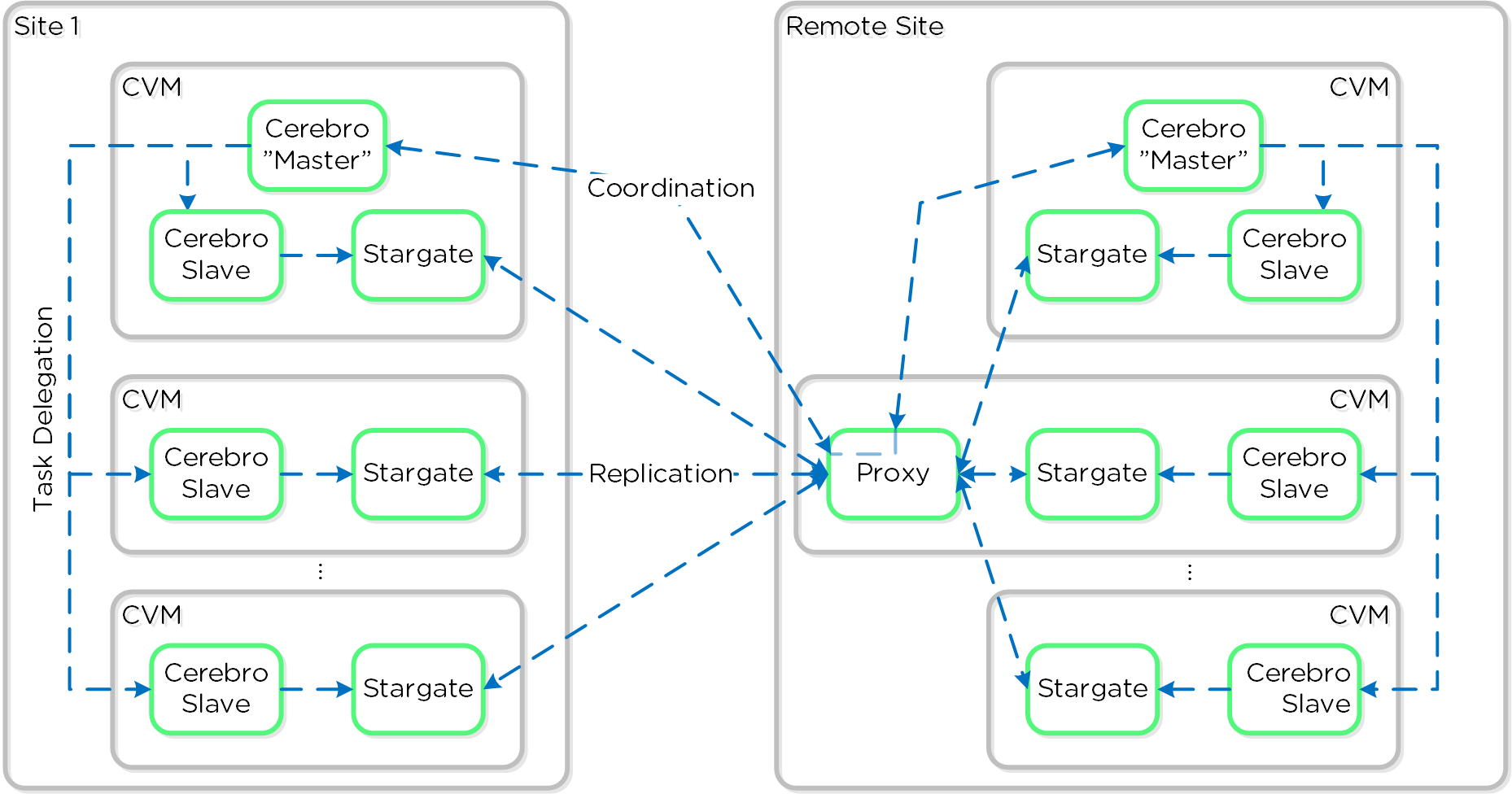 복제 아키텍처 – 프록시 (Replication Architecture - Proxy
복제 아키텍처 – 프록시 (Replication Architecture - Proxy
특정 시나리오에서 모든 트래픽이 두 CVM 간에 흐를 SSH 터널을 사용하여 원격 사이트를 구성할 수도 있다.
Note
Note
프로덕션 이외의 시나리오에서만 사용해야 하며 가용성을 보장하기 위해 클러스터 가상 IP를 사용해야 한다.
다음 그림은 SSH 터널을 사용하는 복제 아키텍처를 나타낸다.
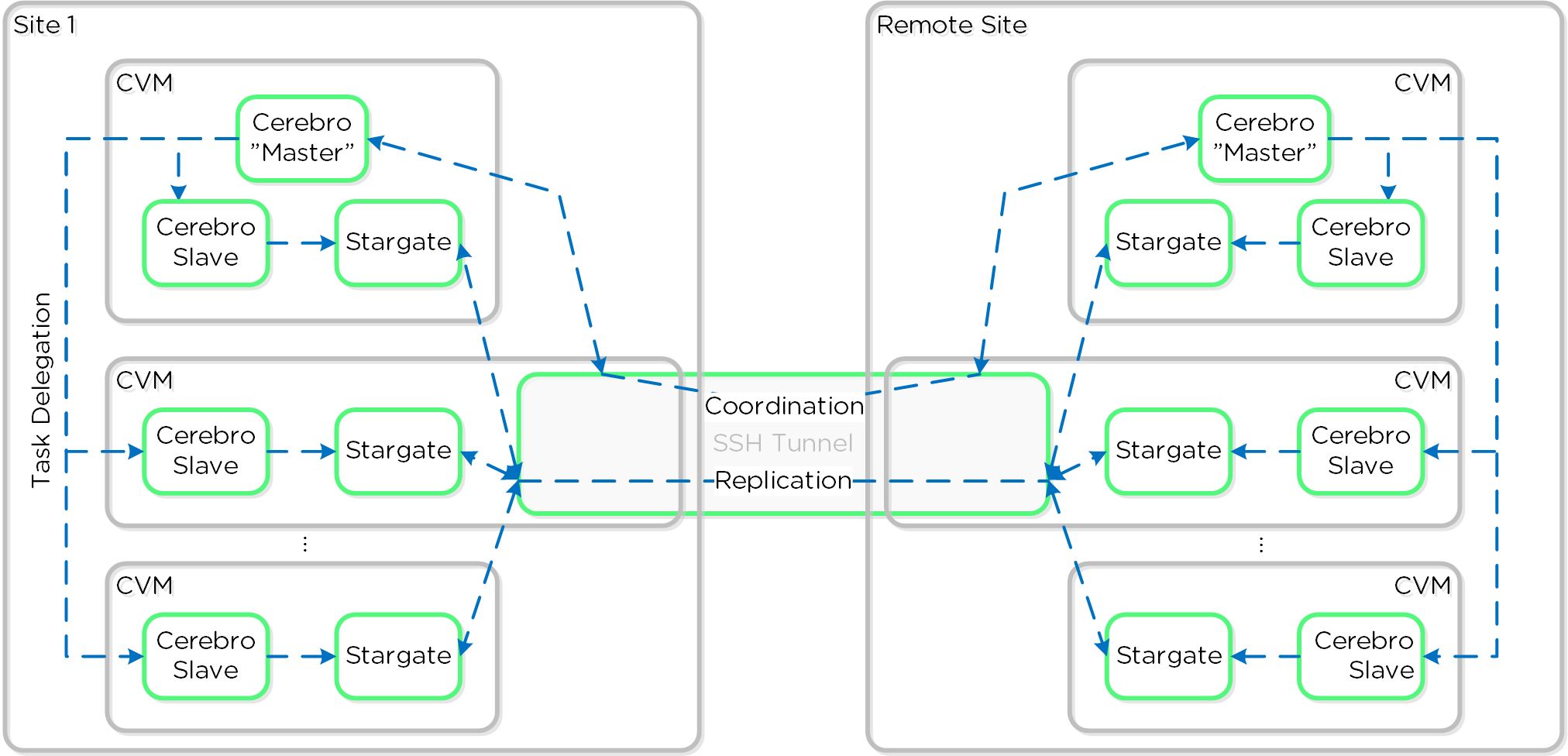 복제 아키텍처 – SSH 터널 (Replication Architecture - SSH Tunnel)
복제 아키텍처 – SSH 터널 (Replication Architecture - SSH Tunnel)
글로벌 중복제거 (Global Deduplication)
"탄력적인 중복제거 엔진" 섹션에서 설명한 것처럼 DSF는 메타데이터 포인터만 업데이트하여 데이터를 중복제거할 수 있다. DR 및 복제 기능에도 동일한 개념이 적용된다. 유선을 통해 데이터를 전송하기 전에 DSF는 원격 사이트에 쿼리하여 타깃에 이미 지문이 있는지(데이터가 이미 존재함) 여부를 확인한다. 그렇다면 유선으로 데이터가 전송되지 않으며 메타데이터 업데이트만 발생한다. 타깃에 존재하지 않는 데이터의 경우 데이터가 압축되어 타깃 사이트로 전송된다. 이 시점에서 두 사이트에 존재하는 데이터를 중복제거에 사용할 수 있다.
다음 그림은 각 사이트에 하나 이상의 보호 도메인(PD)이 포함된 세 사이트 배포의 예를 보여준다.
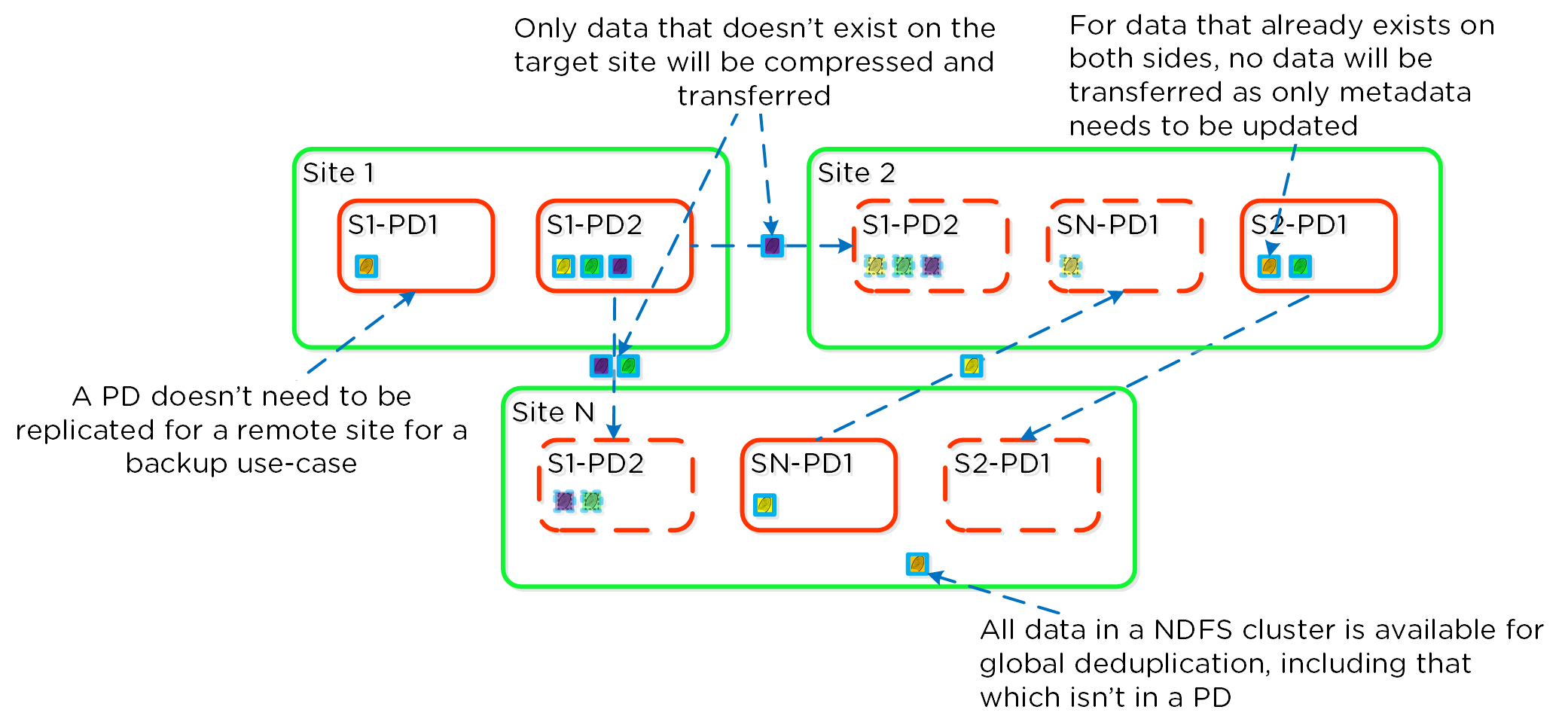 복제 중복제거 (Replication Deduplication)
복제 중복제거 (Replication Deduplication)
Note
Note
복제 중복 제거를 수행하려면 소스 및 타깃 컨테이너/vstore에서 지문(Fingerprinting)을 활성화해야 한다.
NearSync
앞에서 언급한 기존의 비동기(Async) 복제 기능을 기반으로 뉴타닉스는 니어 동기 복제(NearSync) 기능을 지원한다.
NearSync는 두 가지 장점을 모두 제공한다: 매우 낮은 RPO(동기 복제(Metro)와 같은) 외에 기본 I/O 레이턴시(비동기 복제와 같은)에 전혀 영향을 미치지 않음. 이를 통해 사용자는 쓰기를 위해 동기 복제가 요구하는 오버헤드 없이 매우 낮은 RPO를 구현할 수 있다.
이 기능은 LWS(Light-Weight Snapshot)라는 새로운 스냅샷 기술을 사용한다. 비동기에서 사용하는 기존 vDisk 기반 스냅샷과 달리 이것은 마커를 활용하고 완전히 OpLog 기반이다 (vDisk 스냅샷은 익스텐트 스토어에서 수행된다).
메소스(Mesos)는 스냅샷 계층을 관리하고 전체/증분 스냅샷의 복잡성을 추상화하기 위해 추가된 새로운 서비스이다. 세레브로는 상위 수준의 구성 및 정책(예: 일관성 그룹 등)을 계속 관리하며 메소스는 스타게이트와 상호 작용하고 LWS 수명주기를 제어한다.
다음 그림은 NearSync 컴포넌트 간의 통신 예를 보여 준다.
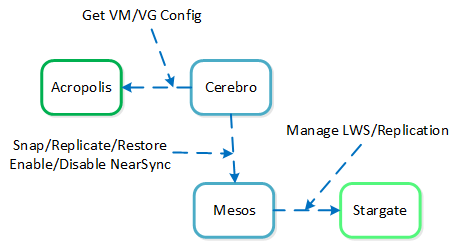 NearSync 컴포넌트 상호작용 (NearSync Component Interaction)
NearSync 컴포넌트 상호작용 (NearSync Component Interaction)
사용자가 스냅샷 주기를 15분 이하로 설정하면 NearSync가 자동적으로 활용된다. 이 시점에서 초기 시드 스냅샷이 생성된 다음 원격 사이트로 복제된다. 이 작업이 60분 안에 완료되면(첫 번째 또는 n 이후일 수 있음) LWS 스냅 샷 복제 시작 외에 다른 시드 스냅샷이 즉시 생성되어 복제된다. 두 번째 시드 스냅샷이 복제를 마치면 이미 복제된 모든 LWS 스냅샷이 유효해지고 시스템은 안정적인 NearSync 상태가 된다.
다음 그림은 NearSync 활성화부터 실행까지의 타임라인 예제이다.
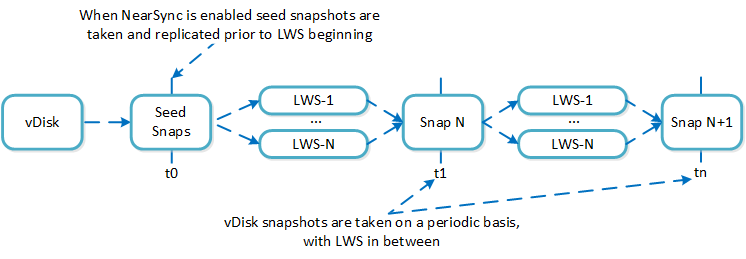 NearSync 복제 생애주기 (NearSync Replication Lifecycle)
NearSync 복제 생애주기 (NearSync Replication Lifecycle)
안정적인 실행 상태 동안 vDisk 스냅샷은 매시간마다 생성된다. 원격 사이트는 LWS 외에 원격 사이트로 스냅샷을 전송하는 대신 이전 vDisk 스냅샷과 해당 시점의 LWS를 기반으로 vDisk 스냅샷을 구성한다.
NearSync가 동기화되지 않아(e.g. 네트워크 단절, WAN 레이턴시 증가 등) LWS 복제가 60분 이상 걸리는 경우 시스템은 자동으로 vDisk 기반 스냅샷으로 다시 전환된다. 이 중 하나가 60분 이내에 완료되면 시스템은 즉시 다른 스냅샷을 생성하고 LWS 복제를 시작한다. 전체 스냅샷이 완료되면 LWS 스냅샷이 유효해지고 시스템은 안정적인 NearSync 상태가 된다. 이 프로세스는 NearSync의 초기 활성화와 유사하다.
LWS 기반 스냅샷이 복원(또는 클론)되면 시스템은 최신 vDisk 스냅샷을 클론하여 원하는 LWS에 도달할 때까지 LWS를 점진적으로 적용한다.
다음 그림은 LWS 기반 스냅샷이 복원되는 방법의 예를 보여준다.
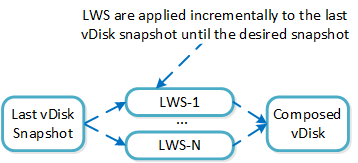 LWS로부터 vDisk 복원 (vDisk Restore from LWS)
LWS로부터 vDisk 복원 (vDisk Restore from LWS)
메트로 가용성
뉴타닉스는 컴퓨트 및 스토리지 클러스터가 여러 물리적 사이트에 걸쳐 구성할 수 있는 네이티브 “스트레치 클러스터링(Stretch Clustering)" 기능을 제공한다. 이러한 배포에서 컴퓨트 클러스터는 두 위치에 걸쳐 있으며 공유 스토리지 풀에 액세스할 수 있다.
이를 통해 VM HA 도메인이 단일 사이트에서 두 사이트 간으로 확장되어 near 0 RTO와 0 RPO를 제공한다.
이러한 배포에서 각 사이트는 자체 뉴타닉스 클러스터를 가지지만 쓰기를 승인하기 전에 원격 사이트에 동기적으로 복제하여 컨테이너기 “확장(Stretched)”된다.
다음 그림은 이 아키텍처에 대한 하이-레벨 디자인을 보여준다.
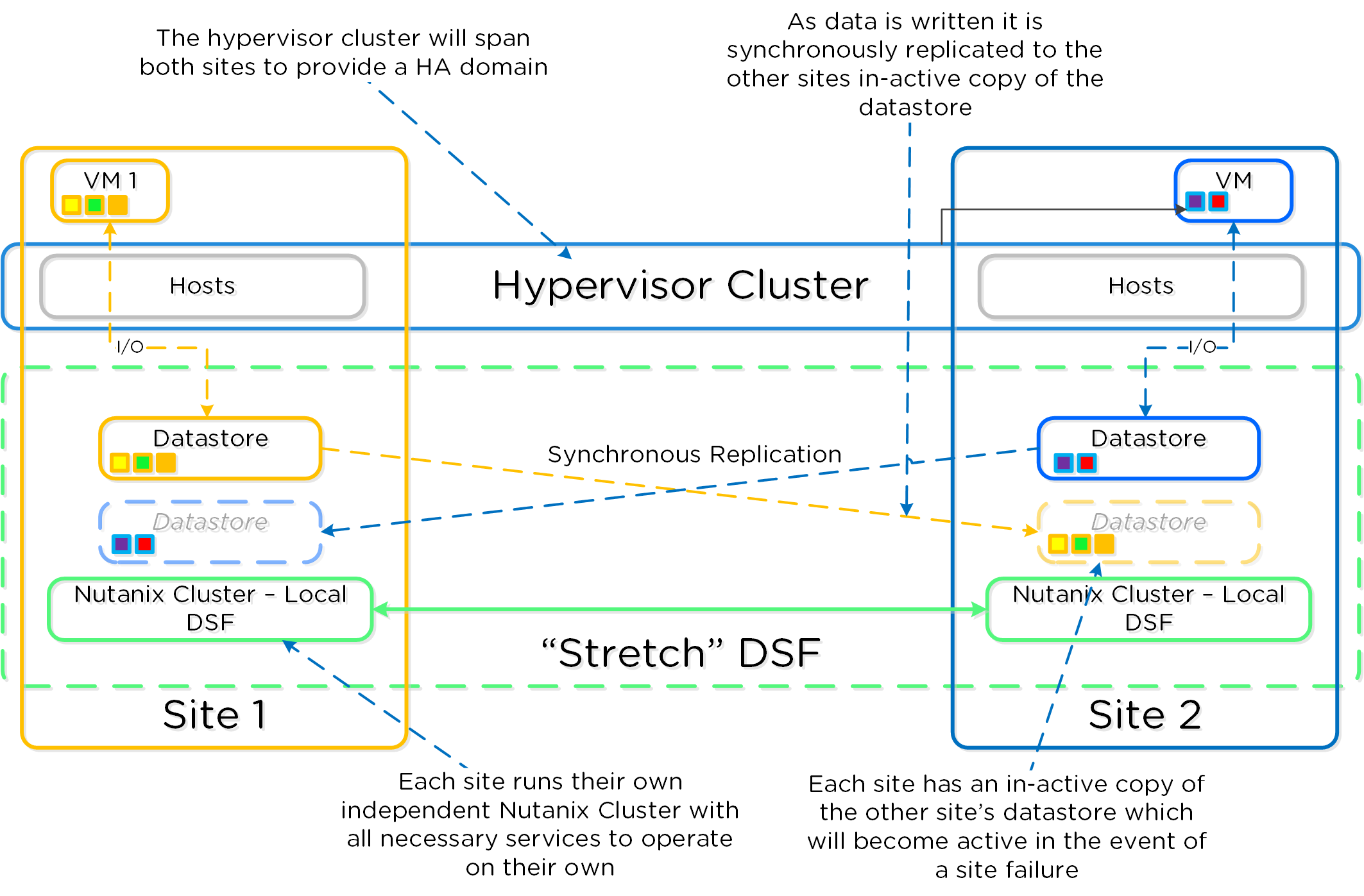 메트로 가용성 – 정상 상태 (Metro Availability - Normal State)
메트로 가용성 – 정상 상태 (Metro Availability - Normal State)
사이트 장애가 발생하면 다른 사이트에서 VM을 재시작할 수 있는 HA 이벤트가 발생한다. 페일오버 프로세스는 일반적으로 수동 프로세스이다. AOS 5.0 릴리스에서는 페일오버를 자동화할 수 있는 메트로 위트니스(Metro Witness)를 구성할 수 있다. Witness VM은 포탈을 통해 다운로드할 수 있으며 프리즘에서 설정할 수 있다.
다음 그림은 사이트 장애의 예를 보여준다.
 메트로 가용성 – 사이트 장애 (Metro Availability - Site Failure)
메트로 가용성 – 사이트 장애 (Metro Availability - Site Failure)
두 사이트 간에 링크 장애가 있는 경우 각 클러스터는 독립적으로 동작한다. 링크가 다시 시작되면 사이트가 재동기화되고(델타 부분만) 동기식 복제가 시작된다.
다음 그림은 링크 장애의 예이다.
 메트로 가용성 – 링크 장애 (Metro Availability - Link Failure)
메트로 가용성 – 링크 장애 (Metro Availability - Link Failure)
AOS 관리
중요 페이지
이것들은 자세한 통계 및 메트릭스를 모니터링할 수 있는 표준 사용자 인터페이스 외에 고급 뉴티닉스 페이지이다. URL은 http://<뉴타닉스 CVM IP/DNS>:<포트/경로>와 같은 방식으로 형식이 지정된다. 예를 들어 “http://MyCVM-A:2009”와 같다. NOTE: 다른 서브넷에 있는 경우 페이지에 액세스하려면 CVM에서 iptables를 비활성화해야 한다.
2009 페이지
백엔드 스토리지 시스템을 모니터링하는 데 사용되는 스타케이트 페이지로 고급 사용자만 사용해야 한다. 2009 페이지와 살펴볼 내용을 설명하는 블로그가 있다.
2009/latency 페이지
백엔드 레이턴시를 모니터링하는 데 사용되는 스타게이트 페이지이다.
2009/vdisk_stats 페이지
이 페이지는 I/O 크기의 히스토그램, 레이턴시, 쓰기 히트(e.g. OpLog, eStore), 읽기 히트(캐시, SSD, HDD 등)를 포함한 다양한 vDisk 통계를 표시하는 데 사용되는 스타게이트 페이지이다.
2009/h/traces 페이지
오퍼레이션에 대한 액티비티 추적을 모니터링하는 데 사용되는 스타게이트 페이지이다.
2009/h/vars 페이지
다양한 카운터를 모니터링하는 데 사용되는 스타게이트 페이지이다.
2010 페이지
큐레이터 실행을 모니터링하는 데 사용되는 큐레이터 페이지이다.
2010/master/control 페이지
큐레이터 잡(Job)을 수동으로 시작하는 데 사용되는 큐레이터 컨트롤 페이지이다.
2011 페이지
큐레이터에 의해 스케줄링된 잡(Job) 및 태스크(Task)를 모니터링하는 크로노스 페이지이다.
2020 페이지
보호 도메인, 복제 상태 및 DR을 모니터링하는 세레브로 페이지이다.
2020/h/traces 페이지
PD 오퍼레이션 및 복제에 대한 액티비티 추적을 모니터링하는 데 사용되는 세레브로 페이지이다.
2030 페이지
메인 아크로폴리스 페이지로 환경 호스트, 현재 실행 중인 모든 태스크 및 네트워킹 등과 관련된 상세 정보를 보여준다.
2030/sched 페이지
이 페이지는 배치 결정에 사용되는 VM 및 자원 예약에 대한 정보를 표시하는 데 사용되는 아크로폴리스 페이지이다. 이 페이지는 사용 가능한 호스트 자원 및 각 호스트에서 실행되는 VM을 보여준다.
2030/tasks 페이지
이 페이지는 아크로폴리스 태스크 및 해당 상태에 대한 정보를 표시하는 데 사용되는 아크로폴리스 페이지이다. 태스크 UUID를 클릭하면 태스크에 대한 자세한 JSON을 얻을 수 있다.
2030/vms 페이지
이 페이지는 아크로폴리스 VM 정보 및 각 VM에 대한 세부 정보를 표시하는 데 사용되는 아크로폴리스 페이지이다. VM 이름을 클릭하여 콘솔에 연결할 수 있다.
클러스터 명령
클러스터 상태 체크 (Check cluster status)
설명: CLI로 클러스터 상태 체크
cluster status
로컬 CVM 서비스 상태 체크 (Check local CVM service status)
설명: CLI로 단일 CVM의 서비스 상태 체크
genesis status
업그레이드 상태 체크 (Check upgrade status)
upgrade_status
수동/CLI 업그레이드 수행 (Perform manual / cli upgrade)
download NUTANIXINSTALLERPACKAGE.tar.gz into ~/tmp
tar xzf NUTANIXINSTALLERPACKAGE.tar.gz
cd ~/tmp
./install/bin/cluster -i ./install upgrade
노드 업그레이드 (Node(s) upgrade)
하이퍼바이저 업그레이드 상태 (Hypervisor upgrade status)
설명: 임의의 CVM에서 CLI로 하이퍼바이저 업그레이드 상태 체크
host_upgrade_status
자세한 로그 (모든 CVM에서)
~/data/logs/host_upgrade.out
CLI로 클러스터 서비스 재시작 (Restart cluster service from CLI)
설명: CLI로 단일 클러스터 서비스 재시작
서비스 중지
cluster stop ServiceName
중지된 서비스 시작
cluster start #NOTE: This will start all stopped services
CLI로 클러스터 서비스 시작 (Start cluster service from CLI)
설명: CLI로 중지된 클러스터 서비스 시작
중지된 서비스 시작
cluster start #NOTE: This will start all stopped services
OR
단일 서비스 시작
Start single service: cluster start ServiceName
CLI로 로컬 서비스 재시작 (Restart local service from CLI)
설명: CLI로 단일 클러스터 서비스 재시작
서비스 중지
genesis stop ServiceName
서비스 시작
cluster start
CLI로 로컬 서비스 시작 (Start local service from CLI)
설명: CLI로 중지된 클러스터 서비스 시작
cluster start #NOTE: 모든 중지된 서비스가 시작됨
cmdline으로 클러스터 노드 추가 (Cluster add node from cmdline)
설명: CLI로 클러스터 노드 추가 수행
ncli cluster discover-nodes | egrep “Uuid” | awk ‘{print $4}’ | xargs -I UUID ncli cluster add-node node-uuid=<UUID>
클러스터 ID 찾기 (Find cluster id)
설명: 현재 클러스터의 클러스터 ID 찾기
zeus_config_printer | grep cluster_id
포트 열기 (Open port)
설명: IPtables로 포트 활성화
sudo vi /etc/sysconfig/iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport PORT -j ACCEPT sudo service iptables restart
쉐도우 클론 체크 (Check for Shadow Clones)
설명: “name#id@svm_id” 형식으로 쉐도우 클론 출력
vdisk_config_printer | grep '#'
레이턴시 페이지 통계 리셋 (Reset Latency Page Stats)
설명: 레이턴시 페이지(CVM IP:2009/latency) 카운터 리셋
allssh "wget 127.0.0.1:2009/latency/reset"
vDisk 정보 찾기 (Find vDisk information)
설명: 이름, ID, 크기, IQN 및 기타를 포함한 vDisk 정보 및 상세 정보 찾기
vdisk_config_printer
vDisk 개수 찾기 (Find Number of vDisks)
설명: DSF에서 현재 vDisk (Files) 개수 찾기
vdisk_config_printer | grep vdisk_id | wc -l
vDisk 상세 정보 가져오기 (Get detailed vDisk information)
설명: 제공된 vDisk egroup ID, 크기, 변환 및 절감, 가비지 및 복제본 배치를 표시한다.
vdisk_usage_printer -vdisk_id=VDISK_ID
CLI로 큐레이터 스캔 시작 (Start Curator scan from CLI)
설명: CLI로 큐레이터 스캔 시작
전체 스캔 (Full Scan)
allssh "wget -O - "http://localhost:2010/master/api/client/StartCuratorTasks?task_type=2";"
부분 스캔 (Partial Scan)
allssh "wget -O - "http://localhost:2010/master/api/client/StartCuratorTasks?task_type=3";"
사용량 새로 고침 (Refresh Usage)
allssh "wget -O - "http://localhost:2010/master/api/client/RefreshStats";"
CLI로 Under-Replicated 데이터 체크 (Check under replicated data via CLI)
설명: curator_cli를 이용하여 Under-Replicated 데이터 체크
curator_cli get_under_replication_info summary=true
링 콤팩트 (Compact ring)
설명: 메타데이터 링 콤팩트
allssh "nodetool -h localhost compact"
AOS 버전 찾기 (Find NOS version)
D설명: AOS 버전 찾기 (NOTE: nCLI 명령으로 수행 가능)
allssh "cat /etc/nutanix/release_version"
CVM 버전 찾기 (Find CVM version)
설명: CVM 이미지 버전 찾기
allssh "cat /etc/nutanix/svm-version"
수동으로 vDisk 지문 생성 (Manually fingerprint vDisk(s))
설명: 특정 vDisk에 대한 지문 생성 (중복제거를 위해). NOTE: 컨테이너에서 중복제거가 활성화되어야 함)
vdisk_manipulator –vdisk_id=vDiskID --operation=add_fingerprints
수동으로 모든 vDisk 지문 생성 (Manually fingerprint all vDisk(s))
설명: 모든 vDisk에 대한 지문 생성 (중복제거를 위해). NOTE: 컨테이너에서 중복제거가 활성화되어야 함)
for vdisk in `vdisk_config_printer | grep vdisk_id | awk {'print $2'}`; do vdisk_manipulator -vdisk_id=$vdisk --operation=add_fingerprints; done
모든 클러스터 노드의 Factory_Config.JSON 출력 (Echo Factory_Config.json for all cluster nodes)
설명: 클러스터의 모든 노드에 대한 factory_config.json 출력
allssh "cat /etc/nutanix/factory_config.json"
단일 뉴타닉스 노드의 AOS 버전 업그레이드 (Upgrade a single Nutanix node’s NOS version)
설명: 클러스터의 AOS 버전과 일치하도록 단일 노드의 AOS 버전 업그레이드
~/cluster/bin/cluster -u NEW_NODE_IP upgrade_node
DSF의 파일(vDisk) 목록 출력 (List files (vDisk) on DSF)
설명: DSF에 저장된 vDisk에 대한 파일 및 관련 정보 출력
Nfs_ls
도움말 출력
Nfs_ls --help
NCC(Nutanix Cluster Check) 설치 (Install Nutanix Cluster Check (NCC))
설명: 잠재적인 이슈 및 클러스터 헬스를 테스트하기 위해 NCC(Nutanix Cluster Health) 헬스 스크립트 설치
뉴타닉스 서포트 포털(portal.nutanix.com)에서 NCC 다운로드
.tar.gz를 /home/nutanix 디렉토리에 복사
NCC .tar.gz 압축 해제
tar xzmf ncc.tar.gz --recursive-unlink
설치 스크립트 실행
./ncc/bin/install.sh -f ncc.tar.gz
링크 생성
source ~/ncc/ncc_completion.bash echo "source ~/ncc/ncc_completion.bash" >> ~/.bashrc
NCC(Nutanix Cluster Check) 실행 (Run Nutanix Cluster Check (NCC))
설명: 잠재적인 이슈 및 클러스터 헬스를 테스트하기 위해 NCC(Nutanix Cluster Health) 헬스 스크립트 실행한다. 모든 클러스터 이슈의 장애 처리를 위한 첫 번째 단계이다.
NCC가 설치되어 있는지 확인한다 (위의 설치 단계 참조).
NCC 헬스 체크 실행
ncc health_checks run_all
프로그레스 모니터 CLI를 사용하여 태스크 목록 출력 (List tasks using progress monitor cli)
progress_monitor_cli -fetchall
프로그레스 모니터 CLI를 사용하여 태스크 제거 (Remove task using progress monitor cli)
progress_monitor_cli --entity_id=ENTITY_ID --operation=OPERATION --entity_type=ENTITY_TYPE --delete # NOTE: operation and entity_type should be all lowercase with k removed from the begining
메트릭스 및 임계 값 (Metrics and Thresholds)
다음 섹션에서 뉴타닉스 백엔드의 특정 메트릭스 및 임계 값에 대해 설명한다. 보다 상세한 내용 추가 예정입니다.
Gflags
내용 추가 예정입니다.
장애 처리 및 고급 관리
아크로폴리스 로그 찾기 (Find Acropolis logs)
설명: 클러스터의 아크로폴리스 로그 찾기
allssh "cat ~/data/logs/Acropolis.log"
클러스터 ERROR 로그 찾기 (Find cluster error logs)
설명: 클러스터의 ERROR 로그 찾기
allssh "cat ~/data/logs/COMPONENTNAME.ERROR"
스타게이트 예제
allssh "cat ~/data/logs/Stargate.ERROR"
클러스터 FATAL 로그 찾기 (Find cluster fatal logs)
설명: 클러스터의 FATAL 로그 찾기
allssh "cat ~/data/logs/COMPONENTNAME.FATAL"
스타게이트 예제
allssh "cat ~/data/logs/Stargate.FATAL"
2009 페이지 사용하기 (스타게이트)
대부분의 경우 프리즘은 필요한 모든 정보와 데이터 포인트를 줄 수 있어야 한다. 그러나 특정 시나리오에서 또는 더 자세한 데이터를 원하는 경우 009 페이지로 알려진 스타게이트 정보를 활용할 수 있다. 2009 페이지는 “<CVM IP>:2009”로 이동하면 볼 수 있다.
Note
백엔드 페이지에 액세스 (Accessing back-end pages)
다른 네트워크 세그먼트(L2 서브넷)에 있는 경우 백엔드 페이지에 액세스하려면 IP 테이블에 규칙을 추가해야 한다.
페이지 맨 위에는 클러스터에 대한 다양한 세부 정보를 보여주는 개요 세부 정보가 있다.
 2009 페이지 - 스타게이트 개요 (2009 Page - Stargate Overview)
2009 페이지 - 스타게이트 개요 (2009 Page - Stargate Overview)
이 섹션에는 살펴봐야 할 두 가지 주요 영역이 있는데, 첫 번째는 승인/미해결 오퍼레이션 수를 보여주는 I/O 큐이다.
그림은 개요 섹션의 큐 부분을 보여준다.
 2009 페이지 - 스타게이트 개요 - 큐 (2009 Page - Stargate Overview - Queues)
2009 페이지 - 스타게이트 개요 - 큐 (2009 Page - Stargate Overview - Queues)
두 번째 부분은 캐시 크기 및 Hit Rates 정보를 보여주는 유니파이드 캐시 세부 정보이다.
그림은 개요 섹션의 유니파이드 캐시 부분을 보여준다.
 2009 페이지 - 스타게이트 개요 - 유니파이드 캐시 (2009 Page - Stargate Overview - Unified Cache)
2009 페이지 - 스타게이트 개요 - 유니파이드 캐시 (2009 Page - Stargate Overview - Unified Cache)
Note
Pro tip
워크로드가 읽기 중심인 경우 최대의 읽기 성능을 위해서는 Hit Ratio이 80~90%+ 이상이어야 한다.
NOTE: 이 값은 스타게이트/CVM 당이다
다음 섹션은 클러스터의 다양한 스타케이트 및 디스크 사용량에 대한 세부 정보를 보여주는 '클러스터 상태'이다.
그림은 스타게이트 및 디스크 사용률(가용/전체)을 보여준다.
 2009 페이지 - 클러스터 상태 - 디스크 사용률 (2009 Page - Cluster State - Disk Usage)
2009 페이지 - 클러스터 상태 - 디스크 사용률 (2009 Page - Cluster State - Disk Usage)
다음은 vDisk 별 다양한 세부 정보 및 통계를 보여주는 'NFS 워커'섹션이다.
그림은 vDisk 및 다양한 I/O 세부 정보를 보여준다.
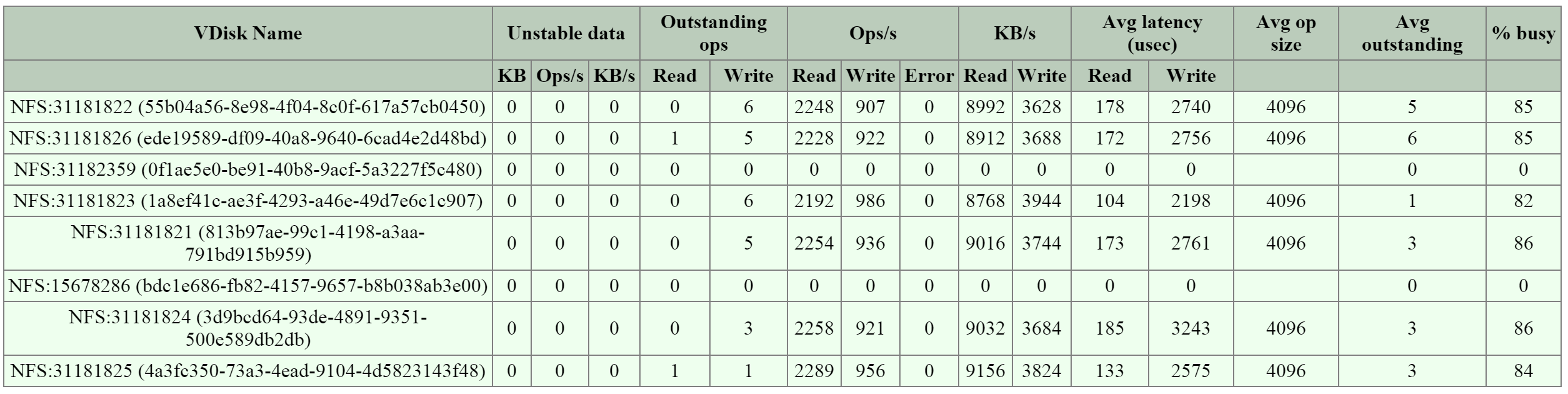 2009 페이지 - NFS 워커 - vDisk 통계 (2009 Page - NFS Worker - vDisk Stats)
2009 페이지 - NFS 워커 - vDisk 통계 (2009 Page - NFS Worker - vDisk Stats)
Note
Pro tip
잠재적인 성능 이슈를 살펴볼 때는 다음 메트릭스를 살펴봐야 한다.
- 평균 레이턴시 (Average latency)
- 평균 오퍼레이션 크기 (Average op size)
- 평균 미해결 수 (Average outstanding)
보다 구체적인 세부 정보를 위해 vdisk_stats 페이지에는 많은 정보가 포함되어 있다.
2009/vdisk_stats 페이지 사용하기
2009 vdisk_stats 페이지는 vDisk 당 더 많은 데이터 포인트를 제공하는 상세 페이지이다. 이 페이지에는 무작위성, 레이턴시 히스토그램, I/O 크기 및 Working Set 세부 정보와 같은 항목의 히스토그램과 세부 정보가 포함되어 있다.
왼쪽 컬럼에서 'vDisk Id'를 클릭하여 vdisk_stats 페이지로 이동할 수 있다.
그림은 섹션과 하이퍼링크된 vDisk ID를 보여준다.
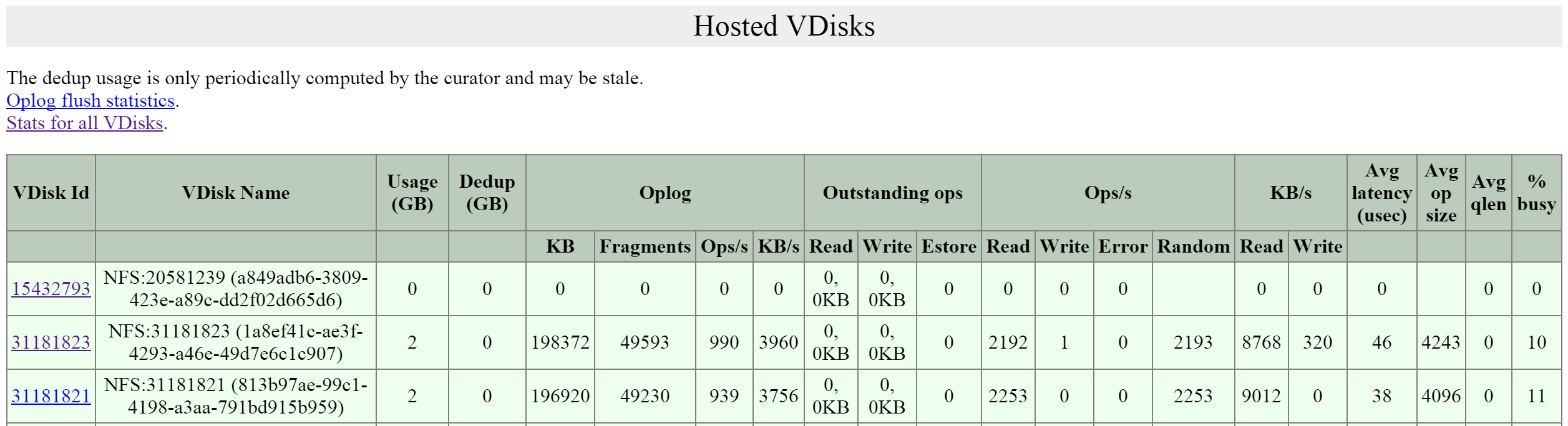 2009 페이지 - 호스트된 vDisks (2009 Page - Hosted vDisks)
2009 페이지 - 호스트된 vDisks (2009 Page - Hosted vDisks)
그러면 자세한 vDisk 통계를 제공하는 vdisk_stats 페이지로 이동하게 된다. NOTE: 이 값은 실시간이며 페이지를 새로 고침으로써 업데이트할 수 있다.
첫 번째 핵심 영역은 '오퍼레이션 및 무작위성' 섹션으로 I/O 패턴이 본질적으로 랜덤인지 순차적인지를 보여준다.
그림은 '오퍼레이션 및 무작위성'섹션을 보여준다.
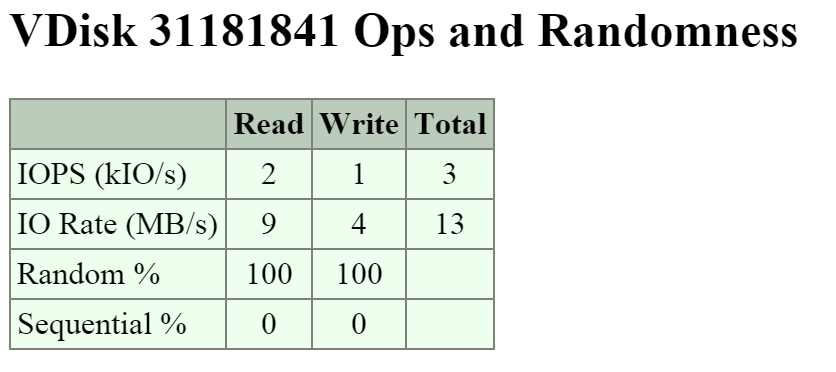 2009 페이지 - vDisks 통계 - 오퍼레이션 및 무작위성 (2009 Page - vDisk Stats - Ops and Randomness)
2009 페이지 - vDisks 통계 - 오퍼레이션 및 무작위성 (2009 Page - vDisk Stats - Ops and Randomness)
다음 영역은 프런트엔드 읽기 및 쓰기 I/O 레이턴시(VM/OS가 보는 레이턴시로 알려진)의 히스토그램을 보여준다.
그림은 '프런트엔드 읽기 레이턴시' 히스토그램을 보여준다.
 2009 페이지 - vDisks 통계 - 프런트엔드 읽기 레이턴시 (2009 Page - vDisk Stats - Frontend Read Latency)
2009 페이지 - vDisks 통계 - 프런트엔드 읽기 레이턴시 (2009 Page - vDisk Stats - Frontend Read Latency)
그림은 '프런트엔드 쓰기 레이턴시' 히스토그램을 보여준다.
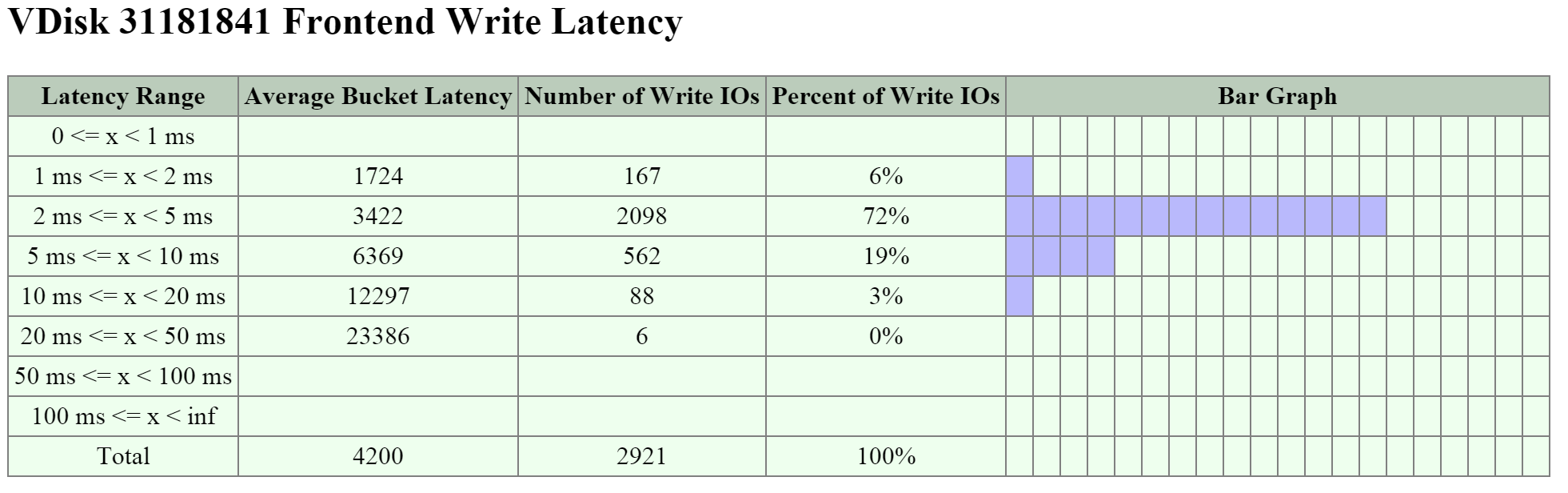 2009 페이지 - vDisks 통계 - 프런트엔드 쓰기 레이턴시 (2009 Page - vDisk Stats - Frontend Write Latency)
2009 페이지 - vDisks 통계 - 프런트엔드 쓰기 레이턴시 (2009 Page - vDisk Stats - Frontend Write Latency)
다음 주요 영역은 읽기 및 쓰기 I/O 크기의 히스토그램을 보여주는 I/O 크기 분포 섹션이다.
그림은 '읽기 크기 분포' 히스토그램을 보여준다.
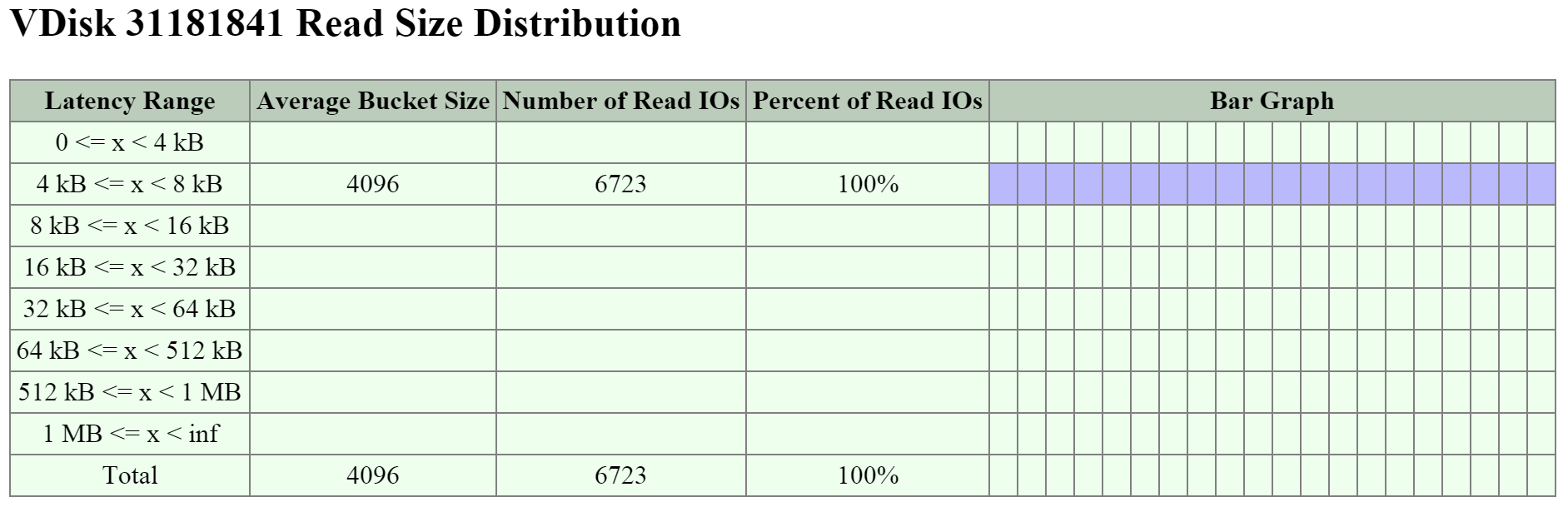 2009 페이지 - vDisks 통계 - 읽기 I/O 크기 (2009 Page - vDisk Stats - Read I/O Size)
2009 페이지 - vDisks 통계 - 읽기 I/O 크기 (2009 Page - vDisk Stats - Read I/O Size)
그림은 '쓰기 크기 분포' 히스토그램을 보여준다.
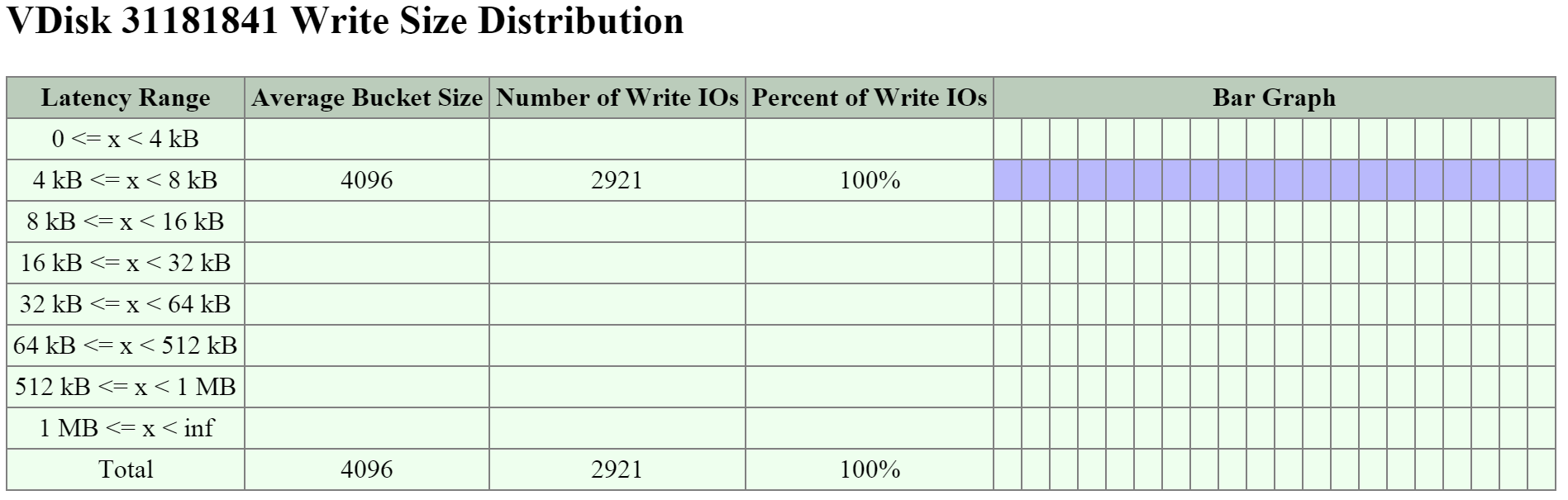 2009 페이지 - vDisks 통계 - 쓰기 I/O 크기 (2009 Page - vDisk Stats - Write I/O Size)
2009 페이지 - vDisks 통계 - 쓰기 I/O 크기 (2009 Page - vDisk Stats - Write I/O Size)
다음 주요 영역은 최근 2분 및 1시간 동안 Working Set 크기에 대한 통찰력을 제공하는 'Working Set 크기'섹션이다. 읽기 및 쓰기 I/O 모두에 대해 세분화된다.
그림은 'Working Set 크기' 테이블을 보여준다.
 2009 페이지 - vDisks 통계 - Working Set (2009 Page - vDisk Stats - Working Set)
2009 페이지 - vDisks 통계 - Working Set (2009 Page - vDisk Stats - Working Set)
'읽기 소스'는 읽기 I/O가 서비스되는 계층 또는 위치에 대한 세부 정보를 제공한다.
그림은 '읽기 소스' 세부 정보를 보여준다.
 2009 페이지 - vDisks 통계 - 읽기 소스 (2009 Page - vDisk Stats - Read Source)
2009 페이지 - vDisks 통계 - 읽기 소스 (2009 Page - vDisk Stats - Read Source)
Note
Pro tip
읽기 레이턴시가 높은 경우 vDisk의 읽기 소스를 보고 I/O가 서비스되는 위치를 살펴본다. 대부분의 경우 높은 레이턴시는 HDD(Estore HDD)에서 오는 읽기로 인해 발생할 수 있다.
'쓰기 목적지' 섹션은 새 쓰기 I/O가 발생하는 위치를 보여준다.
그림은 '쓰기 목적지' 테이블을 보여준다.
 2009 페이지 - vDisks 통계 - 쓰기 목적지 (2009 Page - vDisk Stats - Write Destination)
2009 페이지 - vDisks 통계 - 쓰기 목적지 (2009 Page - vDisk Stats - Write Destination)
Note
Pro tip
랜덤 I/O는 Oplog에 써지고 순차 I/O는 Oplog를 우회하여 익스텐트 스토어(Estore)에 직접 써진다.
또 다른 흥미로운 데이터 포인트는 데이터가 ILM을 통해 HDD에서 SSD로 업-마이그레이트되는 것이다. '익스텐트 그룹 업-마이그레이션' 테이블은 최근 300, 3,600 및 86,400초 동안 마이그레이션된 데이터를 보여준다.
그림은 '익스텐트 그룹 업-마이그레이션' 테이블을 보여준다.
 2009 페이지 - vDisks 통계 - 익스텐트 그룹 업-마이그레이션 (2009 Page - vDisk Stats - Extent Group Up-Migration)
2009 페이지 - vDisks 통계 - 익스텐트 그룹 업-마이그레이션 (2009 Page - vDisk Stats - Extent Group Up-Migration)
2010 페이지 사용하기 (큐레이터)
2010년 페이지는 큐레이터 맵리듀스 프레임워크를 모니터링하기 위한 세부 페이지이다. 이 페이지는 잡(Job), 스캔 및 관련 태스크에 대한 세부 정보를 제공한다.
큐레이터 페이지는 http://<CVM IP>:2010으로 이동하여 볼 수 있다. NOTE: 큐레이터 리더가 아닌 경우 '큐레이터 리더' 뒤에 있는 IP 하이퍼링크를 클릭한다.
페이지 상단에는 가동 시간, 빌드 버전 등 큐레이터 리더에 대한 다양한 세부 정보가 표시된다.
다음 섹션은 클러스터의 노드, 역할 및 헬스 상태에 대한 다양한 세부 정보를 보여주는 '큐레이터 마스터' 테이블이다. 이것이 큐레이터가 분산 프로세싱 및 태스크 위임에 활용하는 노드이다.
그림은 '큐레이터 노드' 테이블을 보여준다.
 2010 페이지 - 큐레이터 노드 (2010 Page - Curator Nodes)
2010 페이지 - 큐레이터 노드 (2010 Page - Curator Nodes)
다음 섹션은 완료되었거나 현재 실행 중인 잡(Job)을 보여주는 '큐레이터 잡' 테이블이다.
60분마다 실행할 수 있는 부분 스캔과 6시간마다 실행할 수 있는 전체 스캔을 포함하는 두 가지 주요 작업 유형이 있다. NOTE: 타이밍은 사용률 및 기타 액티비티에 따라 달라질 수 있다.
이러한 스캔은 정기적인 일정에 따라 실행되지만 특정 클러스터 이벤트에 의해 트리거될 수도 있다.
잡(Job) 실행에 대한 몇 가지 이유는 다음과 같다.
- 주기적인 실행 (정상 상태)
- 디스크 / 노드 / 블록 장애
- ILM 불균형
- 디스크 / 계층 불균형
그림은 '큐레이터 잡' 테이블을 보여준다.
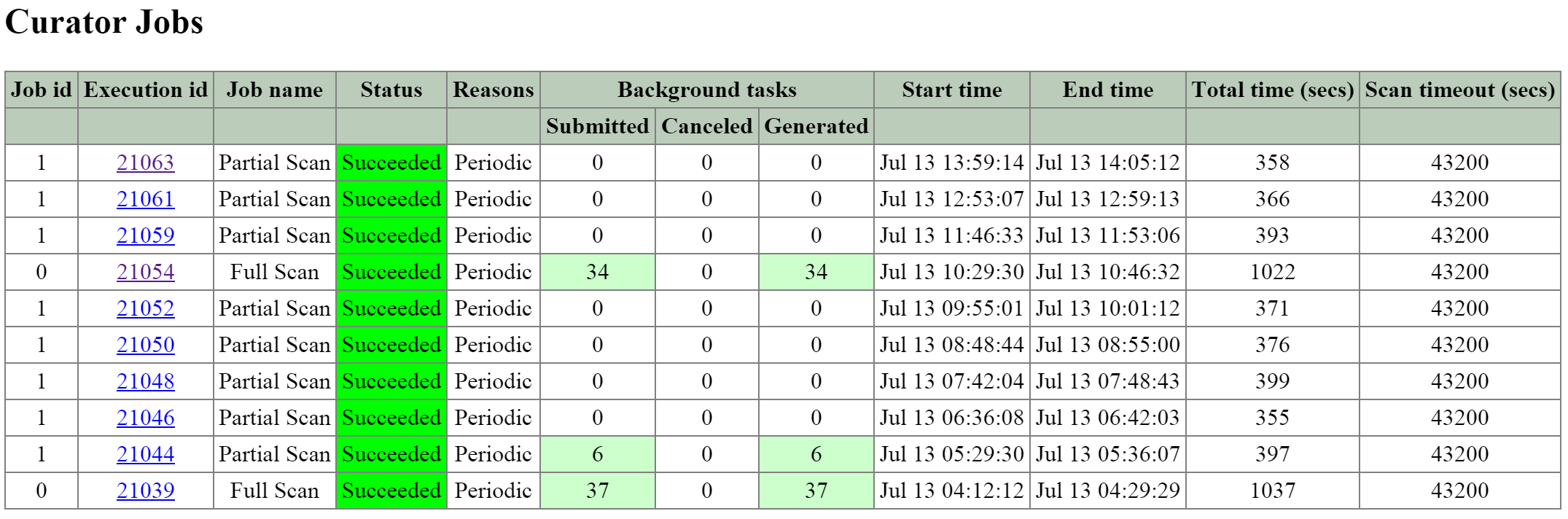 2010 페이지 - 큐레이터 잡 (2010 Page - Curator Jobs)
2010 페이지 - 큐레이터 잡 (2010 Page - Curator Jobs)
다음 테이블은 각 잡에 의해 수행되는 하이-레벨 액티비티의 일부를 보여준다.
| 액티비티 | 전체 스캔 | 부분 스캔 |
|---|---|---|
| ILM | X | X |
| 디스크 밸런싱 | X | X |
| 압축 | X | X |
| 중복제거 | X | |
| Erasure Coding | X | |
| 가비지 정리 | X |
'실행 ID'를 클릭하면 다양한 잡 통계 및 생성된 태스크를 보여주는 접 세부 페이지로 이동한다.
페이지 상단의 테이블에는 유형, 이유, 태스크 및 기간을 포함하여 잡에 대한 다양한 세부 정보가 표시된다.
다음 섹션은 태스크 유형, 생성 수량 및 우선순위에 대한 다양한 세부 정보를 보여주는 '백그라운드 태스크 통계' 테이블이다.
그림은 잡 세부 정보 테이블을 보여준다.
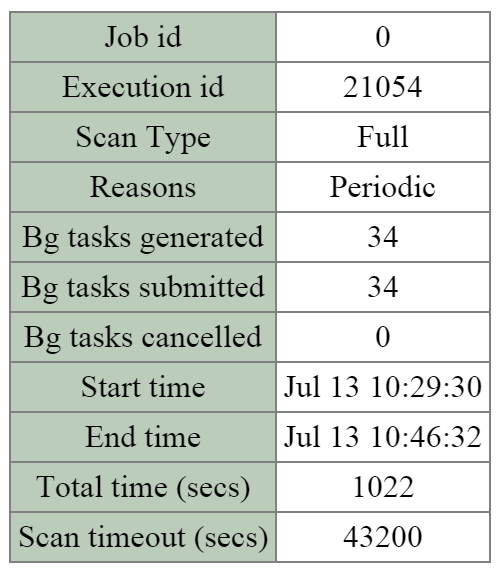 2010 페이지 - 큐레이터 잡 - 상세 정보 (2010 Page - Curator Job - Details)s
2010 페이지 - 큐레이터 잡 - 상세 정보 (2010 Page - Curator Job - Details)s
그림은 '백그라운드 태스크 통계' 테이블을 보여준다.
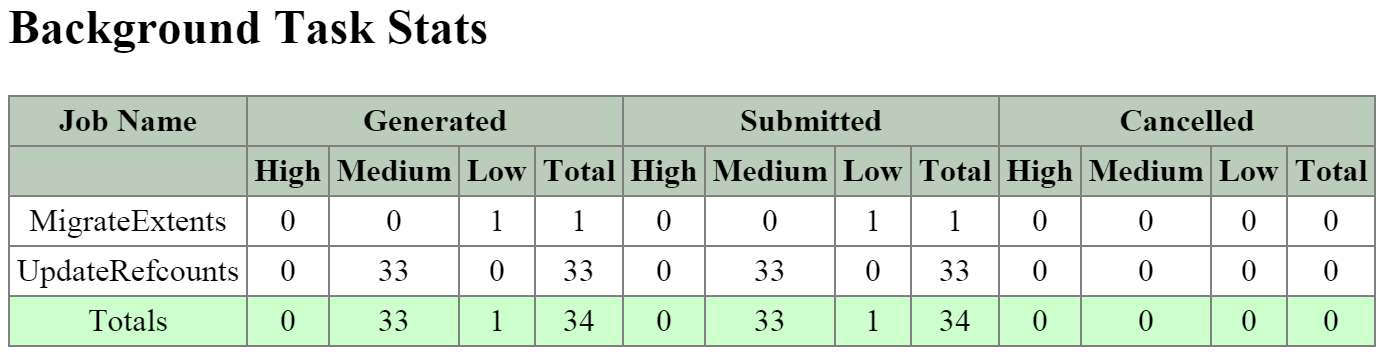 2010 페이지 – 큐레이터 잡 – 태스크 (2010 Page - Curator Job - Tasks)
2010 페이지 – 큐레이터 잡 – 태스크 (2010 Page - Curator Job - Tasks)
다음 섹션은 각 큐레이터 잡에 의해 시작된 실제 맵리듀스 태스크를 보여주는 '맵리듀스 잡' 테이블이다. 부분 스캔에는 한 개의 맵리듀스 잡이 있고 전체 스캔에는 네 개의 맵리듀스 잡이 있다.
그림은 '맵리듀스 잡' 테이블을 보여준다.
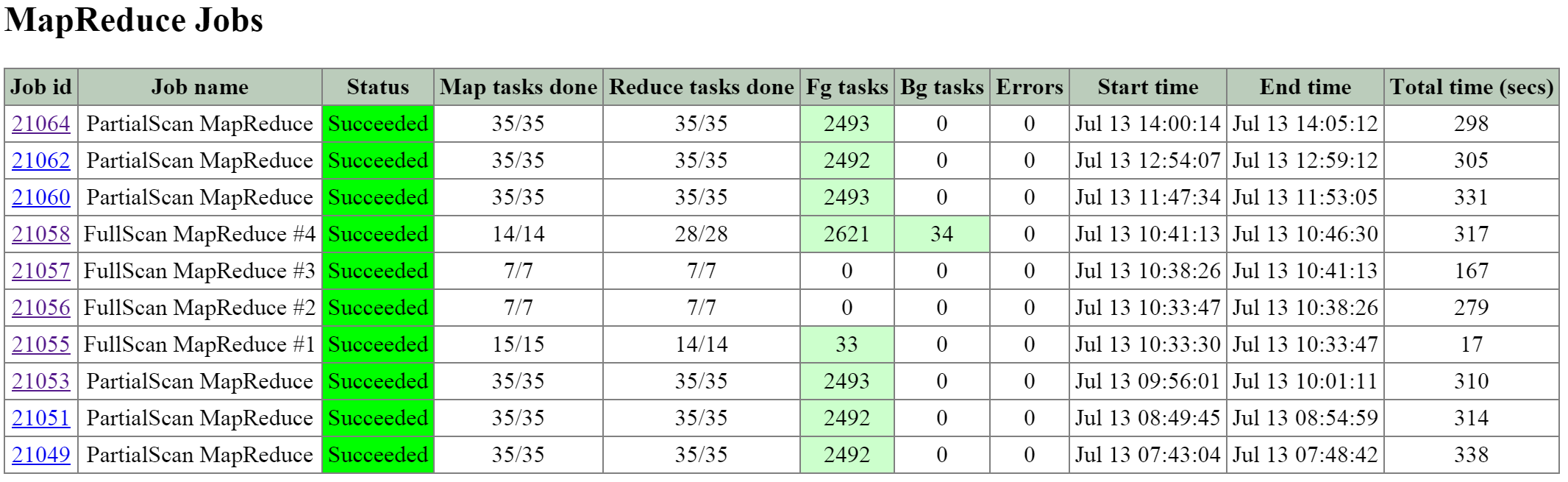 2010 페이지 - 맵리듀스 잡 (2010 Page - MapReduce Jobs)
2010 페이지 - 맵리듀스 잡 (2010 Page - MapReduce Jobs)
'JOB ID'를 클릭하면 작업 상태, 다양한 카운터 및 맵리듀스 잡에 대한 세부 정보를 표시하는 맵리듀스 잡 세부 정보 페이지로 이동한다.
다음은 잡 카운터의 일부 샘플을 보여준다.
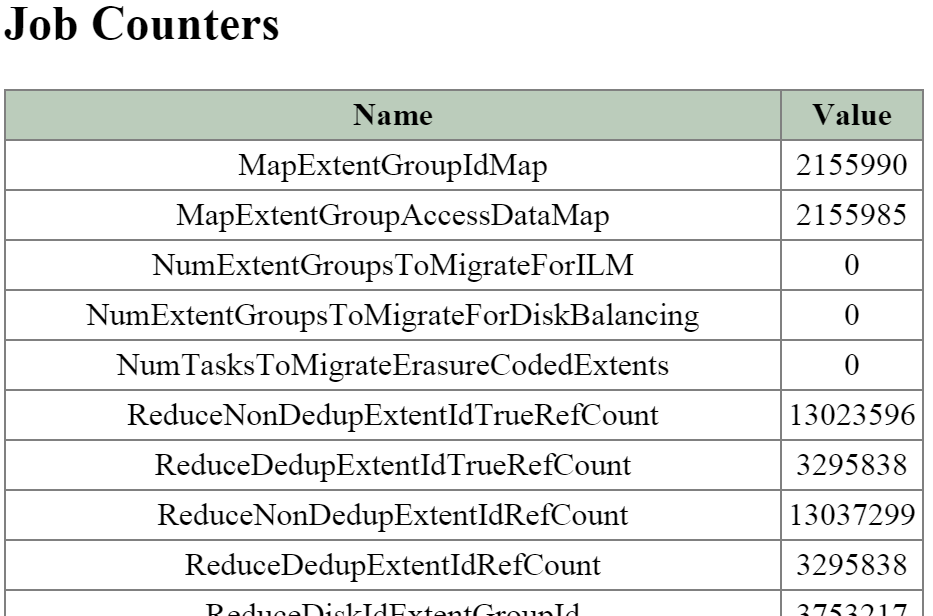 2010 페이지 - 맵리듀스 잡 - 카운터 ( 2010 Page - MapReduce Job - Counters)
2010 페이지 - 맵리듀스 잡 - 카운터 ( 2010 Page - MapReduce Job - Counters)
메인 페이지에서 다음 섹션은 '대기 중인 큐레이터 잡' 및 '마지막으로 성공한 큐레이터 스캔' 섹션이다. 이 테이블은 주기적 스캔을 실행할 수 있는 시기와 마지막으로 성공한 스캔의 세부 정보를 보여준다.
그림은 '대기 중인 큐레이터 잡' 및 '마지막으로 성공한 큐레이터 스캔' 섹션을 보여준다.
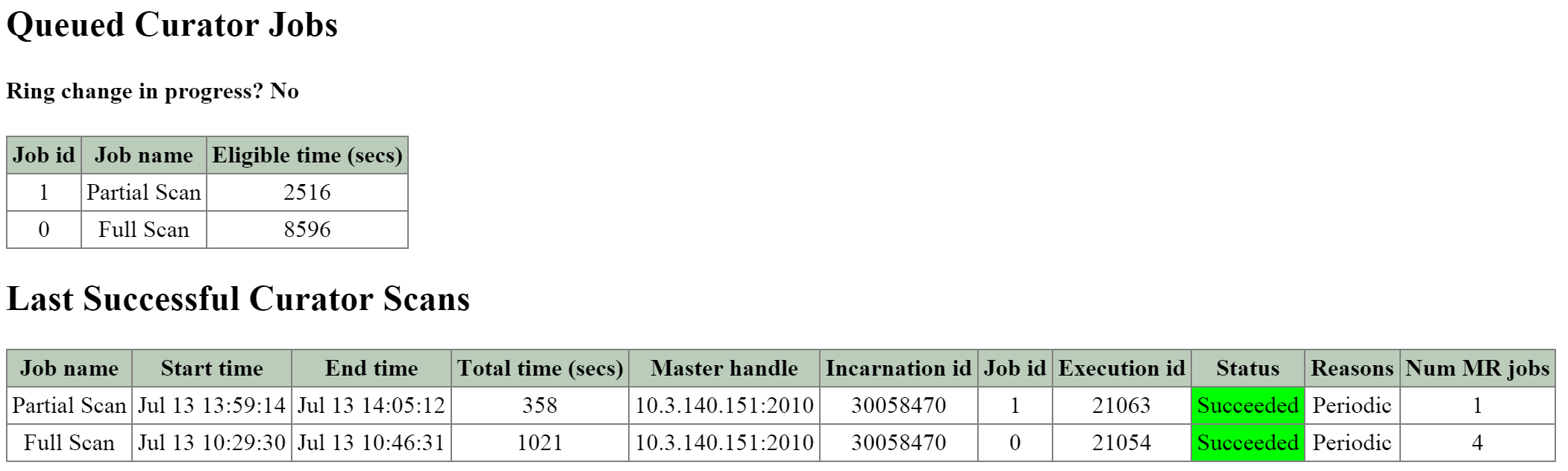 2010 페이지 - 대기 및 성공한 스캔 (2010 Page - Queued and Successful Scans)
2010 페이지 - 대기 및 성공한 스캔 (2010 Page - Queued and Successful Scans)
고급 CLI 정보
프리즘은 일반적인 장애 처리 및 성능 모니터링 측면에서 필요한 모든 것을 제공해야 한다. 그러나 위에서 언급한 일부 백앤드 페이지 또는 CLI에서 보이는 보다 자세한 정보를 얻으려는 경우가 있다.
vdisk_config_printer
vdisk_config_printer 명령은 클러스터의 모든 vdisk에 대한 vdisk 정보 목록을 표시한다.
아래에 몇 가지 중요한 필드를 강조했다.
- Vdisk ID
- Vdisk name
- Parent vdisk ID (if clone or snapshot)
- Vdisk size (Bytes)
- Container id
- To remove bool (to be cleaned up by curator scan)
- Mutability state (mutable if active r/w vdisk, immutable if snapshot)
다음은 명령 출력 예이다.
nutanix@NTNX-13SM35210012-A-CVM:~$ vdisk_config_printer | more ... vdisk_id: 1014400 vdisk_name: "NFS:1314152" parent_vdisk_id: 16445 vdisk_size: 40000000000 container_id: 988 to_remove: true creation_time_usecs: 1414104961926709 mutability_state: kImmutableSnapshot closest_named_ancestor: "NFS:852488" vdisk_creator_loc: 7 vdisk_creator_loc: 67426 vdisk_creator_loc: 4420541 nfs_file_name: "d12f5058-f4ef-4471-a196-c1ce8b722877" may_be_parent: true parent_nfs_file_name_hint: "d12f5058-f4ef-4471-a196-c1ce8b722877" last_modification_time_usecs: 1414241875647629 ...
vdisk_usage_printer -vdisk_id=
vdisk_usage_printer는 vdisk, 익스텐트 및 egroup에 대한 자세한 정보를 얻는 데 사용된다.
아래에 몇 가지 중요한 필드를 강조했다.
- Egroup ID
- Egroup extent count
- Untransformed egroup size
- Transformed egroup size
- Transform ratio
- Transformation type(s)
- Egroup replica locations (disk/cvm/rack)
다음은 명령 출력 예이다.
nutanix@NTNX-13SM35210012-A-CVM:~$ vdisk_usage_printer -vdisk_id=99999 Egid # eids UT Size T Size ... T Type Replicas(disk/svm/rack) 1256878 64 1.03 MB 1.03 MB ... D,[73 /14/60][184108644/184108632/60] 1256881 64 1.03 MB 1.03 MB ... D,[73 /14/60][152/7/25] 1256883 64 1.00 MB 1.00 MB ... D,[73 /14/60][184108642/184108632/60] 1055651 4 4.00 MB 4.00 MB ... none[76 /14/60][184108643/184108632/60] 1056604 4 4.00 MB 4.00 MB ... none[74 /14/60][184108642/184108632/60] 1056605 4 4.00 MB 4.00 MB ... none[73 /14/60][152/7/25] ...
NOTE: 중복제거된 egroup 대 중복제거되지 않은 egroups(1MB 대 4MB)에 대한 egroup 크기에 유의하여야 한다. “데이터 구조” 섹션에서 언급했듯이 중복제거된 데이터의 경우 데이터를 중복제거하여 잠재적인 프래그멘테이션을 무효화하려면 1MB egroup 크기가 선호된다.
curator_cli display_data_reduction_report
curator_cli display_data_reduction_report는 변환(e.g. 클론, 스냅샷, 중복제거, 압축, Erasure Coding 등)에 의한 컨테이너 당 스토리지 절감에 대한 자세한 정보를 얻는 데 사용된다.
아래에 몇 가지 중요한 필드를 강조했다.
- Container ID
- Technique (transform applied)
- Pre reduction Size
- Post reduction size
- Saved space
- Savings ratio
다음은 명령 출력 예이다.
CVM:~$ curator_cli display_data_reduction_report Using curator leader: 99.99.99.99:2010 Using execution id 68188 of the last successful full scan +---------------------------------------------------------------------------+ | Container| Technique | Pre | Post | Saved | Ratio | | Id | | Reduction | Reduction | | | +---------------------------------------------------------------------------+ | 988 | Clone | 4.88 TB | 2.86 TB | 2.02 TB | 1.70753 | | 988 | Snapshot | 2.86 TB | 2.22 TB | 656.92 GB | 1.28931 | | 988 | Dedup | 2.22 TB | 1.21 TB | 1.00 TB | 1.82518 | | 988 | Compression | 1.23 TB | 1.23 TB | 0.00 KB | 1 | | 988 | Erasure Coding | 1.23 TB | 1.23 TB | 0.00 KB | 1 | | 26768753 | Clone | 764.26 GB | 626.25 GB | 138.01 GB | 1.22038 | | 26768753 | Snapshot | 380.87 GB | 380.87 GB | 0.00 KB | 1 | | 84040 | Snappy | 810.35 GB | 102.38 GB | 707.97 GB | 7.91496 | | 6853230 | Snappy | 3.15 TB | 1.09 TB | 2.06 TB | 2.88713 | | 12199346 | Snappy | 872.42 GB | 109.89 GB | 762.53 GB | 7.93892 | | 12736558 | Snappy | 9.00 TB | 1.13 TB | 7.87 TB | 7.94087 | | 15430780 | Snappy | 1.23 TB | 89.37 GB | 1.14 TB | 14.1043 | | 26768751 | Snappy | 339.00 MB | 45.02 MB | 293.98 MB | 7.53072 | | 27352219 | Snappy | 1013.8 MB | 90.32 MB | 923.55 MB | 11.2253 | +---------------------------------------------------------------------------+
curator_cli get_vdisk_usage lookup_vdisk_ids=<COMMA SEPARATED VDISK ID(s)>
curator_cli get_vdisk_usage lookup_vdisk_ids 명령은 지정된 각 vdisk가 사용하는 공간에 대한 다양한 통계를 가져오는 데 사용된다.
아래에 몇 가지 중요한 필드를 강조했다.
- Vdisk ID
- Exclusive usage (Data referred to by only this vdisk)
- Logical uninherited (Data written to vdisk, may be inherited by a child in the event of clone)
- Logical dedup (Amount of vdisk data that has been deduplicated)
- Logical snapshot (Data not shared across vdisk chains)
- Logical clone (Data shared across vdisk chains)
다음은 명령 출력 예이다.
Using curator leader: 99.99.99.99:2010 VDisk usage stats: +------------------------------------------------------------------------+ | VDisk Id | Exclusive | Logical | Logical | Logical | Logical | | | usage | Uninherited | Dedup | Snapshot | Clone | +------------------------------------------------------------------------+ | 254244142 | 596.06 MB | 529.75 MB | 6.70 GB | 11.55 MB | 214 MB | | 15995052 | 599.05 MB | 90.70 MB | 7.14 GB | 0.00 KB | 4.81 MB | | 203739387 | 31.97 GB | 31.86 GB | 24.3 MB | 0.00 KB | 4.72 GB | | 22841153 | 147.51 GB | 147.18 GB | 0.00 KB | 0.00 KB | 0.00 KB | ...
curator_cli get_egroup_access_info
curator_cli get_egroup_access_info는 마지막 액세스 (읽기) / 수정 ([덮어]쓰기)을 기반으로 각 버킷의 egroup 수에 대한 자세한 정보를 얻는 데 사용된다. 이 정보는 Erasure Coding을 활용하기 위한 후보가 될 수 있는 egroup의 수를 추정하는 데 사용될 수 있다.
아래에 몇 가지 중요한 필드를 강조했다.
- Container ID
- Access \ Modify (secs)
다음은 명령 출력 예이다.
Using curator leader: 99.99.99.99:2010 Container Id: 988 +----------------------------------------------------------------------------.. | Access \ Modify (secs) | [0,300) | [300,3600) | [3600,86400) | [86400,60480.. +----------------------------------------------------------------------------.. | [0,300) | 345 | 1 | 0 | 0 .. | [300,3600) | 164 | 817 | 0 | 0 .. | [3600,86400) | 4 | 7 | 3479 | 7 .. | [86400,604800) | 0 | 0 | 81 | 7063 .. | [604800,2592000) | 0 | 0 | 15 | 22 .. | [2592000,15552000) | 1 | 0 | 0 | 10 .. | [15552000,inf) | 0 | 0 | 0 | 1 .. +----------------------------------------------------------------------------.. ...
Book of AHV
AHV는 네이티브 뉴타닉스 하이퍼바이저이며 CentOS KVM foundation을 기반으로 한다. HA, 라이브 마이그레이션, IP 주소 관리 등과 같은 기능을 포함하도록 기능을 확장하였다.
AHV는 Microsoft Server Virtualization Validation Program의 일부로 검증되었으며, Microsoft OS 및 응용 프로그램을 실행하도록 검증되었다.
본 BOOK에서는 AHV의 아키텍처 및 기능을 설명한다.
AHV 아키텍처
노드 아키텍처
AHV 배포에서 컨트롤러 VM(CVM)은 VM으로 실행되고 디스크는 PCI 패스스루를 사용하여 제공된다. 이를 통해 전체 PCI 컨트롤러(및 연결된 디바이스)를 CVM으로 직접 전달하고 하이퍼바이저를 우회할 수 있다. AHV는 CentOS KVM을 기반으로 한다. 게스트 VM(HVM)을 위해 전체 하드웨어 가상화가 사용된다.
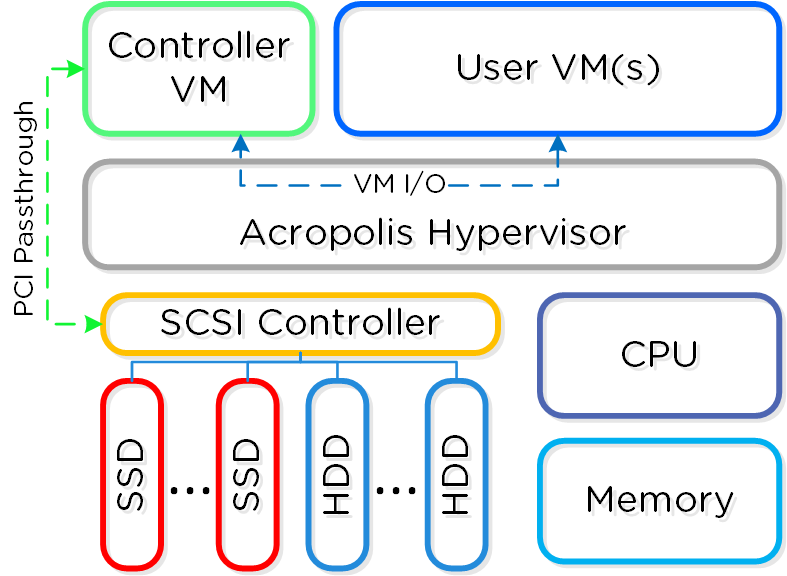 AHV 노드 (AHV Node)
AHV 노드 (AHV Node)
KVM 아키텍처
KVM에는 몇 가지 주요 컴포넌트가 있다.
- KVM-kmod
- KVM 커널 모듈
- Libvirtd
- KVM 및 QEMU 관리를 위한 API, 데몬 및 관리 툴이다. AOS와 KVM/QEMU 간의 통신은 libvirtd를 통해 이루어진다.
- Qemu-kvm
- 모든 VM(도메인)을 위해 유저 스페이스에서 실행되는 머신 에뮬레이터 및 버츄얼라이저이다. AHV에서는 하드웨어 지원 가상화에 사용되며 VM은 HVM으로 실행된다.
다음 그림은 다양한 컴포넌트 간의 관계를 보여준다.
 KVM 컴포넌트 간의 관계 (KVM Component Relationship)
KVM 컴포넌트 간의 관계 (KVM Component Relationship)
AOS와 KVM 간의 통신은 Libvirt를 통해 이루어진다.
Note
프로세서 세대 호환성 (Processor Generation Compatibility)
VM을 서로 다른 프로세서 세대 간에 이동할 수 있는 VMware의 EVC(Enhanced vMotion Capability)와 유사하게 AHV는 클러스터에서 가장 낮은 프로세서 세대를 결정하고 모든 QEMU 도메인을 해당 수준으로 제한한다. 이를 통해 AHV 클러스터 내에서 프로세서 세대를 혼합하고 호스트들 간에 라이브 마이그레이션 기능을 보장한다.
설정 최대값 및 확장성
다음과 같은 설정 최대값 및 확장성 제한이 적용된다.
- 최대 클러스터 크기: N/A – 뉴타닉스 클러스터 크기와 동일
- VM 당 최대 vCPU: 호스트 당 물리적 코어 수
- VM 당 최대 메모리: 4TB와 사용 가능한 물리적 노드 메모리의 최소값
- 최대 가상 디스크 크기: 9EB* (Exabyte)
- 호스트 당 최대 VM 수: N/A – 메모리로 제한
- 클러스터 당 최대 VM 수: N/A – 메모리로 제한
*AHV에는 ESXi/Hyper-V와 같은 기존 스토리지 스택이 없으며 모든 디스크는 원시 SCSI 블록 디바이스로 VM에 전달된다. 이는 최대 가상 디스크 크기가 최대 DSF vDisk 크기(9 Exabytes)로 제한됨을 의미한다.
네트워킹
AHV는 모든 VM 네트워킹에 OVS(Open vSwitch)를 활용한다. VM 네트워킹은 프리즘/ACLI를 통해 설정되며 각 VM NIC는 탭 인터페이스에 연결된다.
다음 그림은 OVS 아키텍처의 개념도를 보여준다.
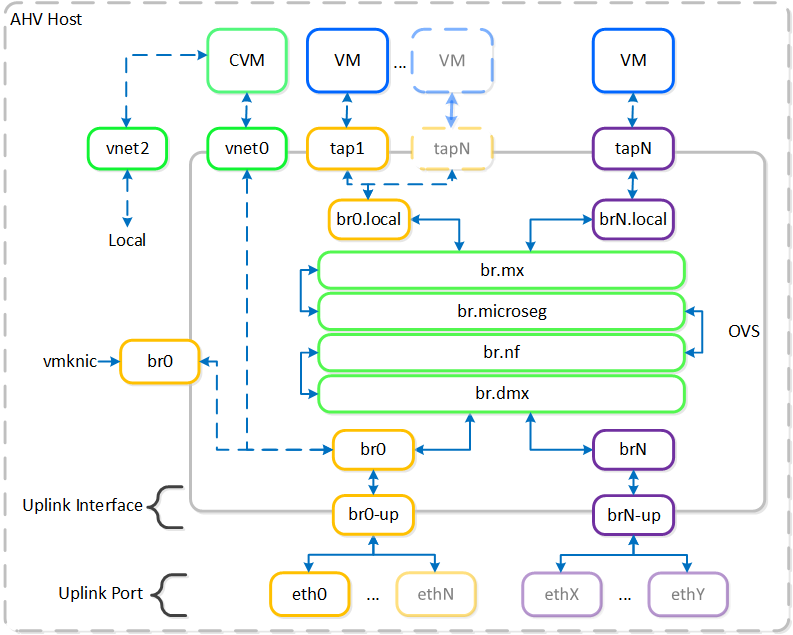 Open vSwitch 네트워크 개요 (Open vSwitch Network Overview)
Open vSwitch 네트워크 개요 (Open vSwitch Network Overview)
이전 이미지에 몇 가지 유형의 컴포넌트가 있다.
Open vSwitch (OVS)
OVS는 Linux 커널에서 구현되고 다중 서버 가상화 환경에서 동작하도록 설계된 오픈 소스 소프트웨어 스위치이다. 기본적으로 OVS는 MAC 주소 테이블을 유지하는 Layer-2 러닝 스위치처럼 동작한다. 하이퍼바이저 호스트와 VM은 스위치의 가상 포트에 연결된다.
OVS는 VLAN 태깅, LACP, 포트 미러링 및 QoS를 포함하여 많은 일반적인 스위치 기능을 지원한다. 각 AHV 서버는 OVS 인스턴스를 유지하며 모든 OVS 인스턴스는 하나의 논리적 스위치를 구성하기 위해 결합된다. 브릿지는 AHV 호스트에 있는 스위치 인스턴스를 관리한다.
브릿지 (Bridge)
브릿지는 물리적 및 가상 네트워크 인터페이스 간의 네트워크 트래픽을 관리하는 가상 스위치 역할을 한다. 기본 AHV 설정에는 br0로 불리는 OVS 브리지와 virbr0로 불리는 네이티브 Linux 브리지가 포함된다. virbr0 Linux 브리지는 CVM과 AHV 호스트 간의 관리 및 스토리지 통신을 전달한다. 다른 모든 스토리지, 호스트 및 VM 네트워크 트래픽은 br0 OVS 브리지를 통해 흐른다. AHV 호스트, VM 및 물리적 인터페이스는 브릿지 연결을 위해 "포트"를 사용한다.
포트 (Port)
포트는 가상 스위치와의 연결을 위해 브릿지에서 생성된 논리적 컨스트럭트이다. 뉴타닉스는 내부(Internal), 탭(Tap), VXLAN 및 본드(Bond)를 포함한 몇 가지 포트 유형을 사용한다.
- 기본 브리지(br0)와 동일한 이름을 가진 내부 포트는 AHV 호스트에 대한 액세스를 제공한다.
- 탭 포트는 VM에 제공되는 가상 NIC의 브릿지 연결 역할을 한다.
- VXLAN 포트는 아크로폴리스에서 제공하는 IP 주소 관리 기능에 사용된다.
- Bonded 포트는 AHV 호스트의 물리적 인터페이스를 위한 NIC 티밍(NIC Teaming)을 제공한다.
본드 (Bond)
Bonded 포트는 AHV 호스트의 물리적 인터페이스를 집계한다. 기본적으로 br0-up이라는 이름의 본드가 브릿지 br0에 생성된다. 노드 이미징 프로세스 후 모든 인터페이스가 하나의 본드 내에 배치되는데, 이는 파운데이션 이미징 프로세스의 요구 사항이다. 기본 본드인 br0-up을 변경하면 종종 본드의 이름이 bond0로 바뀐다. 뉴타닉스는 브릿지 br0 업링크 인터페이스를 신속하게 식별할 수 있도록 br0-up이라는 이름의 사용을 권장한다.
OVS 본드는 active-backup, balance-slb, balance-tcp를 포함한 여러 가지 로드 밸런싱 모드를 지원한다. LACP는 본드를 위해 활성화될 수 있다. 설지 중에 "bond_mode" 설정이 지정되지 않아 기본적으로 권장 모드인 active-backup으로 설정된다.
업링크 로드 밸런싱
이전 섹션에서 간단히 언급했듯이 본드 업링크를 통해 트래픽을 조정할 수 있다.
다음과 같은 본드 모드를 사용할 수 있다.
- active-backup
- 하나의 액티브 어댑터를 통해 모든 트래픽을 전송하는 기본 설정. 액티브 어댑터를 사용할 수 없게 되면 본드 내의 다른 어댑터가 액티브로 된다. 처리량이 한 개 NIC의 대역폭으로 제한된다(권장 모드).
- balance-slb
- 본드의 어댑터 전체에서 각 VM의 NIC을 밸런싱 한다 (e.g. VM A nic 1 - eth0 / nic 2 - eth1). VM의 NIC 당 처리량을 한 개 NIC의 대역폭으로 제한하지만, x개의 NIC을 갖는 VM은 x * 어댑터 대역폭을 활용할 수 있다 (x는 VM NIC의 수와 본드의 물리적 어댑터 수가 같다고 가정). NOTE: 멀티캐스트 트래픽에 대한 주의 사항이 있다.
- balance-tcp / LACP
- 본드의 어댑터 전체에서 각 VM NIC의 TCP 세션을 밸런싱 한다. NIC 당 처리량은 최대 본드 대역폭(물리적 업링크 어댑터 수 * 속도)으로 제한된다. Link Aggregation이 필요하며 LACP가 필요할 때 사용된다.
본드에 대한 추가적인 정보는 AHV 네트워킹 가이드 문서 참조: (LINK).
VM NIC 유형
HV는 다음 VM 네트워크 인터페이스 유형을 지원한다.
- 액세스 (Access) - 디폴트
- 트렁크 (Trunk) - AOS 4.6 이상
기본적으로 VM NIC은 액세스 인터페이스(포트 그룹의 VM NIC에서 볼 수 있는 것과 유사)로 생성되지만 트렁크 인터페이스를 VM의 OS에 노출시킬 수 있다. 트렁크 NIC은 태그가 없는 기본 VLAN과 태그가 있는 모든 추가 VLAN을 VM의 동일 vNIC으로 전송한다. 이것은 vNIC를 추가하지 않고 여러 네트워크를 VM에 할당하는 데 유용하다.
다음 명령을 사용하여 트렁크 인터페이스를 추가 할 수 있다.
vm.nic_create VM_NAME vlan_mode=kTrunked trunked_networks=ALLOWED_VLANS network=NATIVE_VLAN
예제:
vm.nic_create fooVM vlan_mode=kTrunked trunked_networks=10,20,30 network=vlan.10
서비스 체인
AHV 서비스 체인을 통해 모든 트래픽을 가로채서 네트워크 경로의 일부로 패킷 프로세서(NFV, 어플라이언스, 가상 어플라이언스 등) 기능에 전달할 수 있다.
서비스 체인의 일반적인 용도는 다음과 같다.
- 방화벽 (e.g. Palo Alto 등)
- 로드 밸런서 (e.g. F5, NetScaler 등)
- IDS/IPS/네트워크 모니터 (e.g. 패킷 캡처)
서비스 체인 내에는 두 가지 유형의 방법이 있다.
 서비스 체인 – 패킷 프로세서 (Service chain - Packet Processors)
서비스 체인 – 패킷 프로세서 (Service chain - Packet Processors)
- 인라인 패킷 프로세서 (Inline packet processor)
- 패킷이 OVS를 통과할 때 인라인으로 패킷을 가로챈다.
- 패킷을 수정할 수 있고 허용/거부할 수 있다.
- 일반적인 활용 예: 방화벽 및 로드 밸런서
- 탭 패킷 프로세서 (Tap packet processor)
- 패킷이 흐를 때 패킷을 검사한다. 패킷 흐름에 대한 탭이므로 읽기만 가능하다.
- 일반적인 활용 예: IDS/IPS/네트워크 모니터
모든 서비스 체인은 플로우-마이크로세그멘테이션 규칙이 적용된 후 패킷이 로컬 OVS를 떠나기 전에 수행된다. 이는 네트워크 기능 브리지(br.nf)에서 발생한다.
 서비스 체인 – 플로우 (Service Chain - Flow)
서비스 체인 – 플로우 (Service Chain - Flow)
NOTE: 하나의 체인에 여러 개의 NFV/패킷 프로세서를 함께 묶을 수 있다.
VM 템플릿 (VM Templates)
AHV는 쉽게 복제할 수 있도록 단일 vDisk 내에서 데이터를 캡처하는 데 중점을 둔 이미지 라이브러리를 항상 가지고 있었지만, CPU, 메모리 및 네트워크 상세 정보 선언 프로세스를 완료하려면 관리자의 입력이 필요했다. VM 템플릿(VM Templates)은 이러한 개념을 한 단계 더 단순하게 만들뿐만 아니라 다른 하이퍼바이저에서 템플릿을 활용했던 관리자에게 보다 친숙한 환경을 제공한다.
AHV VM 템플릿은 기존 VM에서 CPU, 메모리, vDisk 및 네트워킹 상세 정보 등과 같은 VM을 정의하는 속성을 상속받아 생성된다. 그런 다음 배포 시 게스트 OS를 커스터마이제이션할 수 있도록 템플릿을 설정할 수 있으며 선택적으로 Windows 라이선스 키를 제공할 수 있다. 템플릿을 사용하면 여러 버전을 유지 관리할 수 있으며, 새로운 템플릿을 만들 필요 없이 OS 및 애플리케이션 패치와 같은 업데이트를 쉽게 적용할 수 있다. 관리자는 활성화된 템플릿 버전을 선택할 수 있으므로 업데이트를 미리 준비하거나 필요한 경우 이전 버전으로 다시 전환할 수 있다.
메모리 오버커밋 (Memory Overcommit)
가상화의 핵심 장점 중의 하나는 컴퓨팅 리소스를 오버커밋하는 기능으로, 서버 호스트에 물리적으로 존재하는 것보다 더 많은 CPU를 VM에 프로비저닝할 수 있다. 대부분의 워크로드에는 할당된 모든 CPU가 100% 필요하지 않으므로, 하이퍼바이저는 특정 시점에 CPU 주기를 필요로 하는 워크로드에 CPU 주기를 동적으로 할당할 수 있다.
CPU 또는 네트워크 자원과 마찬가지로 메모리도 오버커밋될 수 있다. 특정 시간 대에 호스트에서 실행 중인 VM은 할당된 모든 메모리를 사용하거나 사용하지 않을 수 있으므로, 하이퍼바이저는 사용되지 않은 메모리를 다른 워크로드와 공유할 수 있다. 메모리 오버커밋을 통해 관리자는 사용하지 않는 메모리를 결합하고 모은 후에 이를 필요로 하는 VM에게 할당함으로써 호스트 당 더 많은 VM을 프로비저닝할 수 있다.
AOS 6.1은 추가 메모리 및 높은 VM 집적도가 필요한 테스트 및 개발과 같은 환경에서 관리자가 활용할 수 있도록 AHV에서 메모리 오버커밋을 옵션으로 제공한다. 오버커밋은 디폴트로 비활성화되어 있으며, 클러스터에 있는 VM 전체 또는 일부에서만 공유를 수행할 수 있도록 VM 별로 정의할 수 있다.
VM 선호도 정책 (VM Affinity Policies)
다양한 유형의 애플리케이션에는 VM이 동일한 호스트에서 실행되어야 하는지 아니면 다른 호스트에서 실행되어야 하는지를 지시하는 요구 사항이 있을 수 있다. 이는 일반적으로 성능 또는 가용성 목적을 위해 수행된다. 선호도 정책을 통해 VM이 실행되는 위치를 제어할 수 있다. AHV에는 두 가지 유형의 선호도 정책이 있다.
- VM-호스트 선호도 (VM-host affinity)
- VM을 호스트 또는 호스트 그룹에 엄격하게 연결하므로 VM은 해당 호스트 또는 그룹에서만 실행된다. 선호도는 특히 소프트웨어 라이선스 또는 VM 어플라이언스와 관련된 사용 사례에 적용할 수 있다. 이러한 경우 애플리케이션이 실행될 수 있는 호스트 수를 제한하거나 VM 어플라이언스를 단일 호스트에 바인딩해야 하는 경우가 많다.
- 반선호도 (Anti-affinity)
- AHV는 지정된 VM 목록이 동일한 호스트에서 실행되지 않도록 선언할 수 있는 기능을 제공한다. 반선호도는 클러스터된 VM 또는 분산 애플리케이션을 실행하는 VM이 다른 호스트에서 실행되도록 허용하는 메커니즘을 제공하여 애플리케이션의 가용성과 복원력을 높여 준다. VM 격리보다 VM 가용성을 제공하기 위해 시스템은 클러스터가 정상 동작 중이 아닌 경우에는 이러한 유형의 규칙을 무시한다.
뉴타닉스 AHV 동작 방식
스토리지 I/O 경로
AHV는 ESXi 또는 Hyper-V와 같은 기존 스토리지 스택을 활용하지 않는다. 모든 디스크는 원시 SCSI 블록 디바이스로 VM에 전달된다. 이렇게 하면 I/O 경로가 가벼워지고 최적화된다.
Note
Note
AOS는 최종 사용자로부터 kvm, virsh, qemu, libvirt 및 iSCSI를 추상화하고 모든 백엔드 설정을 처리한다. 이는 사용자가 프리즘/ACLI를 통해 VM의 더 높은 스택에 집중할 수 있게 한다. 다음은 정보 제공만을 목적으로 하며 virsh, libvirt 등과 같은 명령을 직접 사용할 것을 권고하는 것은 아니다.
각 AHV 호스트는 NOP 명령을 사용하여 클러스터 전체에서 스타게이트 헬스를 정기적으로 확인하는 iSCSI 리디렉터를 실행한다.
iscsi_redirector 로그(AHV 호스트의 "/var/log/"에 있음)에서 각 스타게이트 헬스를 확인할 수 있다.
2017-08-18 19:25:21,733 - INFO - Portal 192.168.5.254:3261 is up ... 2017-08-18 19:25:25,735 - INFO - Portal 10.3.140.158:3261 is up 2017-08-18 19:25:26,737 - INFO - Portal 10.3.140.153:3261 is up
NOTE: 로컬 스타게이트는 192.168.5.254 내부 주소를 통해 볼 수 있다.
다음에서 iscsi_redirector가 127.0.0.1:3261에서 수신 대기 중인 것을 볼 수 있다.
[root@NTNX-BEAST-1 ~]# netstat -tnlp | egrep tcp.*3261 Proto ... Local Address Foreign Address State PID/Program name ... tcp ... 127.0.0.1:3261 0.0.0.0:* LISTEN 8044/python ...
QEMU는 iSCSI 타깃 포탈로 iSCSI 리디렉터를 사용하여 설정된다. 로그인 요청 시 리디렉터는 헬시 스타게이트(로컬 스타게이트 선호)로 iSCSI 로그인 리디렉트를 수행한다.
 iSCSI 멀티-패싱 – 정상 상태 (iSCSI Multi-pathing - Normal State)
iSCSI 멀티-패싱 – 정상 상태 (iSCSI Multi-pathing - Normal State)
선호하는 컨트롤러 유형은 virtio-scsi(SCSI 디바이스의 기본값)이다. IDE 디바이스는 가능하지만 대부분의 시나리오에 권장되지 않는다. virtio를 Windows와 함께 사용하려면 virto 드라이버, 뉴타닉스 모빌리티 드라이버 또는 뉴타닉스 게스트 툴이 설치되어야 한다. 최신 Linux 배포판에는 virtio가 사전 설치되어 제공된다.
액티브 스타게이트가 다운되는 경우 (따라서 NOP OUT 명령에 응답하지 않는 경우), iSCSI 리디렉터는 로컬 스타게이트를 비정상으로 표시한다. QEMU가 iSCSI 로그인을 재시도하면 리디렉터는 로그인을 다른 헬시 스타게이트로 리디렉트한다.
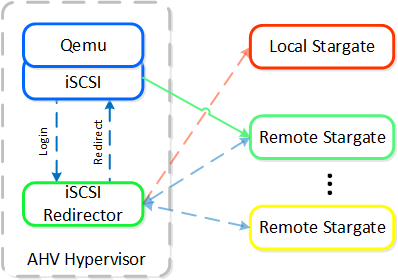 iSCSI 멀티-패싱 - 로컬 CVM 다운 (iSCSI Multi-pathing - Local CVM Down)
iSCSI 멀티-패싱 - 로컬 CVM 다운 (iSCSI Multi-pathing - Local CVM Down)
로컬 CVM의 스타게이트가 다시 사작되면 (그리고 NOP OUT 명령에 응답을 시작하면), 원격 스타게이트는 잠시 멈춘 후에 원격 iSCSI 세션에 대한 모든 연결을 종료한다. 그런 다음 QEMU는 iSCSI 로그인을 다시 시도하고 로컬 스타게이트로 리디렉트된다.
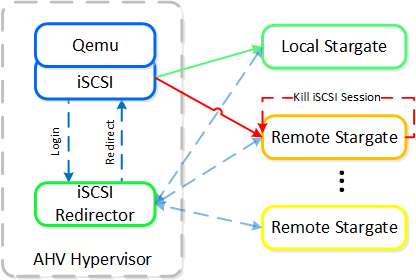 iSCSI 멀티-패싱 - 로컬 CVM 백업 (iSCSI Multi-pathing - Local CVM Back Up
iSCSI 멀티-패싱 - 로컬 CVM 백업 (iSCSI Multi-pathing - Local CVM Back Up
기존 I/O 경로
모든 하이퍼바이저 및 OS와 마찬가지로 일반적인 액티비티를 수행하기 위해 상호작용하는 유저 및 커널 스페이스 컴포넌트가 혼합되어 있다. 다음 내용을 읽기 전에 '유저 대 커널 스페이스'섹션을 읽고 서로 상호 작용하는 방법에 대해 자세히 알아보는 것이 좋다.
VM이 I/O를 수행하면 다음을 수행한다 (명확성을 위해 일부 단계를 제외).
- VM의 OS가 가상 디바이스에 SCSI 명령을 수행한다.
- virtio-scsi가 요청을 받아 게스트 메모리에 저장한다.
- 요청은 QEMU 메인 루프에 의해 처리된다.
- Libiscsi는 각 요청을 검사하고 전달한다.
- 네트워크 계층은 요청을 로컬 CVM으로 전달한다 (로컬 CVM이 가용하지 않으면 원격 노드의 CVM으로 전달한다).
- 스타게이트가 요청을 처리한다.
다음은 이 샘플 흐름을 보여준다.
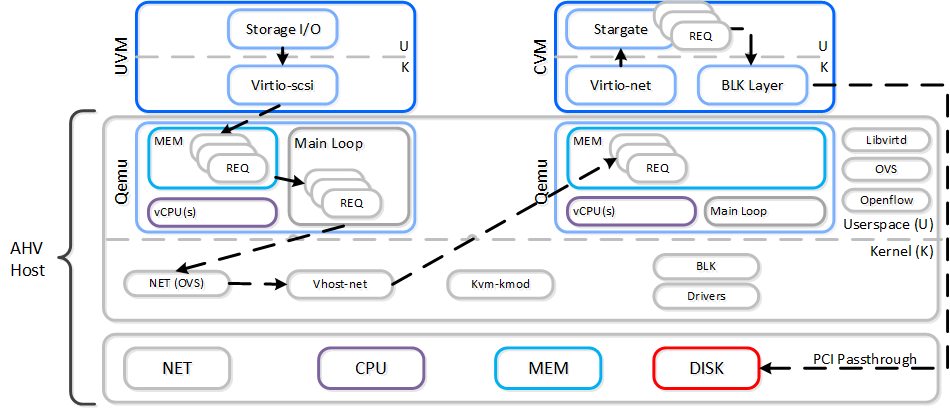 AHV VirtoIO 데이터 경로 – 클래식 (AHV VirtIO Data Path - Classic)
AHV VirtoIO 데이터 경로 – 클래식 (AHV VirtIO Data Path - Classic)
AHV 호스트를 살펴보면 qemu-kvm이 로컬 브리지와 IP를 사용하여 헬시 스타게이트와 세션을 설정한 것을 볼 수 있다. 외부 통신을 위해 외부 호스트와 스타게이트 IP가 사용된다. NOTE: 디스크 디바이스 당 하나의 세션이 있다 (PID 24845 참조).
[root@NTNX-BEAST-1 log]# netstat -np | egrep tcp.*qemu Proto ... Local Address Foreign Address State PID/Program name tcp ... 192.168.5.1:50410 192.168.5.254:3261 ESTABLISHED 25293/qemu-kvm tcp ... 192.168.5.1:50434 192.168.5.254:3261 ESTABLISHED 23198/qemu-kvm tcp ... 192.168.5.1:50464 192.168.5.254:3261 ESTABLISHED 24845/qemu-kvm tcp ... 192.168.5.1:50465 192.168.5.254:3261 ESTABLISHED 24845/qemu-kvm ...
본 경로에서 메인 루프가 단일 스레드이고 libiscsi가 모든 SCSI 명령을 검사하므로 약간의 비효율성이 있다.
프로도 I/O 경로 (AHV 터보 모드로 알려짐)
스토리지 기술이 계속 발전하고 더욱 효율적으로 되므로 뉴타닉스도 그렇게 해야 한다. 뉴타닉스가 AHV와 뉴타닉스 스택을 완전히 컨트롤한다는 사실을 감안할 때 이것은 기회의 영역이다.
간단히 말해서 프로도(Frodo)는 AHV에 매우 최적화된 I/O 경로로 처리량을 높이고 레이턴시를 줄이며 CPU 오버헤드를 줄일 수 있다.
Note
Pro tip
프로도는 AOS 5.5.x 이상의 버전에서 VM의 전원이 커질 때 디폴트로 활성화된다.
VM이 I/O를 수행하면 다음을 수행한다 (명확성을 위해 일부 단계를 제외).
- VM의 OS가 가상 디바이스에 SCSI 명령을 수행한다.
- virtio-scsi가 요청을 받아 게스트 메모리에 저장한다.
- 요청은 프로도에 의해 처리된다.
- 커스텀 Libiscsi가 iSCSI 헤더를 추가하고 전달한다.
- 네트워크 계층은 요청을 로컬 CVM으로 전달한다 (로컬 CVM이 가용하지 않으면 원격 노드의 CVM으로 전달한다).
- 스타게이트가 요청을 처리한다.
다음은 이 샘플 흐름을 보여준다.
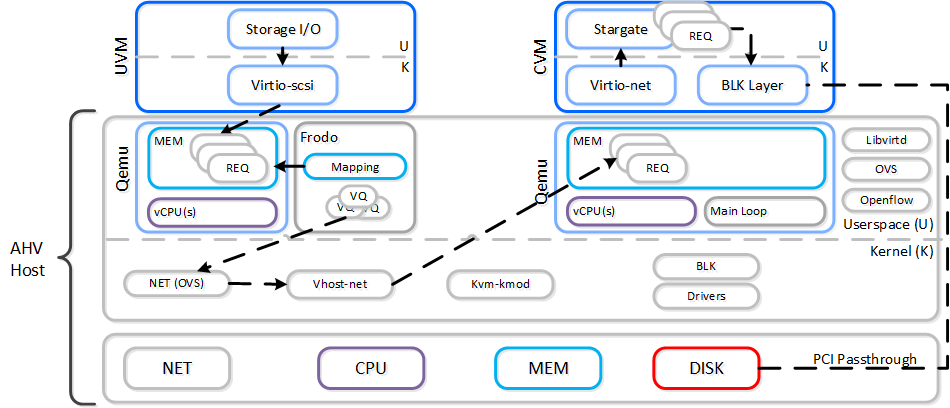 AHV VirtIO 데이터 경로 - 프로도 (AHV VirtIO Data Path - Frodo)
AHV VirtIO 데이터 경로 - 프로도 (AHV VirtIO Data Path - Frodo)
다음 경로는 몇 가지 주요 차이점을 제외하고는 기존 I/O 경로와 유사하다.
- QEMU 메인 루프가 프로도(vhost-user-scsi)로 대체되었다.
- 프로도는 여러 가상 큐(VQ)를 게스트에 노출한다 (vCPU 당 1개).
- 다중 vCPU VM을 위해 여러 스레드를 활용한다.
- Libiscsi는 훨씬 더 가벼운 뉴타닉스 버전으로 대체되었다.
게스트는 이제 디스크 디바이스에 대한 큐가 여러 개 있고 성능이 향상되었다는 것만 볼 수 있다. 경우에 따라 I/O를 수행하기 위한 CPU 오버헤드가 25% 감소하고 QEMU에 비해 성능이 최대 3배까지 향상되었다. 다른 하이퍼바이저와 비교하여 I/O를 수행하기 위한 CPU 오버헤드가 최대 3배까지 감소했다.
AHV 호스트를 살펴보면 실행 중인 각 VM(qemu-kvm-process)에 대한 프로도 프로세스를 볼 수 있다.
[root@drt-itppc03-1 ~]# ps aux | egrep frodo ... /usr/libexec/qemu-kvm ... -chardev socket,id=frodo0,fd=3 \ -device vhost-user-scsi-pci,chardev=frodo0,num_queues=16... ... /usr/libexec/frodo ... 127.0.0.1:3261 -t iqn.2010-06.com.nutanix:vmdisk... ...
Note
Pro tip
프로도의 다중 스레드/연결을 활용하려면 전원이 켜질 때 VM에 2개 이상의 vCPU가 있어야 한다.
다음과 같은 특징이 있다.
- 1 vCPU UVM
- 디스크 디바이스 당 1개의 프로도 스레드/세션.
- >= 2vCPU UVM
- 디스크 디바이스 당 2개의 프로도 스레드/세션
다음에서 프로도가 로컬 브리지와 IP를 사용하여 헬시 스타게이트와 세션을 설정한 것을 볼 수 있다. 외부 통신에는 외부 호스트와 스타게이트 IP가 사용된다.
[root@NTNX-BEAST-1 log]# netstat -np | egrep tcp.*frodo Proto ... Local Address Foreign Address State PID/Program name tcp ... 192.168.5.1:39568 192.168.5.254:3261 ESTABLISHED 42957/frodo tcp ... 192.168.5.1:39538 192.168.5.254:3261 ESTABLISHED 42957/frodo tcp ... 192.168.5.1:39580 192.168.5.254:3261 ESTABLISHED 42957/frodo tcp ... 192.168.5.1:39592 192.168.5.254:3261 ESTABLISHED 42957/frodo ...
IP 주소 관리
아크로폴리스 IP 주소 관리(IPAM) 솔루션은 DHCP 범위를 설정하고 VM에 주소를 할당하는 기능을 제공한다. 이것은 VXLAN 및 OpenFlow 규칙을 활용하여 DHCP 요청을 가로채고 DHCP response에 응답한다.
다음은 아크로폴리스 리더가 로컬로 실행되는 뉴타닉스 IPAM 솔루션을 사용한 DHCP 요청의 예이다.
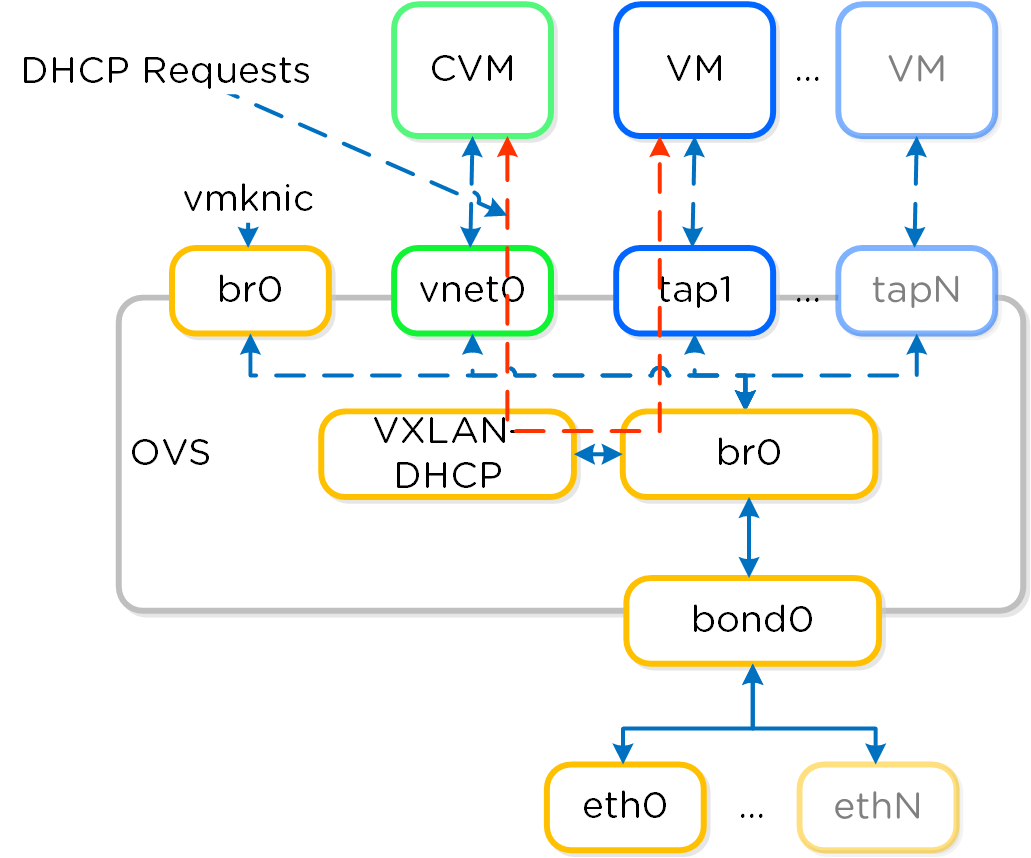 IPAM - 로컬 아크로폴리스 리더 (IPAM - Local Acropolis Leader)
IPAM - 로컬 아크로폴리스 리더 (IPAM - Local Acropolis Leader)
아크로폴리스 리더가 원격으로 실행 중인 경우 동일한 VXLAN 터널을 활용하여 네트워크를 통한 요청을 처리한다.
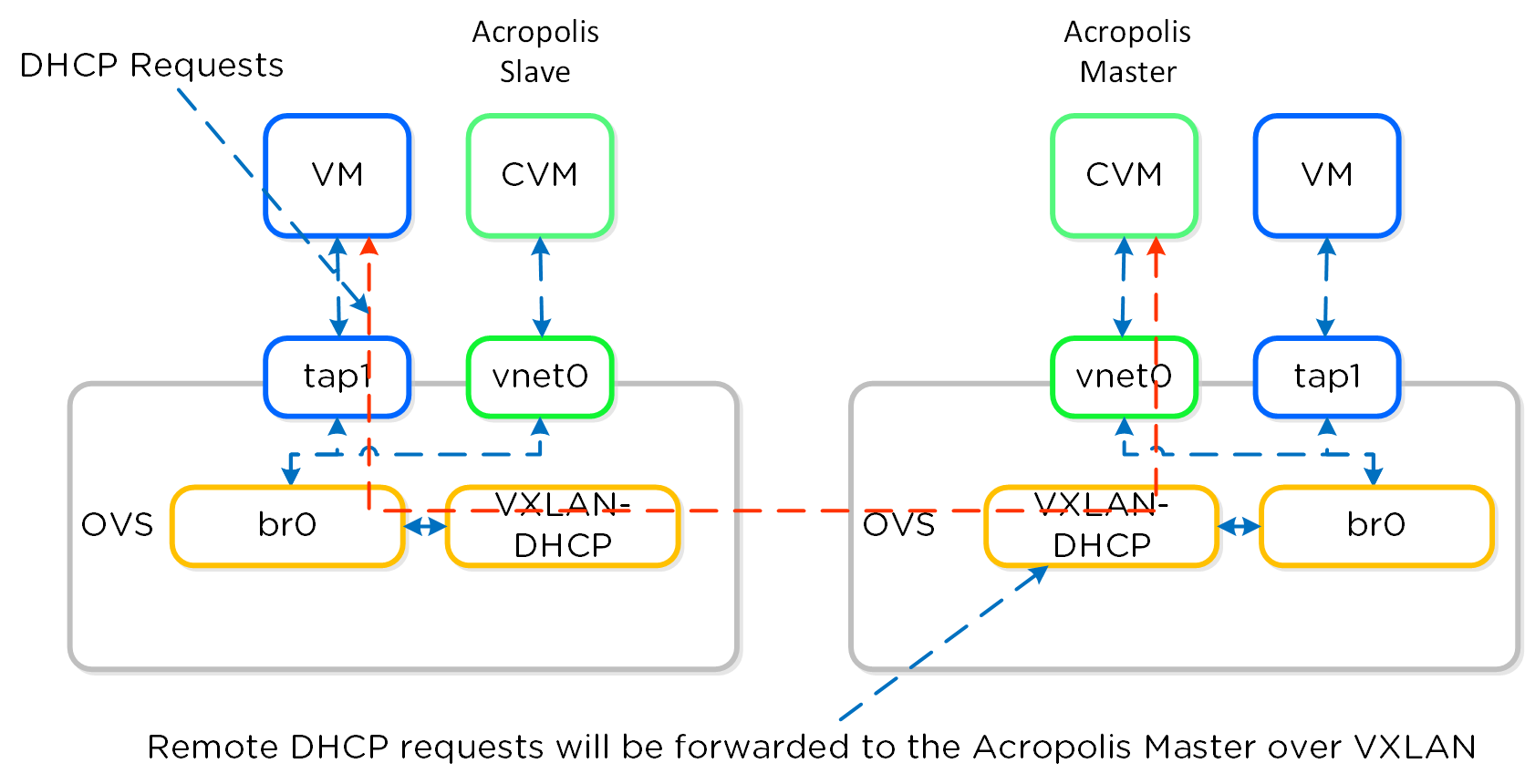 IPAM - 원격 아크로폴리스 리더 (IPAM - Remote Acropolis Leader)
IPAM - 원격 아크로폴리스 리더 (IPAM - Remote Acropolis Leader)
기존의 DHCP/IPAM 솔루션은 '관리되지 않는(Unmanaged)' 네트워크 시나리오에서도 활용할 수 있다.
VM 고가용성(HA)
AHV VM HA는 호스트 또는 블록 장애 시 VM 가용성을 보장하기 위해 구축된 기능이다. 호스트 장애가 발생하면 해당 호스트에서 이전에 실행된 VM이 클러스터 전체의 다른 정상 노드에서 다시 시작된다. 아크로폴리스 리더는 정상 호스트에서 VM을 다시 시작한다.
아크로폴리스 리더는 모든 클러스터 호스트에서 libvirt에 대한 연결을 모니터링하여 호스트 헬스를 추적한다.
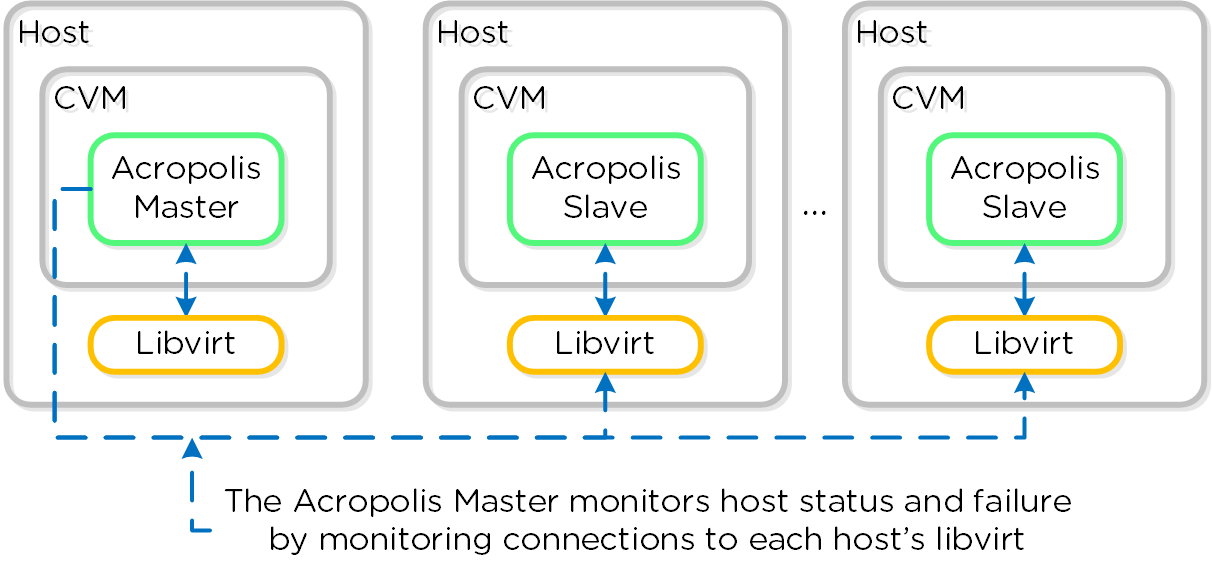 HA - 호스트 모니터링 (HA - Host Monitoring)
HA - 호스트 모니터링 (HA - Host Monitoring)
libvirt 연결이 끊어지면 HA 재시작에 대한 카운트다운이 시작된다. 제한 시간 내에 libvirt 연결이 다시 설정되지 않으면 아크로폴리스는 연결이 끊어진 호스트에서 실행 중인 VM을 다시 시작한다. 이 경우 120초 내에 VM을 다시 시작해야 한다.
아크로폴리스 리더가 분할, 분리 또는 실패하는 경우 클러스터의 정상 부분에서 새로운 아크로폴리스 리더로 선출된다. 클러스터가 분할되면(e.g. X 노드가 다른 Y 노드와 통신할 수 없음) 쿼럼이 있는 쪽이 그대로 유지되고 해당 호스트에서 VM이 다시 시작된다.
VM HA에는 두 가지 주요 모드가 있다.
- 디폴트 (Default)
- 이 모드는 설정이 필요하지 않으며 AHV 기반 뉴타닉스 클러스터를 설치할 때 기본적으로 포함된다. AHV 호스트를 사용할 수 없게 되면 장애가 발생한 호스트에서 실행 중이던 VM은 사용 가능한 자원에 따라 나머지 호스트에서 다시 시작된다. 나머지 호스트에 충분한 자원이 없는 경우 모든 실패한 VM이 다시 시작되는 것은 아니다.
- 보장 (Guarantee)
- 설정이 필요한 모드로 호스트 장애 시 장애가 발생한 모든 VM이 AHV 클러스터의 다른 호스트에서 다시 시작될 수 있도록 클러스터의 AHV 호스트 전체에 공간을 예약한다. 보장 모드를 활성화하려면 아래 그림과 같이 'Enable HA' 체크 박스를 선택한다. 그러면 예약된 메모리 용량과 허용할 수 있는 AHV 호스트 장애 수를 표시하는 메시지가 나타난다.
자원 예약
VM HA에 보장 모드를 사용하면 시스템은 VM에 대한 호스트 자원을 예약한다. 예약된 자원의 양은 다음과 같이 요약된다.
- 모든 컨테이너가 RF2(FT1)인 경우
- 단일 '호스트' 자원
- RF3(FT2) 컨테이너를 포함하는 경우
- 두 개 '호스트' 자원
호스트의 메모리 용량이 균일하지 않을 경우 시스템은 호스트 당 예약할 용량을 결정할 때 가장 큰 호스트의 메모리 용량을 사용한다.
Note
AOS 5.0 버전 이후의 자원 예약 (Post 5.0 Resource Reservations)
AOS 5.0 이전에는 호스트 및 세그먼트 기반 예약을 모두 지원했다. AOS 5.0 이상에서는 이제 보장 HA 모드가 선택되었을 때 자동으로 구현되는 세그먼트 기반 예약만 지원한다.
예약 세그먼트는 클러스터의 모든 호스트에 지원 예약을 분산한다. 이 시나리오에서 각 호스트는 HA 예약의 일부를 공유한다. 이렇게 하면 호스트 장애 발생 시 전체 클러스터에 충분한 페일오버 용량이 있으므로 VM을 다시 시작할 수 있다.
그림은 예약된 세그먼트가 있는 예제 시나리오를 보여준다.
 HA - 세그먼트 예약 (HA - Reserved Segment)
HA - 세그먼트 예약 (HA - Reserved Segment)
호스트 장애가 발생하면 나머지 정상 호스트의 클러스터 전체에서 VM이 다시 시작된다.
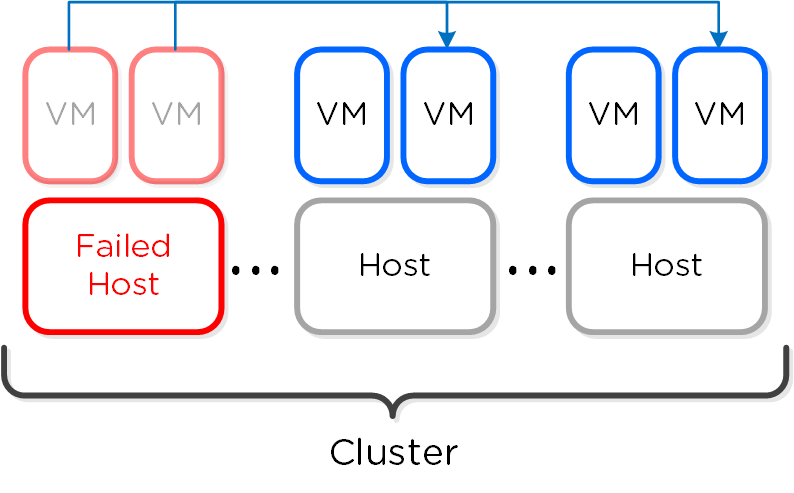 HA - 세그먼트 예약 - 페일오버 (HA - Reserved Segment - Fail Over)
HA - 세그먼트 예약 - 페일오버 (HA - Reserved Segment - Fail Over)
Note
예약 세그먼트 계산 (Reserved segments calculation)
시스템은 자동으로 총 예약 세그먼트 수와 호스트 당 예약 수를 계산한다.
예약을 찾는 것은 Knapsack이라는 잘 알려진 문제와 유사하다. 최적해를 찾는 문제는 NP-hard(지수함수) 문제이지만 일반적인 경우에 휴리스틱 솔루션이 최적해에 근접한 솔루션을 제공한다. 뉴타닉스는 MTHM으로 불리는 알고리즘을 구현한다. 뉴타닉스는 배치 알고리즘을 지속적으로 개선할 예정이다.
AHV 관리
명령 참조
OVS에서만 10GbE 링크 활성화 (Enable 10GbE links only on OVS)
설명: 로컬 호스트에 대해 bon0에서만 10g 활성화
manage_ovs --interfaces 10g update_uplinks
설명: 전체 클러스터에 대한 OVS 업링크 표시
allssh "manage_ovs --interfaces 10g update_uplinks"
OVS 업링크 표시 (Show OVS uplinks)
설명: 로컬 호스트에 대한 OVS 업링크 표시
manage_ovs show_uplinks
설명: 전체 클러스터에 대한 OVS 업링크 표시
allssh "manage_ovs show_uplinks"
OVS 인터페이스 표시 (Show OVS interfaces)
설명: 로컬 호스트에 대한 OVS 인터페이스 표시
manage_ovs show_interfaces
설명: 전체 클러스터에 대한 OVS 인터페이스 표시
allssh "manage_ovs show_interfaces"
OVS 스위치 정보 표시 (Show OVS switch information)
설명: 스위치 정보 표시
ovs-vsctl show
OVS 브릿지 목록 출력 (List OVS bridges)
설명: 브릿지 목록 출력
ovs-vsctl list br
OVS 브릿지 정보 표시 (Show OVS bridge information)
설명: OVS 포트 정보 표시
ovs-vsctl list port br0 ovs-vsctl list port bond
OVS 인터페이스 정보 표시 (Show OVS interface information)
설명: 인터페이스 정보 표시
ovs-vsctl list interface br0
브릿지에서 포트/인터페이스 표시 (Show ports / interfaces on bridge)
설명: 브릿지에서 포트 표시
ovs-vsctl list-ports br0
설명: 브릿지에서 ifaces 표시
ovs-vsctl list-ifaces br0
OVS 브릿지 생성 (Create OVS bridge)
설명: 브릿지 생성
ovs-vsctl add-br bridge
브릿지에 포트 추가 (Add ports to bridge)
설명: 브릿지에 포트 추가
ovs-vsctl add-port bridge port
설명: 브릿지에 본드 포트 추가
ovs-vsctl add-bond bridge port iface
OVS 본드 상세 정보 표시 (Show OVS bond details)
설명: 본드 상세 정보 표시
ovs-appctl bond/show bond
예제:
ovs-appctl bond/show bond0
본드 모드 및 본드에서 LACP 설정 (Set bond mode and configure LACP on bond)
설명: 포트에서 LACP 활성화
ovs-vsctl set port bond lacp=active/passive
설명: bond0에 대해 모든 호스트에서 활성화
for i in `hostips`;do echo $i; ssh $i source /etc/profile > /dev/null 2>&1; ovs-vsctl set port bond0 lacp=active;done
본드에서 LACP 상세 정보 표시 (Show LACP details on bond)
설명: LACP 상세 정보 표시
ovs-appctl lacp/show bond
본드 모드 설정 (Set bond mode)
설명: 포트에서 본드 모드 설정
ovs-vsctl set port bond bond_mode=active-backup, balance-slb, balance-tcp
OpenFlow 정보 표시 (Show OpenFlow information)
설명: OVS OpenFlow 상세 정보 표시
ovs-ofctl show br0
설명: OpenFlow 규칙 표시
ovs-ofctl dump-flows br0
QEMU PID 및 TOP 정보 가져오기 (Get QEMU PIDs and top information)
설명: QEMU PID 가져오기
ps aux | grep qemu | awk '{print $2}'
설명: 특정 PID에 대한 TOP 메트릭스 가져오기
top -p PID
QEMU 프로세스를 위한 액티브 스타게이트 가져오기 (Get active Stargate for QEMU processes)
설명: 각 QEMU 프로세스에 대한 스토리지 I/O를 위한 액티브 스타게이트 가져오기
netstat –np | egrep tcp.*qemu
메트릭스 및 임계 값
내용 추가 예정입니다.
장애 처리 및 고급 관리
iSCSI 리디렉터 로그 체크 (Check iSCSI Redirector Logs)
설명: 모든 호스트의 iSCSI 리디렉터 로그 체크
for i in `hostips`; do echo $i; ssh root@$i cat /var/log/iscsi_redirector;done
단일 호스트 예제:
Ssh root@HOSTIP Cat /var/log/iscsi_redirector
CPU steal (stolen CPU) 모니터링 [Monitor CPU steal (stolen CPU)]
설명: CPU steal time (stolen CPU) 모니터링
TOP을 실행하고 %st를 찾음 (아래에서 굵게 표시)
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni, 96.4%id, 0.0%wa, 0.0%hi, 0.1%si, **0.0%st**
VM 네트워크 자원 통계 모니터링 (Monitor VM network resource stats)
설명: VM 자원 통계 모니터링
virt-top 실행
Virt-top
Book of vSphere
뉴타닉스는 VMware ESXi를 지원하므로 vSphere에서 가상 환경을 실행하면서 뉴타닉스 분산 스토리지 패브릭을 활용할 수 있다. 또한 뉴타닉스는 VMware 가상 인프라를 관리하기 위한 단일 관리 창을 제공하여 프리즘에서 직접 ESXi VM 생성 및 관리를 지원한다.
본 BOOK에서는 VMware ESXi에서 실행되는 뉴타닉스의 상세한 기술적인 내용을 살명한다.
VMware vSphere 아키텍처
노드 아키텍처
ESXi 배포에서 컨트롤러 VM(CVM)은 VM으로 실행되고 디스크는 VMDirectPath I/O를 사용하여 제공된다. 이를 통해 전체 PCI 컨트롤러(및 연결된 디바이스)를 CVM으로 직접 전달하고 하이퍼바이저를 바이패스할 수 있다.
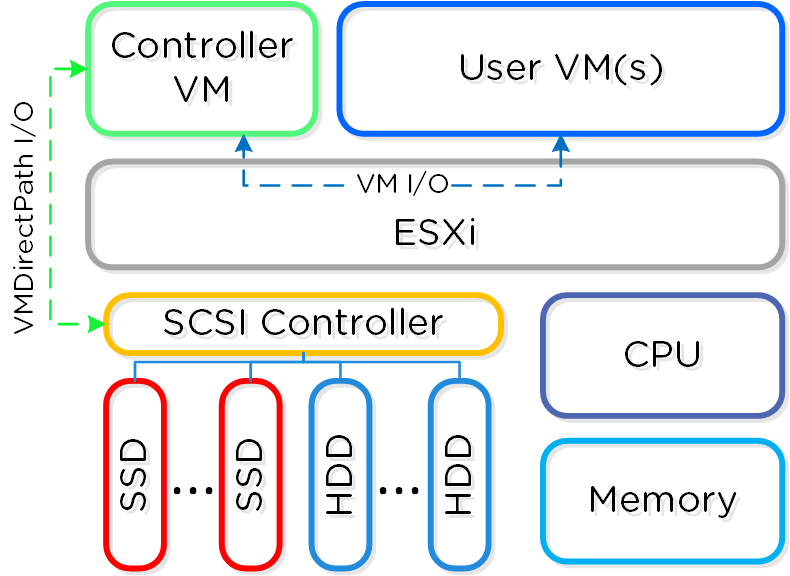 ESXi 노드 아키텍처 (ESXi Node Architecture)
ESXi 노드 아키텍처 (ESXi Node Architecture)
설정 최대값 및 확장성
다음과 같은 설정 최대값 및 확장성 제한이 적용된다.
- 최대 클러스터 크기: 64
- VM 당 최대 vCPU: 128
- VM 당 최대 메모리: 4TB
- 최대 가상 디스크 크기: 62TB
- 호스트 당 최대 VM 수: 1,024개
- 클러스터 당 최대 VM 수: 8,000개 (HA를 사용하도록 설정한 경우 데이터스토어 당 2,048개)
NOTE: vSphere 6.0 기준
Note
Pro tip
ESXi 호스트에서 벤치마킹을 수행할 때는 항상 ESXi 호스트의 전원 정책을 “High Performance”로 설정하고 테스트하여야 한다. 이는 P- 및 C- 상태를 비활성화하고 테스트 결과가 인위적으로 제한되지 않도록 한다.
네트워킹
각 ESXi 호스트에는 뉴타닉스 CVM과 호스트 간의 호스트 내 통신에 사용되는 로컬 vSwitch가 있다. 외부 통신 및 VM의 경우 표준 vSwitch(기본값) 또는 dvSwitch가 활용된다.
로컬 vSwitch(vSwitchNutanix)는 뉴타닉스 CVM과 ESXi 호스트 간의 로컬 통신을 위한 것이다. 호스트에는 이 vSwitch에 VMkernel 인터페이스(vmk1 - 192.168.5.1)가 있고 CVM에는 이 내부 스위치의 포트 그룹에 바인딩된 인터페이스(svm-iscsi-pg - 192.168.5.2)가 있다. 이것이 기본 스토리지 통신 경로이다.
외부 vSwitch는 표준 vSwitch 또는 dvSwitch 일 수 있다. 이것은 ESXi 호스트 및 CVM에 대한 외부 인터페이스와 호스트의 VM에 의해 활용되는 포트 그룹을 호스트 한다. 외부 VMkernel 인터페이스는 호스트 관리, vMotion 등에 활용된다. 외부 CVM 인터페이스는 다른 뉴타닉스 CVM과의 통신에 사용된다. 트렁크에서 VLAN이 활성화되어 있다고 가정하면 필요한 만큼 많은 포트 그룹을 만들 수 있다.
다음 그림은 vSwitch 아키텍처의 개념도를 보여준다.
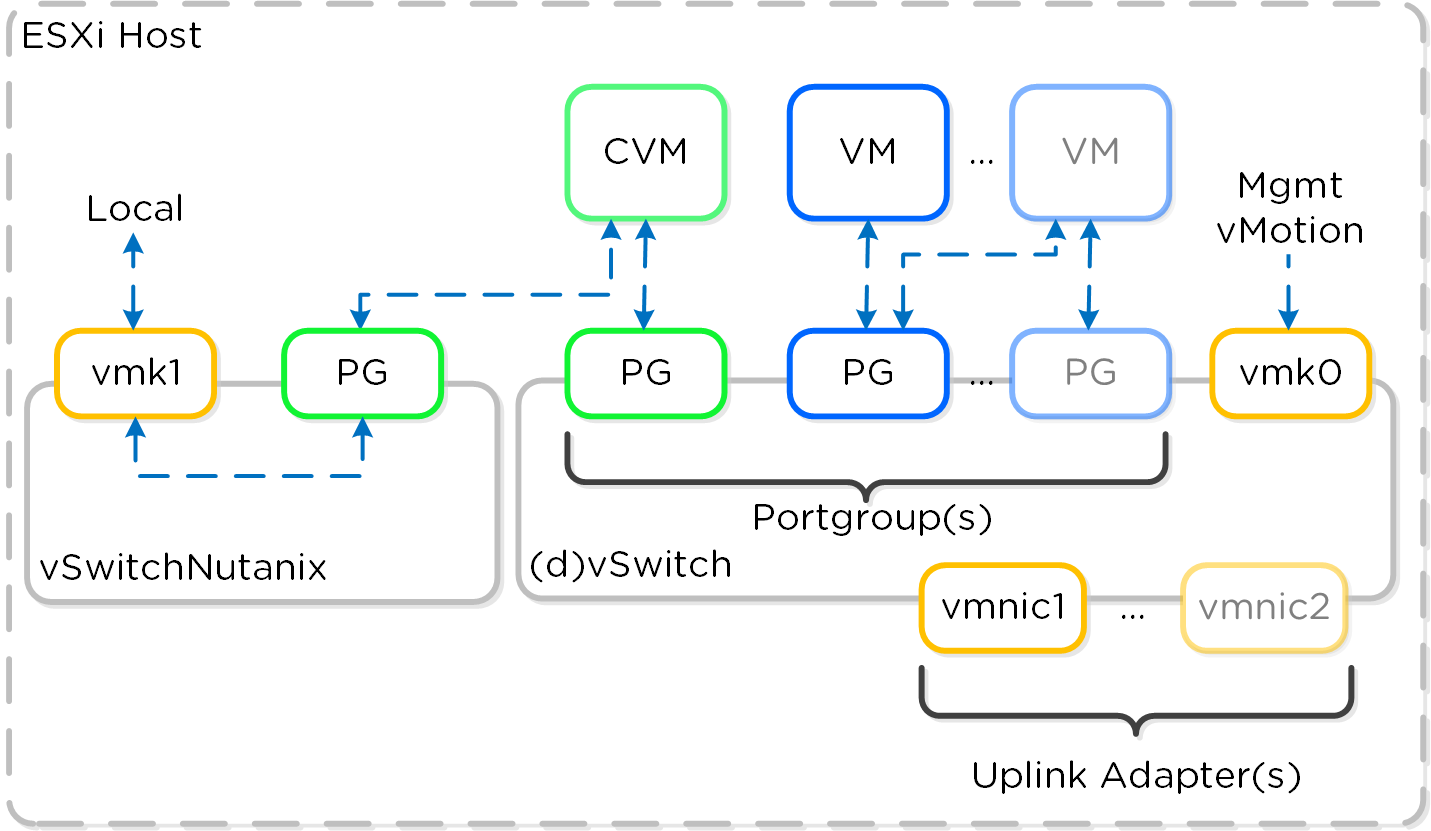 ESXi vSwitch 네트워크 개요 (ESXi vSwitch Network Overview)
ESXi vSwitch 네트워크 개요 (ESXi vSwitch Network Overview)
Note
업링크 및 티밍 정책 (Uplink and Teaming Policy)
스위치 HA의 경우 두 스위치에 듀얼 ToR 스위치와 업링크를 사용하는 것이 좋다. 기본적으로 시스템에는 액티브/패시브 모드의 업링크 인터페이스가 있다. 추가적인 네트워크 처리량을 위해 활용할 수 있는 액티브/액티브 업링크 인터페이스(e.g. vPC, MLAG, etc.)를 가질 수 있는 업스트림 스위치를 사용할 수 있다.
뉴타닉스에서 vSphere 동작 방식
어레이 오프로드 - VAAI
뉴타닉스 플랫폼은 하이퍼바이저가 특정 태스크를 어레이로 오프로드할 수 있도록 하는 VAAI(VMware APIs for Array Integration)를 지원한다. 이는 하이퍼바이저가 '중간자'가 될 필요가 없기 때문에 훨씬 더 효율적이다. 뉴타닉스는 현재 '전체 파일 클론', '빠른 파일 클론', '용량 예약' 프리미티브를 포함한 NAS 용 VAAI 프리미티브를 지원한다. 다음 사이트를 방문하면 다양한 프리미티브에 대한 설명을 참조할 수 있다: http://cormachogan.com/2012/11/08/vaai-comparison-block-versus-nas/.
전체 및 빠른 파일 클론 모두에 대해 DSF의 “빠른 클론”이 수행되는데, 이는 생성된 각 클론이 쓰기 가능한 스냅샷(re-direct on write를 사용하여) 이라는 것을 의미한다. 이러한 클론들 각각은 자신의 블록 맵을 가지는데, 이것은 체인의 깊이를 걱정할 필요가 없다는 것을 의미한다. 다음은 특정 시나리오에 VAAI를 사용할지 여부를 결정한다.
- 스냅샷이 있는 VM 복제 → VAAI가 사용되지 않음
- 전원이 꺼진 스냅샷이 없는 VM 복제 → VAAI가 사용됨
- 다른 데이터스토어/컨테이너에 VM 복제 → VAAI는 사용되지 않음
- 전원이 켜진 VM 복제 → VAAI가 사용되지 않음
이 시나리오는 VMware View에 적용된다.
- 뷰 풀 클론 (스냅샷이 있는 템플릿) → VAAI가 사용되지 않음
- 뷰 풀 클론 (스냅샷이 없는 템플릿) → VAAI가 사용됨
- 뷰 링크드 클론 (VCAI) → VAAI가 사용됨
'NFS Adaptor' 액티비티 추적 페이지를 사용하여 VAAI 작업이 수행되고 있는지 확인할 수 있다.
CVM 자동 경로 지정 (Ha.py)
이 섹션에서는 CVM '장애' 처리 방법을 설명한다 (향후 업데이트에서 컴포넌트 장애 처리 방법을 설명한다). CVM '장애'에는 사용자가 CVM의 전원을 끄는 경우, CVM 롤링 업그레이드 또는 CVM을 다운시킬 수 있는 모든 이벤트를 포함한다. DSF에는 로컬 CVM을 사용할 수 없게 되면 I/O가 클러스터의 다른 CVM에 의해 투명하게 처리되는 자동 경로 지정이라는 기능이 있다. 하이퍼바이저와 CVM은 전용 vSwitch에서 사설 192.168.5.0 네트워크를 사용하여 통신한다 (위에 자세히 설명). 이는 모든 스토리지 I/O가 CVM의 내부 사설 IP(192.168.5.2)에서 발생한다는 것을 의미한다. CVM의 외부 IP 주소는 원격 복제 및 CVM 통신에 사용된다.
다음 그림은 이것이 어떻게 보이는지에 대한 예이다.
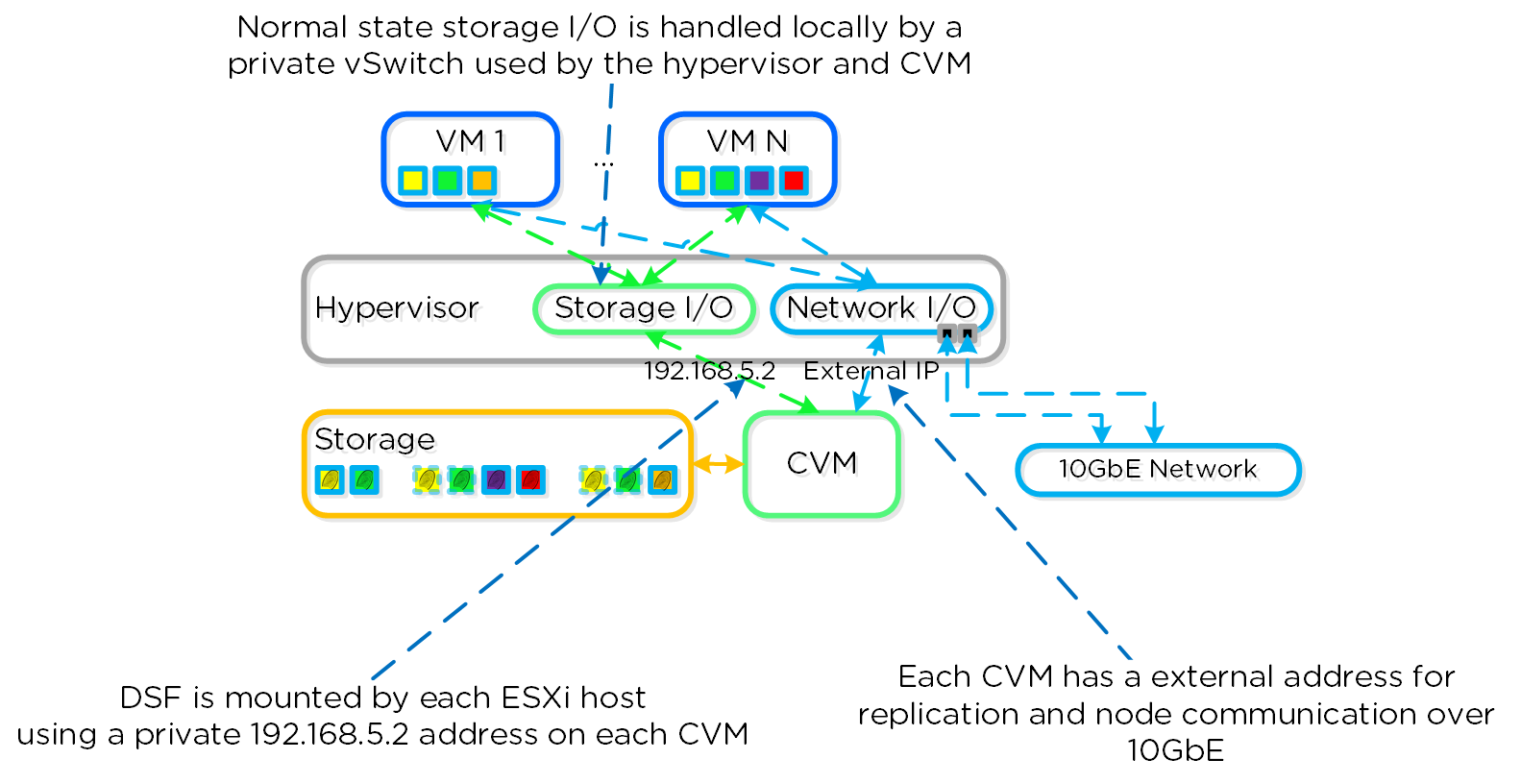 ESXi 호스트 네트워킹 (ESXi Host Networking)
ESXi 호스트 네트워킹 (ESXi Host Networking)
로컬 CVM에 장애가 발생하면 이전에 로컬 CVM에서 호스팅한 로컬 192.168.5.2 주소를 사용할 수 없다. DSF는 이러한 장애를 자동으로 감지하고 이러한 I/O를 10GbE를 통해 클러스터의 다른 CVM으로 리디렉션한다. 재라우팅은 호스트에서 실행 중인 하이퍼바이저 및 VM에 투명하게 수행된다. 즉, CVM의 전원이 꺼지더라도 VM은 계속해서 DSF에 대한 I/O를 수행할 수 있다. 로컬 CVM을 백업하고 사용할 수 있게 되면 트래픽이 원활하게 다시 전송되어 로컬 CVM에 의해 서비스된다.
다음 그림은 장애가 발생한 CVM을 찾는 방법을 그래픽으로 보여준다.
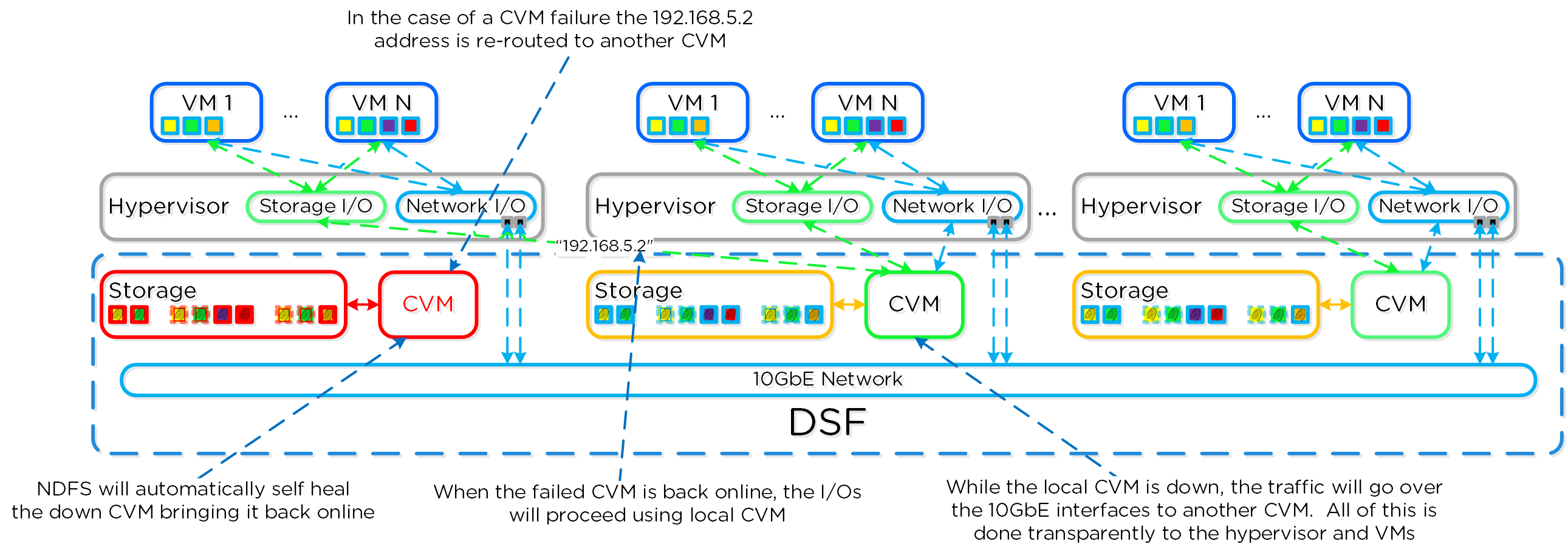 ESXi 호스트 네트워킹 - 로컬 CVM 다운 (ESXi Host Networking - Local CVM Down)
ESXi 호스트 네트워킹 - 로컬 CVM 다운 (ESXi Host Networking - Local CVM Down)
VMware ESXi 관리
VM 관리
핵심 VM 관리 작업을 하이퍼바이저 관리 인터페이스를 사용하지 않고 프리즘에서 직접 수행할 수 있다. 뉴타닉스 노드가 vCenter 인스턴스에 추가되고 vCenter 서버가 뉴타닉스 클러스터에 등록되면(Settings > vCenter Registration), 프리즘을 통해 직접 다음 작업을 수행할 수 있다.
- VM 생성, 클론, 변경, 삭제
- NIC 생성 및 삭제
- 디스크 연결 및 분리
- VM 전원 작업 (on/off, reset, suspend, resume, guest shutdown, guest restart)
- VM 콘솔 시작
- VM 게스트 툴 관리 (VMware 또는 뉴타닉스 게스트 툴)
명령 참조
ESXi 클러스터 업그레이드 (ESXi cluster upgrade)
설명: CLI 및 커스텀 오프라인 번들을 이용하여 ESXi 호스트의 자동 업그레이드 수행
- 업그레이드 오프라인 번들을 뉴타닉스 CVM에 업로드
- 뉴타닉스 CVM에 로그인
- 업그레이드 수행
cluster --md5sum=bundle_checksum --bundle=/path/to/offline_bundle host_upgrade
예제
cluster --md5sum=bff0b5558ad226ad395f6a4dc2b28597 --bundle=/tmp/VMware-ESXi-5.5.0-1331820-depot.zip host_upgrade
ESXi 호스트 서비스 재시작 (Restart ESXi host services)
설명: 점진적인 방법으로 각 ESXi 호스트 서비스 재시작
for i in `hostips`;do ssh root@$i "services.sh restart";done
'Up' 상태인 ESXi 호스트의 NIC 출력 (Display ESXi host nics in ‘Up’ state)
설명: 'Up' 상태인 ESXi 호스트의 NIC 출력
for i in `hostips`;do echo $i && ssh root@$i esxcfg-nics -l | grep Up;done
ESXi 호스트의 10GbE NIC 및 상태 출력 (Display ESXi host 10GbE nics and status)
설명: ESXi 호스트의 10GbE NIC 및 상태 출력
for i in `hostips`;do echo $i && ssh root@$i esxcfg-nics -l | grep ixgbe;done
ESXi 호스트의 액티브 어댑터 출력 (Display ESXi host active adapters)
설명: ESXi 호스트의 액티브, 스탠바이, 사용하지 않는 어댑터 출력
for i in `hostips`;do echo $i && ssh root@$i "esxcli network vswitch standard policy failover get --vswitch-name vSwitch0";done
ESXi 호스트의 라우팅 테이블 출력 (Display ESXi host routing tables)
설명: ESXi 호스트의 라우팅 테이블 출력
for i in `hostips`;do ssh root@$i 'esxcfg-route -l';done
데이터스토어의 VAAI 활성화 여부 체크 (Check if VAAI is enabled on datastore)
설명: 데이터스토어에 대해 VAAI 활성화/지원 여부 체크
vmkfstools -Ph /vmfs/volumes/Datastore Name
VIB 승인 레벨을 “Community Supported”로 설정 (Set VIB acceptance level to community supported)
설명: VIB 승인 레벨을 “CommunitySupported”로 설정하여 3rd 파티 VIB가 설치될 수 있도록 한다.
esxcli software acceptance set --level CommunitySupported
VIB 설치 (Install VIB)
설명: 시그너처를 체크하지 않고 VIB 설치
esxcli software vib install --viburl=/VIB directory/VIB name --no-sig-check
또는
esxcli software vib install --depoturl=/VIB directory/VIB name --no-sig-check
ESXi RAMDISK 공간 체크 (Check ESXi ramdisk space)
설명: ESXi RAMDISK의 여유 공간 체크
for i in `hostips`;do echo $i; ssh root@$i 'vdf -h';done
pynfs 로그 삭제 (Clear pynfs logs)
설명: 각 ESXi 호스트에서 pynfs 로그 삭제
for i in `hostips`;do echo $i; ssh root@$i '> /pynfs/pynfs.log';done
Book of Hyper-V
뉴타닉스는 Microsoft Hyper-V를 지원하므로 뉴타닉스 분산 스토리지 패브릭을 활용하면서 Hyper-V에서 가상 환경을 실행할 수 있다.
본 BOOK에서는 Hyper-V에서 실행되는 뉴타닉스의 상세한 기술적인 내용을 살명한다.
Microsoft Hyper-V 아키텍처
뉴타닉스 Hyper-V 클러스터가 생성되면 Hyper-V 호스트를 지정된 윈도우즈 액티브 디렉토리 도메인에 자동으로 조인시킨다. 그런 다음 이러한 호스트는 VM HA를 위해 페일오버 클러스터에 배치된다. 이 작업이 완료되면 각 개별 Hyper-V 호스트 및 페일오버 클러스터에 대한 AD 오브젝트가 있게 된다.
노드 아키텍처
Hyper-V 배포에서 컨트롤러 VM(CVM)은 VM으로 실행되고 디스크는 디스크 패스스루를 사용하여 제공된다.
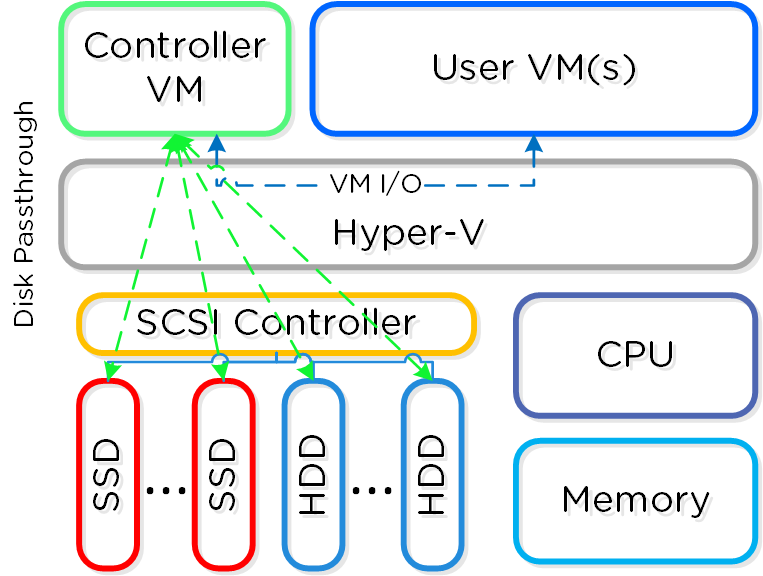 Hyper-V 노드 아키텍처 (Hyper-V Node Architecture)
Hyper-V 노드 아키텍처 (Hyper-V Node Architecture)
설정 최대값 및 확장성
다음과 같은 설정 최대값 및 확장성 제한이 적용된다.
- 최대 클러스터 크기: 64
- VM 당 최대 vCPU: 64
- VM 당 최대 메모리: 1TB
- 최대 가상 디스크 크기: 64TB
- 호스트 당 최대 VM 수: 1,024개
- 클러스터 당 최대 VM 수: 8,000개
NOTE: Hyper-V 2012 R2 기준
네트워킹
각 Hyper-V 호스트에는 뉴타닉스 CVM과 호스트 간의 호스트 내부 통신에 사용되는 내부 전용 가상 스위치가 있다. 외부 통신 및 VM의 경우 외부 가상 스위치(기본값) 또는 논리 스위치가 활용된다.
내부 스위치(InternalSwitch)는 뉴타닉스 CVM과 Hyper-V 호스트 간의 로컬 통신을 위한 것이다. 호스트는 이 내부 스위치(192.168.5.1)에 가상 이더넷 인터페이스(vEth)가 있고 CVM은 이 내부 스위치(192.168.5.2)에 vEth를 가지고 있다. 이것이 기본 스토리지 통신 경로이다.
외부 vSwitch는 표준 가상 스위치 또는 논리적 스위치일 수 있다. 이것은 Hyper-V 호스트 및 CVM의 외부 인터페이스와 호스트의 VM이 활용하는 논리 및 VM 네트워크를 호스팅한다. 외부 vEth 인터페이스는 호스트 관리, 실시간 마이그레이션 등에 활용된다. 외부 CVM 인터페이스는 다른 뉴타닉스 CVM과의 통신에 사용된다. 트렁크에서 VLAN이 활성화되어 있다고 가정하면 필요한 만큼 많은 논리 및 VM 네트워크를 만들 수 있다.
다음 그림은 가상 스위치 아키텍처의 개념도를 보여준다.
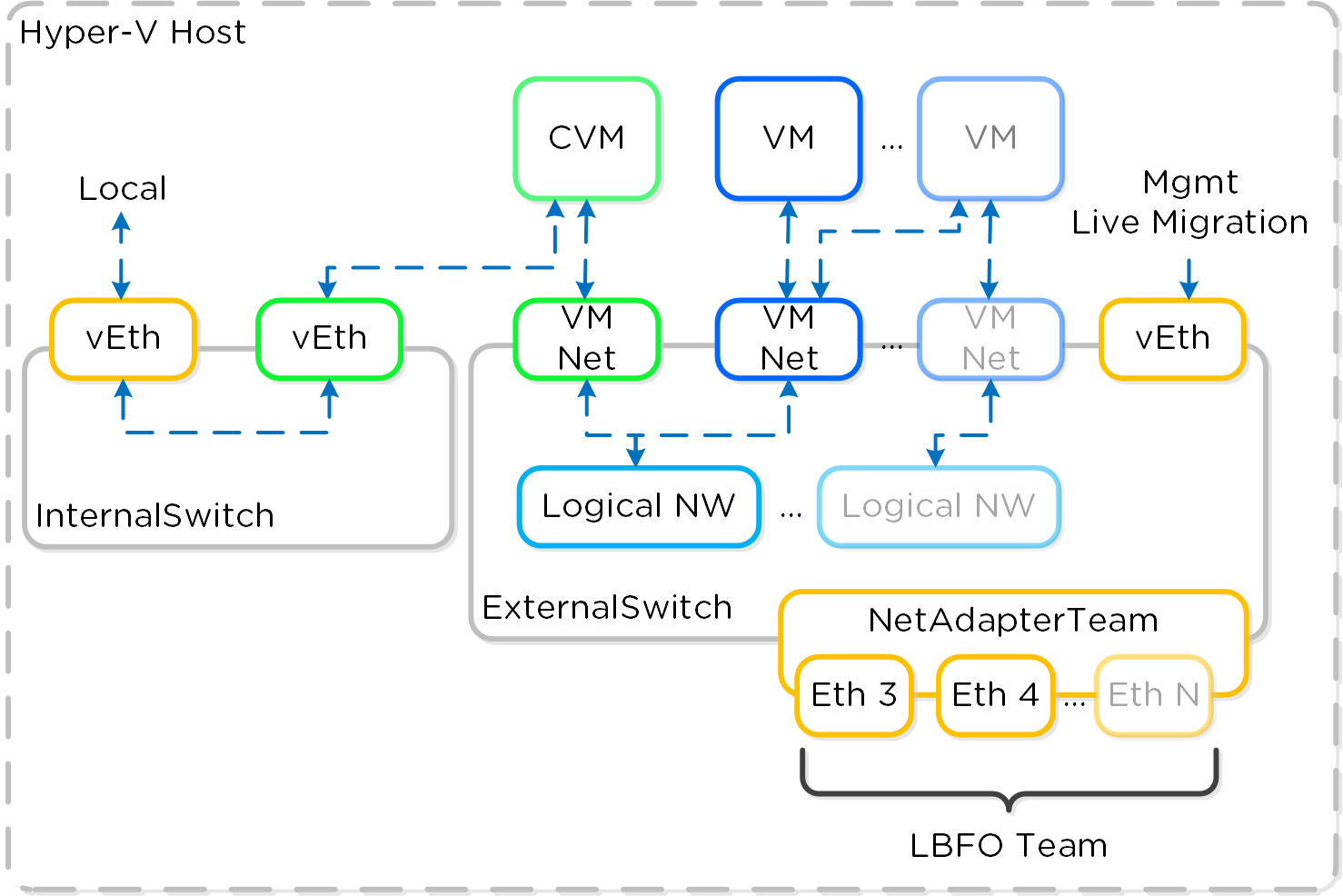 Hyper-V 가상 스위치 네트워크 개요 (Hyper-V Virtual Switch Network Overview)
Hyper-V 가상 스위치 네트워크 개요 (Hyper-V Virtual Switch Network Overview)
Note
업링크 및 티밍 정책 (Uplink and Teaming Policy)
스위치 HA의 경우 두 스위치에 듀얼 ToR 스위치와 업링크를 사용하는 것이 좋다. 기본적으로 시스템에는 특별한 구성이 필요하지 않은 스위치 독립 모드로 설정된 LBFO 팀이 있다.
뉴타닉스에서 Hyper-V 동작 방식
어레이 오프로드 - ODX
뉴타닉스 플랫폼은 하이퍼바이저가 특정 작업을 어레이로 오프로드할 수 있도록 하는 Microsoft ODX(Off-loaded Data Transfers)를 지원한다. 이는 하이퍼바이저가 '중간자'가 될 필요가 없기 때문에 훨씬 더 효율적이다. 뉴타닉스는 현재 전체 복사 및 제로잉 오퍼레이션을 포함하여 SMB 용 ODX 프리미티브를 지원한다. 그러나 “빠른 파일” 클론 오퍼레이션(쓰기 가능한 스냅샷을 이용)이 있는 VAAI와 달리 ODX 프리미티브는 동등한 기능을 가지고 있지 않으므로 전체 복사를 수행한다. 이를 고려할 때 현재 nCLI, REST 또는 PowerShell CMDlets을 통해 호출할 수 있는 네이티브 DSF 클론에 의존하는 것이 더 효율적이다. 현재 다음 오퍼레이션을 위해 ODX가 호출된다.
- DSF SMB 공유의 VM 또는 VM에서 VM으로 파일 복사
- SMB 공유 파일 복사
SCVMM 라이브러리(DSF SMB 공유)에서 템플릿을 배포 - NOTE: 짧은 이름(e.g. FQDN이 아님)을 사용하여 SCVMM 클러스터에 공유를 추가해야 한다. 이를 강제하는 쉬운 방법은 클러스터의 호스트 파일에 엔트리를 추가하는 것이다 (e.g. 10.10.10.10 nutanix-130).
ODX는 다음 오퍼레이션을 위해 호출되지 않는다.
- SCVMM을 통한 VM 복제
- SCVMM 라이브러리에서 템플릿 배포 (DSF가 아닌 SMB 공유)
- XenDesktop 클론 배포
"NFS Adaptor" 액티비티 추적 페이지를 사용하여 ODX 오퍼레이션이 수행되고 있는지 확인할 수 있다 (이 작업이 SMB를 통해 수행되는 경우에도 마찬가지임). 오퍼레이션 액티비티 쇼는 vDisk를 복사할 때 "NfsWorkerVaaiCopyDataOp"이고 디스크를 비울 때 "NfsWorkerVaaiWriteZerosOp"이다.
Microsoft Hyper-V 관리
중요 페이지
내용 추가 예정입니다.
명령 참조
여러 원격 호스트에서 명령 실행 (Execute command on multiple remote hosts)
설명: 하나 이상의 원격 호스트에서 PowerShell 실행
$targetServers = "Host1","Host2","Etc"
Invoke-Command -ComputerName $targetServers {
사용 가능한 VMQ 오프로드 체크 (Check available VMQ Offloads)
설명: 특정 호스트에 대해 사용 가능한 VMQ 오프로드 개수를 출력
gwmi –Namespace "root\virtualization\v2" –Class Msvm_VirtualEthernetSwitch | select elementname, MaxVMQOffloads
특정 접두사와 일치하는 VM에 대해 VMQ 비활성화 (Disable VMQ for VMs matching a specific prefix)
설명: 특정 VM에 대해 VMQ 비활성화
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix} | Get-VMNetworkAdapter | Set-VMNetworkAdapter -VmqWeight 0
특정 접두사와 일치하는 VM에 대해 VMQ 활성화 (Enable VMQ for VMs matching a certain prefix)
설명: 특정 VM에 대해 VMQ 활성화
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix} | Get-VMNetworkAdapter | Set-VMNetworkAdapter -VmqWeight 1
특정 접두사와 일치하는 VM의 전원 켜기 (Power-On VMs matching a certain prefix)
설명: 특정 접두사와 일치하는 VM의 전원 켜기
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix -and $_.StatusString -eq "Stopped"} | Start-VM
특정 접두사와 일치하는 VM을 종료 (Shutdown VMs matching a certain prefix)
설명: 특정 접두사와 일치하는 VM을 종료
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix -and $_.StatusString -eq "Running"}} | Shutdown-VM -RunAsynchronously
특정 접두사와 일치하는 VM을 중지 (Stop VMs matching a certain prefix)
설명: 특정 접두사와 일치하는 VM을 중지
$vmPrefix = "myVMs"
Get-VM | Where {$_.Name -match $vmPrefix} | Stop-VM
Hyper-V 호스트 RSS 설정 가져오기 (Get Hyper-V host RSS settings)
설명: Hyper-V 호스트 RSS(Receive Side Scaling) 설정 가져오기
Get-NetAdapterRss
Winsh 및 WinRM 연결 체크 (Check Winsh and WinRM connectivity)
설명: 오류가 아닌 컴퓨터 시스템 오브젝트를 반환하는 샘플 쿼리를 수행하여 Winsh 및 WinRM 연결/상태 체크
allssh "winsh "get-wmiobject win32_computersystem"
메트릭스 및 임계 겂
내용 추가 예정입니다.
장애 처리 및 고급 관리
내용 추가 예정입니다.
Part 2: Services
Book of Nutanix Clusters (NC2)
퍼블릭 클라우드를 활용한다는 것은 몇 분 안에 애플리케이션과 데이터를 온디맨드 방식으로 확장할 수 있다는 것을 의미한다. 뉴타닉스 클라우드 클러스터 (NC2)를 사용하면 단일 관리 플레인인 동일 프리즘 인터페이스에서 뉴타닉스 프라이빗 클라우드와 퍼블릭 클라우드 자원을 모두 관리할 수 있다.
본 BOOK에서는 NC2 실행과 관련된 아키텍처, 네트워킹, 스토리지 등의 기술적인 상새 사항을 설명한다.
NC2는 현재 AWS에서 지원된다. NC2는 현재 Azure에서 고객과 함께 테스트 중이며 조만간에 정식 릴리즈될 예정이다.
AWS에서 뉴타닉스 클라우드 클러스터
AWS에서 뉴타닉스 클라우드 클러스터 (NC2A)는 베어-메탈 자원을 사용하여 타깃 클라우드 환경에서 실행되는 온-디맨드 클러스터를 제공한다. 이는 이미 알고 있는 것과 같이 뉴타닉스 플랫폼의 단순성을 통해 진정한 온-디멘드 용량을 제공한다. 프로비저닝된 클러스터는 기존 AHV 클러스터처럼 나타나며 단지 클라우드 프로바이더 데이터센터에서 실행된다.
지원 환경 (Supported Configurations)
솔루션은 아래 구성에 적용할 수 있다 (목록이 불완전할 수 있으니 전체 지원 목록은 관련 문서를 참조).
Core Use Case(s):
핵심 사용 사례:
- 온-디멘드 / 버스트 용량
- 백업 / DR
- 클라우드 네이티브
- 지역 확장 및 DC 통합
- App 마이그레이션
- 기타
관리 인터페이스:
- 뉴타닉스 클러스터 포탈 - 프로비저닝
- 프리즘 센트럴 - 뉴타닉스 관리
- AWS 콘솔 - AWS 관리
지원 환경:
- 클라우드:
- AWS
- Azure (private-preview)
- EC2 메탈 인스턴스 유형:
- i3.metal
- m5d.metal
- z1d.metal
- i3en.metal
- g4dn.metal
업그레이드:
- AOS의 일부
호환되는 기능:
- AOS 기능
- AWS 서비스
핵심 용어 / 컨스트럭트 (Key terms / Constructs)
다음과 같은 핵심 용어가 이 섹션에서 사용되며 다음에 정의된다.
- 뉴타닉스 Clusters 포탈 (Nutanix Clusters Portal)
- 뉴타닉스 Clusters 포탈은 클러스터 프로비저닝 요청을 처리하고 AWS 및 프로비저닝된 호스트와의 상호 작용을 담당한다. 클러스터 별 세부 정보를 생성하고 동적 CloudFormation 스택 생성을 처리한다.
- 리전 (Region)
- 여러 AZ(사이트)가 있는 지리적 토지 또는 지역. 리전에는 둘 이상의 AZ가 있을 수 있다. 여기에는 US-Northwest 또는 US-West와 같은 리전이 포함될 수 있다.
- AZ (Availability Zone)
- AZ는 레이턴시가 작은 링크로 상호 연결된 하나 이상의 개별 데이터센터로 구성된다. 각 사이트에는 자체 리던던트 전원, 냉각, 네트워크 등이 있다. 이를 기존 코로케이션 또는 데이터센터와 비교할 때 AZ가 여러 개의 독립적인 데이터센터로 구성될 수 있으므로 보다 탄력적인 것으로 간주된다. 여기에는 US-East-1a 또는 US-West-1a와 같은 사이트가 포함될 수 있다.
- VPC
- 테넌트를 위한 AWS 클라우드의 논리적으로 격리된 세그먼트이다. 다른 환경으로부터 환경을 보호하고 격리하는 메커니즘을 제공한다. 인터넷 또는 기타 사설 네트워크 세그먼트 (다른 VPC 또는 VPN)에 노출될 수 있다.
- S3
- Amazon의 오브젝트 서비스로 S3 API를 통해 액세스되는 영구 객체 스토리지를 제공한다. 이것은 아카이브/복원에 사용된다.
- EBS
- AMI에 연결할 수 있는 영구 볼륨을 제공하는 Amazon의 볼륨/블록 서비스.
- CFT (Cloud Formation Template)
- CFT(Cloud Formation Template)은 프로비저닝을 단순화하지만 자원 및 종속성의 "스택"을 정의할 수 있다. 그러면 이 스택은 각 개별 자원 대신에 전체로 프로비저닝 될 수 있다.
클러스터 아키텍처 (Cluster Architecture)
하이-레벨의 뉴타닉스 클러스터는 AWS에서 뉴타닉스 클러스터를 프로비저닝하고 AWS와 상호 작용하기 위한 메인 인터페이스이다.
프로비저닝 프로세스는 다음과 같은 하이-레벨 단계로 요약될 수 있다.
- NC2 포탈에서 클러스터 생성
- 배포 별 입력 설정(e.g. 리전, AZ, 인스턴스 유형, VPC/서브넷 등)
- NC2 포탈은 관련 자원 생성
- 뉴타닉스 AMI에 있는 호스트 에이전트가 AWS의 뉴타닉스 클러스터에 체크인
- 모든 호스트가 가동되면 클러스터 생성
다음은 NC2A 상호 작용에 대한 하이-레벨 개요를 보여준다.
 NC2A - 개요 (NC2A - Overview)
NC2A - 개요 (NC2A - Overview)
다음은 NC2 포털 및 생성된 일부 리소스에서 취한 입력에 대한 하이-레벨 개요를 보여준다.
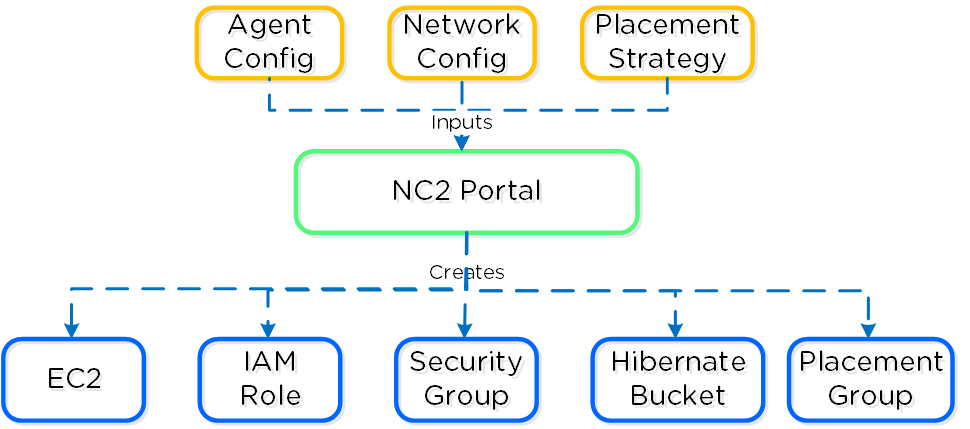 NC2 - 클러스터 오케스트레이터 입력 (NC2 - Cluster Orchestrator Inputs)
NC2 - 클러스터 오케스트레이터 입력 (NC2 - Cluster Orchestrator Inputs)
다음은 AWS에서 노드에 대한 하이-레벨 개요를 보여준다.
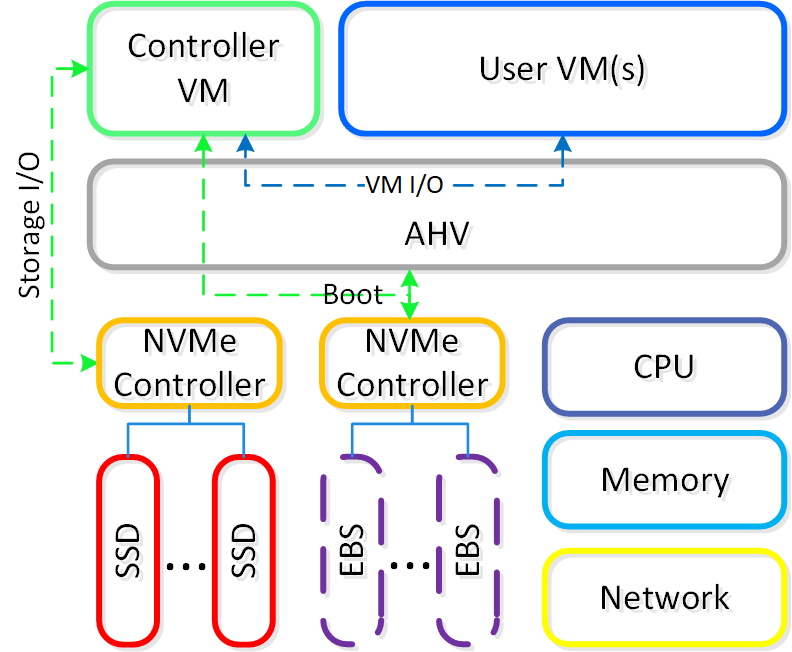 NC2A - 노드 아키텍처 (NC2A - Node Architecture)
NC2A - 노드 아키텍처 (NC2A - Node Architecture)
호스트가 베어-메탈이기 때문에 일반적인 온-프레미스 배포와 유사하게 스토리지 및 네트워크 자원을 완전히 제어할 수 있다. CVM 및 AHV 호스트 부팅에는 EBS 볼륨이 사용된다. NOTE: EBS 상호 작용과 같은 특정 자원은 AHV 호스트에서 NVMe 컨트롤러로 나타나는 AWS Nitro 카드를 통해 실행된다.
배치 정책 (Placement policy)
뉴타닉스는 AWS 가용 영역 내부에 노드를 배포할 때 파티션 배치 전략을 사용한다. 하나의 뉴타닉스 클러스터는 동일한 리전의 서로 다른 가용 영역에 걸쳐 있을 수 없지만, 서로 다른 영역 또는 리전에서 서로 복제하는 여러 뉴타닉스 클러스터를 가질 수 있다. 뉴타닉스는 최대 7개의 파티션을 사용하여 AWS 베어메탈 노드를 서로 다른 AWS 랙에 배치하고 파티션 전체에 새로운 호스트를 스트라이프한다.
AWS의 NC2는 클러스터에서 이기종 노드 유형의 결합을 지원한다. 단일 노드 유형의 클러스터를 배포한 다음 이기종 노드를 추가하여 해당 클러스터의 용량을 확장할 수 있다. 이 기능은 오리지널 노드 유형이 리전에서 실행되는 경우 클러스터를 보호하고, 필요에 따라 클러스터를 확장할 수 있는 유연성을 제공한다. 스토리지 솔루션의 크기를 적절하게 조정하려는 경우 이기종 노드 지원을 통해 더 많은 인스턴스 옵션을 선택할 수 있다.
클러스터에서 인스턴스 유형을 결합할 때, 베이스 클러스터로 배포한 오리지널 유형의 노드를 항상 3개 이상 유지해야 한다. 오리지널 유형의 노드가 3개 이상 남아 있고 클러스터 크기가 28개 노드 제한 내에서 유지되는 경우, 이기종 노드 수에 관계없이 베이스 클러스터를 확장하거나 축소할 수 있다.
다음 표와 그림은 모두 클러스터의 오리지널 인스턴스 유형을 Type A로, 호환되는 이기종 유형을 Type B로 나타낸다.
표: 지원되는 인스턴스 유형 조합
| Type A | Type B |
|---|---|
| i3.metal | i3en.metal |
| i3en.metal | i3.metal |
| z1d.metal | m5d.metal |
| m5d.metal | z1d.metal |
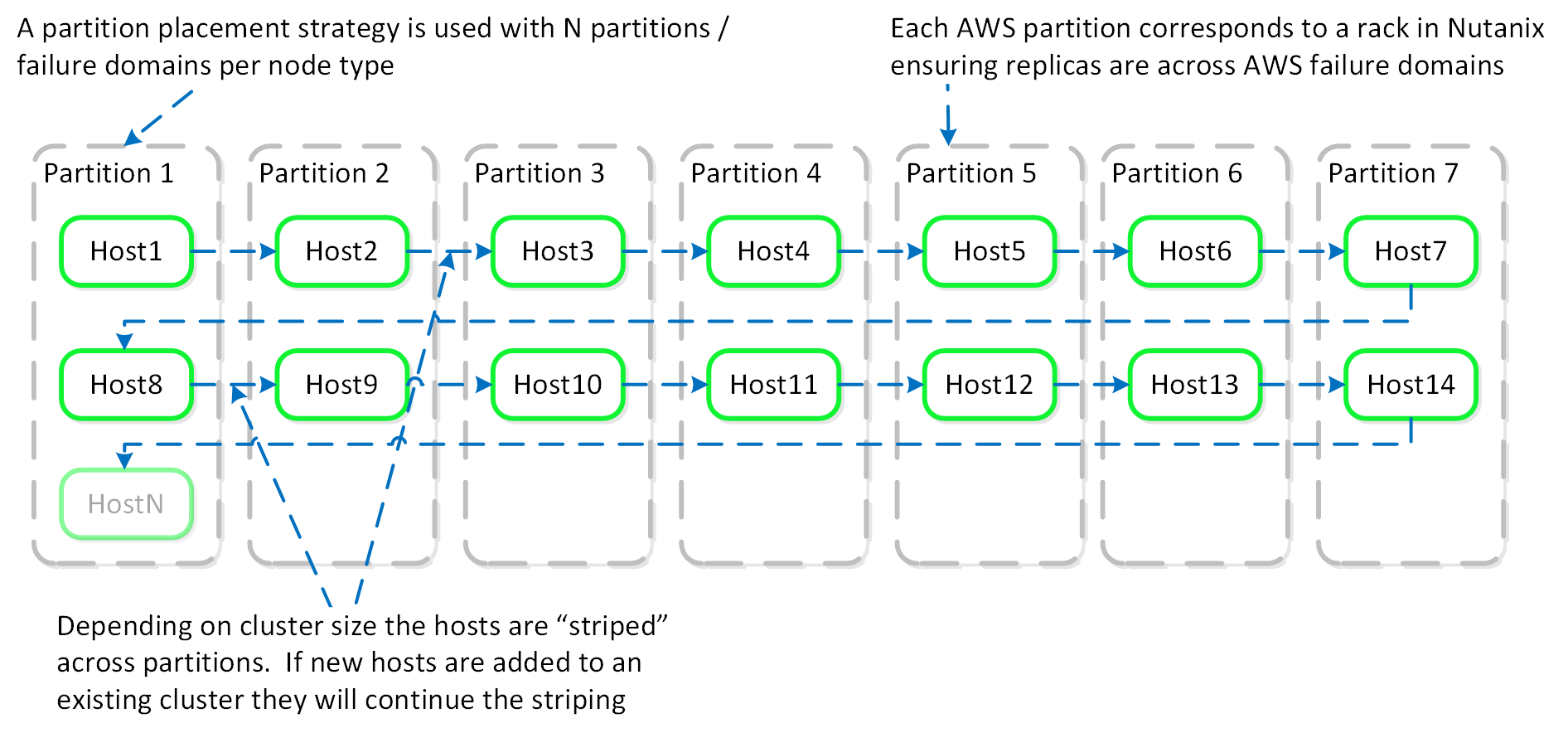 NC2A - 파티션 배치 (NC2A - Partition Placement)
NC2A - 파티션 배치 (NC2A - Partition Placement)
뉴타닉스 클러스터를 구성하면, 파티션 그룹이 뉴타닉스 랙-인식 기능에 매핑된다. AOS 스토리지는 데이터 복제본을 클러스터의 다른 랙에 기록하여 랙 장애 또는 계획된 다운타임의 경우 RF2 및 RF3 시나리오 모두에서 데이터를 계속 사용할 수 있도록 한다.
스토리지 (Storage)
AWS에서 뉴타닉스 클라우드 클러스터 용 스토리지는 두 가지 핵심 영역으로 나눌 수 있다.
- 코어/액티브
- Hibernation
코어 스토리지는 모든 뉴타닉스 클러스터에서 예상되는 것과 정확히 동일하며 "로컬" 스토리지 디바이스를 CVM으로 전달하여 스타게이트에서 활용한다.
Note
인스턴스 스토리지 (Instance Storage)
"로컬"스토리지는 AWS 인스턴스 스토어에 의해 지원되므로, 정전/노드 장애 등의 경우에 완전히 복원되지 않으므로 추가 고려 사항을 처리해야 한다.
예를 들어, 정전 또는 노드 장애가 발생한 경우 로컬 뉴타닉스 클러스터에서 스토리지는 로컬 디바이스로 유지되며, 노드/전원이 다시 온라인 상태가 되면 다시 복구된다. AWS 인스턴스 스토어의 경우에는 이에 해당되지 않는다.
대부분의 경우 전체 AZ의 전원이 끊기거나 다운될 가능성은 거의 없지만 민감한 워크로드의 경우 다음을 수행하는 것이 좋다.
- 백업 솔루션을 활용하여 S3 또는 내구성 있는 스토리지에 백업
- 다른 AZ/리전/클라우드(온-프레미스 또는 원격)의 다른 뉴타닉스 클러스터로 데이터 복제
NC2A의 고유한 기능 중 하나는 EC2 컴퓨팅 인스턴스를 스핀 다운하면서 데이터를 유지할 수 있도록 클러스터를 "최대 절전 모드"로 설정할 수 있다는 것이다. 이는 컴퓨팅 자원이 필요하지 않고 컴퓨팅 자원에 대한 비용을 계속 지불하고 싶지 않지만 데이터를 유지하고 나중에 복원할 수 있는 기능이 필요한 경우에 유용할 수 있다.
클러스터가 최대 절전 모드일 때 데이터는 클러스터에서 S3으로 백업된다. 데이터가 백업되면 EC2 인스턴스가 종료된다. 재개/복원 시 새로운 EC2 인스턴스가 프로비저닝되고 S3에서 데이터가 클러스터로 로드된다.
네트워킹 (Networking)
네트워킹은 몇 가지 핵심 영역으로 나눌 수 있다.
- 호스트/클러스터 네트워킹
- 게스트/UVM 네트워킹
- WAN/L3 네트워킹
Note
네이티브 대 오버레이 (Native vs. Overlay)
뉴타닉스는 자체 오버레이 네트워크를 실행하는 대신, 플랫폼에서 실행되는 VM이 성능 저하 없이 AWS 서비스와 기본적으로 통신할 수 있도록 AWS 서브넷에서 실행하기로 결정했다.
NC2A는 AWS VPC에 프로비저닝되며 다음은 AWS VPC에 대한 하이-레벨 개요를 보여준다.
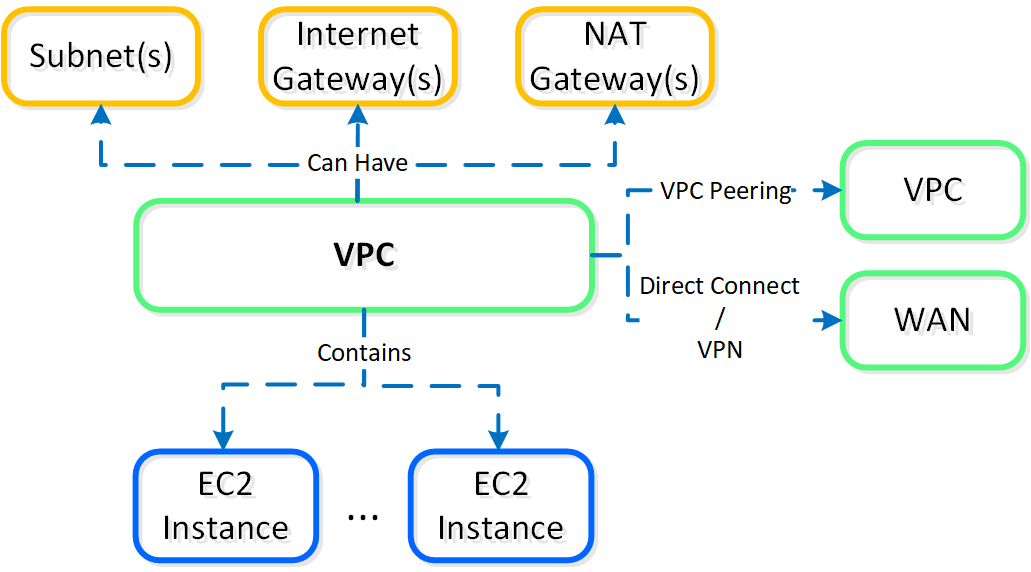 NC2A - AWS VPS (NC2A - AWS VPC)
NC2A - AWS VPS (NC2A - AWS VPC)
Note
새로운 VPC와 디폴트 VPC (New vs. Default VPC)
AWS는 각 리전에 대해 172.31.0.0/16 IP 체계로 기본 VPC/서브넷/기타를 생성한다.
회사 IP 체계에 맞는 서브넷, NAT/인터넷 게이트웨이 등이 연결된 새로운 VPC를 생성하는 것이 좋다. 이는 VPC 간(VPC 피어링) 또는 기존 WAN으로 네트워크를 확장하려는 경우에 중요하다. 또한, WAN의 모든 사이트를 다루었던 것처럼 다루어야 한다.
호스트 네트워킹 (Host Networking)
AWS의 베어 메탈에서 실행되는 호스트는 기존 AHV 호스트이므로 동일한 OVS 기반 네트워크 스택을 활용한다.
다음은 AWS AHV 호스트의 OVS 스택에 대한 하이-레벨 개요를 보여준다.
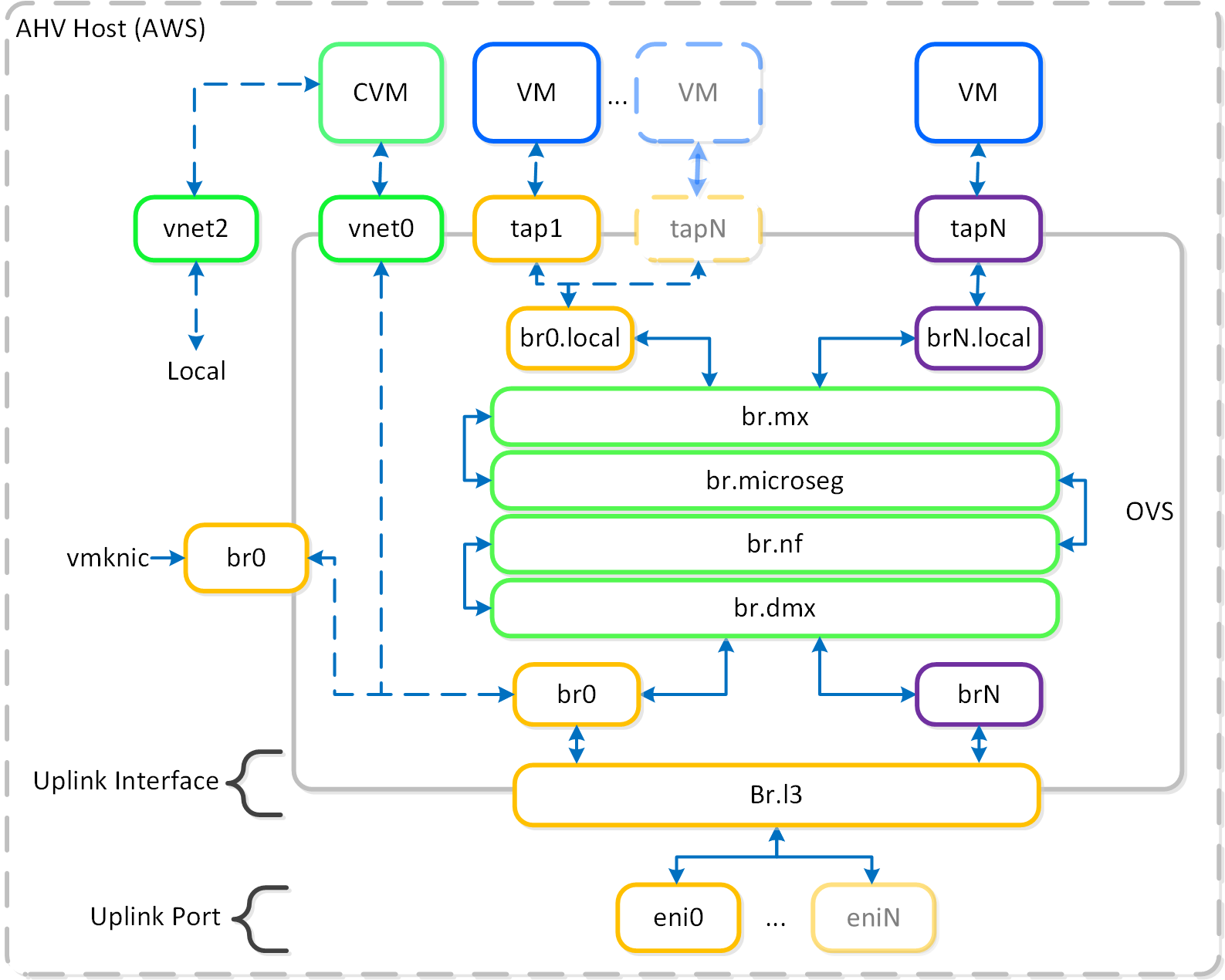 NC2A - OVS 아키텍처 (NC2A - OVS Architecture)
NC2A - OVS 아키텍처 (NC2A - OVS Architecture)
OVS 스택은 L3 업링크 브리지 추가 부분을 제외하고, 다른 AHV 호스트와 비교적 동일하다.
UVM (Guest VM) 네트워킹에는 VPC 서브넷이 사용된다. UVM 네트워크는 클러스터 생성 프로세스 중에 또는 다음 단계를 통해 생성된다.
AWS VPC 대시보드에서 'subnets'을 클릭한 다음 'Create Subne'을 클릭하고 네트워크 세부 정보를 입력한다.
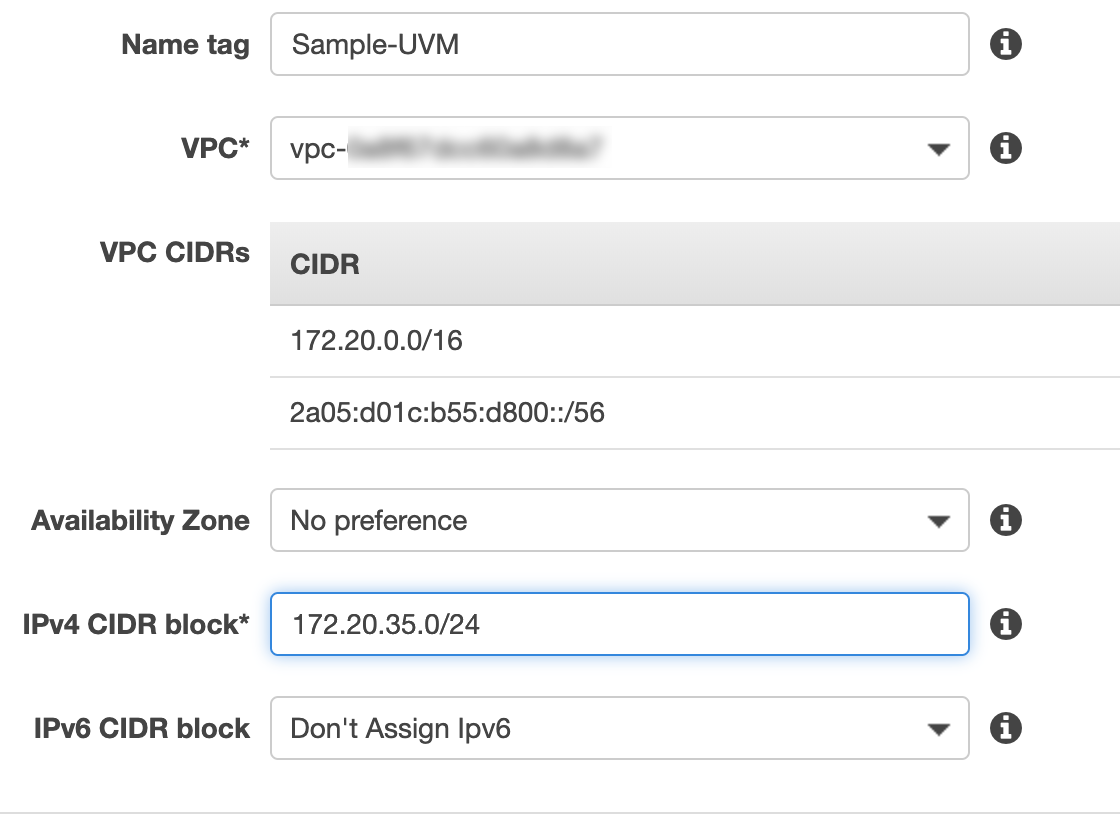 NC2A - 서브넷 생성 (NC2A - Create Subnet)
NC2A - 서브넷 생성 (NC2A - Create Subnet)
NOTE: CIDR 블록은 VPC CIDR 범위의 하위 집합이어야 한다.
서브넷은 VPC에서 라우팅 테이블을 상속한다.
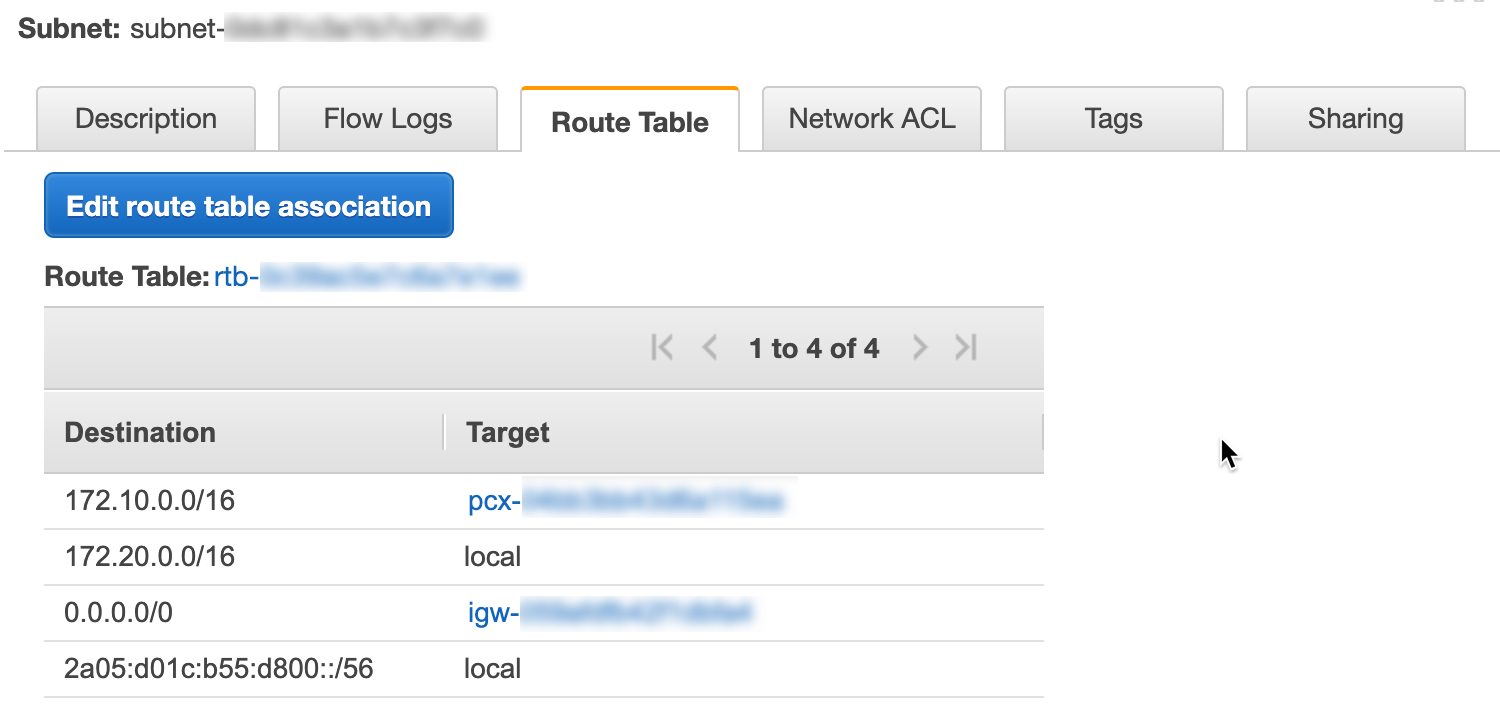 NC2A - 라우팅 테이블 (NC2A - Route Table)
NC2A - 라우팅 테이블 (NC2A - Route Table)
이 경우 피어링된 VPC의 모든 트래픽이 VPC 피어링 링크를 통해 이동하고 외부 트래픽이 인터넷 게이트웨이를 통해 이동하는 것을 볼 수 있다.
완료되면 프리즘에서 네트워크를 사용할 수 있다.
WAN/L3 네트워킹 (WAN / L3 Networking)
대부분의 경우 배포는 AWS에만 있는 것이 아니라 외부 세계(다른 VPC, 인터넷 또는 WAN)와의 통신을 필요로 한다.
VPC(동일 또는 다른 리전)에 연결하는 경우 VPC 간의 터널링을 가능하게 하는 VPC 피어링을 사용할 수 있다. NOTE: WAN IP 체계 모범 사례를 따르고 VPC/서브넷 간에 CIDR 범위가 겹치지 않도록 해야 한다.
다음은 eu-west-1 및 eu-west-2 리전에서 VPC 간의 VPC 피어링 연결을 보여준다.
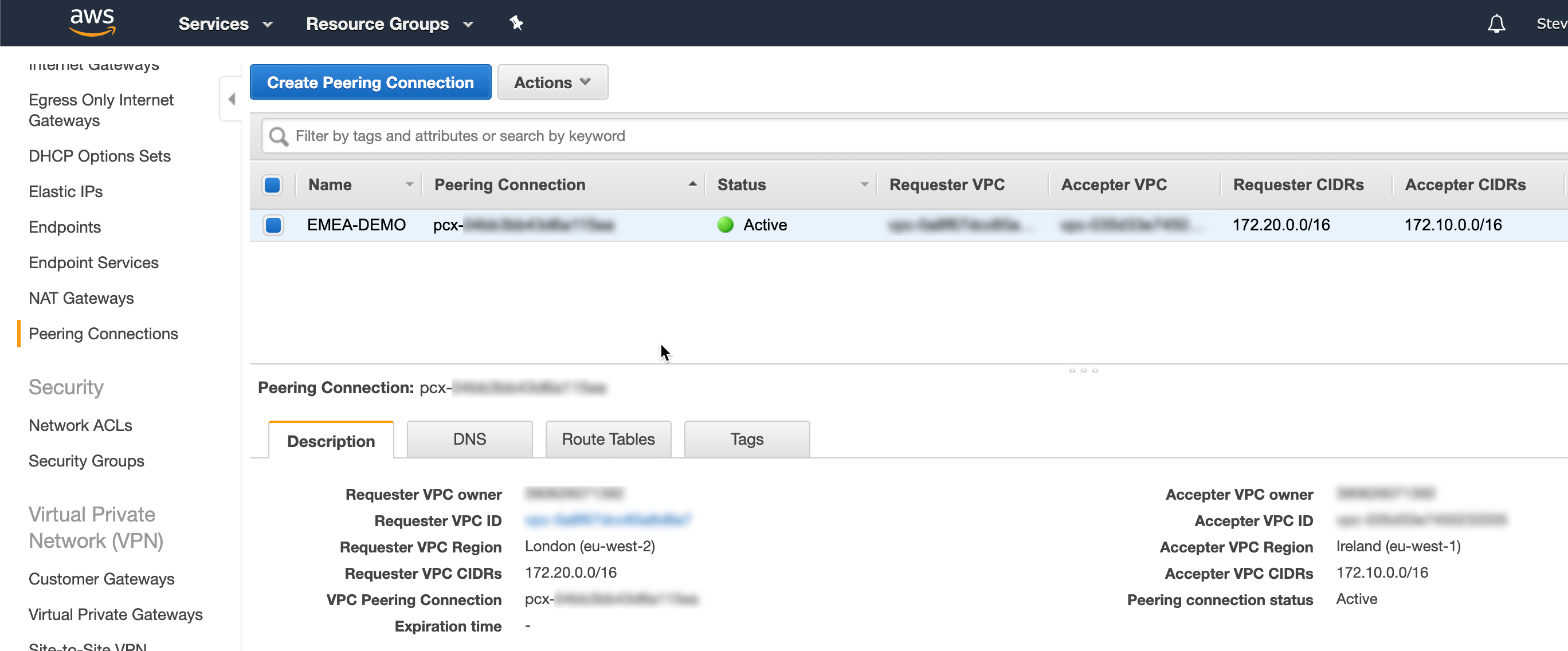 NC2A - VPC 피어링 (NC2A - VPC Peering)
NC2A - VPC 피어링 (NC2A - VPC Peering)
그런 다음 각 VPC의 라우팅 테이블은 피어링 연결을 통해 다른 VPC로 가는 트래픽을 라우팅한다 (이는 양방향 통신이 필요한 경우 양쪽에 존재해야 한다).
NC2A - 라우팅 테이블 (NC2A - Route Table)
온-프레미스/WAN으로의 네트워크 확장을 위해 VPN 게이트웨이 (터널) 또는 AWS Direct Connect를 활용할 수 있다.
보안 (Security)
이러한 리소스가 전체 제어 보안 외부에 존재하는 클라우드에서 실행되고 있으므로 데이터 암호화 및 규정 준수는 매우 중요한 고려 사항이다.
권장 사항은 다음과 같은 특징이 있다.
- 데이터 암호화 사용
- 프라이빗 서브넷만 사용 (퍼블릭 IP 할당 없음)
- 보안 그룹 및 허용된 포트/IP CIDR 블록 잠금
- 보다 세분화된 보안을 위해 Flow를 활용
사용법 및 설정 (Usage and Configuration)
다음 섹션에서는 NC2A 설정 및 활용 방법을 설명한다.
하이-레벨 프로세스는 다음과 같은 하이-레벨 단계로 특징지을 수 있다.
- AWS 계정 생성
- AWS 네트워크 자원 설정 (필요한 경우)
- 뉴타닉스 클러스터 포탈을 통한 클러스터 프로비저닝
- 프로비저닝이 완료되면 클러스터 자원 활용
내용 추가 예정입니다!
Azure에서 뉴타닉스 클라우드 클러스터
Azure의 NC2(Nutanix Cloud Clusters)는 베어-메탈 자원을 사용하여 대상 클라우드 환경에서 실행되는 온-디멘드 클러스터를 제공한다. 이를 통해 이미 알고 있는 바와 같이 뉴타닉스 플랫폼의 단순성과 함께 진정한 온-디맨드 용량을 구현할 수 있다. 일단 클라우드가 프로비저닝되면, 클러스터는 클라우드 프로바이더의 데이터센터에서 실행되는 기존 AHV 클러스터처럼 나타난다.
지원되는 환경 (Supported Configurations)
솔루션은 아래 설정에 적용할 수 있다 (목록이 불완전할 수 있으니 완전히 지원되는 목록은 설명서 참조):
핵심 사용 사례:
- On-Demand / burst capacity
- Backup / DR
- Cloud Native
- Geo Expansion / DC consolidation
- App migration
- Etc.
관리 인터페이스:
- 뉴타닉스 클러스터 포탈 - 프로비저닝
- 프리즘 센트럴 (PC) - 뉴타닉스 관리
- Azure 포탈 - Azure 관리
지원 환경:
- 클라우드:
- AWS
- Azure (private-preview)
- 베어-메탈 인스턴스 유형:
- AN36
- AN36P
업그레이드:
- AOS의 일부
호환되는 기능:
- AOS 기능
- Azure 서비스
주요 용어 / 컨스트럭트 (Key terms / Constructs)
다음 주요 항목은 본 섹션 전체에서 사용되며 다음과 같이 정의한다:
- 뉴타닉스 클라우드 포탈 (Nutanix Clusters Portal)
- 뉴타닉스 클러스터 포털(Nutanix Clusters Portal)은 클러스터 프로비저닝 요청을 처리하고 Azure 및 프로비저닝된 호스트와 상호 작용한다. 클러스터별 세부 정보를 생성하고 클러스터 생성을 처리하며 하드웨어 문제를 해결하는 데 도움을 준다.
- 리전 (Region)
- 여러 AZ(사이트)가 있는 지리적 대륙 또는 영역이다. 리전에는 2개 이상의 AZ가 있을 수 있다. 여기에는 East US (Virginia) 또는 West US 2 (Washington)와 같은 지역이 포함될 수 있다.
- 가용 영역 (Availability Zone: AZ)
- AZ는 레이턴시가 매우 적은 링크로 상호 연결된 하나 이상의 개별 데이터 센터로 구성된다. 각 사이트에는 자체 예비 전원, 냉각, 네트워크 등이 있다. 이를 기존의 COLO나 데이터센터와 비교하면, AZ가 여러 개의 독립적인 데이터 센터로 구성될 수 있으므로 보다 탄력적이다.
- VNet
- 테넌트를 위한 Azure 클라우드의 논리적으로 격리된 세그먼트이다. 환경을 다른 환경으로부터 보호하고 격리하는 메커니즘을 제공한다. 인터넷 또는 기타 사설 네트워크 세그먼트(다른 VNet 또는 VPN)와 연동할 수 있다.
클러스터 아키텍처 (Cluster Architecture)
하이-레벨에서 NC2(Nutanix Clusters) 포털은 Azure에서 뉴타닉스 클러스터를 프로비저닝하고 Azure와 상호 작용하기 위한 기본 인터페이스이다.
프로비저닝 프로세스는 다음과 같은 하이-레벨 단계로 요약할 수 있다:
- NC2 포털에서 클러스터 생성
- 배포 별 입력 (예를 들어 리전, AZ, 인스턴스 유형, VNets/서브넷 등)
- NC2 포털은 관련 자원을 생성한다.
- AHV에서 실행되는 호스트 에이전트는 Azure에서 뉴타닉스 클러스터와 체크인ㅎ한다.
- 모든 호스트가 가동되면 클러스터가 생성된다.
다음은 Azure 상호 작용하는 NC2의 대한 하이-레벨 개요를 보여준다:
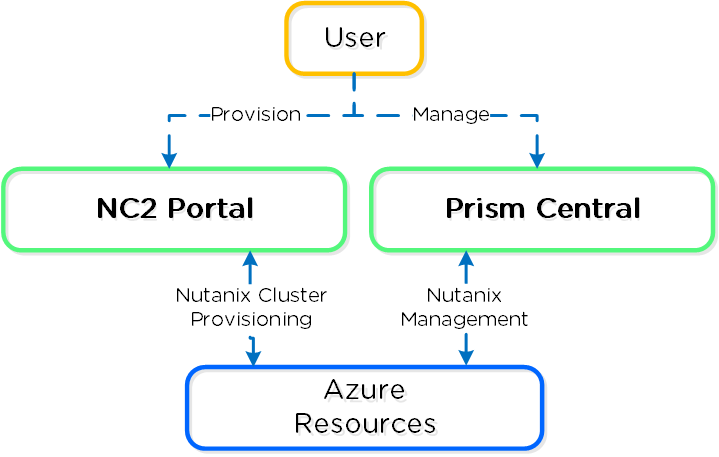 Azure에서 NC2 - 개요 (NC2 on Azure - Overview)
Azure에서 NC2 - 개요 (NC2 on Azure - Overview)
다음은 NC2 포털 및 생성된 일부 자원에 필요한 입력에 대한 하이-레벨 개요를 보여준다:
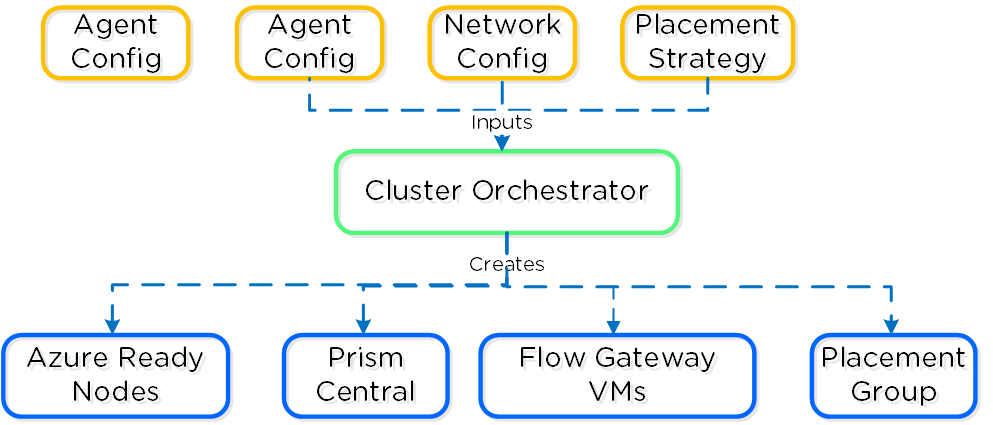 Azure에서 뉴타닉스 클러스터 - 클러스터 오케스트레이터 입력 (Nutanix Clusters on Azure - Cluster Orchestrator Inputs)
Azure에서 뉴타닉스 클러스터 - 클러스터 오케스트레이터 입력 (Nutanix Clusters on Azure - Cluster Orchestrator Inputs)
노드 아키텍처 (Node Architecture)
호스트가 베어-메탈인 경우 일반적인 온-프레미스 배포와 유사한 스토리지 및 네트워크 자원을 완벽하게 제어할 수 있다. 뉴타닉스는 Ready 노드를 빌딩 블록으로 사용하고 있다. AWS와 달리 Azure 기반 노드는 CVM 또는 AHV에 대한 추가 서비스를 사용하지 않는다.
배치 정책 (Placement policy)
Azure에서 뉴타닉스 클러스터는 디폴트로 7개의 파티션을 갖는 파티션 배치 정책을 사용한다. 호스트는 뉴타닉스의 랙에 해당하는 이러한 파티션에 걸쳐 스트라이프된다. 이렇게 하면 1-2개의 전체 "랙(Rack)" 장애를 허용하고 가용성을 계속 유지할 수 있다.
다음은 파티션 배치 전략 및 호스트 스트라이핑에 대한 하이-레벨 개요를 보여준다:
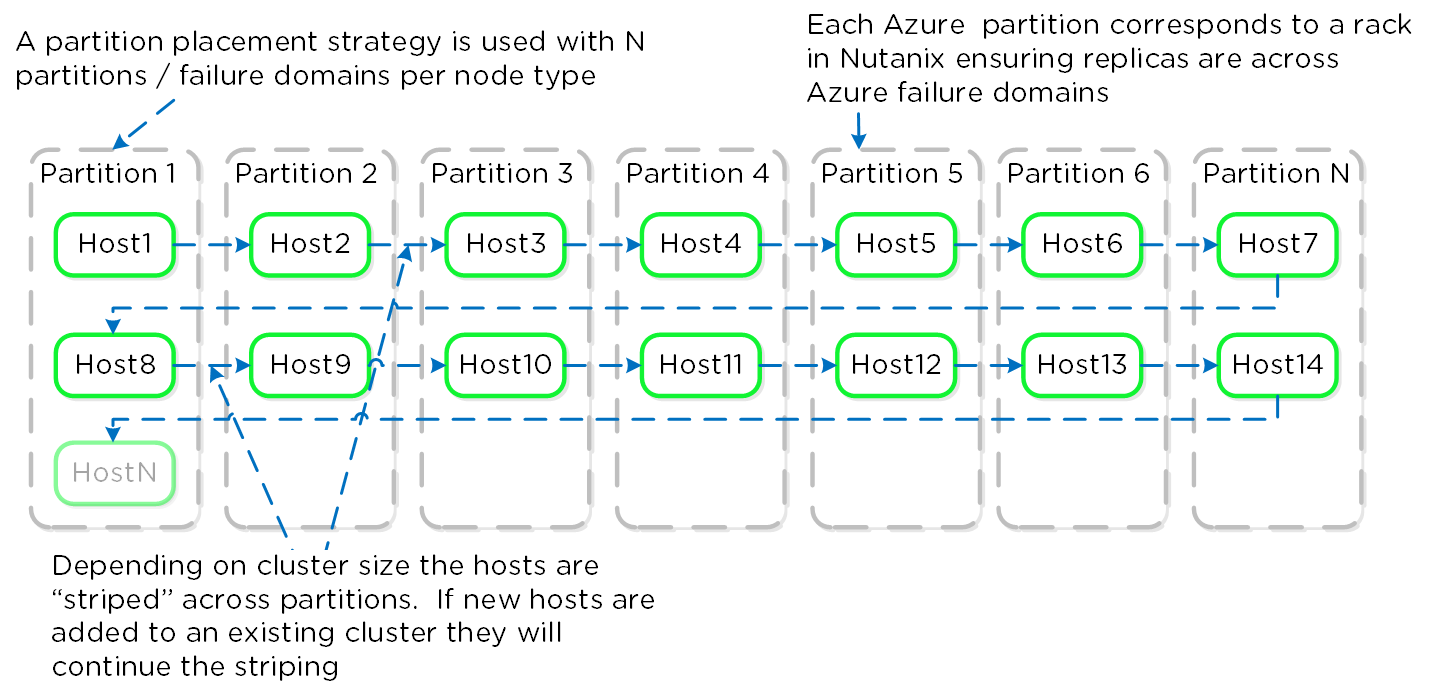 Azure에서 NC2 - 파티션 배치 (NC2 on Azure - Partition Placement)
Azure에서 NC2 - 파티션 배치 (NC2 on Azure - Partition Placement)
스토리지 (Storage)
코어 스토리지는 모든 뉴타닉스 클러스터에서 기대하는 것과 정확히 동일하며, "로컬" 스토리지 디바이스를 스타게이트에서 활용할 CVM으로 전달한다.
Note
인스턴스 스토리지 (Instance Storage)
"로컬" 스토리지가 로컬 플래시에 의해 지원된다는 점을 감안할 때 정전 시 완벽하게 복원된다.
네트워킹 (Networking)
NC2는 Azure에서 오버레이 네트워크를 생성하기 위해 Flow 가상 네트워킹(Flow Virtual Networking)을 활용하므로, 뉴타닉스 관리자의 관리를 용이하게 하고 클라우드 벤터 전반의 네트워킹 제약을 줄인다. Flow 가상 네트워킹은 오버레이 가상 네트워크를 생성하여 Azure 네이티브 네트워크를 추상화하는 데 사용된다. 한편으로 이는 Azure에서 기반 네트워크를 추상화하는 동시에 네트워크 기반 레이어(및 관련 기능)가 고객의 온-프레미스 뉴타닉스 배포와 동일하도록 한다. 뉴타닉스 내에서 새로운 가상 네트워크(가상 사설 클라우드 또는 VPC라고 함)를 생성할 수 있는데, 친숙한 프리즘 센트럴 인터페이스를 활용하여 RFC1918(사설) 주소 공간을 포함하여 모든 주소 범위의 서브넷을 사용할 수 있으며, DHCP, NAT, 라우팅 및 보안 정책을 정의할 수 있다.
Flow 가상 네트워킹은 추상화 계층을 제공하여 클라우드 제약 조건을 마스킹하거나 줄일 수 있다. 예를 들어 Azure는 VNet 당 하나의 위임된 서브넷만 허용한다. 서브넷 위임을 사용하면 선택한 Azure PaaS 서비스에 대해 가상 네트워크에 삽입해야 하는 특정 서브넷을 지정할 수 있다. NC2에는 Microsoft.BareMetal/AzureHostedService에 위임된 관리 서브넷이 필요하다. 서브넷이 BareMetal 서비스에 위임되면, 클러스터 포털은 해당 서브넷을 사용하여 뉴타닉스 클러스터를 배포할 수 있다. AzureHostedService는 클러스터 포털이 베어-메탈 노드에서 네트워킹을 배포 및 설정하는 데 사용하는 것이다.
사용자 네이티브 VM 네트워킹에 사용되는 모든 서브넷도 동일한 서비스에 위임해야 한다. VNet에는 위임된 서브넷이 하나만 있을 수 있으므로 네트워킹 설성은 통신을 허용하기 위해 서로 VNet을 피어링해야 하는 번거로움이 있다. Flow 가상 네트워킹을 사용하면 클러스터 및 Azure에서 실행되는 워크로드의 통신을 허용하는 데 필요한 VNet의 양을 크게 줄일 수 있다. Flow 가상 네트워킹을 사용하면 1개의 Azure VNet만 사용하면서 500개가 넘는 서브넷을 만들 수 있다.
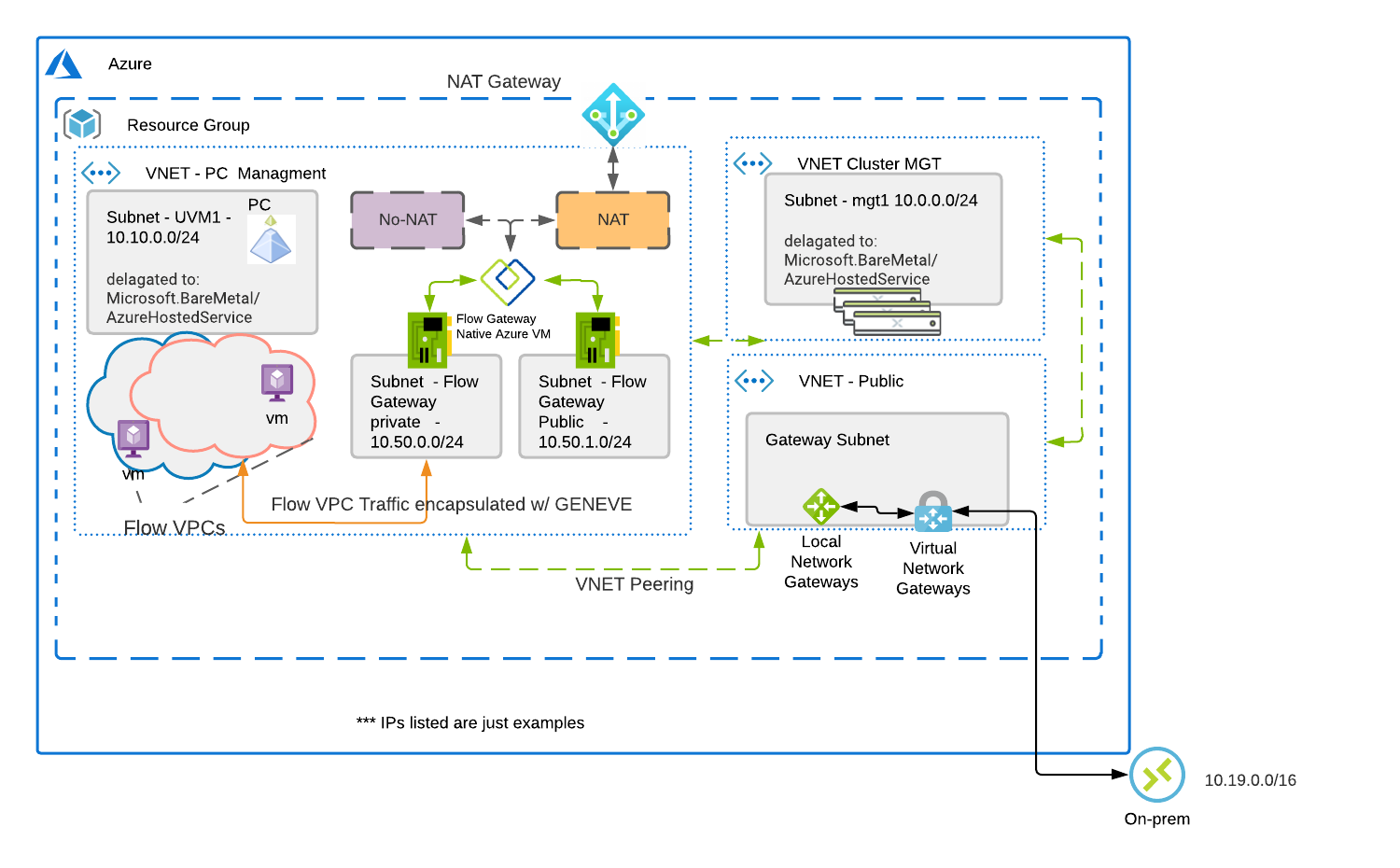
회사 IP 체계에 맞는 관련된 서브넷, NAT/인터넷 게이트웨이 등을 갖는 새로운 VPC를 생성할 것을 권장한다. 이는 VPC 간(VPC 피어링) 또는 기존 WAN으로 네트워크를 확장하려는 경우에 매우 중요하다. 나는 이것을 WAN의 모든 사이트와 마찬가지로 취급한다.
프리즘 센트럴(PC)은 배포 후 뉴타닉스 클러스터에 배포된다. 프리즘 센트럴에는 Flow 가상 네트워킹을 위한 컨트롤 플레인이 포함되어 있다. PC 용 서브넷은 Microsoft.BareMetal/AzureHostedService에 위임되므로 네이티브 Azure 네트워킹을 사용하여 PC 용 IP를 배포할 수 있다. PC가 배포되면, Flow 게이트웨이(Flow Gateway)는 PC가 사용하는 동일한 서브넷에 배포된다. Flow 게이트웨이를 사용하면, Flow VPC를 사용하는 사용자 VM이 네이티브 Azure 서비스와 통신할 수 있으며, VM이 다음과 같은 네이티브 Azure VM과 동일한 기능을 가질 수 있다:
- 사용자 정의 라우팅 (User defined routes) - Azure에서 커스텀 또는 사용자 정의(정적) 라우팅 생성하여, Azure의 디폴트 시스템 라우팅을 재정의하거나 서브넷의 라우팅 테이블에 라우팅을 추가할 수 있다. Azure에서 라우팅 테이블을 생성한 다음 라우팅 테이블을 0개 이상의 가상 네트워크 서브넷에 연결한다.
- 로드 밸러서 배포 (Load Balancer Deployment) - Azure 네이티브 로드 밸런서를 사용하여 UVM에서 제공하는 프런트-엔드 서비스 기능
- 네트워크 보안 그룹 (Network Security Groups) - 상태 저장 방화벽 정책을 작성하는 기능
Flow 게이트웨이 VM은 클러스터에서 VM의 모든 north-south 트래픽을 담당한다. 배포 중에 필요한 대역폭에 따라 Flow 게이트웨이 VM에 대해 다양한 크기를 선택할 수 있다. 다른 CVM과 온-프레미스 간의 CVM 복제는 Flow 게이트웨이 VM을 통해 흐르지 않으므로 해당 트래픽에 맞게 크기를 조정할 필요가 없다는 점을 인식하는 것이 중요하다.
네트웨크 주소 변환 (NAT): AHV/CVM/PC 및 Azure 자원과 통신하려는 UVM은 Flow 게이트웨이 VM의 외부 네트워크 카드를 통해 통신한다. 제공된 NAT는 모든 자원에 대한 라우팅을 보장하기 위해 네이티브 Azure 주소를 사용한다. NAT 사용이 선호되지 않는 경우 Azure의 사용자 정의 경로를 사용하여 Azure 자원과 직접 통신할 수 있다. 이를 통해 새로 설치하면 Azure와 즉시 통신할 수 있지만 고객에게 고급 설정에 대한 옵션도 제공할 수 있다.
호스트 네트워킹 (Host Networking)
Azure의 베어-메탈에서 실행되는 호스트는 기존 AHV 호스트이므로 동일한 OVS 기반 네트워크 스택을 활용한다.
다음은 Azure AHV 호스트의 OVS 스택에 대한 하이-레벨 개요를 보여준다:
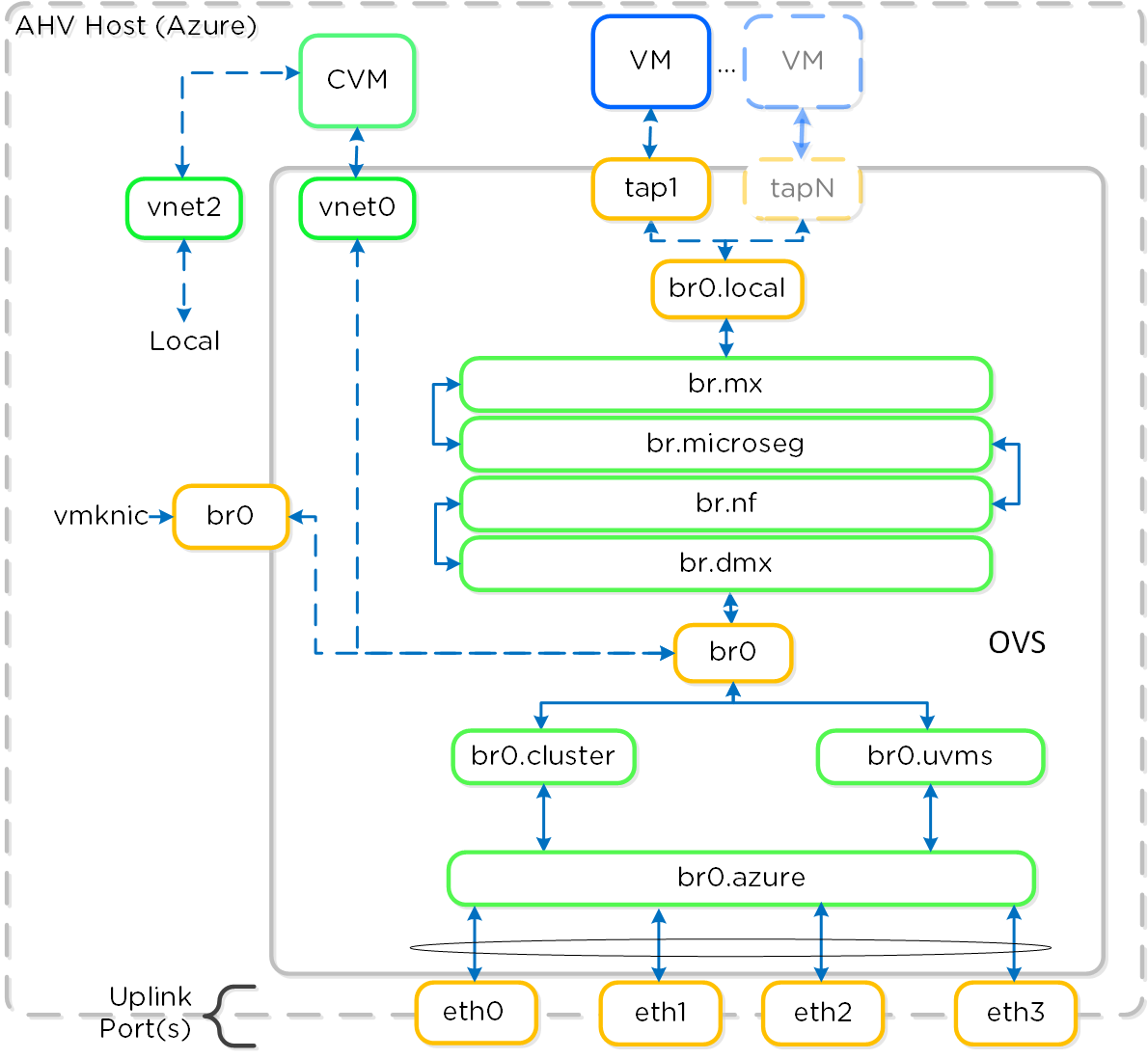 Azure에서의 NC2 - 호스트 네트워킹 (NC2 on Azure - Host Networking)
Azure에서의 NC2 - 호스트 네트워킹 (NC2 on Azure - Host Networking)
뉴타닉스의 Open vSwitch 구현은 온-프레미스 구현과 매우 유사하다. 위의 다이어그램은 베어-메탈에 배포된 AHV의 내부 아키텍처를 보여준다. br0 브리지는 br0.cluster(AHV/CVM IP)와 br0.uvms(사용자 VM IP) 간에 트래픽을 분할한다.
br0.cluster를 경유하는 AHV/CVM 트래픽의 경우 데이터 패킷을 수정하지 않고 br0.azure 브리지로 간단하게 패스-스루된다. ToR 스위칭은 br0.cluster 트래픽에 대한 보안을 제공한다. UVM IP 트래픽은 br0.uvms를 통해 통신하므로 vlan-id 변환 및 br0.azure로의 패스-스루 트래픽을 위해 OVS 규칙이 설치된다.
br0.azure에는 OVS bond인 br0.azure-up이 있는데, 이는 베어-메탈로 연결된 물리적 NIC와 본드 인터페이스를 구성한다. 따라서 br0.azure는 br0.uvms 및 br0.cluster로부터 본드 인터페이스를 숨긴다.
서브넷 생성 (Creating a Subnet)
생성한 서브넷에는 자체 IPAM이 내장되어 있으며 온-프레미스에서 Azure로 네트워크를 확장할 수 있는 옵션이 있다. 외부 애플리케이션이 서브넷 내부의 UVM과 직접 통신해야 하는 경우, Flow 게이트웨이의 외부 네트워크에서 오는 Azure의 IP 풀에서 유동 IP를 할당하는 옵션도 있다.
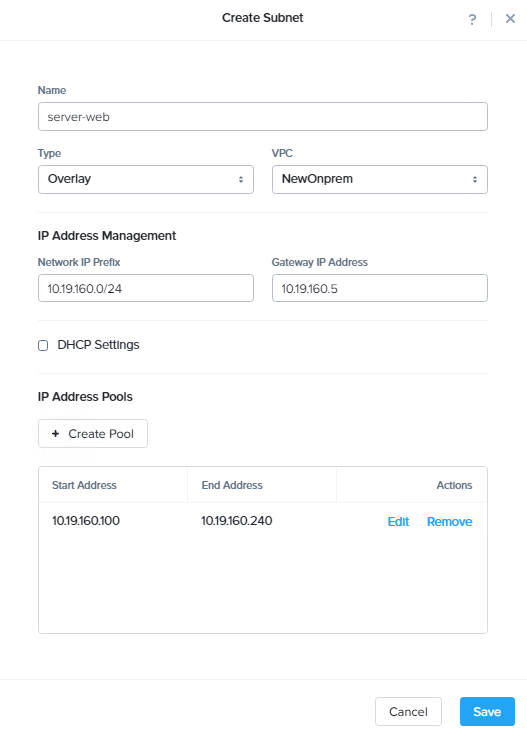 Azure에서의 NC2 - Azure의 IPAM (NC2 on Azure - IPAM with Azure)
Azure에서의 NC2 - Azure의 IPAM (NC2 on Azure - IPAM with Azure)
성공적인 배포를 위해 뉴타닉스 클러스터는 NAT 게이트웨이 또는 아웃바운드 액세스가 있는 온-프레미스 VPN을 사용하여 NC2 포털에 대한 아웃바운드 액세스가 필요하다. 뉴타닉스 클러스터는 VPN에서만 액세스할 수 있는 프라이빗 서브넷에 위치하여 환경에 대한 노출을 제한할 수 있다.
WAN / L3 네트워킹 (WAN / L3 Networking)
대부분의 경우 배포는 Azure에만 있는 것이 아니며 외부 세계(기타 VNet, 인터넷 또는 WAN)와 통신해야 한다.
VNet을 연결하기 위해(동일 또는 다른 리전에서), VPC 간 터널링을 허용하는 VPC 피어링을 사용할 수 있다. NOTE: WAN IP 체계 모범 사례를 따르고 VNet/서브넷 간에 CIDR 범위가 겹치지 않는지 확인해야 한다.
온-프레미스/WAN으로의 네트워크 확장을 위해 VNet 게이트웨이(터널) 또는 Express Route를 활용할 수 있다.
활용 및 설정 (Usage and Configuration)
다음 섹션에서는 Azure에서 NC2를 설성하고 활용하는 방법을 다룬다.
하이-레벨 프로세스는 다음과 같은 하이-레벨 단계로 특징지을 수 있다:
- 액티브 Azure 구독을 설정한다.
- My Nutanix 계정을 생성하고 NC2에 가입한다.
- Azure 자원 프로바이더를 등록한다.
- 새로운 구독에 대한 "Contributor" 액세스 권한이 있는 Azure AD에서 앱 등록을 생성한다.
- DNS를 설정한댜.
- 자원 그룹을 생성하거나 기존 자원 그룹을 재사용한다.
- 필요한 VNets 및 필요한 서브넷을 생성한다.
- 2개의 NAT 게이트웨이를 설정한다.
- 뉴타닉스 클러스터에 필요한 VNet 피어링을 설정한다.
- NC2 콘솔에 Azure 계정을 추가한다.
- NC2 콘솔을 사용하여 Azure에서 뉴타닉스 클러스터를 생성한다.
내용 추가 예정입니다 !!
Book of Storage Services
뉴타닉스는 설립 초기에 VM 데이터에 최적화된 스토리지 서비스를 제공하는 데 중점을 두었다. 그런 다음 베어-메탈 소비자를 위한 공유 디스크 및 guest-initiated iSCSI와 같은 사용 사례를 위해 모든 운영 체제에서 뉴타닉스 Volumes이 있는 스토리지 시스템에 액세스할 수 있도록 확장했다. 뉴타닉스 Files를 통해 플랫폼을 고가용성 파일 서버로 사용할 수 있는 기능을 제공하기 위해 이를 더욱 확장했다. 마지막으로 뉴타닉스 Objects는 S3 호환 API를 통해 확장성이 뛰어난 오브젝트 스토리지를 제공한다.
본 BOOK에서는 이러한 스토리지 서비스를 보다 깊이있게 설명한다.
Volumes (블록 서비스)
뉴타닉스 Volumes 기능(이전의 아크로폴리스 Volumes)은 iSCSI를 통해 외부 소비자(게스트 OS, 물리 호스트, 컨테이너 등)에게 백엔드 DSF 스토리지를 노출한다.
이를 통해 모든 OS는 DFS에 액세스하고 DFS 스토리지 기능을 활용한다. 이 배포 시나리오에서 OS는 하이퍼바이저를 바이패스하여 뉴타닉스와 직접 통신한다.
Volumes의 핵심 사용 사례:
- 공유 디스크 (Shared Disks)
- Oracle RAC, Microsoft 페일오버 클러스터링 등
- 퍼스트 클래스 엔티티로서의 디스크 (Disks as first-class entities)
- 실행 컨텍스트가 일시적이고 데이터가 중요한 경우
- 컨테이너 등
- Guest-initiated iSCSI
- 베어-메탈 소비자
- vSphere에서 Exchange (Microsoft 지원용)
인증된 OS (Qualified Operating Systems)
이 솔루션은 iSCSI 사양을 준수하며, 공인 OS는 QA에 의해 검증된 OS이다.
- Microsoft Windows Server 2008 R2, 2012 R2
- Redhat Enterprise Linux 6.0 이상
Volumes 컨스트럭트 (Volumes Constructs)
다음 엔티티들이 Volumes을 구성한다.
- 데이터 서비스 IP (Data Services IP): iSCSI 로그인 요청에 사용되는 클러스터 전체 IP 주소 (AOS 4.7에서 도입).
- 볼륨 그룹 (Volume Group): 중앙 집중식 관리, 스냅샷 생성 및 정책 적용이 가능한 iSCSI 타깃 및 디스크 디바이스 그룹
- 디스크(Disks): 볼륨 그룹의 스토리지 디바이스 (iSCSI 타깃의 LUN으로 표시)
- 연결 (Attachment): 볼륨 그룹에 특정 Initiator IQN의 액세스 허용
- 시크리트 (Secret(s)): CHAP/Mutual CHAP 인증에 사용되는 시크리트
NOTE: 백엔드에서 VG 디스크는 DSF에서 vDisk이다.
전제 조건 (Pre-Requisites)
설정을 시작하기 전에 센트럴 디스커버리 및 로그인 포탈 역할을 수행하는 데이터 서비스 IP(Data Services IP)를 설정하여야 한다.
'Cluster Details' (설정 아이콘 -> Cluster Details) 페이지에서 데이터 서비스 IP를 설정할 수 있다.
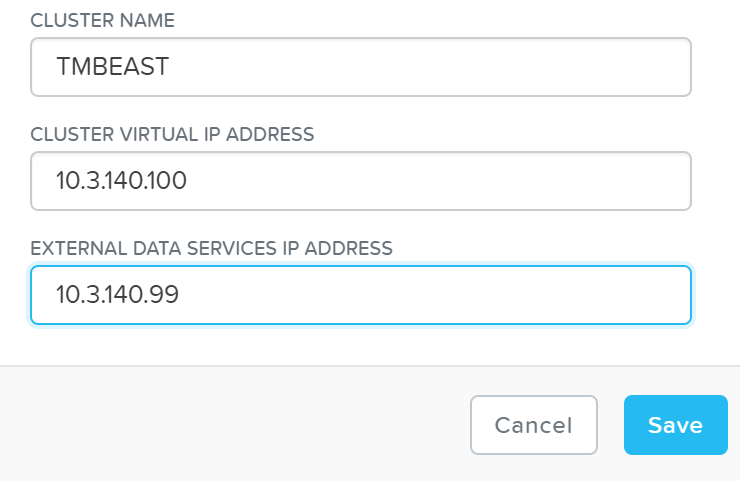 Volumes - 데이터 서비스 IP (Volumes - Data Services IP)
Volumes - 데이터 서비스 IP (Volumes - Data Services IP)
nCLI/API를 통해 설정할 수도 있다.
ncli cluster edit-params external-data- services-ip-address=DATASERVICESIPADDRESS
타깃 생성 (Target Creation)
Volumes을 사용하기 위해 가장 먼저 할 일은 iSCSI 타깃인 “볼륨 그룹”을 생성하는 것이다.
'Storage' 페이지에서 오른쪽 모서리에 있는 '+ Volume Group'을 클릭한다.
 Volumes - 볼륨 그룹 추가 (Volumes - Add Volume Group)
Volumes - 볼륨 그룹 추가 (Volumes - Add Volume Group)
그러면 VG 상세 정보를 지정하는 메뉴가 시작된다.
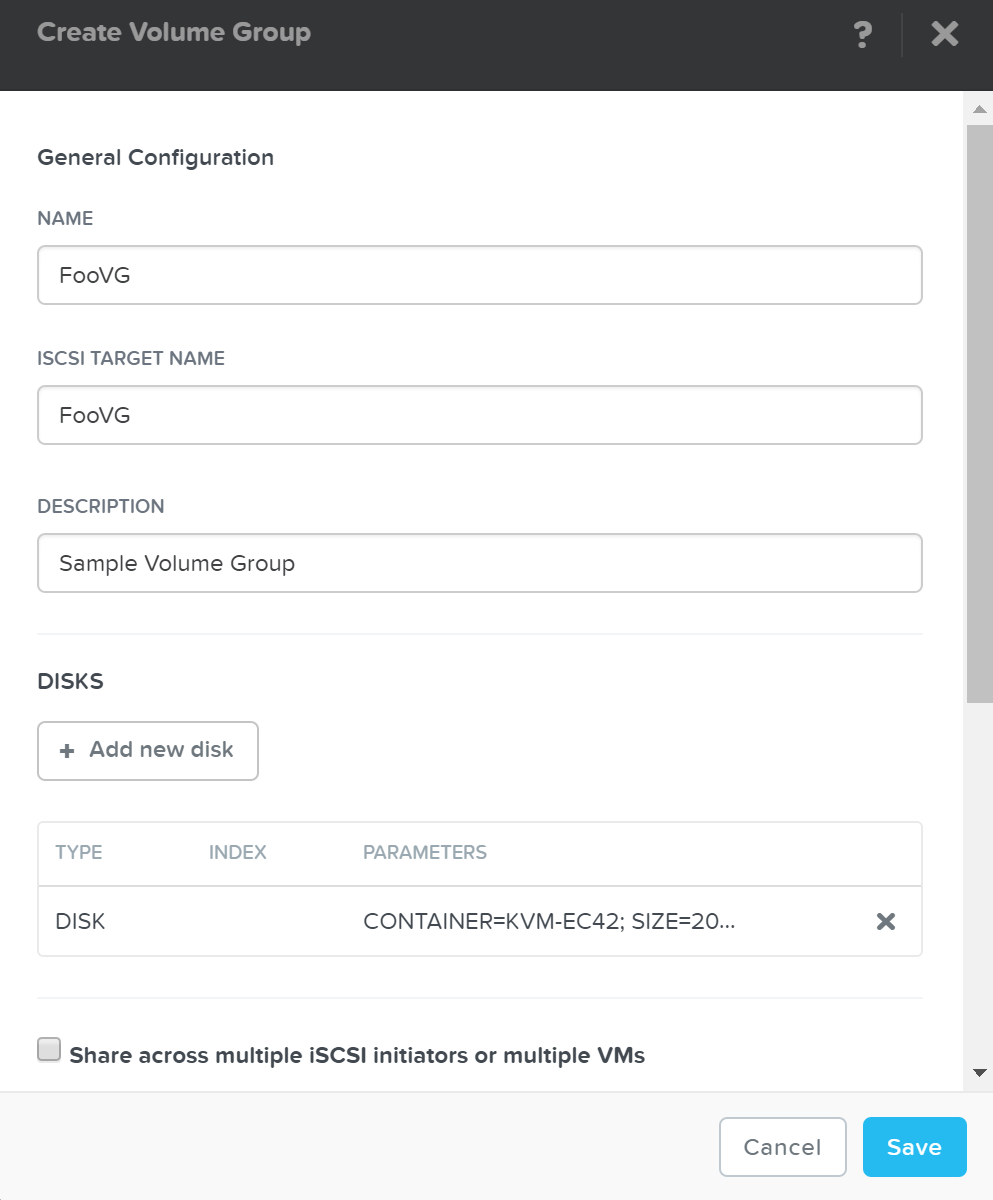 Volumes - VG 상세 정보 추가 (Volumes - Add VG Details)
Volumes - VG 상세 정보 추가 (Volumes - Add VG Details)
다음으로 '+ Add new disk' 클릭하여 디스크를 타깃에 추가한다 (LUN으로 표시).
타깃 컨테이너와 디스크 크기를 선택할 수 있는 메뉴가 나타난다.
 Volumes - 디스크 추가 (Volumes - Add Disk)
Volumes - 디스크 추가 (Volumes - Add Disk)
'Add'를 클릭하고 추가할 디스크 수에 대해 이 작업을 반복한다.
세부 정보를 지정하고 디스크를 추가한 후에 볼륨 그룹을 VM 또는 Initiator IQN에 연결한다. 그러면 VM이 iSCSI 타깃에 액세스할 수 있다 (알 수 없는 Initiator 요청은 거부).
 Volumes - Initiator IQN / VM (Volumes - Initiator IQN / VM)
Volumes - Initiator IQN / VM (Volumes - Initiator IQN / VM)
“Save”를 클릭하면 볼륨 그룹 설정이 완료된다.
이 모든 작업은 ACLI/API를 통해서도 수행할 수 있다.
VG 생성 (Create VG)
vg.create VGName
VG에 디스크 추가 (Add disk(s) to VG)
Vg.disk_create VGName container=CTRName create_size=Disk size, e.g. 500G
VG에 initiator IQN 연결 (Attach initiator IQN to VG)
Vg.attach_external VGName InitiatorIQN
경로 고가용성 (Path High-Availability (HA))
앞에서 언급했듯이 데이터 서비스 IP는 검색에 활용된다. 이를 통해 개별 CVM IP 주소를 알 필요 없이 단일 주소를 활용할 수 있다.
데이터 서비스 IP는 현재 iSCSI 리더에 할당된다. 실패하는 경우 새로운 iSCSI 리더가 선출되어 데이터 서비스 IP가 할당된다. 이것은 검색 포털이 항상 이용 가능한 상태로 유지되는 것을 보장한다.
iSCSI initiator는 iSCSI 타깃 포탈로 데이터 서비스 IP를 설정한다. 로그인 요청 시 플랫폼은 iSCSI 로그인 요청을 헬시 스타게이트로 리디렉트한다.
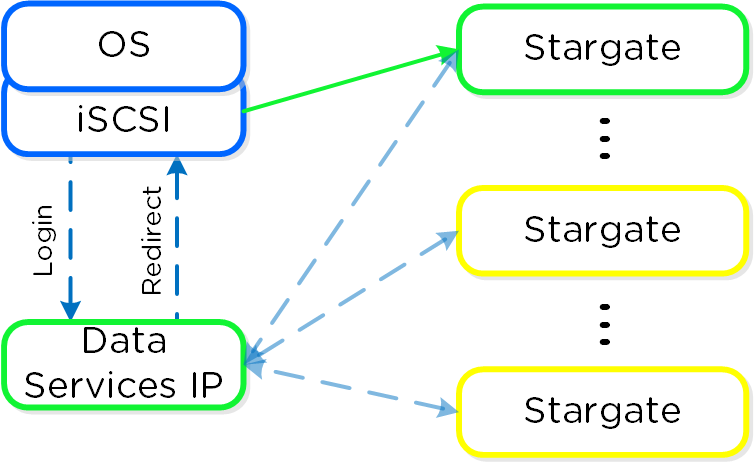 Volumes - 로그인 리디렉트 (Volumes - Login Redirect)
Volumes - 로그인 리디렉트 (Volumes - Login Redirect)
액티브(관련된) 스타게이트가 다운되는 경우 Initiator는 데이터 서비스 IP로 iSCSI 로그인을 재시도하면 해당 요청은 다른 헬시 스타게이트로 리디렉트된다.
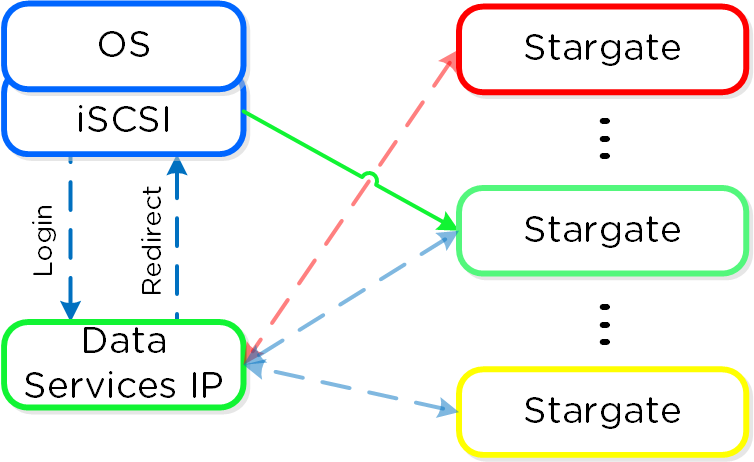 Volumes - 장애 처리 (Volumes - Failure Handling)
Volumes - 장애 처리 (Volumes - Failure Handling)
관련된 스타게이트가 다시 시작되고 안정적이면 현재 액티브 스타게이트는 I/O를 중지하고 액티브 iSCSI 세션을 종료한다. Initiator가 iSCSI 로그인을 다시 시도하면 데이터 서비스 IP가 해당 로그인을 관련된 스타게이트로 리디렉트한다.
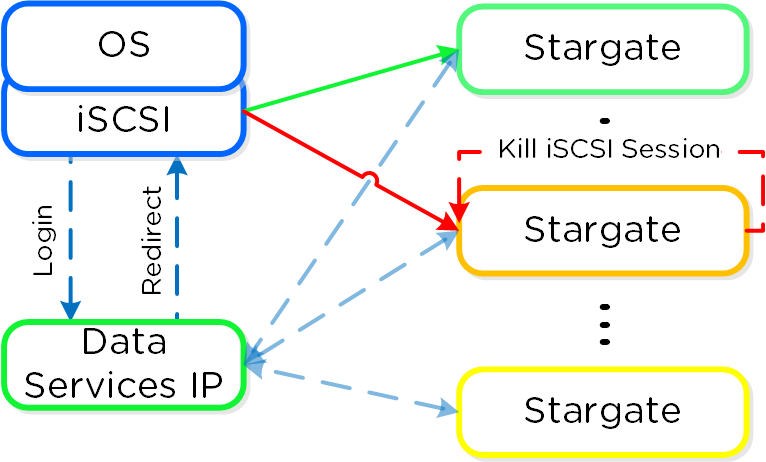 Volumes - 패일백 (Volumes - Failback)
Volumes - 패일백 (Volumes - Failback)
Note
헬스 모니터링 및 기본값 (Health Monitoring and Defaults)
스타게이트 헬스는 DSF와 완전히 동일한 메커니즘으로 Volumes 용 주키퍼를 사용하여 모니터링된다.
페일백의 경우 기본 인터벌은 120초이다. 이것은 관련된 스타게이트가 2분 이상 정상적인 상태를 유지하게 되면 중지한 후에 세션을 종료한다는 것을 의미한다. 관련된 스타게이트로 다시 다른 로그인을 강제한다.
이 메커니즘을 사용하면 경로 HA에는 클라이언트 측 다중-경로(MPIO)가 더 이상 필요하지 않다. 타깃에 연결할 때 이제 'Enable Multi-path'(MPIO를 활성화하는)를 체크할 필요가 없다.
 Volumes - No MPIO (Volumes - No MPIO)
Volumes - No MPIO (Volumes - No MPIO)
다중 경로 (Multi-Pathing)
iSCSI 프로토콜 사양은 Initiator와 타깃 간에 타깃 당 하나의 iSCSI 세션(TCP 연결)을 요구한다. 이는 스타게이트와 타깃 간에 1:1 관계가 있음을 의미한다.
AOS 4.7을 기준으로 Attached Initiator 당 32개(기본값)의 가상 타깃이 자동으로 생성되어 볼륨 그룹(VG)에 추가된 각 디스크 디바이스에 할당된다. 이는 디스크 디바이스 당 하나의 iSCSI 타깃을 제공한다. 이전에는 하나의 디스크를 갖는 여러 볼륨 그룹을 생성하여 처리하였다.
ACLI/API를 이용한 VG 상세 정보를 살펴보면 각 Attachment에 32개의 가상 타깃이 생성된 것을 볼 수 있다.
attachment_list {
external_initiator_name: "iqn.1991-05.com.microsoft:desktop-foo"
target_params {
num_virtual_targets: 32
}
}
여기에 3개의 디스크 디바이스가 추가된 샘플 VG를 생성했다. 클라이언트에서 검색을 수행하면, 각 디스크 디바이스 당 개별 타깃을 볼 수 있다 ('-tgt[int] 형식의 접미사 포함):
 Volumes - 가상 타깃 (Volumes - Virtual Target)
Volumes - 가상 타깃 (Volumes - Virtual Target)
이를 통해 각 디스크 디바이스는 자체 iSCSI 세션을 가지며 이러한 세션을 여러 스타게이트에서 호스팅할 수 있으므로 확장성과 성능이 향상된다.
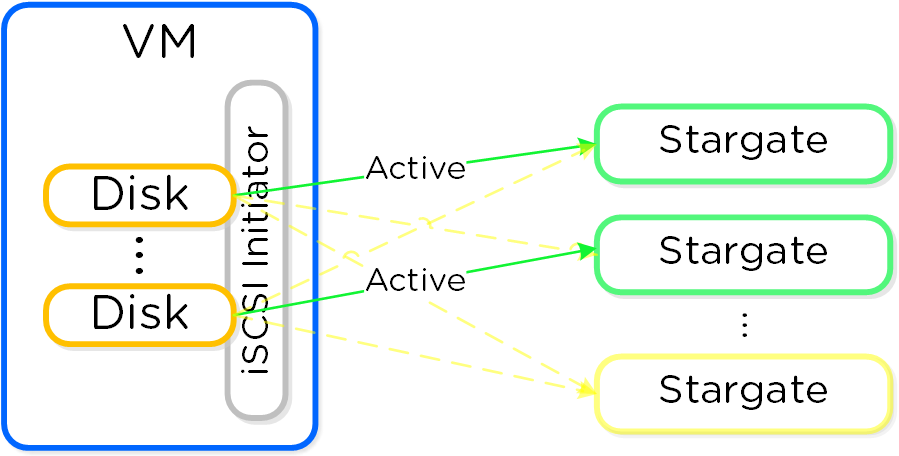 Volumes - 다중 경로 (Volumes - Multi-Path)
Volumes - 다중 경로 (Volumes - Multi-Path)
각 타깃에 대해 iSCSI 세션 설정(iSCSI 로그인) 중에 로드 밸런싱이 발생한다.
Note
액티브 경로 (Active Path(s))
다음 명령을 사용하여 가상 타깃을 호스팅하는 액티브 스타게이트를 볼 수 있다 (스타게이트 호스팅하는 CVM IP가 표시됨).
# Windows Get-NetTCPConnection -State Established -RemotePort 3205 # Linux iscsiadm -m session -P 1
AOS 4.7을 기준으로 간단한 해쉬 함수가 클러스터 전체 노드에 타깃을 분산하는 데 사용된다. AOS 5.0에서 이것은 AOS 동적 스케줄러와 통합되어 필요한 경우에 세션의 리밸런싱한다. 뉴타닉스는 계속해서 알고리즘을 살펴보고 필요에 따라 최적화할 것이다. 또한 헬스 상태에 있는 한 사용될 선호 노드를 설정할 수도 있다.
Note
SCSI UNMAP (TRIM)
Volumes은 SCSI T10 사양에 포함된 SCSI UNMAP(TRIM) 명령을 지원한다. 이 명령은 삭제된 블록에서 공간을 회수하는 데 사용된다.
Files (파일 서비스)
뉴타닉스 Files를 통해 사용자는 뉴타닉스 플랫폼을 고가용성 파일 서버로 활용할 수 있다. 이를 통해 사용자는 홈 디렉토리와 파일을 저장할 수 있는 단일 네임스페이스를 사용할 수 있다.
지원 환경 (Supported Configurations)
솔루션은 아래 구성에 적용할 수 있다 (목록이 불완전할 수 있으니 전체 지원 목록은 관련 문서를 참조).
핵심 사용 사례:
- 홈 폴더 / 사용자 프로파일 (Home folders / user profiles)
- 파일 스토리지 (File storage)
- 미디어 리파지토리 (Media repository)
- 영구 컨테이너 스토리지 (Persistent container storage)
관리 인터페이스:
- 프리즘 엘리먼트 (PE: Prism Element)
- 프리즘 센트럴 (PC: Prism Central)
하이퍼바이저:
- AHV
- ESXi
업그레이드:
- 프리즘
호환되는 기능:
- 뉴타닉스 스냅샷 및 DR
- Files 공유 레벨 복제 및 DR (Smart DR)
- S3 호환 스토리지에 Files 티어링 (Smart Tier)
- WPV(Windows Previous Version)를 포함한 파일 레벨 스냅샷
- 셀프 서비스 리스토어
- CFT 백업
파일 프로토콜:
- SMB 2
- SMB 3
- NFS v4
- NFS v3
Files 컨스트럭트 (Files Constructs)
이 기능은 몇 가지 하이-레벨 컨스트럭트로 구성된다.
- 파일 서버 (File Server)
- 하이-레벨 네임스페이스. 각 파일 서버에는 배포된 자체 Files VM(FSVM) 세트가 있다.
- 공유 (Share)
- 사용자에게 노출된 공유. 파일 서버는 여러 공유를 가질 수 있다 (e.g. 부서별 공유 등).
- 폴더 (Folder)
- 파일 스토리지를 위한 폴더. 폴더는 FSVM 전체에 걸쳐 분할된다.
그림은 컨스트럭트의 하이-레벨 매핑을 보여준다.
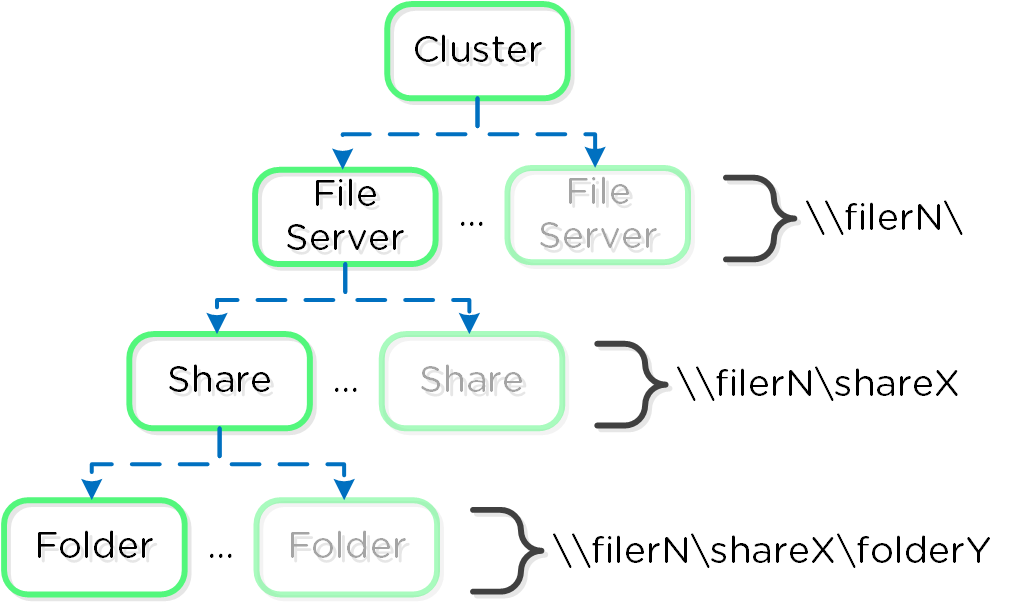 Files 매핑 (Files Mapping)
Files 매핑 (Files Mapping)
뉴타닉스 Files 기능은 가용성과 확장성을 보장하기 위해 뉴타닉스 플랫폼과 동일한 분산 방법을 따른다. 파일 서버 배포의 일부로 최소 3개의 FSVM이 배포된다.
그림은 컴포넌트의 자세한 뷰를 보여준다.
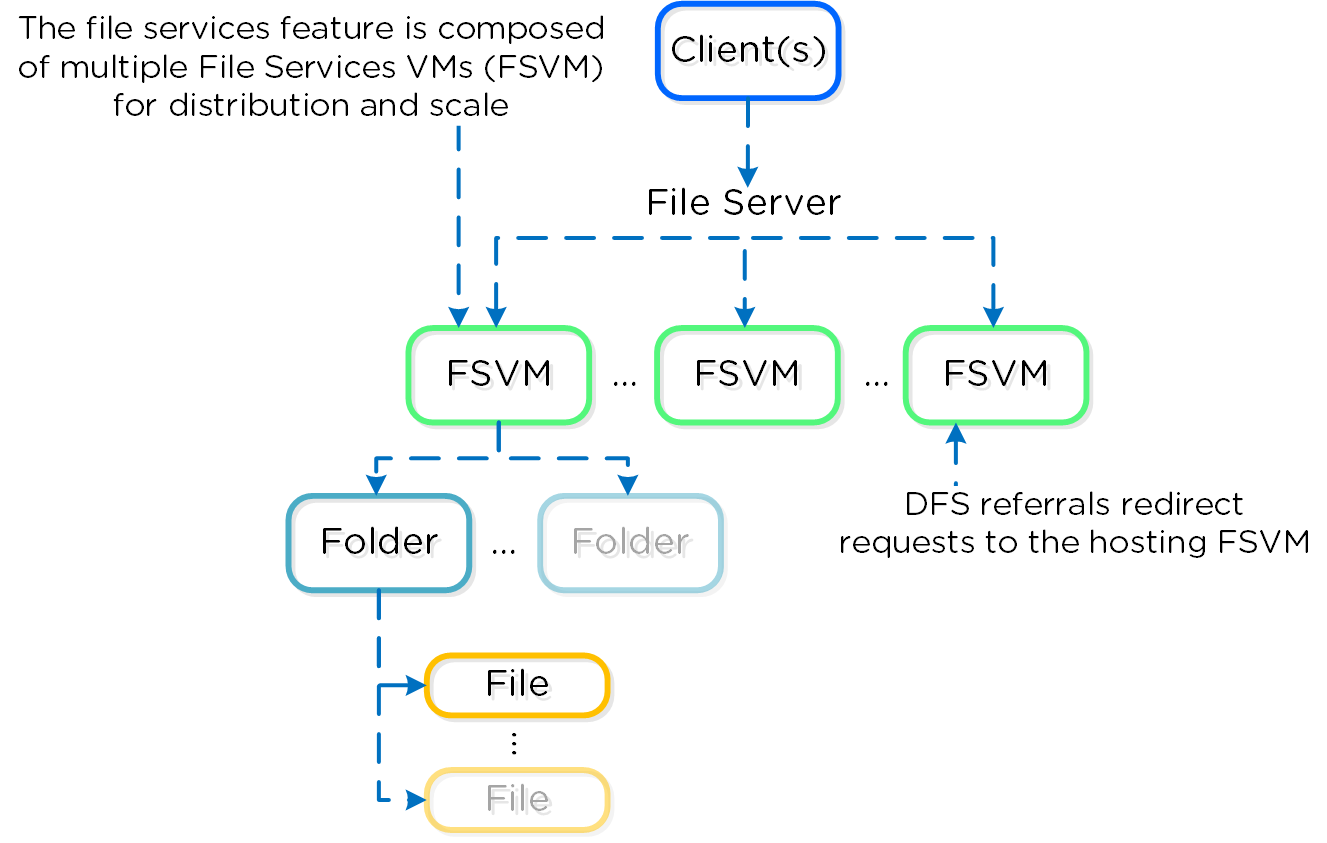 Files 상세 정보 (Files Detail)
Files 상세 정보 (Files Detail)
FSVM은 Files 클러스터로 불리는 논리 파일 서버 인스턴스로 결합된다. 단일 뉴타닉스 클러스터 내에 여러 Files 클러스터를 생성할 수 있다. FSVM은 설정 프로세스의 일부로 투명하게 배포된다.
이 그림은 AOS 플랫폼의 FSVM에 대한 자세한 뷰를 보여준다.
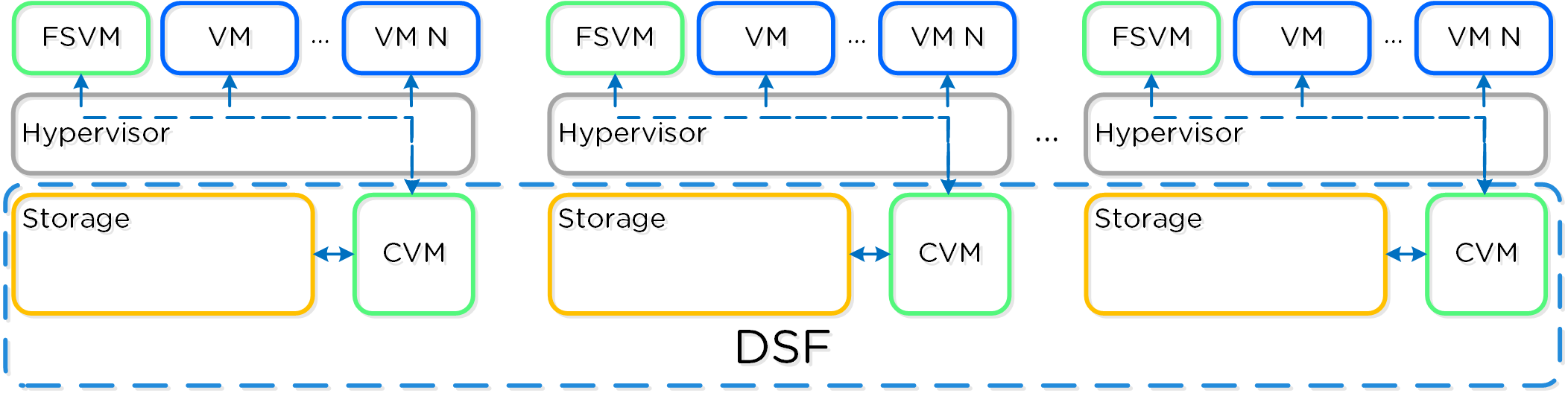 FSVM 배포 아키텍처 (FSVM Deployment Arch)
FSVM 배포 아키텍처 (FSVM Deployment Arch)
인증 및 권한 (Authentication and Authorization)
뉴타닉스 Files 기능은 Microsoft AD와 DNS에 완전히 통합되어 있다. 이를 통해 AD의 안전하고 확립된 인증 및 권한 부여 기능을 모두 활용할 수 있다. 모든 공유 권한, 사용자 및 그룹 관리는 파일 관리를 위한 기존 Windows MMC를 사용하여 수행된다.
설치 프로세스의 일부로서 다음 AD/DNS 오브젝트가 생성된다.
- 파일 서버의 AD 컴퓨터 계정
- 파일 서버 및 각 FSVM의 AD SPN(Service Principal Name)
- 모든 FSVM을 가리키는 파일 서버의 DNS 엔트리
- 각 FSVM의 DNS 엔트리
Note
파일 서버 생성을 위한 AD 권한 (AD Privileges for File Server Creation)
AD 및 DNS 오브젝트가 생성될 때 도메인 서비스 또는 이와 동등한 권한이 있는 사용자 계정을 사용하여 파일 서비스 기능을 배포해야 한다.
고가용성 (HA)
각 FSVM은 게스트 내 iSCSI를 통해 액세스되는 데이터 스토리지를 위해 Volumes API를 활용한다. 이를 통해 FSVM 장애 시에 모든 FSVM은 모든 iSCSI 타깃에 연결할 수 있다.
그림은 FSVM 스토리지에 대한 하이-레벨 개요를 보여준다.
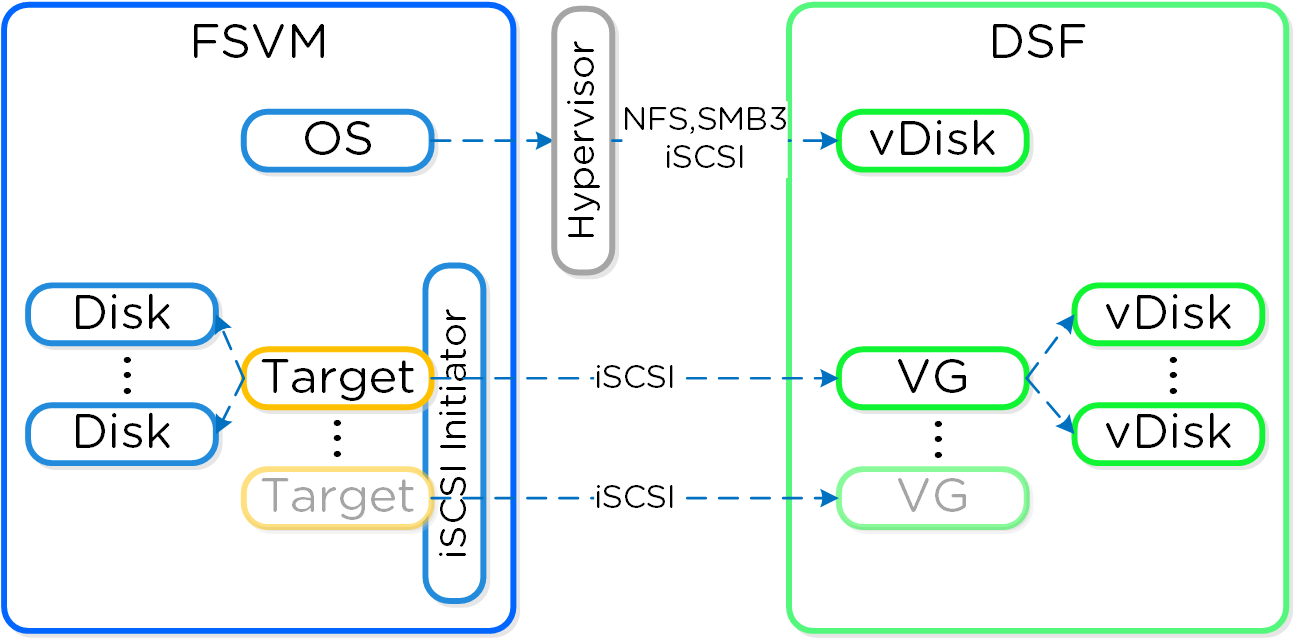 FSVM 스토리지 (FSVM Storage)
FSVM 스토리지 (FSVM Storage)
CVM이 가용하지 않은 경우(예: 활성 경로 다운), iSCSI 리디렉션을 사용하여 대상을 다른 CVM으로 페일오버한 다음 IO를 인계한다.
 FSVM 스토리지 페일오버 (FSVM Storage Failover)
FSVM 스토리지 페일오버 (FSVM Storage Failover)
오리지널 CVM이 정상 상태로 돌아오면 IO를 제공하기 위한 활성 경로로 표시된다.
정상적인 운영 환경에서 각 FSVM은 다른 VG와 패시브 연결을 갖는 데이터 스토리지를 위해 자체 VG와 통신한다. 각 FSVM에는 클라이언트가 DFS 참조 프로세스의 일부로 FSVM과 통신하기 위해 사용하는 IP가 있다. DFS 참조 프로세스가 공유 및 폴더를 호스팅하는 정확한 IP에 연결하기 때문에 클라이언트는 각 개별 FSVM의 IP를 알 필요가 없다.
 FSVM 정상 오퍼레이션 (FSVM Normal Operation)
FSVM 정상 오퍼레이션 (FSVM Normal Operation)
FSVM 장애(e.g. 유지 보수 또는 전원 끄기 등)가 발생한 경우 클라이언트 가용성을 보장하기 위해 장애가 발생한 FSVM의 IP 및 VG는 다른 FSVM으로 인계된다.
그림은 장애가 발생한 FSVM의 IP와 VG의 전송을 보여준다.
 FSVM 장애 시나리오 (FSVM Failure Scenario)
FSVM 장애 시나리오 (FSVM Failure Scenario)
장애가 발생한 FSVM이 다시 돌아와 안정적인 상태가 되면 FSVM은 자신의 IP와 VG을 다시 가져와서 클라이언트에게 IO 서비스를 계속 제공한다.
Objects (오브젝트 서비스)
뉴타닉스 Objects 기능은 S3 호환 API(S3 추가 정보: LINK)를 통해 확장성과 내구성이 뛰어난 오브젝트 서비스를 제공한다. 뉴타닉스 Objects가 뉴타닉스 플랫폼에 배포되면 압축, Erasure Coding, 복제 등과 같은 AOS 기능을 활용할 수 있다. Objects는 AOS 5.11에서 도입되었다.
지원 환경 (Supported Configurations)
솔루션은 아래 구성에 적용할 수 있다 (목록이 불완전할 수 있으니 전체 지원 목록은 관련 문서를 참조).
핵심 사용 사례:
- 규정 준수 수준 WORM이 있는 백업 대상
- PACS/VNA, 이메일, 장기 백업을 위한 아카이브 대상
- Data Lakes, AI/ML 워크로드, 분석, 머신 로깅, SIEM, Pub/Sub를 포함한 빅 데이터
- DevOps, 클라우드 네이티브, 콘텐츠 저장소, K8s
관리 인터페이스:
- 프리즘 센트럴
하이퍼바이저:
- N/A - 뉴타닉스 MSP에서 실행 (MSP를 지원하는 하이퍼바이저에 의존)
업그레이드:
- LCM
주요 기능:
- WORM
- Versioning
- Legal Hold
- Multiprotocol
- Streaming Replication
- Multi-part Upload
- Fast Copy
- S3 Select
지원되는 프로토콜:
- S3 (버전 4)
- NFSv3
Note
뉴타닉스 마이크로서비스 플랫폼 (Nutanix Microservices Platform)
뉴타닉스 Objects는 뉴타닉스 마이크로서비스 플랫폼(MSP)을 활용하며 이를 활용하는 최초의 핵심 서비스 중 하나이다.
뉴타닉스 MSP는 IAM(Identity and Access Management) 및 LB(Load Balancing)와 같은 Objects 컴포넌트와 관련된 컨테이너 및 플랫폼 서비스를 배포하기 위한 공통 프레임워크 및 서비스를 제공한다.
핵심 용어 (Key terms)
다음과 같은 핵심 용어가 이 섹션에서 사용되며 다음에 정의된다.
- 버킷 (Bucket)
- 사용자에게 노출되고 오브젝트를 포함하는 조직 단위(Organization Unit)(파일 서버에서 파일에 대한 공유를 생각하세요). 배포에는 일반적으로 여러 버킷이 있을 수 있다 (e.g. 부서, 구획 등)
- 오브젝트 (Object)
- API(GET/PUT)를 통해 인터페이스되는 스토리지 및 항목의 실제 단위(BLOB)
- S3
- 오리지널 오브젝트 서비스를 설명하는 데 사용되는 용어인 AWS(Amazon Web Services)는 현재 오브젝트 서비스와 동의어로 사용된다. S3는 또한 프로젝트 전반에 걸쳐 많이 활용되는 오브젝트 API를 정의하는 데 사용된다.
- 워커 VM (Worker VMs)
- 다양한 컨테이너화된 오브젝트 서비스를 호스팅하는 오브젝트 저장소 배포 중에 생성된 가상 머신이다. 오브젝트 노드(Object Node)라고도 한다.
- 오브젝트 브라우저 (Objects Browser)
- 사용자가 웹 브라우저에서 직접 오브젝트 저장소 인스턴스를 시작하고 버킷 및 오브젝트 수준 작업을 수행할 수 있도록 하는 사용자 인터페이스(UI)이다.
그림은 개념적 구조의 하이-레벨 매핑을 보여준다.
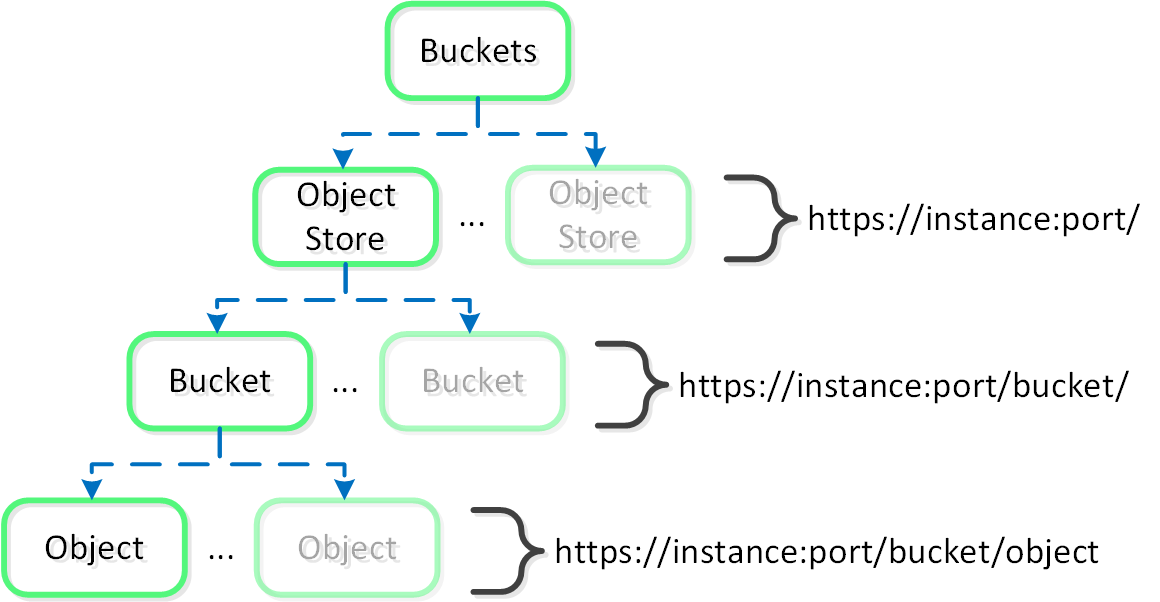 Objects - 계층구조 (Objects - Hierarchy)
Objects - 계층구조 (Objects - Hierarchy)
Objects 컨스트럭트 (Objects Constructs)
이 기능은 몇 가지 하이-레벨 컨스트럭트로 구성된다.
- 로드 밸런서 (Load Balancer)
- 로드 밸런서는 뉴타닉스 MSP의 일부로서 서비스 및 데이터 요청의 프록시 역할을 한다. 이를 통해 Objects 컨테이너 간에 서비스 및 로드 밸런싱을 위한 고가용성이 보장된다.
- 서비스 매니저 (Service Manager)
- 서비스 매니저는 모든 UI 요청에 대한 엔드포인트 역할을 하며 오브젝트 스토어 인스턴스를 관리한다. 또한 인스턴스에서 통계 수집을 담당한다.
- 메타데이터 서버 (Metadata Server)
- 메타데이터 서버에는 뉴타닉스 Objects 배포와 관련된 모든 메타데이터(예: 버킷, 오브젝트 등)가 포함되어 있다. 메타데이터 서버의 성능을 강화하기 위해 뉴타닉스는 ChakrDB를 개발했다. ChakrDB는 RocksDB 기반 키-값(Key-Value) 저장소를 활용하며 스토리지를 위해 뉴타닉스 Volumes을 사용한다.
- 오브젝트 컨트롤러 (Object Controller)
- 자체 개발된 데이터 경로 엔진(Data Path Engine)으로 오브젝트 데이터를 관리하고 메타데이터 서버와 메타데이터 업데이트를 코디네이션하는 역할을 수행한다. Storage Proxy API를 통해 스타게이트와 인터페이스합니다.
- 리전 매니저 (Region Manager)
- 리전 매니저는 DSF에서 모든 오브젝트 스토리지 정보(e.g. 리전)를 관리한다.
- 리전 (Region)
- 리전은 오브젝트와 뉴타닉스 vDisk의 해당 위치 간에 매핑을 제공한다. vDisk ID, 오프셋 및 길이와 유사하다.
- 아틀라스 서비스 (Atlas Service)
- 아틀라스 서비스는 맵리듀스 프레임워크를 기반으로 하며 오브젝트 라이프사이클 정책 시행, 가비지 콜렉션, 티어링 기능 등을 담당한다.
- S3 어댑터 (S3 Adapter)
- 자체 개발된 Objects 3.2의 새로운 기능인 S3 어댑터는 S3 API를 제공하고, S3 클라이언트의 API 요청은 물론 권한 부여도 처리한다. 그런 다음 오브젝트 컨트롤러로 변환되어 처리된다.
이 그림은 Objects 서비스 아키텍처의 자세한 뷰를 보여준다.
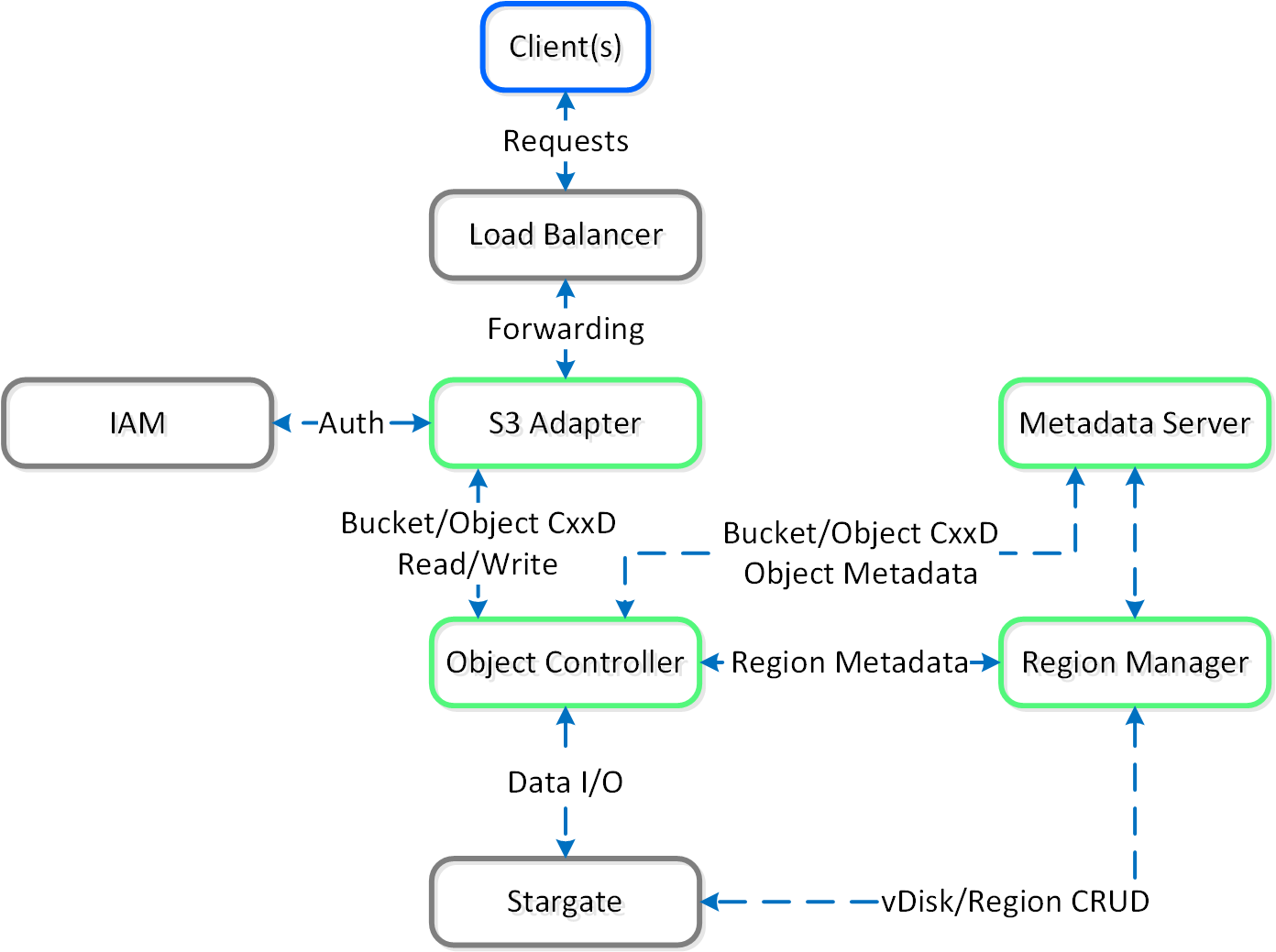 Objects - 아키텍처 (Objects - Architecture)
Objects - 아키텍처 (Objects - Architecture)
Objects와 관련된 컴포넌트는 초록색으로 표시하였다. 오브젝트를 사용하면 "덮어쓰기" 개념이 없기 때문에 CxxD가 CRUD(Create/Replace/Update/Delete)이다. 오브젝트 "덮어쓰기"에 일반적으로 사용하는 방법은 새로운 리비전을 만들거나 새로운 오브젝트를 생성하고 새로운 오브젝트를 가리키는 것이다.
Note
오픈 소스 컴포넌트 (Open Source Components)
뉴타닉스 Objects는 오픈 소스 컴포넌트를 활용하는 동시에 유기적 혁신의 조합을 통해 구축되었다. 우리는 이것이 우리 제품을 더욱 견고하고 성능 있게 만들어 고객에게 비즈니스를 위한 최상의 솔루션을 제공한다고 믿는다.
오픈 소스 라이선스 공개에 대한 추가 정보: LINK
오브젝트 스토리지 및 I/O (Object Storage and I/O)
오브젝트는 리전이라고 불리는 논리적 컨스트럭트로 저장된다. 리전은 vDisk의 고정된 공간 세그먼트이다.
그림은 vDisk와 리젼 간의 관계에 대한 예를 보여준다.
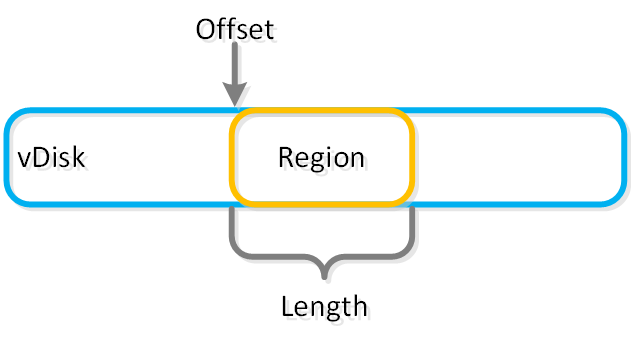 Objects - vDisk 리전 (Objects - vDisk Region)
Objects - vDisk 리전 (Objects - vDisk Region)
작은 오브젝트는 단일 리전(리전 ID, 오프셋, 길이)의 청크에 들어갈 수 있는 반면 큰 오브젝트는 리전에 걸쳐 스트라이프될 수 있다. 큰 오브젝트가 여러 리전에 걸쳐 스트라이핑된 경우 이러한 리전은 여러 vDisk에서 호스팅되어 여러 스타게이트를 동시에 활용할 수 있다.
그림은 객체, 청크 및 리전 간의 관계에 대한 예를 보여준다.
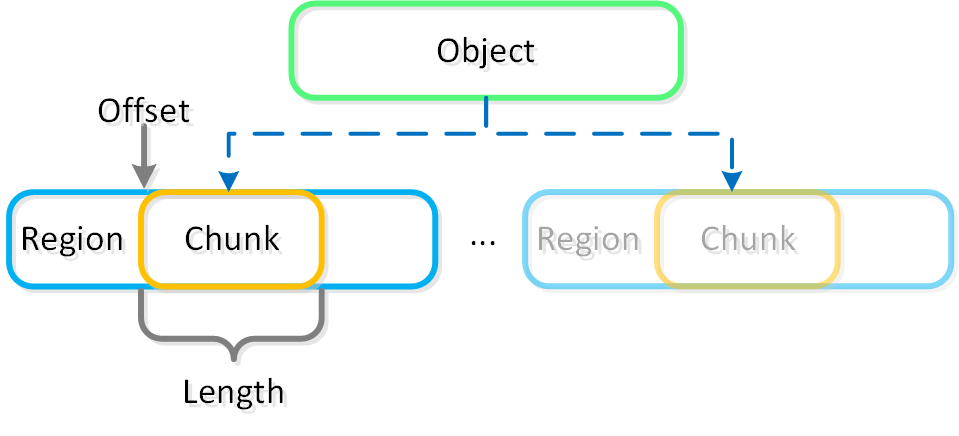 Objects - 오브젝트 청크 (Objects - Object Chunk)
Objects - 오브젝트 청크 (Objects - Object Chunk)
오브젝트 서비스 기능은 가용성과 확장성을 보장하기 위해 뉴타닉스 플랫폼과 동일한 분산 방법을 따른다. Objects 배포의 일부로 최소 3개의 오브젝트 VM이 배포된다.
Book of Network Services
본 BOOK에서는 뉴타닉스가 제공하는 네트워크 및 네트워크 보안 서비스에 대해 설명한다.
- Flow 네트워크 보안 (Flow Network Security)
- 보안 센트럴 (Security Central)
- Flow 가상 네트워킹 (Flow Virtual Networking)
다음은 이러한 제품에 대해 다른 이름으로 들어본 적이 있는 경우를 대비하여 약간의 역사가 있는 각 제품에 대한 개요이다.
뉴타닉스는 뉴타닉스 Flow를 카테고리 및 정책 기반 마이크로세그먼테이션 솔루션으로 출시했다. 이전에 Flow로 알려졌던 상태 저장 분산 마이크로세그멘테이션 방화벽은 이제 Flow 네트워크 보안(Flow Network Security)이라고 한다.
뉴타닉스는 온프레미스 및 클라우드 환경 모두에 대한 보안 계획, 위협 탐지 및 규정 준수 감사를 제공하기 위해 SaaS 기반 제품인 Beam을 출시했다. Beam의 보안 컴포넌트는 이제 보안 센트럴(Security Central)으로 부른다.
IP 주소가 겹치는 진정한 멀티-테넌트 네트워킹, 셀프 서비스 네트워크 프로비저닝 등을 위해 뉴타닉스는 현재 Flow 가상 네트워킹(Flow Virtual Networking)이라고 하는 Flow 네트워킹을 출시했다.
다음 섹션에서는 이에 대해 보다 자세히 설명한다.
Flow 네트워크 보안 (Flow Network Security)
Flow 네트워크 보안(Flow Network Security)은 AHV 플랫폼에서 실행되는 VM과 VM이 통신하는 외부 엔터티 간에 세분화된 네트워크 모니터링 및 시행을 가능하게 하는 분산 상태 저장 방화벽이다.
지원 환경 (Supported Configurations)
솔루션은 아래 구성에 적용할 수 있다.
핵심 사용 사례:
- 마이크로세그멘테이션
관리 인터페이스:
- 프리즘 센트럴
지원 환경:
- 온-프레미스:
- AHV
- Cloud:
- AWS에서 뉴타닉스 클라우드 클러스터 (Nutanix Cloud Clusters on AWS)
업그레이드:
- Flow로 LCM에 포함됨
호환되는 기능:
- 서비스 체인 (Service Chaining)
- 보안 센트럴 (Security Central)
- Calm
설정은 정책을 정의하고 카테고리에 할당하여 프리즘 센트럴을 통해 수행된다. 이를 통해 중앙에서 설정을 수행하고 여러 뉴타닉스 클러스터로 푸시할 수 있다. 각 AHV 호스트는 OpenFlow를 이용하여 규칙을 구현한다. Flow 네트워크 보안(Flow Network Security) 설정은 프리즘 센트럴에서 정책을 정의하고 VM에 카테고리를 할당함으로서 수행된다. 프리즘 센트럴은 연결된 많은 AHV 클러스터의 보안 정책 및 카테고리를 중앙에서 정의할 수 있다. 각 AHV 호스트는 분산 실행의 필요에 맞게 OVS 및 OpenFlow를 사용하여 규칙을 구현한다.
구현 컨스트럭트 (Implementation Constructs)
Flow 네트워크 보안(Flow Network Security)에는 몇 가지 주요 컨스트럭트가 있다.
카테고리 (Categories)
카테고리는 정책이 적용되는 VM 그룹을 정의하는 데 사용되는 간단한 텍스트 기반의 Key-Value 쌍이다. 일반적인 카테고리는 환경(environment), 애플리케이션 유형(application type) 및 애플리케이션 계층(application tier)이다. VM을 식별하는 데 도움이 되는 모든 키(Key) 및 값(Value) 태그를 카테고리로 사용할 수 있지만 AppType 및 AppTier와 같은 일부 카테고리는 애플리케이션 보안 정책에 필요하다.
- Category: “Key: Value” or Tag
- Examples Keys: AppType, AppTier, Group, Location
예를 들어 프로덕션 데이터베이스 서비스를 제공하는 VM에는 다음과 같은 카테고리가 할당될 수 있다.
- AppTier: Database
- AppType: Billing
- Environment: Production
그런 다음 보안 정책에서 이러한 카테고리를 활용하여 적용할 규칙이나 작업을 결정할 수 있다. 카테고리는 Flow 네트워크 보안(Flow Network Security)를 위한 것일 뿐만 아니라 보호 정책에도 이와 동일한 카테고리를 사용할 수 있다.
보안 정책 (Security Policies)
보안 정책(Security Policies)은 소스와 대상 간에 허용되는 항목을 결정하는 정의된 규칙으로 구성된다. 애플리케이션 정책 내의 규칙에는 특정 애플리케이션 계층에 대한 모든 인바운드 및 아웃바운드 트래픽이 포함된다. 단일 규칙에는 여러 소스와 여러 대상이 포함될 수 있다. 다음 예에는 AppTier: Web에 대해 정의된 단일 규칙이 있다. AppTier: Database에 허용된 트래픽을 추가하면 두 가지 규칙이 있게 된다.
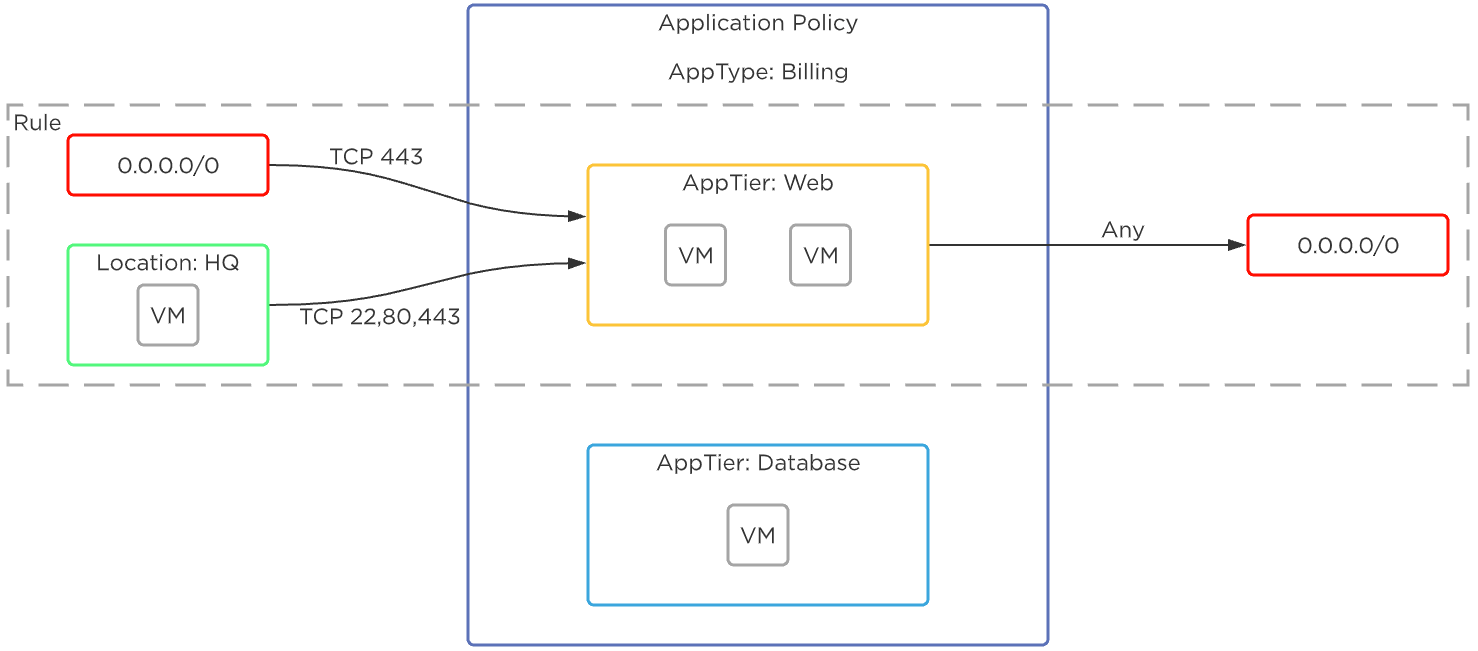 Flow 네트워크 보안 - 규칙 (Flow Network Security - Rules)
Flow 네트워크 보안 - 규칙 (Flow Network Security - Rules)
보안 정책에는 몇 가지 유형이 있으며 다음과 같은 순서로 평가된다:
- 검역 정책 (Quarantine Policy)
- 지정된 VM에 대한 모든 트래픽 거부: Strict
- 조사를 위해 특정 트래픽을 제외한 모든 트래픽 거부: Forensic
- 예제 1: 바이러스에 감염된 VM A, B, C는 바이러스가 네트워크를 추가로 감염시키지 못하도록 이들을 격리한다.
- 예제 2: VM A,B,C가 감염되었다. 이들을 격리하되 보안 팀이 분석을 위해 VM에 연결할 수 있도록 허용한다.
- 격리 정책 (Isolation Policy)
- 두 카테고리 간의 트래픽을 거부하고 카테고리 내의 트래픽은 허용한다.
- 예제: 테넌트 A를 테넌트 B와 분리하고, 환경을 복제하고 정상적인 네트워크 통신에 영향을 주지 않고 병렬로 실행할 수 있다.
- 애플리케이션 정책 (Application Policy)
- 이것은 트랜스포트(TCP/UDP), 포트 및 소스/대상이 허용되는지를 정의할 수 있는 일반적인 5-튜플 규칙이다.
- 트랜스포트 허용: Port(s) To,From
- 예제: Location:HQ 카테고리의 VM에서 AppTier:Web 카테고리의 VM으로 TCP 443 허용
- VDI 정책 (VDI Policy)
- 로그인한 사용자의 AD 그룹을 기반으로 VDI VM에 카테고리를 적용하는 ID 기반 방화벽.
- 할당된 AD 그룹을 기반으로 정책 구현
다음은 Flow 네트워크 보안(Flow Network Security)을 활용하여 샘플 애플리케이션에서 트래픽을 제어하는 예제를 보여준다.
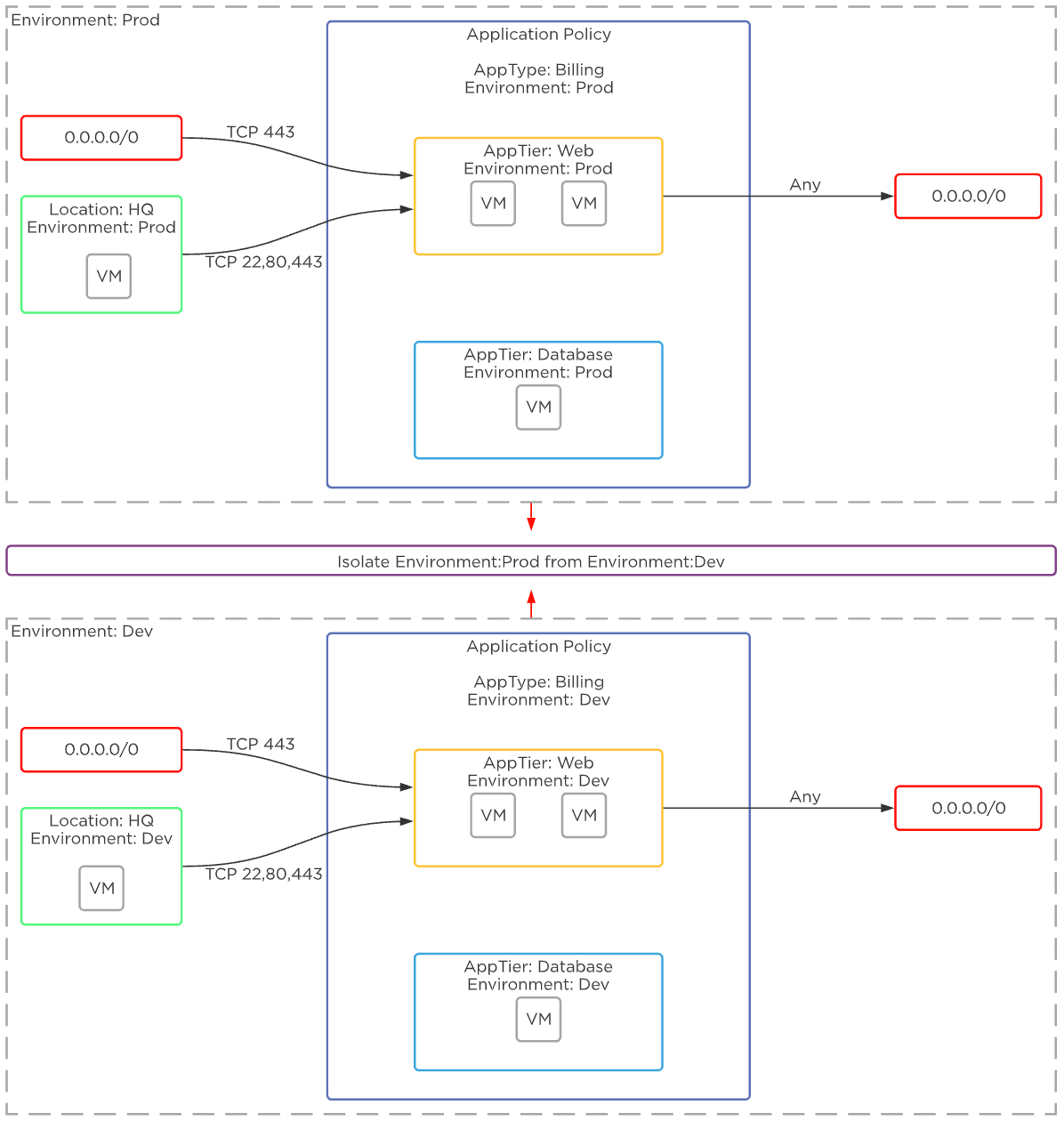 Flow 네트워크 보안 - 예제 애플리케이션 (Flow Network Security - Example Application)
Flow 네트워크 보안 - 예제 애플리케이션 (Flow Network Security - Example Application)
정책 상태 (Policy State)
정책 상태(Policy State)는 규칙이 일치할 때 수행할 작업을 결정한다. Flow 네트워크 보안(Flow Network Security)에는 두 가지 주요 상태가 있다.
- 시행 (Enforce)
- 정의된 흐름(flow)만 허용하고 나머지는 모두 삭제(drop)하여 정책을 시행한다.
- 모니터 (Monitor)
- 모든 흐름(flow)을 허용하되 정책 시각화 페이지에서 정책을 위반한 패킷을 강조 표시한다.
규칙 시행 (Rule Enforcement)
Flow 네트워크 보안(Flow Network Security) 정책은 패킷이 UVM을 떠나고 다른 VM에 도달하기 전에 패킷에 적용된다. 이것은 AHV 호스트의 마이크로세그멘테이션 브리지(br.microseg)에서 수행된다.
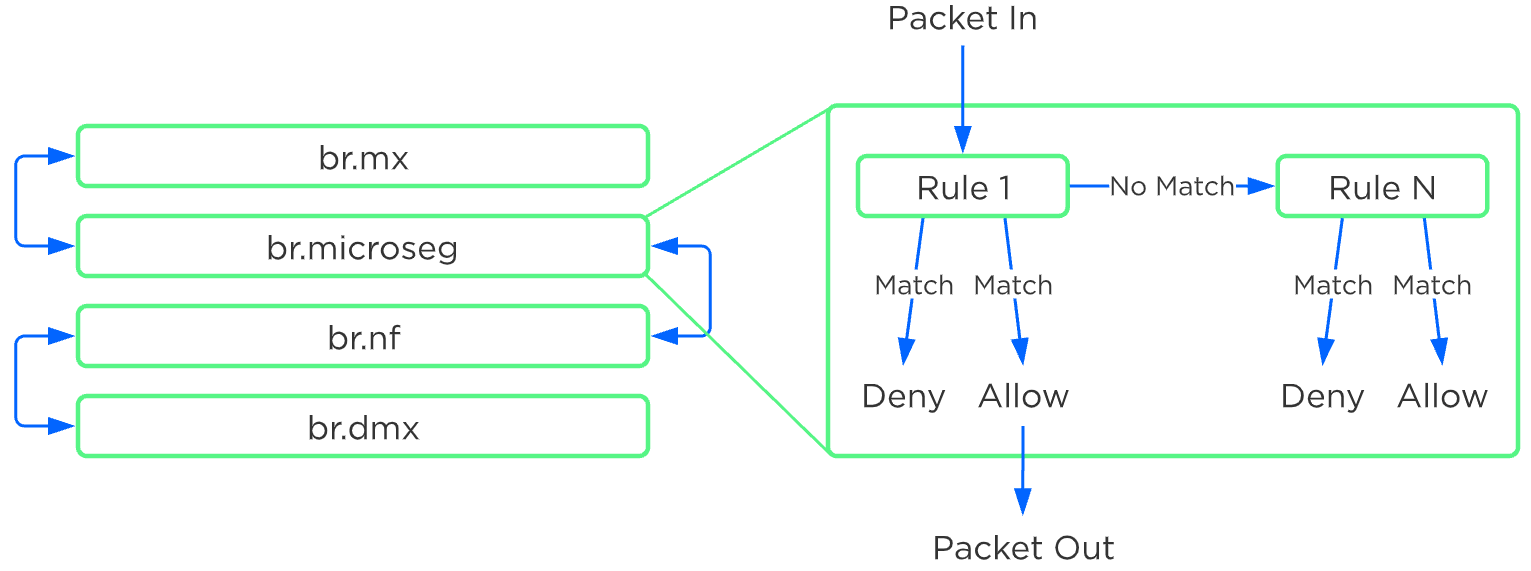 Flow 네트워크 보안 - 규칙 순서 개요 (Flow Network Security - Rule Order Overview)
Flow 네트워크 보안 - 규칙 순서 개요 (Flow Network Security - Rule Order Overview)
정책은 카테고리를 기반으로 구축되지만 규칙 시행은 감지된 VM IP 주소를 기반으로 수행된다. Flow 네트워크 보안(Flow Network Security)의 작업은 모든 VM에 할당된 카테고리와 정책을 평가한 다음 보호된 VM이 실행되는 호스트의 br.microseg 브리지에 올바른 규칙을 프로그래밍하는 것이다. 뉴타닉스 AHV IPAM을 사용하는 VM은 NIC이 프로비저닝되는 즉시 알려진 IP 주소를 가지며 VM의 전원이 켜질 때 규칙이 프로그래밍된다. 뉴타닉스 아크로폴리스 프로세스는 DHCP 및 ARP 메시지를 가로채서 고정 IP 또는 외부 DHCP가 있는 VM의 IP 주소를 감지한다. 이러한 VM의 경우 VM IP가 알려지는 즉시 규칙이 적용된다.
검역(Quarantine), 애플리케이션(Application) 및 VDI 정책에 대한 규칙 평가는 감지된 IPv4 주소를 기반으로 한다.
격리(Isolation) 정책에 대한 규칙 평가는 IPv4 주소와 VM MAC 주소를 모두 기반으로 한다.
평가 순서는 다음 순서에 기반하여 먼저 일치하는 것을 기준으로 한다.
- 검역 (Quarantine)
- 격리 (Isolation)
- 애플리케이션 (Application)
- VDI
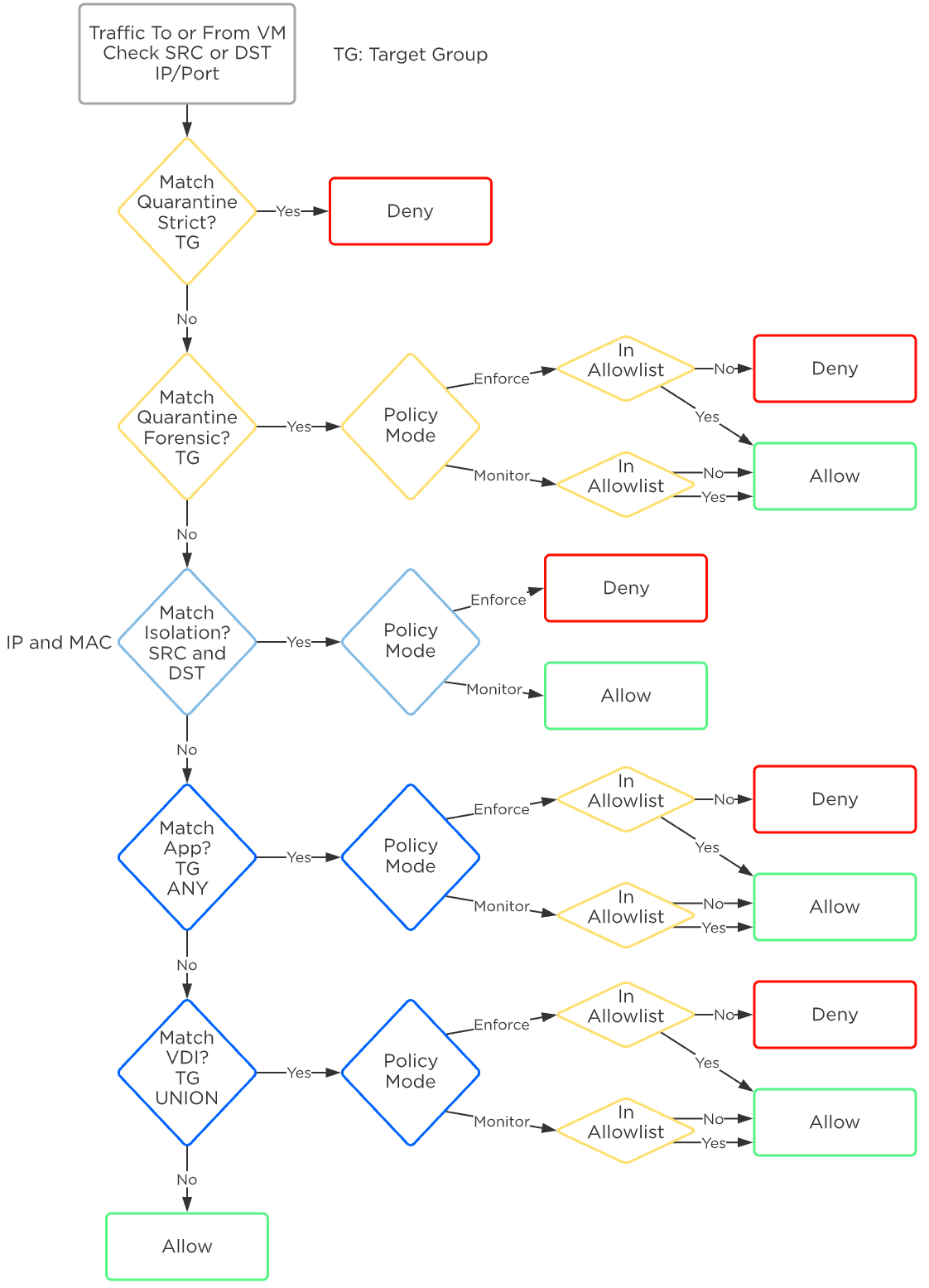 Flow 네트워크 보안 - 정책 적용 순서 (Flow Network Security - Policy Order)
Flow 네트워크 보안 - 정책 적용 순서 (Flow Network Security - Policy Order)
일치하는 첫 번째 정책에는 작업이 수행되고 모든 추가 처리가 중지된다. 예를 들어 트래픽이 모니터링 모드에 있는 격리 정책을 만나면 수행되는 액션은 트래픽을 전달하고 허용 및 모니터링되는 것으로 기록하는 것이다. 목록 아래에 있는 애플리케이션 또는 VDI 정책이 본 트래픽을 차단하더라도 추가 규칙은 평가되지 않는다.
또한 VM은 하나의 AppType 카테고리에만 속할 수 있으며, AppType 카테고리에서는 단일 AppType 정책의 대상 그룹에만 속할 수 있다. 즉, 모든 VM은 하나의 AppType 정책의 대상 그룹에만 속할 수 있다. VM으로 들어오고 나가는 모든 트래픽은 이 단일 AppType 정책에서 정의되어야 한다. 현재 VM이 여러 애플리케이션 정책의 중심에 있다는 개념이 없으므로 애플리케이션 정책 간에 충돌이나 평가 순서에 대한 문제는 발생하지 않는다.
보안 센트럴 (Security Central)
뉴타닉스 보안 센트럴(Security Central)은 마이크로세그멘테이션 보안 계획, 위협 탐지 경고 및 지속적인 규정 준수 모니터링을 제공하는 SaaS(Software as a Service) 기반 제품이다. Louvain, Arima, 트리 기반 및 클러스터링과 같은 여러 머신 러닝(ML) 모델 및 알고리즘을 사용하는 보안 센트럴은 500개 이상의 감사 체크 및 보안 모범 사례를 기반으로 온-프레미스 배포의 보안에 대한 통찰력을 제공한다.
보안 센트럴 포털(https://flow.nutanix.com/securitycentral)은 클라우드 및 온-프레미스 인프라에 대한 인벤토리 및 설정 평가를 제공하여 일반적인 설정 오류와 고위험 설정 오류를 스캔한다. 보안 센트럴 사용자는 쿼리와 같은 커스텀 또는 시스템 정의 SQL을 사용하여 보안 상태에 대한 즉각적인 통찰력을 얻을 수도 있다. 이러한 인벤토리를 기반으로 하고 규정 준수 추적 도구와 함께 보안 상태 모니터링도 제공된다. 마지막으로, 온-프레미스 AHV 클러스터에서 수집된 네트워크 흐름 데이터는 트래픽 패턴의 머신 러닝 분석을 기반으로 거의 실시간 위협 탐지를 제공한다.
지원되는 환경
- 뉴타닉스 온-프레미스
- Flow 네트워크 보안 기능이 활성화된 AHV를 사용하는 프라이빗 클라우드
- 퍼블릭 클라우드(AWS 및 Microsoft Azure)
- 퍼블릭 클라우드 인프라 내 자원 및 서비스 모니터링
관리 인터페이스:
- 뉴타닉스 보안 센트럴 SaaS UI
- Flow 보안 센트럴 VM (FSC VM)
- 초기 설정 및 필요한 경우에 업그레이드
구현 컨스트럭트
보안 센트럴(Security Central)은 보안 모니터링 및 관리 프레임워크를 제공하기 위해 몇 가지 새로운 컨스트럭트를 도입하였다. 도입된 2가지 요소는 다음과 같다:
- Flow 보안 센트럴 VM (FSC VM) [뉴타닉스 온-프레미스 환경에서만 필요]
- 초기 설정 중에 사용됨 (Used during initial configuration)
- IPFix 로그 수집기 (IPFix log collection)
- 인벤토리 컬렉션 (Inventory collection)
- 보안 정책 설정을 푸시 (Push security policy configurations)
- 보안 센트럴 SaaS (Security Central SaaS)
- 보안 상태 모니터링 (Security posture monitoring)
- 사용자 및 네트워크 이상 징후 탐지 (User & Network anomaly detection)
- 규정 준수 보고 (Compliance reporting)
- 마이크로세그멘테이션 보안 계획 (Microsegmentation Security planning)
- 다중-클라우드 인벤토리 (Multi-cloud Inventory)
업그레이드
- 보안 센트럴(Security Central)은 SaaS 플랫폼이므로 자동 업그레이드
- 새로운 기능이 릴리즈되면 다음 로그인 시에 사용할 수 있다.
- 경우에 따라 기능 향상을 위해 온-프레미스 FSC VM으로 업그레이드해야 할 수 있다.
- 설정 페이지의 Flow 보안 센트럴 VM UI에서 업그레이드를 수행할 수 있다.
- 최신 FSC VM 이미지(GUI 및 서버 전용)는 뉴타닉스 포탈에 있다.
보안 센트럴 아키텍처 개요
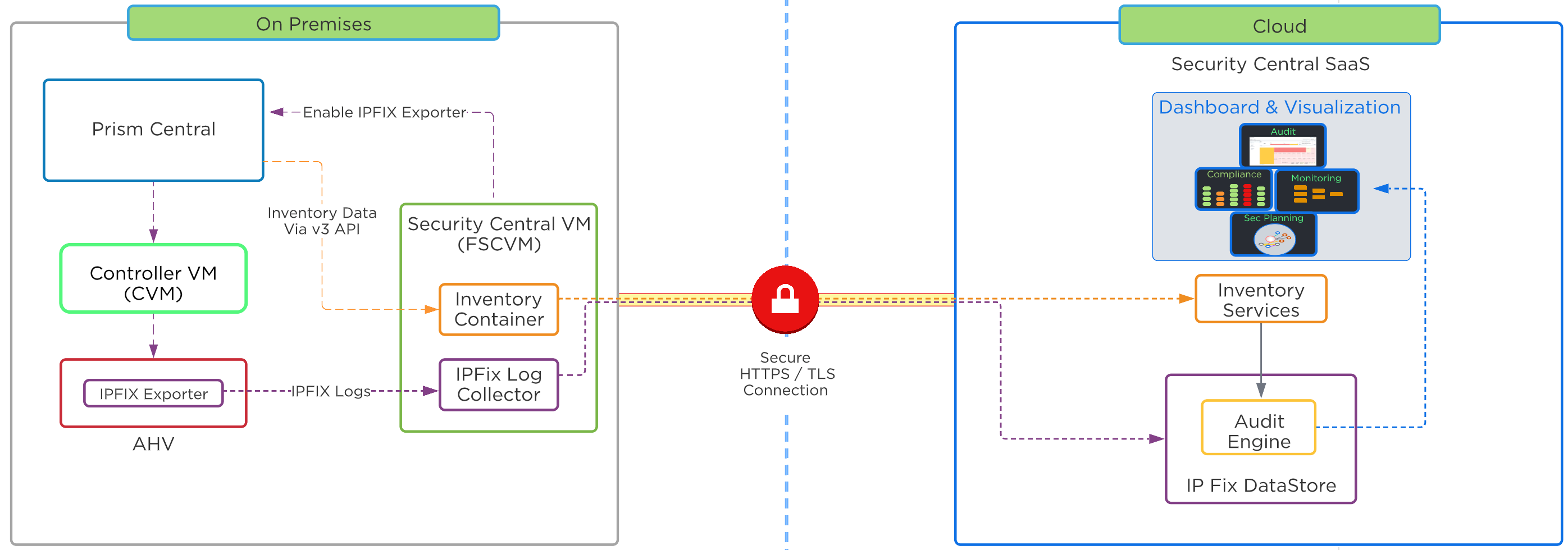 보안 센트럴 아키텍처 개요 (Security Central Architecture Overview)
보안 센트럴 아키텍처 개요 (Security Central Architecture Overview)
보안 센트럴 하이-레벨 아키텍처 상세 내용 (Security Central High Level Architecture Detail)
보안 센트럴(Security Central)은 FSC VM이라는 새로운 서비스 VM을 도입했는데, 이것은 뉴타닉스 온-프레미스 환경에서 보안 모니터링을 활성화하는 데 필요하다. FSC VM은 프록시 역할을 하고 온-프레미스 클러스터에서 정보를 집계한다. 그런 다음 보안 네트워크 연결을 통해 이러한 정보를 보안 센트럴로 보넨다. FSC VM은 환경 및 VM(메타데이터)에 대한 인벤토리 정보를 수집한다. 버안 센트럴은 설치된 소프트웨어 패키지 및 버전과 같이 VM이 소유한 데이터를 수집하지 않지만, Qualys와 같은 파트너 에이전트와의 통합을 통해 사용 가능한 경고를 강화할 수 있다.
설치가 완료되면 관리자는 FSC VM UI에 연결하고 네트워크 로그 수집을 활성화한다. 그러면 FSC VM은 프리즘 센트럴 인스턴스가 관리하는 모든 AHV 클러스터에서 IPFIX 내보내기를 활성화하도록 프리즘 센트럴에 지시한다. FSC VM은 또한 등록된 모든 클러스터 및 VM에 대해 프리즘 센트럴에서 클러스터 인벤토리 정보를 수집한다. 수집된 인벤토리 정보에는 VM 이름, 연결된 네트워크 정보, 설정 정보 및 프리즘 센트럴의 VM에 할당될 수 있는 카테고리와 같은 항목이 포함된다. 인벤토리 폴링은 3시간마다 반복되며 SaaS 포털은 변경 사항을 기록하고 분석을 수행할 수 있다.
인벤토리 및 IPFix 로그는 HTTPS/TLS 연결을 사용하여 보안 센트럴 SaaS 환경으로 안전하게 전송된다. IPFix 로그는 15분 간격으로 전송되어 FSC VM이 데이터를 일괄 증분으로 전송할 수 있도록 하여 FSC VM에 필요한 스토리지 용량을 줄이고 클라우드에 대한 네트워크 제약을 줄인다. 관리자는 필요한 경우 FSC VM을 사용하여 클라우드에 필요한 인벤토리 업데이트를 수동으로 푸시할 수 있다.
FSC VM은 해당 PC에서 관리하는 클러스터 수에 관계없이 각 프리즘 센트럴(PC) 배포에 필요하다. FSC VM은 프리즘 센트럴에 대한 내부 통신과 FSC-SaaS 포털에 대한 아웃바운드 통신을 용이하게 한다. 보안 센트럴은 컴포넌트 간의 통신을 위해 아래 나열된 TCP 포트를 사용한다. 방화벽에 다음 포트가 열려 있는지 확인한다:
- FSC VM이 프리즘 센트럴 VM에 연결하기 위한 TCP 포트 9440
- *.nutanix.com 및 *.amazonaws.com에 연결하기 위한 FSC VM의 TCP 포트 443
FSC 플랫폼은 엄격한 보안 통제를 받는다. FSC 규정 준수 인증을 확인하고 자세히 알아보려면 뉴타닉스 트러스트를 방문하세요.
Flow 보안 센트럴 VM 설정을 위한 요구 사항:
Flow 보안 센트럴 VM에 대한 설정 요구 사항을 충족하는지 확인하려면 보안 센트럴 가이드를 참조한다.
핵심 사용 사례
- 모니터링 및 가시성 (Monitoring and Visibility)
- 다중 클라우드 대시보드, 자산 인벤토리, 보고 및 경고
- 감사 및 복원 (Audit and Remediation)
- 실시간 자동 보안 감사를 사용하여 뉴타닉스 환경 및 퍼블릭 클라우드에 대한 통찰력
- 규정 준수 (Compliance)
- 환경을 지속적으로 모니터링하고 규정 준수 체크를 자동화하며 STIG PCI HIPAA에 추가된 취약점을 해결
- 보안 계획 (Security Planning)
- VM 간 네트워크 트래픽 시각화/토폴로지/맵 보기, 워크로드 분류, 자동화된 보안 정책 권장 사항 및 정책 시행
- 위반 사항 조사 (Investigating Violations)
- 쿼리 언어와 같은 SQL로 자세한 조사 수행
- 위협 탐지 경고 (Threat Detection Alerting)
- 네트워크 및 사용자 기반 이상 징후 탐지
보안 센트럴 주요 기능
메인 대시보드 (Main Dashboard)
보안 센트럴(Security Central)에 성공적으로 로그인한 후 표시되는 첫 번째 화면은 메인 대시보드이다. 대시보드는 보안 센트럴에서 모니터링하고 경고하는 여러 영역을 한 눈에 볼 수 있도록 한다. 각 개별 위젯의 컨텍스트에서 보다 자세한 정보를 볼 수 있다.
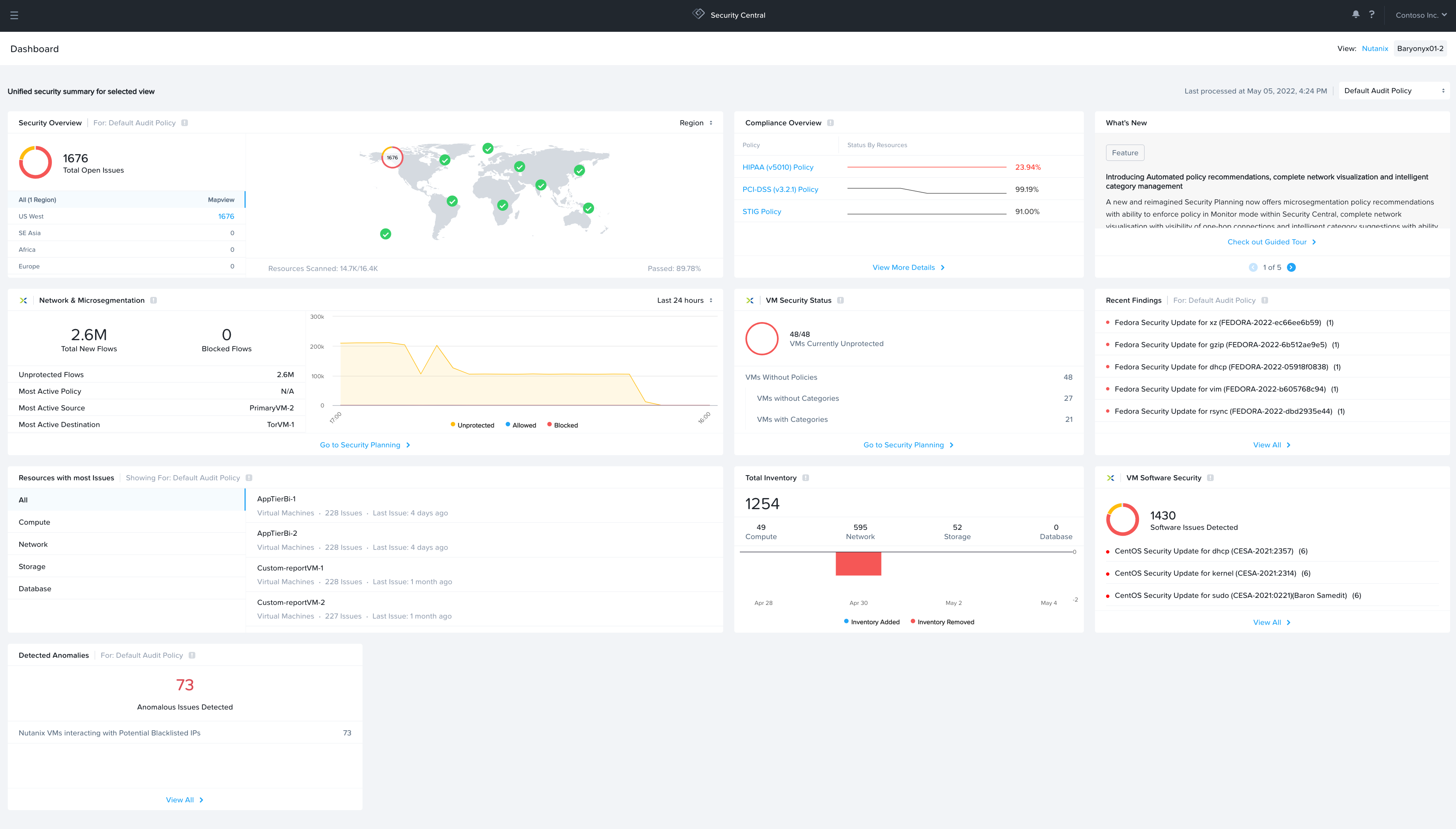 보안 센트럴 메인 대시보드 (Security Central Main Dashboard)
보안 센트럴 메인 대시보드 (Security Central Main Dashboard)
감사 및 복원 (Audit and Remediation)
보안 감사를 활용하면 온-프레미스 배포의 보안에 대한 깊은 통찰력을 얻을 수 있다. 보안 센트럴(Security Central)은 환경에 대해 즉시 사용 가능한 500개 이상의 자동화된 보안 감사를 실행하고 복원 단계와 함께 감사 실패 정보를 리포팅한다. 보안 센트럴 감사 체크는 다음 카테고리 및 뉴타닉스 보안 모범 사례에 따른다:
- 액세스 보안 (Access Security)
- 권한 없는 액세스 또는 액세스 결함 감사를 허용할 수 있는 항목에 대한 설정 및 경고
- 데이터 보안 (Data Security)
- Data-at-Rest Encryption(DARE)가 활성화되지 않은 뉴타닉스 클러스터. DARE는 인프라를 보호하는 데 필수적인 컴포넌트이다. DARE는 암호화된 키를 소유하지 않은 시스템 및 사용자가 데이터에 무단으로 액세스하는 것을 방지한다.
- 호스트 보안 (Host Security)
- 백업 보호가 활성화되지 않은 뉴타닉스 VM은 랜섬웨어에 감염된 경우 복구하기 어렵다.
- 로깅 및 모니터링 (Logging & Monitoring)
- 프리즘 센트럴에서 'Critical Alerts is Unacknowledged'인 것은 경고가 무시되거나 누락되었음을 나타낼 수 있다. 이러한 경고는 인프라를 위험에 빠뜨릴 수 있는 잠재적인 노출 위험을 나타낼 수 있다.
- 네트워크 보안 (Network Security)
- VM은 모든 소스의 모든 트래픽을 허용하므로 악의적인 행위자가 VM을 손상시키고 환경에 침투할 수 있는 매우 심각한 위협이 될 수 있다.
지속적으로 업데이트되는 내장된 감사 외에도, 보안 센트럴(Security Central)은 CQL(Common Query Language)을 사용하여 감사 및 보고서를 커스터마이징할 수 있는 기능을 제공한다. 이를 통해 클라우드 인벤토리에서 다양한 속성에 대한 CQL 쿼리를 실행하고 특정 사용 사례에 대한 감사 체크을 생성할 수 있다.
규정 준수 (Compliance)
규정 준수(Compliance)는 많은 뉴타닉스 고객에게 매우 중요하다. 규정 준수를 유지하면 회사의 운영 환경이 준수해야 관리 표준을 충족하는지 확인할 수 있다. 규정 준수를 위한 모니터링 환경은 어렵고 시간이 많이 소요될 수 있다. 끊임없이 변화하는 요구 사항, 규정 및 환경을 파악하려면 지속적인 규정 준수 모니터링 기능이 필요하다. 고객은 이러한 체크를 자동화하여 간결한 뷰를 통해 규정 준수 위반의 해결 시간을 단축할 수 있다.
보안 센트럴은 뉴타닉스 STIG 정책을 사용하여 PCI-DSS, HIPAA, NIST 및 뉴타닉스 보안 모범 사례와 같은 일반적인 규제 프레임워크에 대한 감사 체크를 제공한다. 규정 준수 대시보드는 모니터링되는 각 프레임워크에 대한 규정 준수 점수를 제공한다. 점수 엘리먼트는 모니터링 및 감사되는 주어진 프레임워크의 요소, 통과된 검사 수 및 실패한 검사 수를 보기 위해 추가로 검사할 수 있다. 규정 준수 보기는 실패한 체크, 체크가 연결된 프레임워크 섹션, 실패한 체크로 보고하기 위해 발견된 문제와 같은 상세 정보를 제공한다. 규정 준수 보고서 및 해당 상세 정보는 오프라인 사용 및 공유를 위해 내보낼 수도 있다. 보안 센트럴은 또한 비즈니스 요구 사항을 기반으로 커스텀 감사 및 커스텀 규정 준수 정책을 생성할 수 있는 확장 가능한 기능을 제공한다.
발견 정보 및 경고 (Findings and Alerts)
“"잘 설명된 문제는 반쯤 해결된 문제이다." - Charles Kettering
끊임없이 변화하는 위협 환경에서 보안 모니터링 및 경고는 오늘날의 환경에서 매우 중요하다. 네트워크, 보안 컨트롤, 서버, 엔드포인트 및 사용자 애플리케이션에서 발견된 위협과 취약성을 지속적으로 모니터링하고 경고함으로써, 전반적인 보안 태세를 강화하고 문제가 감지되었을 때 보다 빠른 해결 시간을 제공하기 위해 경고에 대한 사전 예방적 접근을 허용한다.
보안 센트럴(Security Central) 내의 'Findings and Alerts' 뷰는 현재 보안 상태에 대한 정보를 제공한다. 'Findings and Alerts' 뷰는 보안 센트럴에서 모니터링 중인 뉴타닉스 클러스터에서 관찰된 이상 행위와 탐지된 설정 이슈를 표시한다. 이러한 결과는 선택한 감사 정책을 기반으로 한다. 이러한 이슈가 표시되는 방식을 커스터마이징할 수 있는 기능이 제공되므로 사용자는 감사 카테고리, 자원, 역할 및 비즈니스 요구 사항에 따라 결과를 조정할 수 있는 뛰어난 유연성을 갖는다.
위협 탐지 경고(Threat Detection Alerts)는 'Findings and Alerts' 뷰에 포함된다. 보안 센트럴은 뉴타닉스 IPFix 네트워크 로그를 분석하여 모니터링되는 뉴타닉스 클러스터 내에서 발생하는 관찰된 잠재적 위협 및 비정상적인 동작을 감지하고 리포팅한다. 이러한 경고는 머신 러닝(ML) 및 관찰된 데이터 포인트를 사용하여 모델링된다. 다음은 이상 징후에 대해 엔트리 및 경고를 트리거하기 위해 관찰해야 하는 최소 일수 또는 데이터 포인트와 함께 감지되는 잠재적 위협 및 행위의 일부이다:
- 블랙리스트에 있는 IP(알려진 의심되는 IP)와 통신하는 VM
- 1 데이터-포인트
- 잠재적인 딕셔너리 공격을 갖는 VM
- 1 데이터-포인트
- 잠재적인 DDOS(Denial of Service)를 갖는 VM
- 21일
- 비정상적인 네트워크 동작이 있는 VLAN
- 21일
- 비정상적인 네트워크 동작이 있는 VM
- 21일
- 잠재적인 포트 스캔 공격이 있는 VM
- 21일
- 데이터 유출 공격 가능성이 있는 VM
- 21일
보안 계획 (Security Planning)
애플리케이션 보안을 계획할 때 효과적인 보안 정책을 생성하는 데 필요한 검색 및 정보 수집과 관련된 많은 컴포넌트가 있다. 이러한 정보를 수집하는 것은 상당히 어려울 수 있다. 애플리케이션의 통신 프로파일을 이해하기 위해 방화벽, 네트워킹 장비, 애플리케이션 및 OS 로그를 수집해야햐 할 필요가 있다. 해당 데이터를 수집되고 분석한 후에, 애플리케이션 소유자와 상의하여 관찰된 결과를 예상 동작과 비교할 필요가 있다.
보안 센트럴(Security Central)의 ML 기반 보안 계획은 애플리케이션 보안 정책을 검색하고 계획하는 데 도움이 되는 상세한 시각화 정보를 제공한다. 뉴타닉스 온-프레미스 클러스터 내에서 네트워크 트래픽 흐름을 시각화할 수 있으며, 보안 센트럴은 애플리케이션을 분류하고 보호하는 방법에 대한 권장 사항을 제공한다.
보안 계획 섹션에서는 애플리케이션 및 환경에 대해 최대 2개 수준의 그룹화를 유연하게 활용할 수 있다. 이 기능을 사용하면 분석을 특정 클러스터, VLAN, VM 및 카테고리로 드릴다운할 수 있으므로 애플리케이션 보안에 집중하는 데 매우 유용하다. 이 그룹화를 사용하면 추가 오프라인 공유, 검색 및 계획을 위해 관찰되거나 필터링된 모든 네트워크 트래픽을 다운로드할 수도 있다.
고유한 기계 학습 기능을 사용하여 보안 센트럴(Security Central)은 관찰된 네트워크 흐름을 기반으로 VM에 카테고리 권장 사항 및 할당을 수행하는 기능을 제공한다. 이는 새로운 마이크로세그멘테이션 또는 애플리케이션 배포에서 특히 유용할 수 있다. 애플리케이션 VM을 분류하는 것은 애플리케이션 보안을 위한 중요한 단계이다. 한 단계 더 나아가 보안 센트럴(Security Central)은 인바운드 및 아웃바운드 규칙 권장 사항을 생성하고, 뉴타닉스 AHV 클러스터의 모니터링 모드에서 애플리케이션 보안 정책을 생성할 수도 있다.
모니터링 모드의 보안 정책을 사용하면, 정책 액션를 적용하지 않고도 보안 중인 애플리케이션의 동작을 관찰할 수 있다. 정책을 시행하기 전에 필요한 경우 프리즘 센트럴을 사용하여 정책을 편집할 수 있다.
통합 (Integrations)
보안 아키텍처는 종종 심층 방어 태세를 구축하기 위한 여러 벤더의 솔루션으로 구성된다. 위협 및 취약성에 대해 엔드포인트를 모니터링하는 솔루션, 티켓팅 시스템, 로그 관리, 위협 및 이벤트 분석은 모두 보안 아키텍처의 중요한 컴포넌트가 될 수 있다. 이러한 제품은 필수적이지만 보안 인프라의 다른 컴포넌트와의 제한된 통합으로 인해 독립 실행형인 경우가 많다. 통합은 보안 아키텍처의 컨스트럭트 내에서 보안 솔루션을 제공하는 데 매우 중요하다. 이는 효율성을 높이고 위협 인지, 분석 및 위협 해결 시간을 단축한다.
보안 센트럴(Security Central)은 뉴타닉스가 제공하지 않는 애플리케이션을 보안 센트럴과 직접 통합할 수 있는 기능을 제공한다. 이러한 통합은 OS 수준 모니터링 및 보호에서 엔터프라이즈 티켓팅 시스템 및 분석 엔진에 이르기까지 다양한 솔루션을 포함한다. 지원되는 통합 기능 중의 일부는 다음과 같다:
- Splunk
- Webhook
- ServiceNow
- Qualys
각 통합의 상세 정보에 대한 자세한 내용은 보안 센트럴 가이드(Security Central Guide)에서 확인할 수 있다.
Flow 가상 네트워킹 (Flow Virtual Networking)
Flow 가상 네트워킹(Flow Virtual Networking)을 사용하면 물리적 네트워크와 분리된 완전히 격리된 가상 네트워크를 만들 수 있다. IP 주소가 겹치는 다중 테넌트 네트워크 프로비저닝, 셀프 서비스 네트워크 프로비저닝 및 IP 주소 보존을 수행할 수 있다.
지원되는 설정 (Supported Configurations)
주요 사용 사례:
- 멀티-테넌트 네트워킹 (Multi-tenant networking)
- 네트워크 격리 (Network isolation)
- IP 주소 오버래핑 (Overlapping IP addresses)
- 셀프-서비스 네트워크 생성 (Self-service network creation)
- VM IP 모빌리티 (VM IP mobility)
- 하이브리드 클라우드 연결 (Hybrid Cloud connectivity)
관리 인터페이스:
- 프리즘 센트럴 (PC)
지원되는 환경:
- 온-프레미스:
- AHV
업그레이드:
- 메이저 기능 업그레이드는 다음에 의존
- 프리즘 센트럴
- AHV
- 마이너 기능 업그레이드는 ICM에 포함
- 고급 네트워크 컨트롤러 (Advanced Network Controller)
- 네트워크 게이트웨어 (VPN) [Network Gateway (VPN)]
구현 컨스트럭트
Flow 가상 네트워킹(Flow Virtual Networking)은 완벽한 네트워킹 솔루션을 제공하기 위해 몇 개의 새로운 컨스트럭트를 도입한다.
- VPCs
- Overlay Subnets
- Routes
- Policies
- External Networks
- NAT
- Routed (NoNAT)
- Network Gateway
- Layer 3 VPN
- Layer 2 Extended Subnets with VXLAN
VPCs (Virtual Private Clouds)
VPC 또는 Virtual Private Cloud는 Flow 가상 네트워킹(Flow Virtual Networking)의 기본 단위이다. 각 VPC는 VPC 내부의 모든 서브넷을 연결하는 가상 라우터 인스턴스가 있는 격리된 네트워크 네임스페이스이다. 이것은 한 VPC 내부의 IP 주소가 다른 VPC 또는 물리적 네트워크와도 겹칠 수 있도록 한다. VPC는 동일한 프리즘 센트럴에서 관리하는 모든 클러스터를 포함하도록 확장할 수 있지만, 일반적으로 VPC는 단일 AHV 클러스터 또는 동일한 가용 영역의 클러스터 내에만 존재해야 한다. 외부 네트워크 섹션에서 보다 자세히 설명한다.
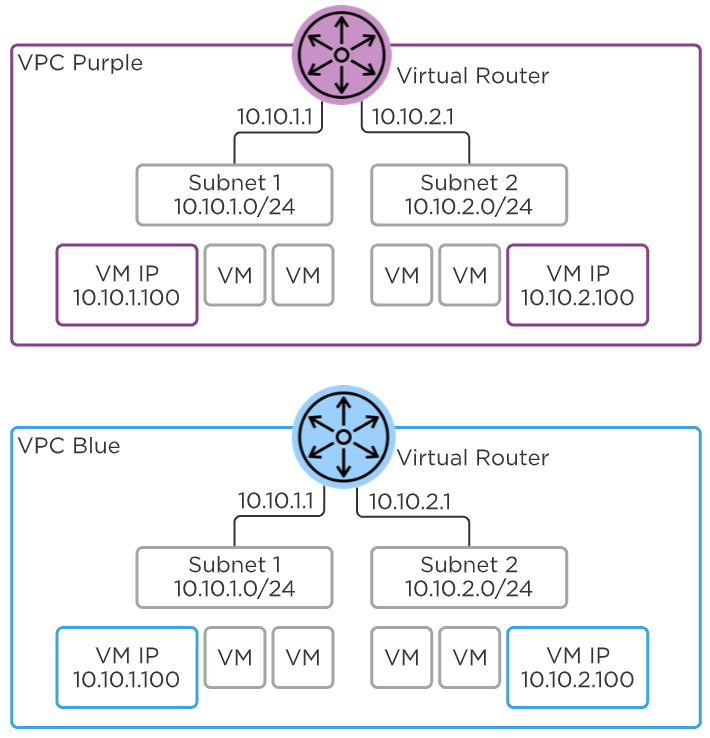 Flow 가상 네트워킹 - VPC (Flow Virtual Networking - VPC)
Flow 가상 네트워킹 - VPC (Flow Virtual Networking - VPC)
Overlay Subnets
각 VPC에는 하나 이상의 서브넷이 있을 수 있으며 모두 동일한 VPC 가상 라우터에 연결되어 있다. 배후에서 VPC는 Geneve 캡슐화를 활용하여 필요에 따라 AHV 호스트 간의 트래픽을 터널링한다. 즉, 다른 호스트의 VM이 통신하기 위해 VPC 내부의 서브넷을 생성하거나 ToR 스위치에 존재할 필요가 없다. 두 개의 서로 다른 호스트의 VPC에 있는 두 개의 VM이 서로 트래픽을 보낼 때, 패킷은 첫 번째 호스트의 Geneve에서 캡슐화되고 다른 호스트로 보내지고 캡슐을 해제한 후에 대상 VM으로 전송된다.
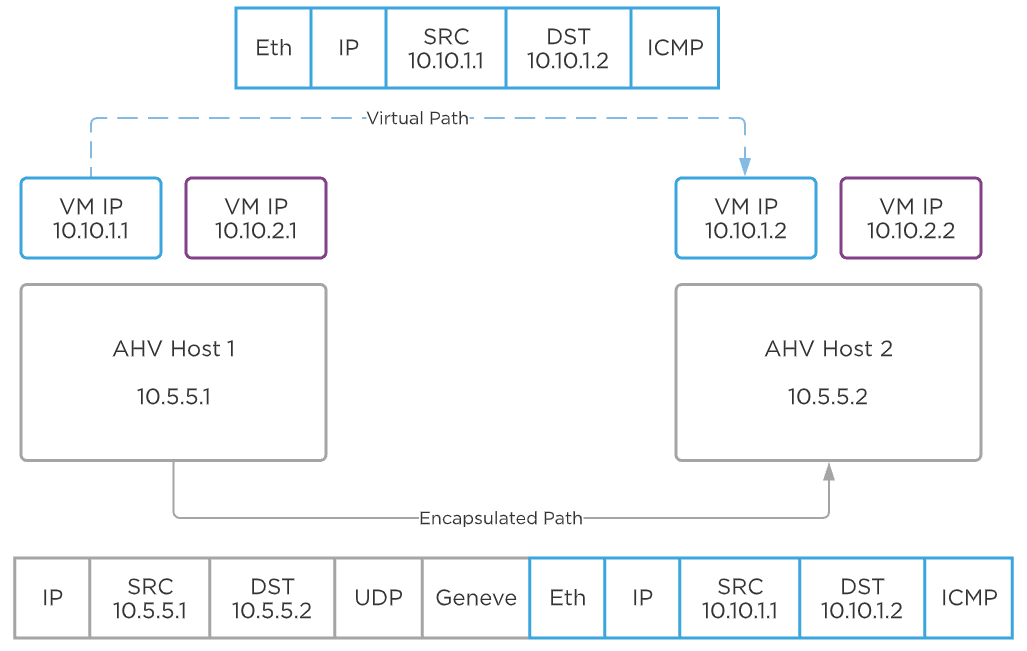 Flow 가상 네트워킹 - Geneve 캡슐화 (Flow Virtual Networking - Geneve Encapsulation)
Flow 가상 네트워킹 - Geneve 캡슐화 (Flow Virtual Networking - Geneve Encapsulation)
VM의 NIC를 선택하여 해당 NIC를 오버레이 서브넷 또는 기존 VLAN 지원 서브넷에 배치할 수 있다. 오버레이 서브넷을 선택하면 VPC도 선택된다.
Note
Pro tip
각 VM은 단일 VPC에만 배치할 수 있다. VM을 VPC와 VLAN에 동시에 연결하거나 두 개의 서로 다른 VPC에 동시에 연결할 수 없다.
Routes
모든 VPC에는 단일 가상 라우터가 포함되어 있으며 몇 가지 유형의 경로가 있다.
- External Networks
- Direct Connections
- Remote Connections
외부 네트워크(External Networks)는 전체 VPC에 대한 0.0.0.0/0 네트워크 접두사의 기본 대상이어야 한다. 사용 중인 각 외부 네트워크에 대해 대체 네트워크 접두사 경로를 선택할 수 있다. 완전히 격리된 VPC의 경우 디폴트 경로를 설정하지 않도록 선택할 수 있다.
직접 연결된 경로는 VPC 내부의 각 서브넷에 대해 생성된다. Flow 가상 네트워킹(Flow Virtual Networking)은 각 서브넷의 첫 번째 IP 주소를 해당 서브넷의 기본 게이트웨이로 할당한다. 디폴트 게이트웨이 및 네트워크 접두사는 서브넷 설정에 의해 결정되며 직접 변경할 수 없다. 동일한 호스트와 동일한 VPC에 있지만 두 개의 다른 서브넷에 있는 두 VM 간의 트래픽은 해당 호스트에서 로컬로 라우팅된다.
VPN 연결 및 외부 네트워크와 같은 원격 연결(Remote Connections)은 네트워크 접두사의 다음 홉 대상으로 설정할 수 있다.
Note
Pro tip
VPC 라우팅 테이블 내의 각 네트워크 접두사는 고유해야 한다. 동일한 대상 접두사를 사용하여 두 개의 다른 다음 홉 대상을 프로그래밍하지 않아야 한다.
Policies
가상 라우터는 VPC 내부 트래픽에 대한 컨트롤 포인트 역할을 한다. 여기에서 간단한 상태 비저장 정책을 적용할 수 있으며, 라우터를 통해 흐르는 모든 트래픽은 정책에 의해 평가된다. 동일한 서브넷 내의 한 VM에서 다른 VM으로의 트래픽은 정책을 거치지 않는다.
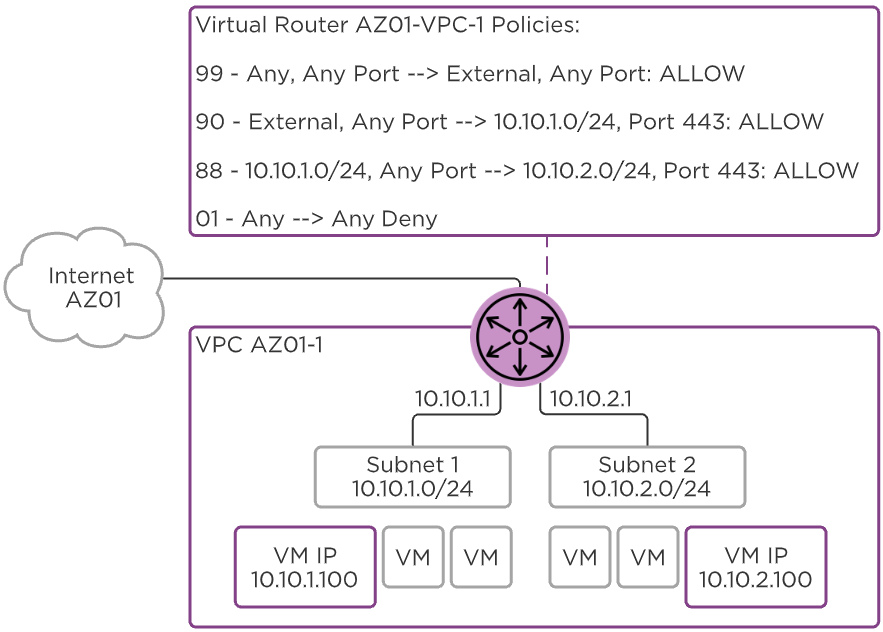 Flow 가상 네트워킹 - 정책 (Flow Virtual Networking - Policies)
Flow 가상 네트워킹 - 정책 (Flow Virtual Networking - Policies)
VPC 내에서 정책은 최고(1,000)에서 최저(10)까지 우선 순위에 따라 평가된다.
다음 값을 기반으로 트래픽을 일치시킬 수 있다.
- Source or Destination IPv4 Address
- Any
- External to the VPC (Any traffic entering the VPC)
- Custom IP Prefix
- Protocol
- Any
- Protocol Number
- TCP
- UDP
- ICMP
- Source or Destination Port Number
트래픽이 일치하면 정책에서 다음 작업을 수행할 수 있다.
- Permit
- Deny
- Reroute
- Redirect traffic to another /32 IPv4 address in another subnet
경로 재지정 정책은 VPC의 다른 서브넷 내부에서 실행되는 로드 밸런서 또는 방화벽 VM을 통해 모든 인바운드 트래픽을 라우팅하는 것과 같은 조치를 취하는 데 매우 유용하다. 여기에는 AHV 호스트 당 NFVM(Network Function VM)이 필요한 기존 서비스 체인이 아니라 VPC 내부의 모든 트래픽에 대해 단일 NFVM만 필요하다는 부가가치가 있다.
Note
Pro tip
상태 비저장 정책에는 허용(Permit) 규칙이 삭제(Drop) 규칙을 재정의하는 경우 정방향 및 역방향 모두에서 정의된 별도의 규칙이 필요하다. 그렇지 않으면 반환 트래픽이 삭제(Drop) 규칙에 의해 정의된다. 유사한 우선순위를 사용하여 일치하는 정방향 및 역방향 항목을 그룹화한다.
External Networks
외부 네트워크(External Network)는 트래픽이 VPC에 들어오고 나가는 기본 방법이다. 외부 네트워크는 프리즘 센트럴에서 생성되며 단일 프리즘 엘리먼트 클러스터에만 존재한다. 외부 네트워크는 VLAN, 디폴트 게이트웨이, IP 주소 풀 및 이를 사용하는 모든 VPC의 NAT 유형을 정의한다. 하나의 외부 네트워크는 여러 VPC에서 사용할 수 있다.
외부 네트워크에는 두 가지 유형이 있다./p>
- NAT
- Routed (NoNAT)
PC.2022.1 및 AOS 6.1부터 VPC에 대해 최대 2개의 외부 네트워크를 선택할 수 있다. VPC에는 최대 하나의 NAT 외부 네트워크와 최대 하나의 라우팅(NoNAT) 외부 네트워크가 있을 수 있다.
NAT
NAT(Network Address Translation) 외부 네트워크는 유동 IP 또는 VPC SNAT(소스 NAT) 주소 뒤의 VPC에 있는 VM의 IP 주소를 숨긴다. 각 VPC에는 외부 네트워크 IP 풀에서 임의로 선택된 SNAT IP 주소가 있으며 VPC에서 나가는 트래픽은 이 소스 주소로 재작성된다.
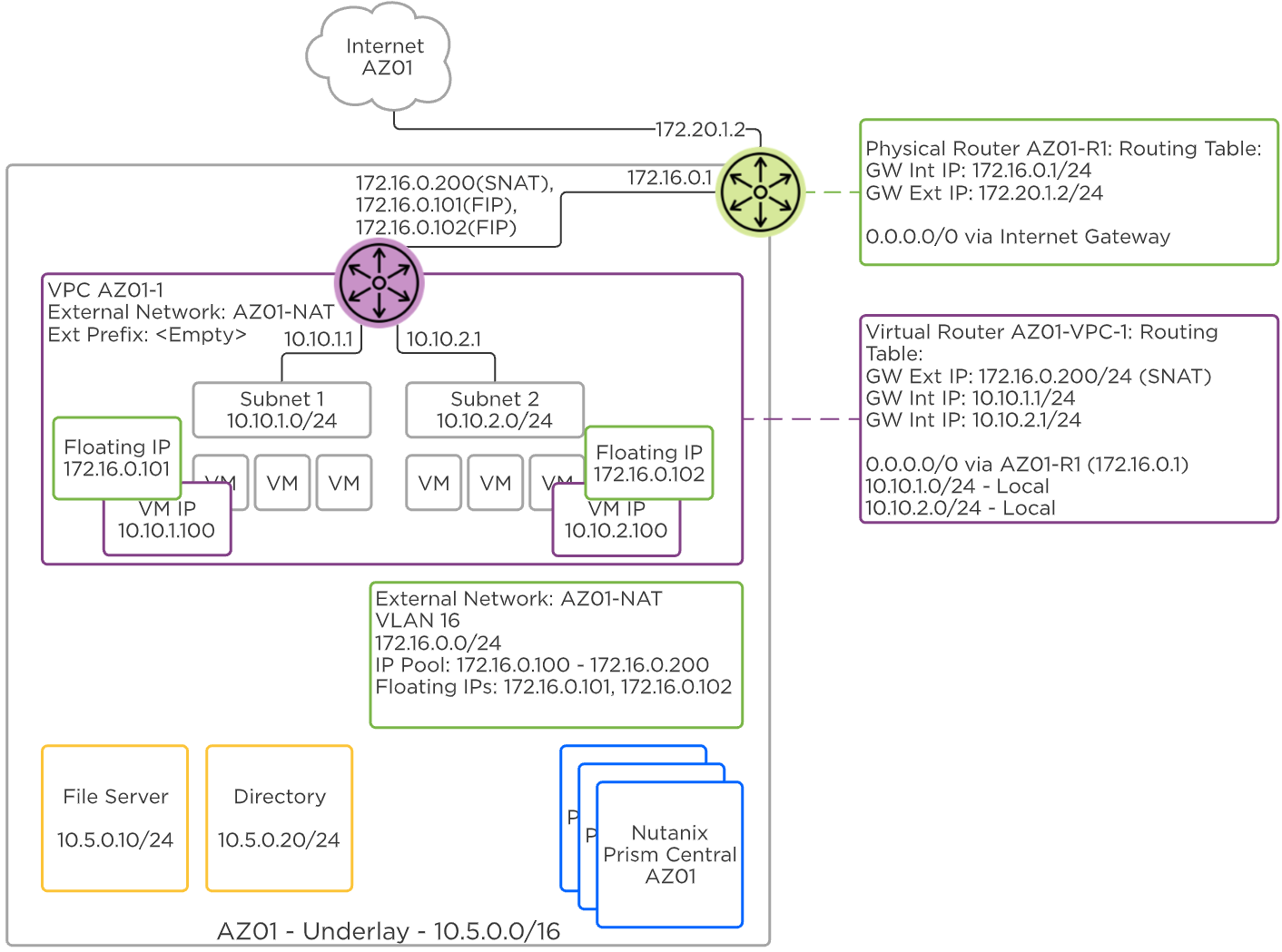 Flow 가상 네트워킹 - NAT 외부 네트워크 (Flow Virtual Networking - NAT External Network)
Flow 가상 네트워킹 - NAT 외부 네트워크 (Flow Virtual Networking - NAT External Network)
유동 IP 주소는 외부 네트워크 IP 풀에서도 선택되고 VPC의 VM에 할당되어 수신 트래픽을 허용한다. 유동 IP가 VM에 할당되면 송신 트래픽은 VPC SNAT IP 대신 유동 IP로 재작성된다. 이는 VM의 사설 IP 주소를 공개하지 않고 VPC 외부의 공개 서비스를 광고하는 데 유용하다.
Routed
라우팅 또는 NoNAT 외부 네트워크를 사용하면 라우팅을 통해 물리적 네트워크의 IP 주소 공간을 VPC 내부에서 공유할 수 있다. VPC SNAT IP 주소 대신 VPC 라우터 IP는 외부 네트워크 풀에서 임의로 선택된다. 이 VPC 라우터 IP를 물리적 네트워크 팀과 공유하면 이 가상 라우터 IP를 VPC 내부에 프로비저닝된 모든 서브넷의 다음 홉으로 설정할 수 있다.
예를 들어 외부 네트워크가 10.5.0.0/24인 VPC에는 가상 라우터 IP 10.5.0.200이 할당될 수 있다. VPC 내부의 서브넷이 10.10.0.0/16 네트워크에서 생성되는 경우 물리적 네트워크 팀은 10.5.0.200을 통해 10.10.0.0/16에 대한 경로를 생성한다. 10.10.0.0/16 네트워크는 VPC에 대해 외부에서 라우팅 가능한 접두사가 된다.
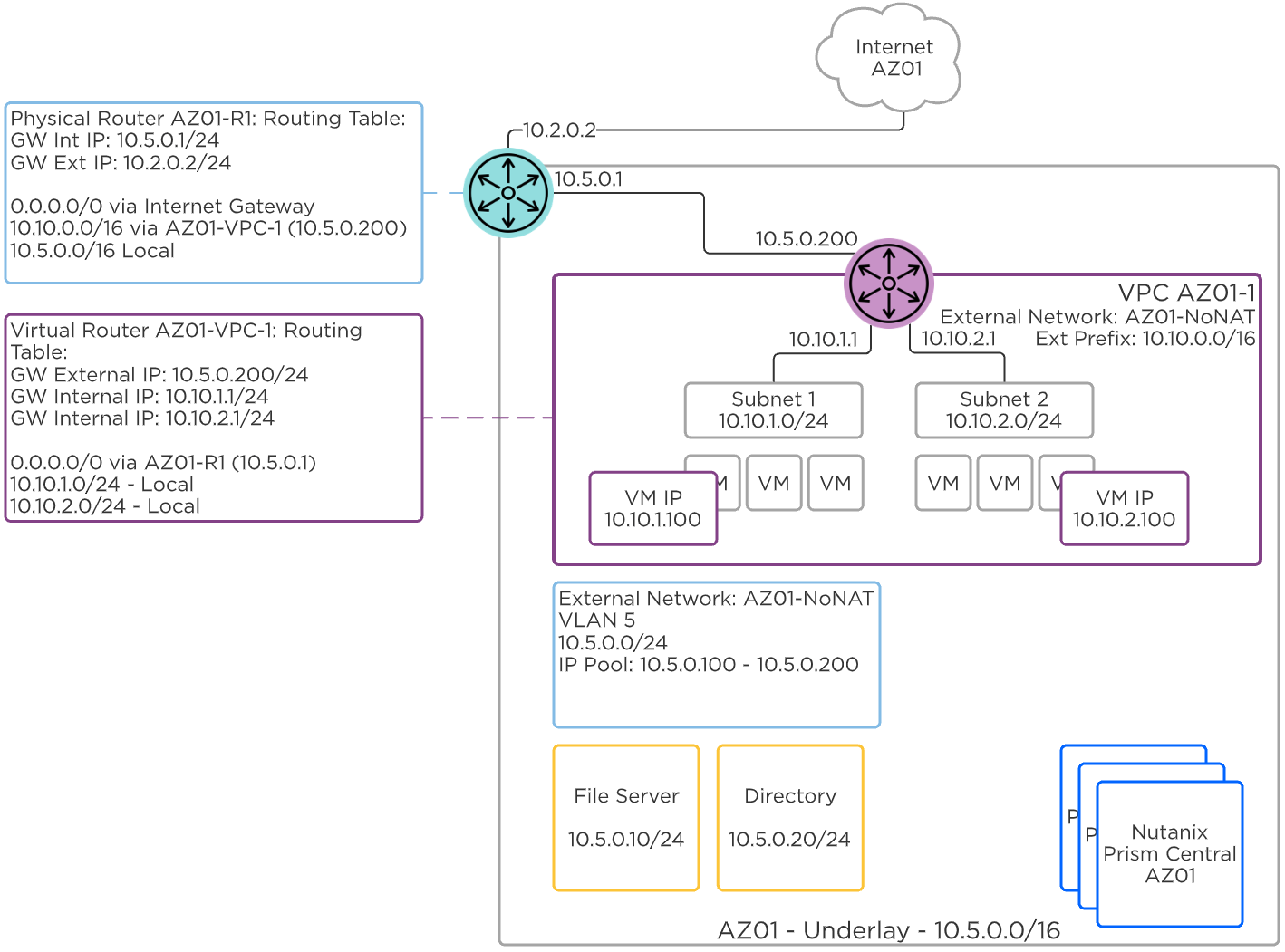 Flow 가상 네트워킹 - 라우팅된 외부 네트워크 (Flow Virtual Networking - Routed External Network)
Flow 가상 네트워킹 - 라우팅된 외부 네트워크 (Flow Virtual Networking - Routed External Network)
Network Gateways
네트워크 게이트웨이(Network Gateway)는 서브넷 간의 커넥터 역할을 한다. 이러한 서브넷은 다양한 유형과 위치에 있을 수 있다.
- Subnet Types
- ESXi VLAN
- AHV VLAN
- VPC Overlay
- Physical Network VLAN
- Subnet Locations
- On-premises VLANs
- On-premises VPCs
- Cloud VPCs
네트워크 게이트웨이에는 서브넷을 연결하는 여러 방법이 있다.
- Layer 3 VPN
- Network Gateway to Network Gateway
- Network Gateway to Physical Firewall or VPN
- Layer 2 VXLAN VTEP
- Network Gateway to Network Gateway
- Network Gateway to Physical Router or Switch VTEP
- Layer 2 VXLAN VTEP over VPN
- Network Gateway to Network Gateway
Layer 3 VPN
Layer 3 VPN 연결 유형에서는 두 개의 개별 네트워크 접두사가 있는 두 개의 서브넷이 연결된다. 예를 들어 로컬 서브넷 10.10.1.0/24는 원격 서브넷 10.10.2.0/24에 연결할 수 있다.
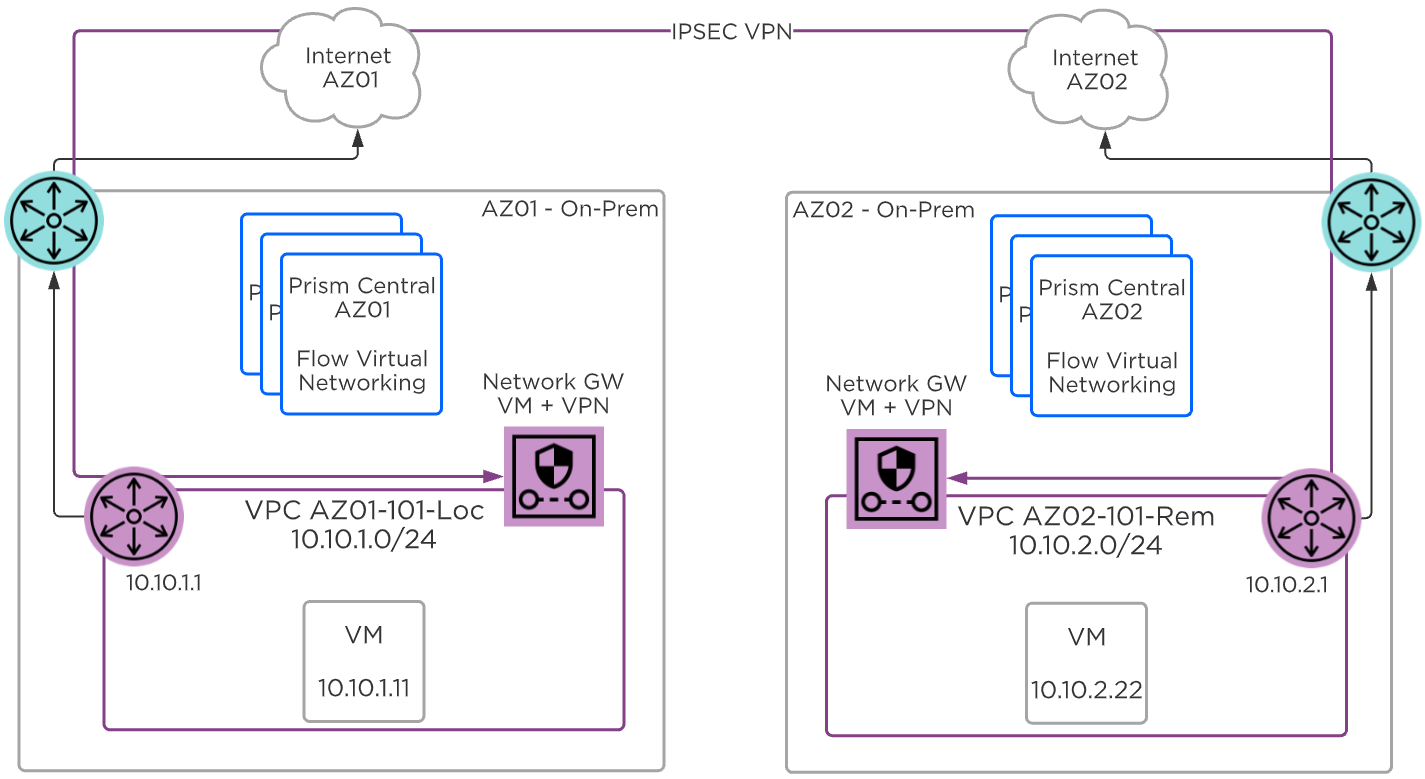 Flow 가상 네트워킹 - Layer 3 VPN (Flow Virtual Networking - Layer 3 VPN)
Flow 가상 네트워킹 - Layer 3 VPN (Flow Virtual Networking - Layer 3 VPN)
두 개의 네트워크 게이트웨이를 사용하는 경우 각 네트워크 게이트웨이에는 DHCP 풀의 외부 IP 주소가 할당되며 이러한 주소를 통해 통신할 수 있어야 한다.
네트워크 게이트웨이 VM을 원격 물리적 방화벽이나 VPN 어플라이언스 또는 VM에 연결할 수도 있다. 로컬 네트워크 게이트웨이는 여전히 원격 물리적 또는 가상 어플라이언스와 통신할 수 있어야 한다.
각 서브넷에서 원격 서브넷으로의 트래픽은 VPC 내부의 IP 라우팅을 사용하여 생성된 VPN 연결을 통해 전달된다. 경로는 정적이거나 BGP를 사용하는 네트워크 게이트웨이 간에 공유될 수 있다. 이 VPN 터널 내부의 트래픽은 IPSEC로 암호화된다.
Note
Pro tip
서브넷 간의 트래픽이 인터넷과 같은 공개 링크를 통해 이동할 때 IPSEC 암호화가 포함된 VPN을 사용한다.
Layer 2 VXLAN VTEP
Layer 2 VXLAN VTEP의 경우 동일한 네트워크 접두사를 공유하는 두 개의 서브넷이 연결된다. 예를 들어 로컬 서브넷 10.10.1.0/24는 10.10.1.0/24도 사용하는 원격 서브넷에 연결된다.
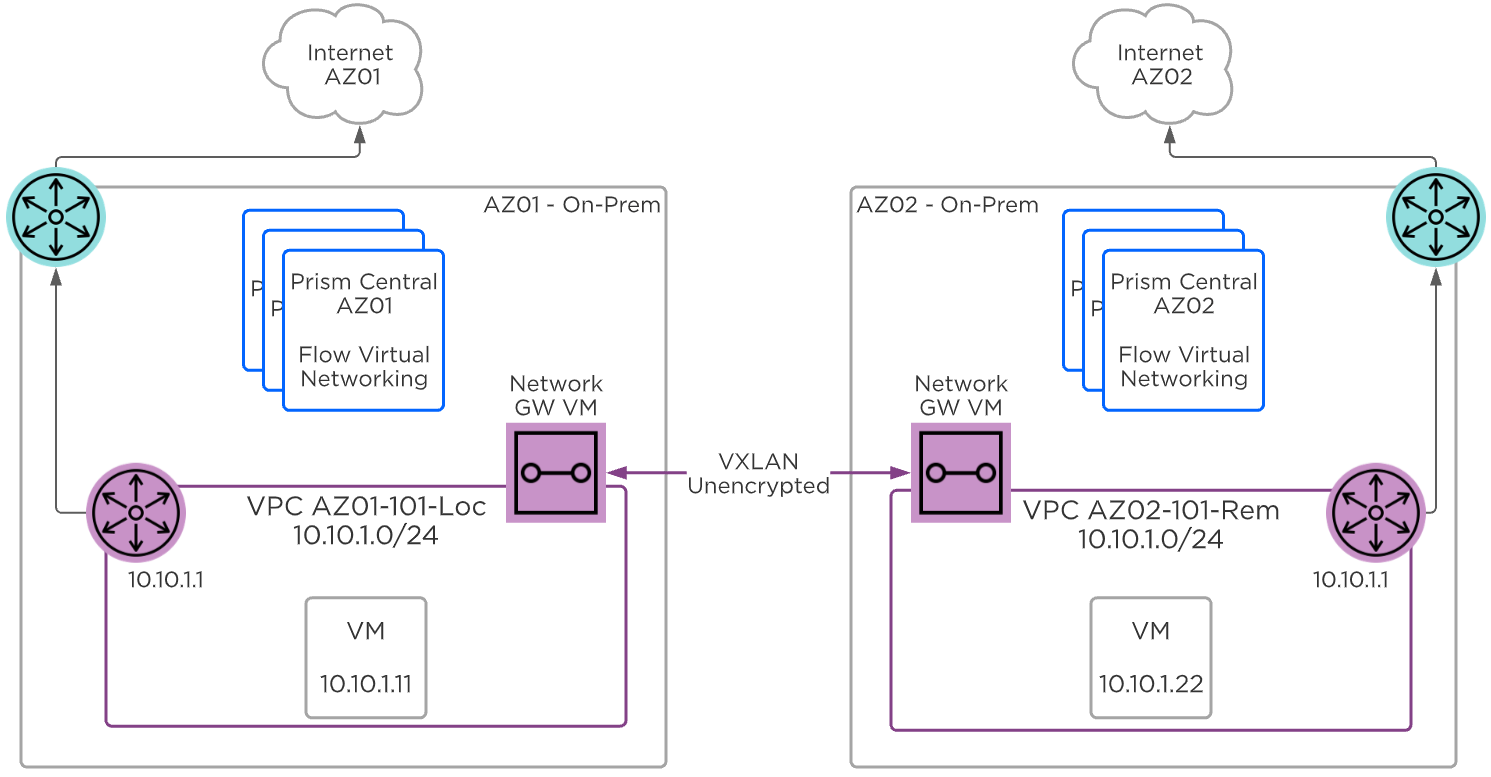 Flow 가상 네트워킹 - Layer 2 VXLAN VTEP (Flow Virtual Networking - Layer 2 VXLAN VTEP)
Flow 가상 네트워킹 - Layer 2 VXLAN VTEP (Flow Virtual Networking - Layer 2 VXLAN VTEP)
두 개의 네트워크 게이트웨이 VM을 사용하는 경우 각 네트워크 게이트웨이에는 외부 IP 주소가 할당되고, 두 개의 네트워크 게이트웨이 VM은 이러한 주소를 통해 통신할 수 있어야 한다.
로컬 네트워크 게이트웨이는 물리적 스위치와 같은 원격 물리적 VXLAN VTEP 종료 장치에 연결할 수도 있다. 물리적 디바이스는 Cisco, Arista 및 Juniper와 같은(이에 국한되지 않음) 널리 사용되는 벤더의 표준 VXLAN 디바이스일 수 있다. VXLAN VTEP 연결에 원격 물리적 디바이스 IP 주소를 입력하기만 하면 된다.
로컬 서브넷에서 원격 서브넷으로의 트래픽은 Layer-2 스위칭을 통해 교환되고 암호화되지 않은 VXLAN에 캡슐화된다. 각 네트워크 게이트웨이는 소스 MAC 주소 테이블을 유지 관리하고 유니캐스트 또는 플러딩된 패킷을 원격 서브넷으로 전달할 수 있다.
Note
Pro tip
트래픽이 개인 또는 보안 링크를 통과하는 경우에만 VXLAN VTEP를 사용한다. 이러한 트래픽은 암호화되지 않기 때문이다.
Layer 2 VXLAN VTEP over VPN
추가 보안을 위해 기존 VPN 연결을 통해 VXLAN 연결을 터널링하여 암호화를 추가할 수 있다. 이 경우 네트워크 게이트웨이 VM은 VXLAN 및 VPN 연결을 제공하므로 로컬 및 원격 서브넷 모두에 네트워크 게이트웨이 VM이 필요하다.
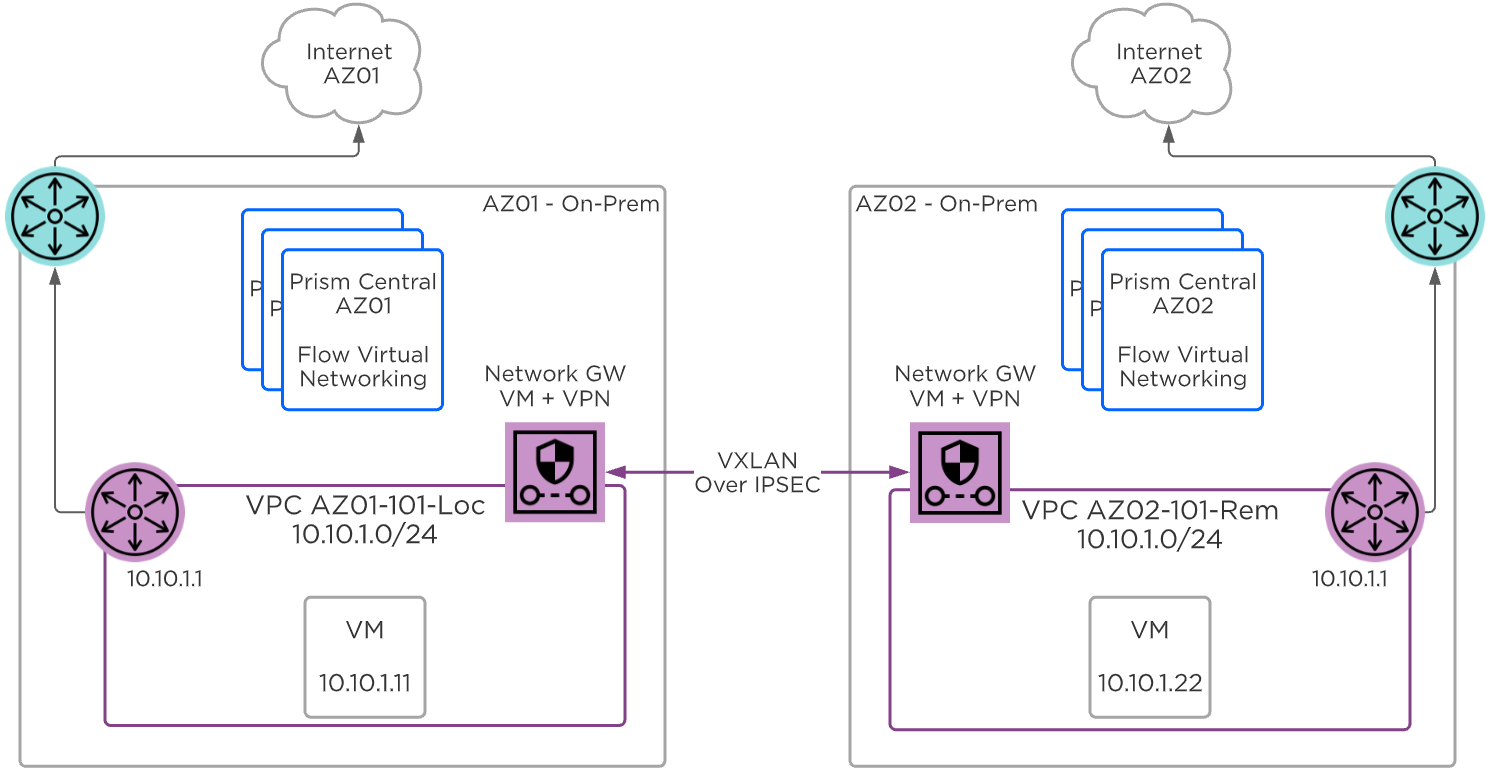 Flow 가상 네트워킹 - Layer 2 VXLAN VTEP over VPN (Flow Virtual Networking - Layer 2 VXLAN VTEP over VPN)
Flow 가상 네트워킹 - Layer 2 VXLAN VTEP over VPN (Flow Virtual Networking - Layer 2 VXLAN VTEP over VPN)
Book of Backup / DR Services
견고한 백업 전략을 갖추는 것은 모든 인프라 설계에서 없어서는 안될 부분이다. 본 BOOK에서는 정책 기반 백업, DR 및 런북 자동화를 제공하는 뉴타닉스 Leap에 대해 자세히 설명한다.
NOTE: 뉴타닉스 Mine 섹션을 추가할 예정입니다.
Leap (정책 기반 DR/런북)
Note
Hands-on에 관심이 있는 분들은 뉴타닉스 테스트 드라이브를 사용해 보세요!
https://www.nutanix.com/test-drive-disaster-recovery뉴타닉스 Leap 기능은 프리즘 센트럴을 통해 설정된 정책 기반 백업, DR 및 런북 자동화 서비스를 제공한다. 이 기능은 AOS에서 사용할 수 있고 수년간 PE에서 설정된 네이티브 DR 및 복제 기능을 기반으로 구축 및 확장된다. 복제 등에 활용되는 실제 백엔드 메커니즘에 대한 자세한 내용은 'Book of Acropolis'의 '백업 및 재해복구(DR)' 섹션을 참조한다. Leap은 AOS 5.10에서 도입되었다.
지원 환경 (Supported Configurations)
솔루션은 아래 구성에 적용할 수 있다 (목록이 불완전할 수 있으니 전체 지원 목록은 관련 문서를 참조).
핵심 사용 사례:
- 정책 기반 백업 및 복제
- DR 런북 자동화
- DRaaS (Xi를 통해)
관리 인터페이스:
- 프리즘 센트럴
지원 환경:
- 온-프레미스
- AHV (AOS 5.10 이상)
- ESXi (AOS 5.11 이상)
- 클라우드
- Xi (AOS 5.10 이상)
업그레이드:
- AOS의 일부
호환되는 기능:
- AOS BC/DR 기능
핵심 용어 (Key terms)
다음 주요 용어가 이 섹션에서 사용되며 다음에 정의된다.
- 복구 지점 목표 (Recovery Point Objective)
- 장애 발생 시 허용 가능한 데이터 손실을 나타낸다. 예를 들어 1시간의 RPO를 원하는 경우 1시간마다 스냅샷을 만들어야 한다. 복원하는 경우 최대 1시간 전의 데이터를 복원한다. 동기 복제의 경우 일반적으로 RPO는 "0"이다.
- 복구 시간 목표 (Recovery Time Objective)
- 장애 이벤트에서 복원된 서비스까지의 기간을 나타낸다. 예를 들어 장애가 발생하여 30분 내에 백업 및 실행해야 하는 작업이 필요한 경우 RTO는 30분이다.
- 복구 지점 (Recovery Point)
- 스냅샷으로 알려진 복원 지점
구현 컨스트럭트 (Implementation Constructs)
뉴타닉스 Leap에는 몇 가지 주요 컨스트럭트가 있다.
보호 정책 (Protection Policy)
- 주요 역할: 할당된 카테고리에 대한 백업/복제 정책
- 설명: 보호 정책(Protection Policy)은 RPO(스냅샷 주기), 복구 위치(원격 클러스터 / Xi), 스냅샷 보존 정책(로컬 대 원격 클러스터) 및 관련 카테고리를 정의한다. 보호 정책을 사용하면 모든 것이 카테고리 레벨에서 적용된다 (기본 정책은 일부/모두에 적용 가능). 이것이 VM을 선택해야 하는 보호 도메인(Protection Domain)과 다른 점이다.
다음 이미지는 뉴타닉스 Leap 보호 정책의 구조를 보여준다.
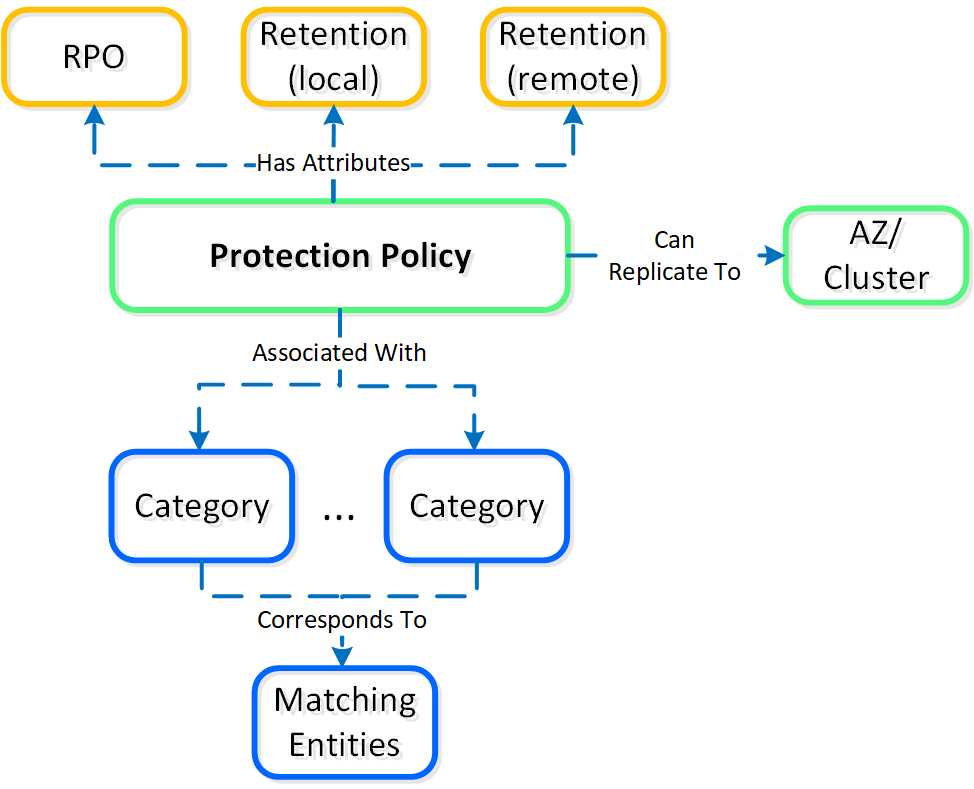 Leap - 보호 정책 (Leap - Protection Policy)
Leap - 보호 정책 (Leap - Protection Policy)
복구 계획 (Recovery Plan)
- 주요 역할: DR 런북
- 설명: 복구 계획(Recovery Plan)은 전원 켜기 순서(카테고리 또는 VM을 지정할 수 있음) 및 네트워크 매핑(기본 대 복구, 테스트 페일오버/페일백)을 정의하는 런북이다. 이것은 사람들이 SRM을 활용하는 것과 가장 동의어이다. NOTE: 복구 계획을 설정하려면 먼저 보호 정책을 설정해야 한다. 데이터를 복구하려면 복구 사이트에 데이터가 있어야 하므로 이 작업이 필요하다.
다음 이미지는 뉴타닉스 Leap 복구 계획의 구조를 보여준다.
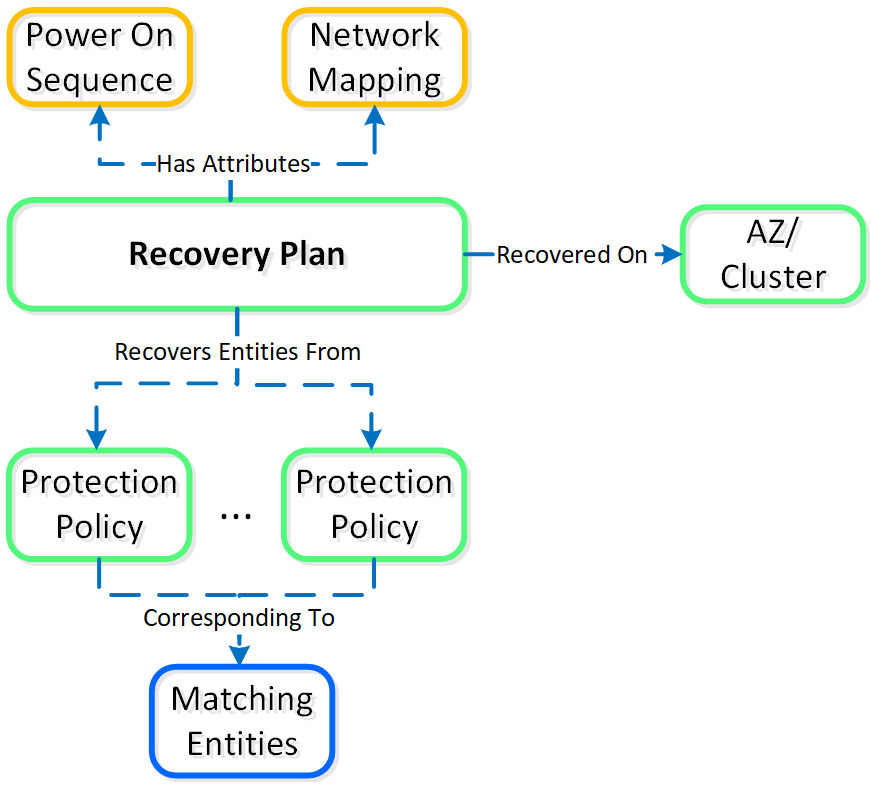 Leap - 복구 계획 (Leap - Recovery Plan)
Leap - 복구 계획 (Leap - Recovery Plan)
선형 보존 정책 (Linear Retention Policy)
- 주요 역할: 복구 지점 보존 정책
- 설명: 선형 보존 정책(Linear Retention Policy)은 보존할 복구 지점 수를 지정한다. 예를 들어 RPO가 1시간이고 보존 기간이 10으로 설정된 경우 10시간(10 x 1시간)의 복구 지점(스냅샷)을 유지한다.
롤업 보존 정책 (Roll-up Retention Policy)
- 주요 역할: 복구 지점 보존 정책
- 설명: 롤업 보존 정책(Roll-up Retention Policy)은 RPO 및 보존 기간에 따라 스냅샷을 "롤업"한다. 예를 들어 RPO가 1시간이고 보존 기간이 5일로 설정되어 있으면 시간 당 1일분과 일 당 4일분의 복구 지점을 유지한다. 논리는 다음과 같이 특징지을 수 있다: 보존 기간이 n일인 경우 1일의 RPO(시간 당 1일분), 일별 n-1일분의 복구 지점을 유지한다. 보존 기간이 n주인 경우 1일의 RPO(시간 당 1일분), 일별 1주, 주별 n-1주분의 복구 지점을 유지한다. 보존 기간이 n월인 경우 1일의 RPO(시간 당 1일분), 일별 1주, 주별 1개월, 월별 n-1개월분의 복구 지점을 유지한다. 보유 기간이 n년인 경우 1일의 RPO(시간 당 1일분), 일별 1주, 주별 1개월, 월별 1년, 월별 n-1년분의 복구 지점을 유지한다.
Note
선형 대 롤업 보존 정책 (Linear vs. roll-up retention)
보존 기간이 짧거나 항상 특정 RPO window로 복구할 수 있어야 하는 작은 RPO window에는 선형 정책을 사용한다.
보존 기간이 긴 경우 롤업 정책을 사용한다. 롤업 보존 정책이 좀 더 유연한데 스냅샷 에이징/가지치기(Snapshot Aging/Pruning) 작업을 자동으로 수행할 뿐만 아니라 첫째 날의 세분화된 RPO를 제공한다.
다음은 Leap 컨스트럭트의 하이-레벨 개요를 보여준다.
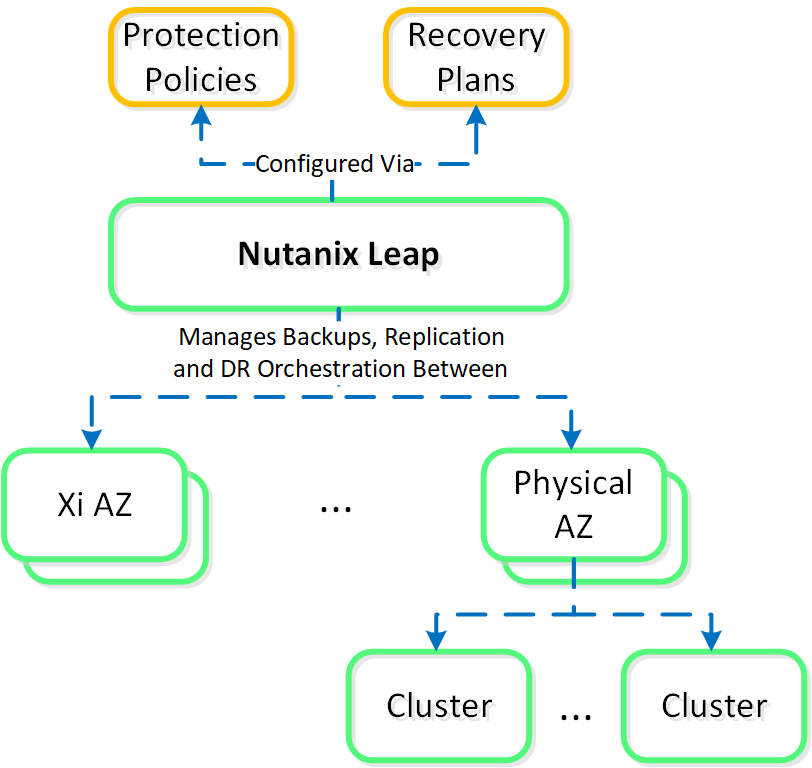 Leap - 개요 (Leap - Overview)
Leap - 개요 (Leap - Overview)
다음은 온-프레미스와 Xi 간에 Leap을 복제하는 방법을 보여준다.
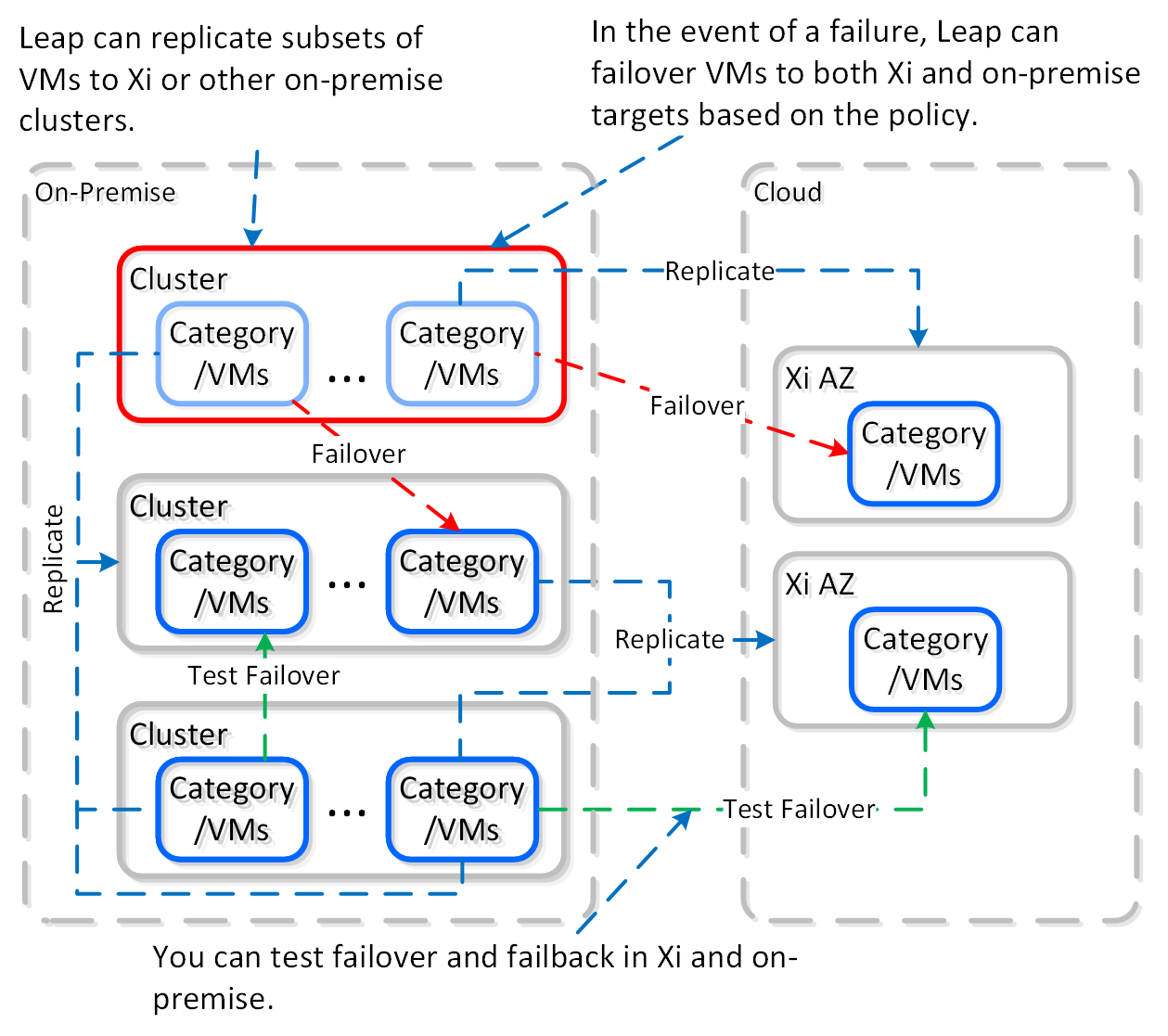 Leap - 토폴로지 (Leap - Topology)
Leap - 토폴로지 (Leap - Topology)
사용법 및 설정 (Usage and Configuration)
다음 섹션에서 Leap을 설정하고 활용하는 방법을 설명한다.
하이-레벨 프로세스는 다음과 같은 하이-레벨 단계로 특징지을 수 있다.
- AZ에 연결
- 보호 정책 설정
- 복구 계획 설정
- 패일오버 & 패일백 수행/테스트
AZ에 연결 (Connect Availability Zone(s))
첫 번째 단계는 Xi AZ 또는 다른 PC가 될 수 있는 AZ에 연결하는 것이다. NOTE: AOS 5.11을 기준으로 최소 2대의 PC가 배포되어야 한다 (각 사이트 당 1개).
PC에서 'Availability Zones'을 검색하거나 'Administration' → 'Availability Zones'로 이동한다.
 Leap - AZ에 연결 (Leap - Connect to Availability Zone)
Leap - AZ에 연결 (Leap - Connect to Availability Zone)
'Connect to Availability Zone'을 클릭하고 AZ 유형(PC 인스턴스로 알려진 'Xi' 또는 'Physical Location')을 선택한다.
 Leap - AZ에 연결 (Leap - Connect to Availability Zone)
Leap - AZ에 연결 (Leap - Connect to Availability Zone)
PC 또는 Xi에 대한 크리덴셜을 입력하고 'Connect'를 클릭한다.
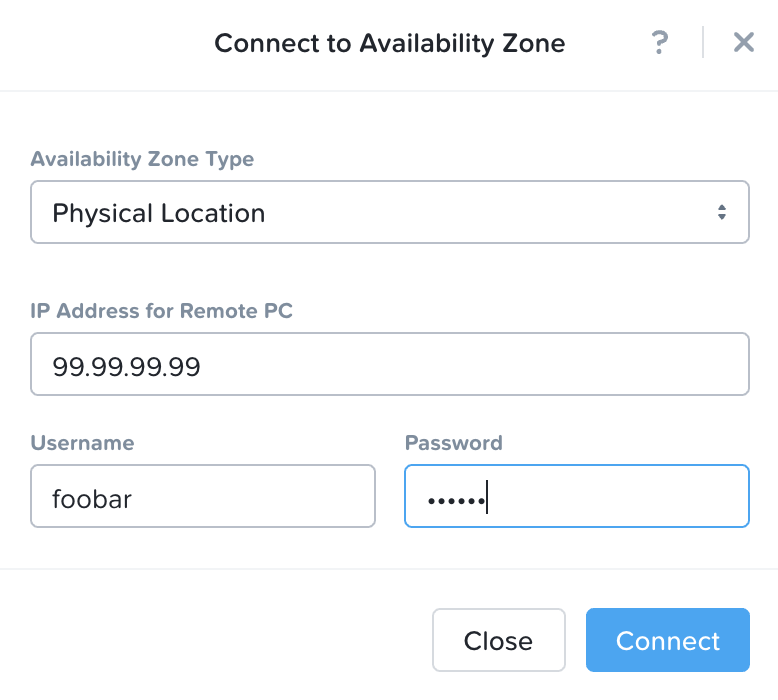 Leap - AZ에 연결 (Leap - Connect to Availability Zone)
Leap - AZ에 연결 (Leap - Connect to Availability Zone)
연결된 AZ가 표시되고 사용할 수 있다.
보호 정책 설정 (Configure Protection Policies)
PC에서 'Protection Policies'를 검색하거나 'Policies' → 'Protection Policies'로 이동한다.
 Leap - 보호 정책 (Leap - Protection Policies)
Leap - 보호 정책 (Leap - Protection Policies)
'Create Protection Policy'를 클릭한다.
 Leap - 보호 정책 생성 (Leap - Create Protection Policy)
Leap - 보호 정책 생성 (Leap - Create Protection Policy)
이름, 복구 위치, RPO 및 보존 정책에 대한 세부 정보를 입력한다 (이전에 설명).
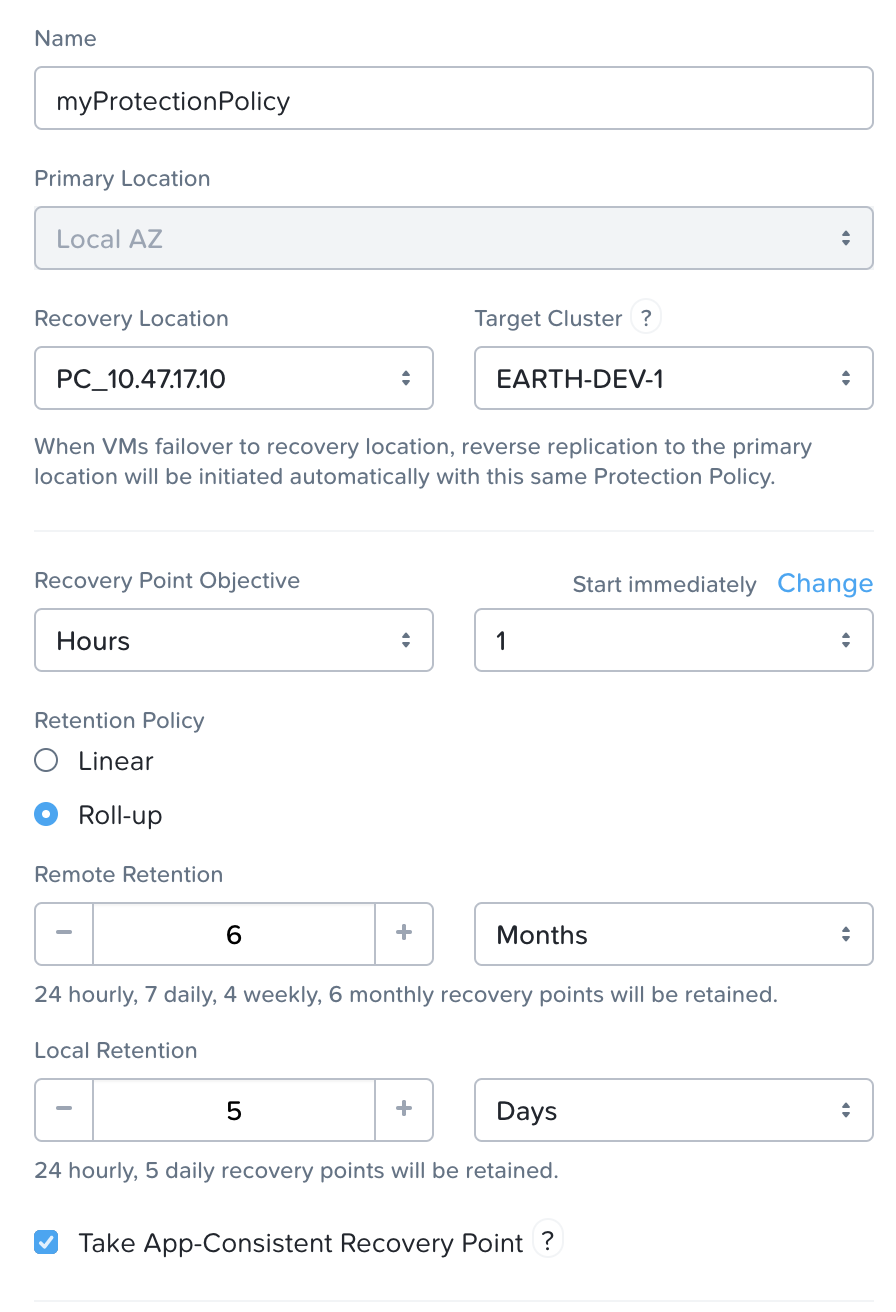 Leap - 보호 정책 입력 (Leap - Protection Policy Inputs)
Leap - 보호 정책 입력 (Leap - Protection Policy Inputs)
NOTE: Xi인 경우 'Target Cluster'를 선택할 필요가 없다.
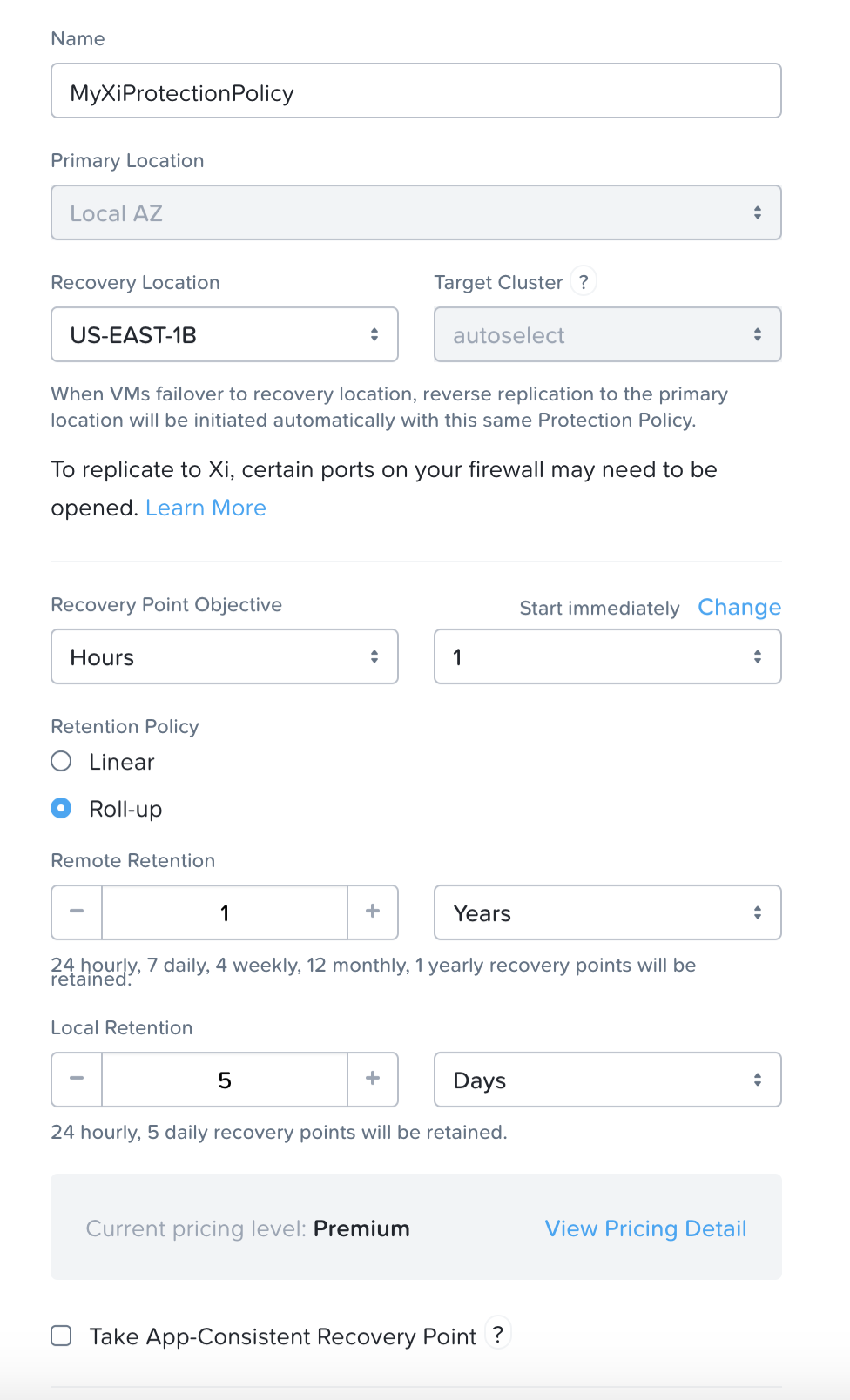 Leap - 보호 정책 입력 - Xi (Leap - Protection Policy Inputs - Xi)
Leap - 보호 정책 입력 - Xi (Leap - Protection Policy Inputs - Xi)
다음으로 적용할 정책의 카테고리를 선택한다.
 Leap - 보호 정책 카테고리 (Leap - Protection Policy Categories)
Leap - 보호 정책 카테고리 (Leap - Protection Policy Categories)
'Save'를 클릭하면 새로 생성된 보호 정책이 나타난다.
 Leap - 보호 정책 (Leap - Protection Policies)
Leap - 보호 정책 (Leap - Protection Policies)
복구 계획 설정 (Configure Recovery Plans)
PC에서 'Recovery Plans'을 검색하거나 'Policies' → 'Recovery Plans' 메뉴로 이동한다.
Leap - 복구 계획 (Leap - Recovery Plans)
최초로 실행하는 경우 첫 번째 복구 계획을 작성하라는 화면이 나타난다.
 Leap - 복구 계획 생성 (Leap - Create Recovery Plan)
Leap - 복구 계획 생성 (Leap - Create Recovery Plan)
드롭-다운 메뉴를 이용하여 'Recovery Location'를 선택한다.
 Leap - 복구 위치 선택 (Leap - Select Recovery Location)
Leap - 복구 위치 선택 (Leap - Select Recovery Location)
NOTE: 이는 Xi AZ 또는 물리적 AZ 일 수 있다 (해당 관리 클러스터가 있는 PC).
복구 계획 이름과 설명을 입력하고 'Next'를 클릭한다.
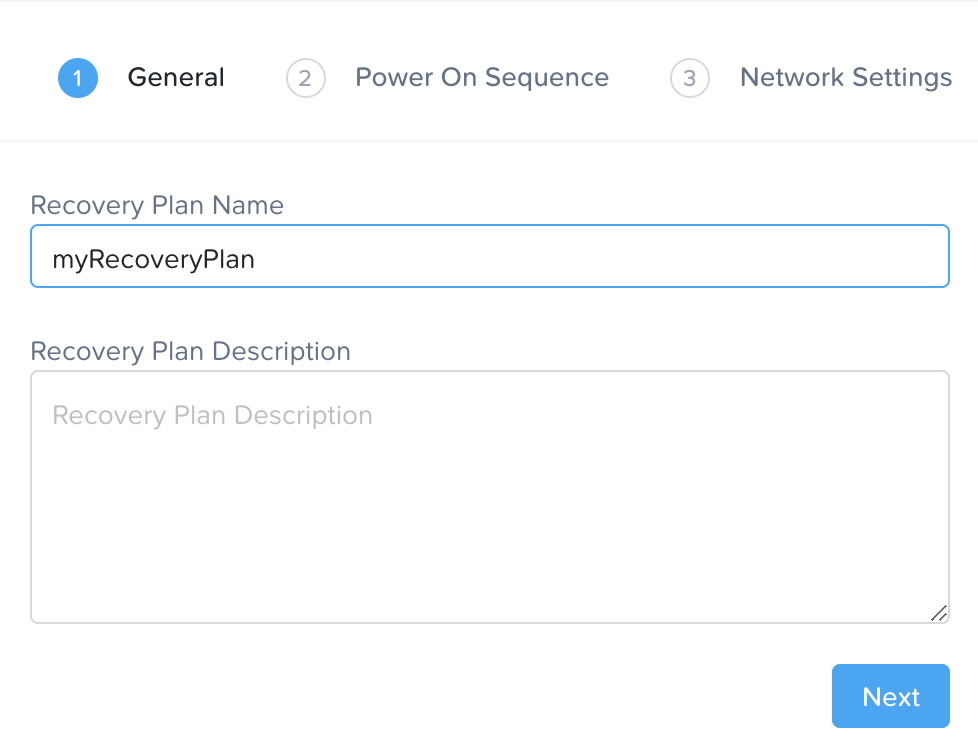 Leap - 복구 계획 - 네이밍 (Leap - Recovery Plan - Naming)
Leap - 복구 계획 - 네이밍 (Leap - Recovery Plan - Naming)
다음으로 'Add Entities'를 클릭하고 전원 켜기 순서를 지정한다.
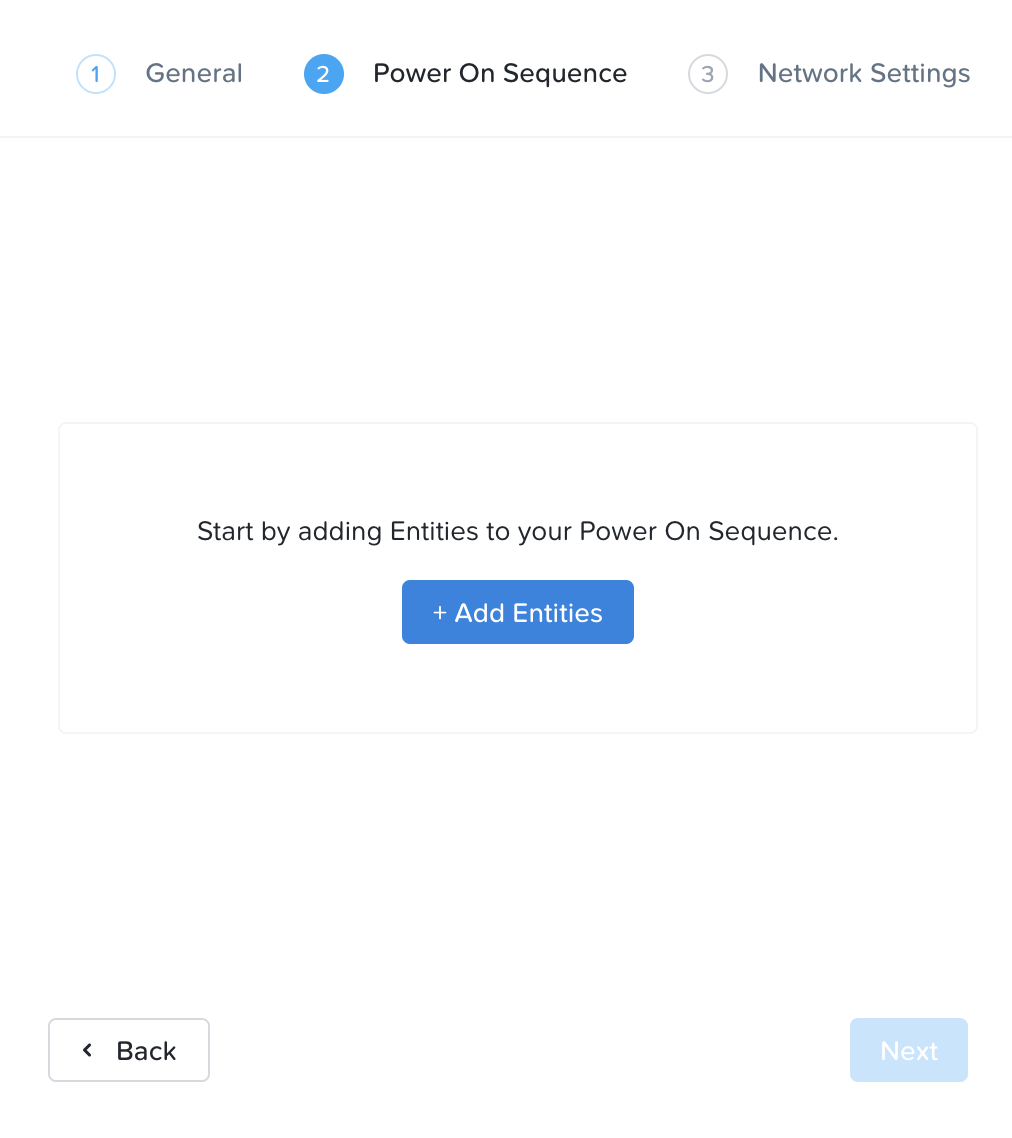 Leap - 복구 계획 - Power On Sequence (Leap - Recovery Plan - Power On Sequence)
Leap - 복구 계획 - Power On Sequence (Leap - Recovery Plan - Power On Sequence)
각 단계에 추가할 VM 또는 카테고리를 검색한다.
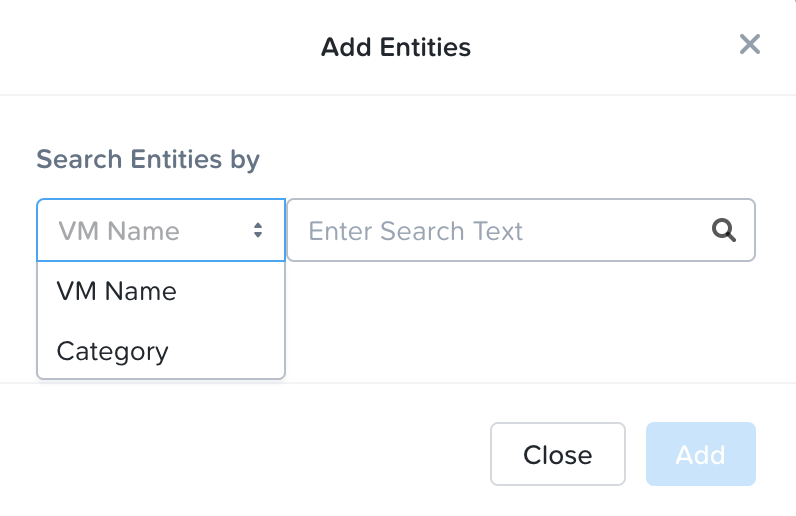 Leap - 복구 계획 - Power On Sequence (Leap - Recovery Plan - Power On Sequence)
Leap - 복구 계획 - Power On Sequence (Leap - Recovery Plan - Power On Sequence)
전원 켜기 순서가 단계에 적합하면 'Next'를 클릭한다.
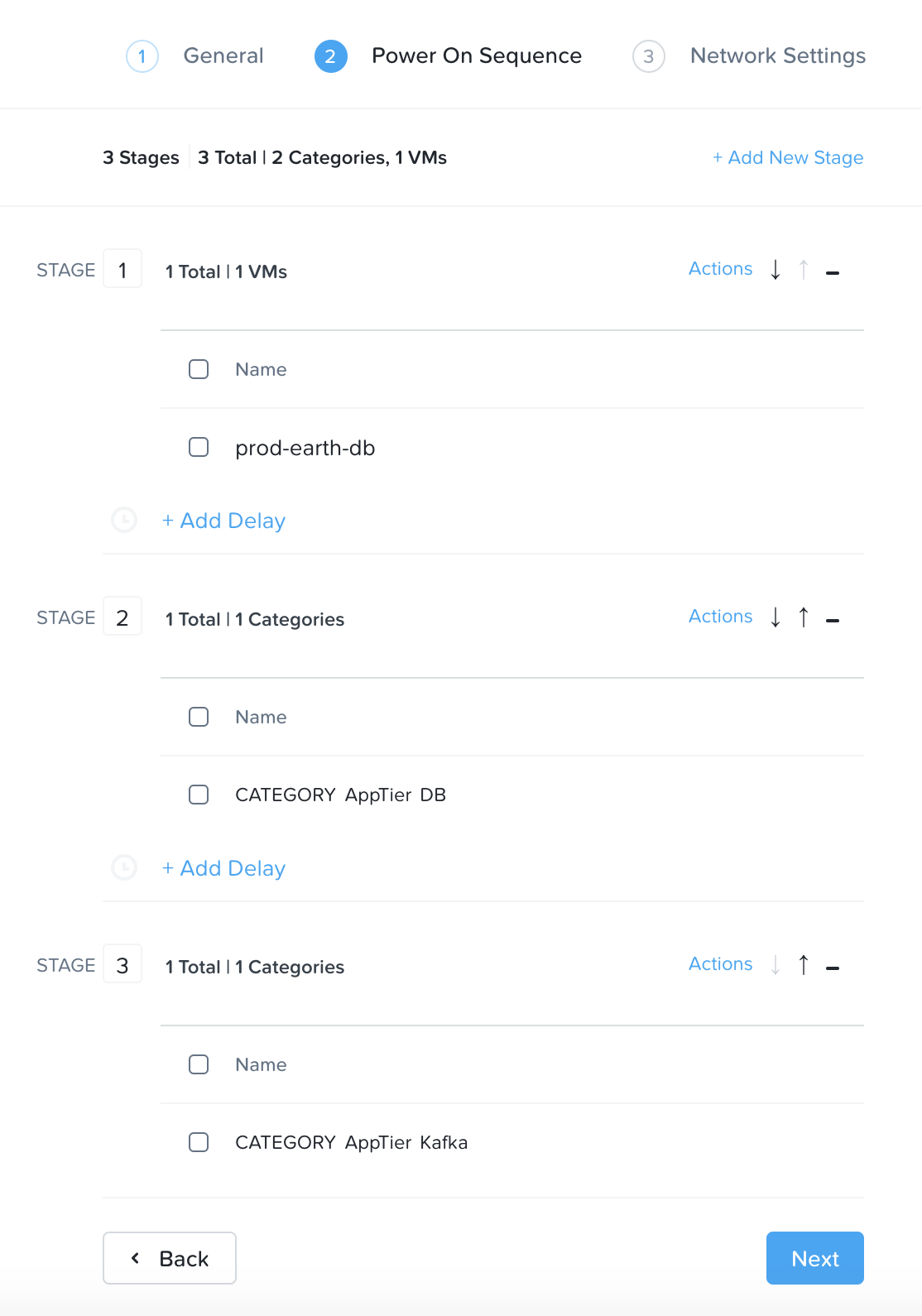 Leap - 복구 계획 - Power On Sequence (Leap - Recovery Plan - Power On Sequence)
Leap - 복구 계획 - Power On Sequence (Leap - Recovery Plan - Power On Sequence)
Note
전원 켜기 순서 (Power On Sequencing)
전원 켜기 순서를 결정할 때 다음과 같은 단계를 고려하는 것이 좋다.
- 단계 0: 핵심 서비스 (AD, DNS 등)
- 단계 1: 단계 0 서비스에 의존하고 단계 2 서비스에 필요한 서비스 (e.g. DB 계층)
- 단계 2: 단계 1 서비스에 의존하고 단계 3 서비스에 필요한 서비스 (e.g. App 계층)
- 단계 3: 단계 2 서비스에 의존하고 단계 4 서비스에 필요한 서비스 (e.g. Web 계층)
- 단계 4-N: 종속성에 따라 반복한다.
이제 소스와 타깃 환경 간에 네트워크를 매핑한다.
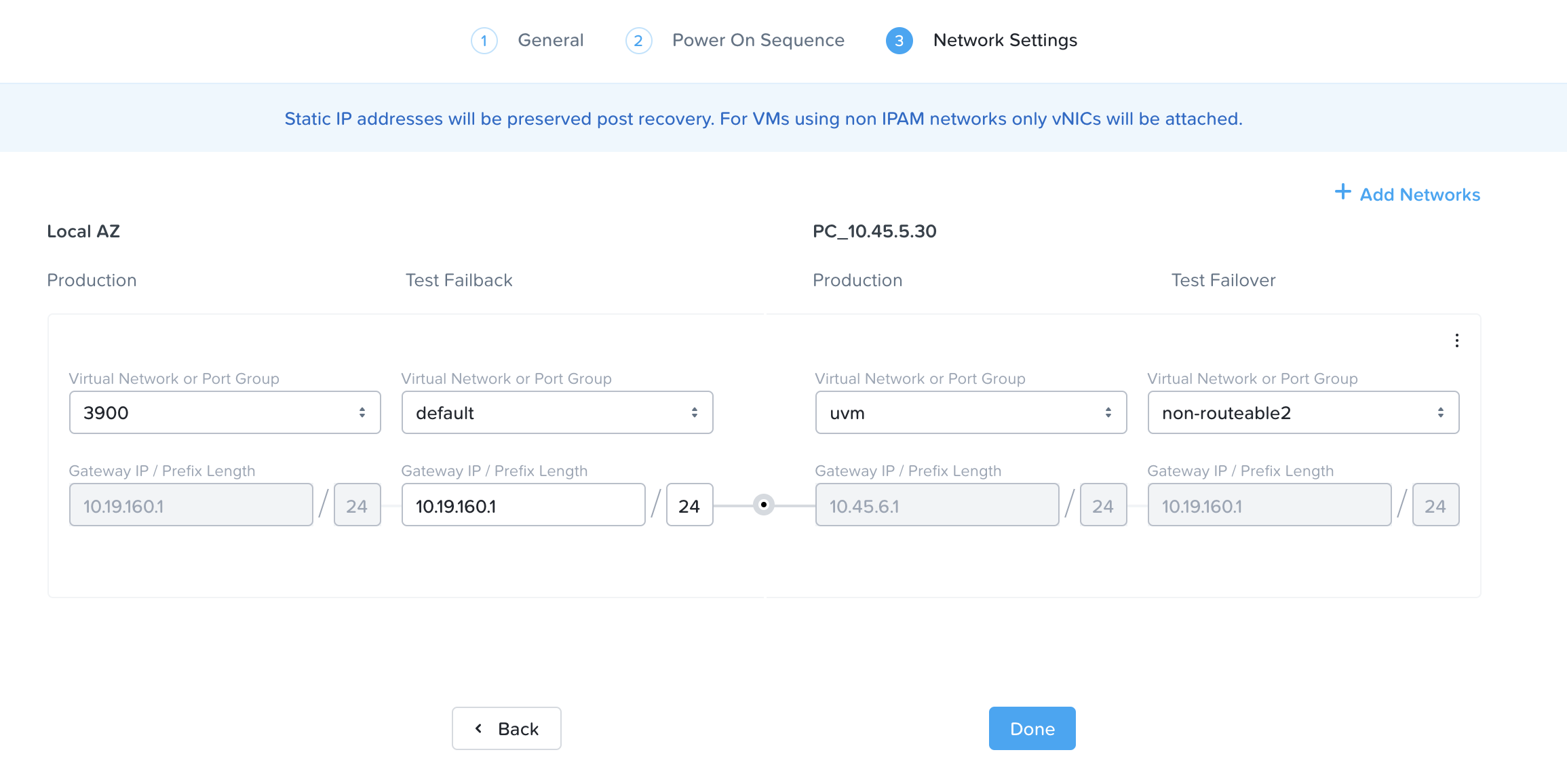 Leap - 복구 계획 - 네트워크 매핑 (Leap - Recovery Plan - Network Mapping)
Leap - 복구 계획 - 네트워크 매핑 (Leap - Recovery Plan - Network Mapping)
Note
페일오버/페일백 네트워크 (Failover/Failback Networks)
대부분의 경우 테스트 네트워크를 위해 라우팅할 수 없거나 분리된 네트워크를 사용한다. 이렇게 하면 중복된 SID, ARP 엔트리 등의 이슈가 발생하지 않는다.
Book of Cloud Native Services
CNCF는 클라우드 네이티브를 "조직이 퍼블릭, 프라이빗 및 하이브리드 클라우드와 같은 현대적이고 역동적인 환경에서 확장 가능한 애플리케이션을 구축 및 실행할 수 있도록 하는 기술 세트"로 정의한다. 애플리케이션 현대화로의 이러한 전환을 주도하는 주요 기술에는 컨테이너(Containers), 마이크로서비스(Microservices) 및 쿠버네티스(Kubernetes)가 포함된다.
뉴타닉스는 뉴타닉스 하이퍼컨버지드 인프라(HCI)가 쿠버네티스에서 대규모로 실행되는 클라우드 네이티브 워크로드를 위한 이상적인 인프라 기반이라고 확신한다. 뉴타닉스는 플랫폼 이동성을 제공하여 뉴타닉스 프라이빗 클라우드와 퍼블릭 클라우드 모두에서 워크로드를 실행할 수 있는 선택권을 제공한다. 뉴타닉스 아키텍처는 하드웨어 장애를 염두에 두고 설계되었으므로 쿠버네티스 플랫폼 컴포넌트와 애플리케이션 데이터 모두에 대해 더 나은 리질리언시를 제공한다. 각 HCI 노드를 추가하면 쿠버네티스 컴퓨팅 노드에 제공되는 확장성과 리질리언시의 이점을 누릴 수 있다. 마찬가지로 중요한 것은 각 HCI 노드와 함께 추가 스토리지 컨트롤러가 배포되므로 상태 저장 컨테이너화된 애플리케이션에 대한 스토리지 성능이 향상된다는 것이다.
뉴타닉스 클라우드 플랫폼은 NKE(Nutanix Kubernetes Engine)를 통해 내장된 턴키 쿠버네티스 환경을 제공한다. NKE는 여러 클러스터의 프로비저닝 및 라이프사이클 관리를 간소화하는 엔터프라이즈급 제품이다. 뉴타닉스는 고객에게 선택권을 제공하므로 고객은 보다 우수한 전체 스택 자원 관리를 위해 OpenShift, Rancher, Anthos 등과 같은 선호하는 배포판을 실행할 수 있다. 보다 자세한 내용은 아래 장을 참조한다.
뉴타닉스 통합 스토리지는 쿠버네티스 클러스터에 지속적이고 확장 가능한 소프트웨어 정의 스토리지를 제공한다. 여기에는 뉴타닉스 CSI 드라이버를 통한 블록 및 파일 스토리지와 S3 호환 오브젝트 스토리지가 포함된다. 또한 뉴타닉스 데이터베이스 서비스를 사용하여 데이터베이스를 대규모로 프로비저닝하고 운영할 수 있다.
다음 장에서는 이에 대해 더 자세히 설명한다:
NOTE: 뉴타닉스 통합 데이터 서비스와 관련된 내용을 제공할 예정입니다!
뉴타닉스 쿠버네티스 엔진 (이전 제품명은 뉴타닉스 Karbon)
NKE(Nutanix Kubernetes Engine)는 쿠버네티스의 턴키 프로비저닝, 운영 및 수명 주기 관리를 지원하는 뉴타닉스의 인증된 엔터프라이즈 쿠버네티스 관리 솔루션이다.
지원되는 환경
솔루션은 다음과 같은 환경에 적용할 수 있다:
핵심 사용 사례:
- 컨테이너 (Containers)
- 마이크로서비스 (Microservices)
- 애플리케이션 현대화 (Application modernization)
관리 인터페이스:
- 프리즘 센트럴(PC)에서 NKE 콘솔
지원되는 환경:
- 하이퍼바이저:
- AHV
- 위치:
- 온-프레미스 (On-premises):
- Owned
- (Managed) Service Providers
- 온-프레미스 (On-premises):
지원되는 노드 OS 이미지:
- CentOS Linux-based provided by Nutanix
업그레이드:
- LCM에 Karbon으로 포함됨
호환 기능:
- 라이프사이클 오퍼레이션 (Lifecycle operations)
- 역할 기반 접근 제어 (Role-based Access Control (RBAC))
- 클러스터 확장 (Cluster expansion)
- 다중 클러스터 관리 (Multi-cluster management)
- 노드 풀 (Node pool)
- GPU 패스스루 (GPU pass-through)
NKE(Nutanix Kubernetes Engine)는 프리즘 센트럴을 통해 활성화할 수 있다. NKE 지원 PC에 등록된 모든 뉴타닉스 AOS 클러스터는 쿠버네티스 클러스터 프로비저닝을 위한 대상으로 사용할 수 있다.
아키텍처 (Architecture)
NKE가 활셩화된 쿠버네티스 클러스터는 여러 뉴타닉스 HCI 클러스터에 걸쳐 있을 수 없다.

NKE 아키텍처
NKE는 프리즘 센트럴에서 컨테이너화된 서비스로 실행된다. NKE가 PC에서 활성화되면 Karbon-core 컨테이너와 Karbon-ui 컨테이너의 두 가지 컨테이너가 아래와 같이 프로비저닝된다.
-
Karbon-core는 쿠버네티스 클러스터의 수명 주기를 담당한다. 프로비저닝, 노드 OS 업그레이드, 클러스터 확장 등과 같은 작업은 이 컨테이너에서 수행된다.
-
Karbon-ui는 프리즘 센트럴을 통해 직관적인 콘솔을 제공한다. 이 통합 UI에서 IT 관리자는 NKE 인스턴스가 관리하는 전체 쿠버네티스 환경을 완전히 제어할 수 있다.
에어-갭 환경 (Air-gapped environments)
NKE는 에어-갭 환경에서도 활성화될 수 있다 (자세히 읽기)
쿠버네티스 클러스터 설정
OS 이미지 (OS Images)
NKE는 쿠버네티스 노드 설치 및 확장을 위한 OS 이미지를 제공한다. NKE는 NKE가 활성화된 쿠버네티스 클러스터 생성을 위해 CentOS Linux 기반 OS를 사용한다. 취약점을 보완하기 위한 패치를 포함하여 새로운 OS 이미지 버전이 주기적으로 릴리즈된다. 지원되는 OS 이미지 버전 목록은 NKE 릴리즈 정보를 확인 (자세히 읽기)
OS 이미지 (Operating System Images)
사설 OS 이미지는 지원하지 않는다.
컴퓨트 (Compute)
권장 설정에는 개발(Development) 클러스터와 프로덕션(Production) 클러스터의 두 가지 옵션이 있다.
-
개발(Development) 클러스터 옵션에는 고가용성 컨트롤 플레인이 없다. 컨트롤 플레인 노드가 오프라인이 되는 경우 쿠버네티스 클러스터가 영향을 받는다.
개발(Development)을 위한 최소 클러스터 크기는 3개의 노드이다:
- 컨트롤 플레인은 etcd 노드와 쿠버네티스 컨트롤 플레인 노드의 두 노드로 나뉜다.
- 워커(Worker) 노드 풀에는 최대 100개 노드(NKE 설정 최대값)까지 확장할 수 있는 단일 노드가 있다.
-
프로덕션(Production) 클러스터 옵션에는 고가용성 컨트롤 플레인이 있다. 본 설정 옵션에는 SPOF(Single-Point-Of-Failure)가 없다.
프로덕션(Production)을 위한 최소 클러스터 크기는 8개 노드이다:
- 컨트롤 플레인은 5개의 노드, 3개의 etcd 노드(최대 5개의 노드까지 확장 가능) 및 2개의 쿠버네티스 컨트롤 플레인 노드로 나뉜다. 쿠버네테스 컨트롤 플레인 노드는 active-passive(2개 노드) 또는 active-active(최대 5개 노드)로 동작할 수 있다. 후자의 경우 외부 로드 밸런서가 필요하다.
- 워커(Worker) 노드 풀에는 최소 3개의 노드가 있으며 최대 100개 노드까지 확장할 수 있다.
네트워킹 (Networking)
큐버네티스 클러스터에는 총 3개의 네트워크가 필요하며 VM 네트워크와 쿠버네티스 네트워크로 그룹화할 수 있다.
-
VM 네트워크 또는 노드 네트워크(Virtual machines network or node network): DHCP(개발 클러스터만 해당) 또는 IPAM이 활성화된 관리 네트워크(관련 도메인 설정 및 IP 주소 풀 포함)를 통해 할당해야 한다. 프로덕션 설정에는 active-passive 및 active-active 모드에 대한 추가 고정 IP 주소가 필요하다.
-
쿠버네티스 네트워크(Kubernetes networks): 클러스터에는 쿠버네티스 서비스 네트워크 용과 쿠버네티스 PODs 네트워크 용으로 최소 2개의 CIDR(Classless Inter-Domain Routing) 범위가 필요하다.
NKE는 쿠버네티스 네트워크에 대해 Flannel 및 Calico의 두 가지 CNI(Container Network Interface) 프로바이더를 지원한다.
- Flannel. NKE는 VXLAN 모드를 사용한다. 모드를 host-gw로 변경할 수 있지만 지원되지 않는다.
- Calico. NKE는 Direct 모드를 사용한다. IP 또는 VXLAN에서 모드를 IP로 변경하는 것은 가능하지만 지원되지 않는다.
Pro tip
서비스 CIDR 및 POD CIDR 범위를 디폴트로 둘 수 있지만, 클러스터의 POD가 해당 외부 네트워크에 액세스해야 하는 경우 범위가 서로 또는 데이터 센터의 기존 네트워크와 겹치지 않아야 한다.
Networking
Active-Active 컨트롤 플레인 모드가 있는 프로덕션 클러스터에는 외부 로드 밸런서가 필요하다.
스토리지 (Storage)
쿠버네티스 클러스터를 배포할 때 뉴타닉스 CSI(Container Storage Interface) 드라이버도 함께 배포된다.
뉴타닉스 Volumes를 사용하는 디폴트 StorageClass도 배포 중에 생성된다. 이는 모니터링을 위한 Prometheus, 메트릭스 및 로그를 저장하기 위한 EFK(Elasticsearch, Fluent Bit 및 Kibana) 로깅 스택과 같은 포함된 추가 기능에 필요하다. 배포 후 동일한 CSI 드라이버를 사용하여 더 많은 스토리지 클래스를 추가할 수 있다(예제 참조).
뉴타닉스 Volumes 외에도 뉴타닉스 Files를 사용하여 파일 저장을 위한 StorageClass를 생성할 수도 있다. StorageClass에 설정된 스토리지 백엔드에 따라 PersistentVolumeClaim을 생성할 때 다양한 액세스 모드가 지원된다.
| 스토리지 백엔드 (Storage backend) | ReadWriteOnce RWO |
ReadOnlyMany ROX |
ReadWriteMany RWX |
ReadWriteOncePod RWOP |
|---|---|---|---|---|
| Volumes | ||||
| Files |
보안 (Security)
액세스 및 인증 (Access and Authentication)
액세스 및 인증과 관련하여 기억해야 할 두어야 할 두 가지 컴포넌트가 있다. PC의 NKE와 NKE-활성화된 Kubernetes 클러스터이다.
-
NKE는 프리즘 센트럴 인증 및 RBAC를 사용한다. 뉴타닉스는 NKE 사용자를 마이크로소프트의 액티브 디렉토리와 같은 프리즘 센트럴의 디렉토리 서비스로 설정해야 한다. 사용자는 NKE 콘솔에 액세스하여 할당된 역할에 따라 특정 작업을 수행할 수 있다.
PC에서 User Admin 역할의 멤버는 NKE 및 해당 기능에 대한 전체 액세스 권한을 가진다.
Prism Central Admin 역할 또는 Viewer 역할은 kubeconfig만 다운로드할 수 있다.
-
즉시 사용 가능한 NKE-활성화된 쿠버네티스 클러스터는 인증을 위해 프리즘 센트럴을 사용하고, 쿠버네티스의 역할인 cluster-admin과 PC의 역할인 User Admin을 매핑한다.
인증 관점에서 쿠버네티스 클러스터는 PC 디렉터리 서비스를 사용하는 NKE에 인증 요청을 보낸다. 즉, 즉시 사용 가능한 액티브 디렉토리를 활용하여 사용자를 인증할 수 있다.
RBAC 관점에서 PC의 역할인 User Admin는 cluster-admin이라는 쿠버네티스 슈퍼 관리자 역할과 매핑된다. 이는 PC에서 User Admin 역할의 사용자 멤버는 NKE 인스턴스에서 관리하는 모든 쿠버네티스 클러스터의 수퍼유저임을 의미한다. 반면에 PC의 역할인 Prism Central Admin 및 Viewer에는 쿠버네티스 역할과의 매핑이 없다. 이는 이 두 역할이 할당된 사용자 멤버는 NKE에서 kubeconfig를 다운로드할 수 있지만 쿠버네티스 수준에서 작업을 수행할 수 없음을 의미한다. Super-Admin 사용자는 쿠버네티스 내에서 정확한 역할 매핑을 생성해야 한다.
NKE에 의해 생성된 kubeconfig는 24시간 동안 유효하며, 그 이후에는 사용자가 새로운 kubeconfig 파일을 요청해야 한다. 이것은 NKE GUI, CLI, API 또는 kubectl 플러그인(HERE(권장)을 사용하여 수행할 수 있다.
노드 (Nodes)
쿠버네티스 노드에 대한 SSH 액세스는 24시간 후에 만료되는 NKE 콘솔에서 사용할 수 있는 임시 인증서를 사용하여 락다운된다. 노드 OS에서 소프트웨어 설치 또는 설정 변경은 지원되지 않으며, 업그레이드 중 또는 노드 풀을 확장할 때 변경 사항이 유지되지 않는다. SSH를 통해 노드에 액세스하는 유일한 이유는 뉴타닉스 지원의 판단에 따라 문제를 해결하기 위한 것이다.
쿠버네티스 용 CIS 벤치마크 (Benchmark for Kubernetes)
뉴타닉스는 CIS Kubernetes Benchmark-1.6에 대해 NKE-활성화된 쿠버네티스 클러스터를 검증했다. GitHub에서 사용할 수 있는 자동화된 오픈 소스 도구인 Kube Bench를 통해 컴프라이언스를 확인할 수 있다. 보고서는 여기에서 볼 수 있다.
애드온 (Add-ons)
NKE 애드온은 배포에 추가 기능을 제공하는 오픈 소스 소프트웨어 확장 모듈이다. 애드온은 쿠버네티스 클러스터를 배포할 때 자동으로 설치된다.
뉴타닉스 쿠버네티스 엔진에는 다음 애드온이 포함되어 있다:
- Elasticsearch, Fluent Bit 및 Kibana(EFK)로 구동되는 로깅 애드온
- Prometheus에서 제공하는 모니터링 애드온
이러한 애드온은 클러스터 내부 전용으로 사용된다. 해당 설정은 쿠버네티스 클러스터에서 실행되는 애플리케이션에 의해 생성된 데이터를 지원하도록 설계되지 않았다. 컨테이너화된 애플리케이션에 대한 로그 및 메트릭스를 수집하려면, EFK 및 Prometheus의 전용 인스턴스를 배포하거나 환경에서 사용 가능한 기존 인스턴스를 재사용해야 한다.
로깅 (Logging)
로깅 스택은 쿠버네티스 노드의 모든 OS 및 인프라 로그를 집계한다. Kibana 대시보드는 NKE 콘솔을 통해 액세스할 수 있다.
NKE 2.4부터 로깅 스택을 비활성화할 수 있고(상세 내용 참조), 외부 기존 로깅 스택에 대한 로그 전달에 Fluent Bit만 사용할 수 있다(상세 내용 참조).
모니터링 (Monitoring)
쿠버네티스 클러스터에는 Prometheus 오퍼레이터가 설치되어 있고 인프라 메트릭스를 수집하기 위해 배포된 인스턴스 하나가 있다. 추가 Prometheus 인스턴스는, 예를 들어 애플리케이션 모니터링(블로그)을 위해, 오퍼레이터를 사용하여 배포할 수 있다.
NKE 2.4부터 SMTP 기반 경고를 이메일 주소로 전달할 수 있는 기능을 활성화할 수 있다(상세 내용 참조).
라이프사이클 관리 (Lifecycle management)
NKE 업그레이드에는 두 가지 유형이 있다:
- 라이프사이클 관리 기능을 사용하여 NKE 버전 업그레이드.
- 노드 OS 이미지 및 쿠버네티스 버전을 위한 쿠버네티스 클러스터 업그레이드.
LCM을 통한 NKE 업그레이드 (NKE upgrade via LCM)
Karbon의 현재 버전을 확인하거나 이후 버전으로 업그레이드하려면 LCM을 사용하여 프리즘 센트럴에서 인벤토리 체크를 수행한다. LCM은 다음 NKE 컴포넌트를 업그레이드한다:
- NKE core (karbon-core container)
- NKE UI (karbon-ui container)
Note
NKE 업그레이드 (NKE Upgrades)
최신 버전의 NKE로 업그레이드할 때, 모든 쿠버네티스 클러스터가 실행 중이거나 먼저 대상 NKE에서 지원하는 버전으로 업그레이드해야 한다. 업데이트된 지원 버전은 뉴타닉스 포털에서 확인한다.
쿠버네티스 클러스터 업그레이드 (Kubernetes cluster upgrades)
쿠버네티스 클러스터 업그레이드에는 두 가지 측면이 있다:
- 노드 OS 업그레이드
- 쿠버네티스 + 애드온 버전 업그레이드
Note
쿠버네티스 클러스터 업그레이드 (Kubernetes Cluster Upgrades)
노드 OS 또는 쿠버네티스 버전 업그레이드는 쿠버네티스 클러스터 유형, 개발 및 프로덕션에 따라 중단될 수 있다.
노드 OS 업그레이드 (Node OS upgrade)
노드 OS 이미지 업그레이드를 사용할 수 있는 경우, NKE는 OS Images 탭에 새로운 이미지를 다운로드하는 옵션을 표시한다. NKE는 또한 클러스터 뷰의 클러스터 옆에 Upgrade Available 아이콘을 표시한다.
쿠버네티스 + 애드온 업그레이드 (Kubernetes + add-ons version upgrade)
업그레이드에 적합한 쿠버네티스 버전이 있는 클러스터는 테이블에 Upgrade Available 아이콘을 표시한다. 업그레이드 프로세스의 일부로 쿠버네티스 버전과 설치된 애드온에 사용할 수 있는 모든 업그레이드를 업그레이드한다.
NKE CLI 및 API
NKE CLI
NKE CLI인 karbonctl은 사용자에게 NKE 및 쿠버네티스 클러스터에 대한 라이프사이클 관리 작업을 실행할 수 있는 기능을 제공한다. 특정 고급 작업은 karbonctl만 사용하여 수행할 수 있다.
karbonctl을 사용하려면 프리즘 센트럴 인스턴스에 SSH로 접속해야 한다. 바이너리 경로는 /home/nutanix/karbon/karbonctl이다.
karbonctl로 실행할 수 있는 몇 가지 일반적인 작업은 다음과 같다:
- 에어갭 배포 설정 (Configuring airgap deployment)
- GPU 지원 설정 (Configuring GPU support)
- 인증서 로테이션 (Rotating certificates)
- 경고 전달 활성화/비활성화 (Enabling/disabling alert forwarding)
- 프라이븟 레지스트리 설정 (Configuring a private registry)
- kubeconfig 파일 갱신 (Renewing the kubeconfig file)
NKE API
NKE API를 사용하면 사용자가 NKE 및 쿠버네티스 클러스터에 대한 관리 작업을 프로그래밍 방식으로 실행할 수 있다. API 문서는 https://www.nutanix.dev/reference/karbon에서 볼 수 있다.
파트너 쿠버네티스 배포
뉴타닉스 클라우드 플랫폼은 인증된 쿠버네티스 배포를 실행하기 위한 이상적인 솔루션이다. 뉴타닉스는 최신 애플리케이션을 대규모로 성공적으로 실행하는 데 필요한 모든 자원을 갖춘 엔터프라이즈급 플랫폼을 제공한다.
쿠버네티스 배포에는 컴퓨팅, 네트워크 및 스토리지가 필요하다. 뉴타닉스를 사용하면 IT 관리자와 개발자가 선호하는 쿠버네테스 배포판을 실행하기 위해 이러한 자원에 쉽게 액세스할 수 있다. Red Hat OpenShift, Google Anthos 및 기타 여러 벤더를 비롯한 여러 주요 쿠버네티스 배포 제공업체가 뉴타닉스와 함께 사용할 수 있도록 솔루션을 인증했다. 뉴타닉스 지원 포털에서 지원되는 파트너 소프트웨어 솔루션을 온라인으로 확인할 수 있다.
쿠버네티스 아키텍처
모든 쿠버네티스 배포에는 최소한 다음 컴포넌트가 포함된 기본 아키텍처가 있다:
- etcd - 모든 쿠버네티스 클러스터 설정 데이터, 상태 데이터 및 메타데이터를 저장하기 위한 키-값(Key-Value) 저장소이다.
- 쿠버네티스 컨트롤 플레인(Kubernetes control plane) - 여기에는 PODs를 스케줄링하고 클러스터 이벤트를 감지하고 응답하기 위한 쿠버네티스 API 서버 및 기타 컴포넌트가 포함된다.
- 쿠버네티스 워커 노드(Kubernetes worker nodes) - 애플리케이션 워크로드를 호스팅하는 머신이다.

또한 이러한 컴포넌트는 모든 쿠버네티스 컨트롤 플레인 및 워커 노드에서 실행된다.
- Kubelet
- Kube-proxy
- Container runtime
이러한 컴포넌트에 대한 자세한 정보는 쿠버네티스 문서(Kubernetes documentation)에서 찾을 수 있다.
Addendum
Release Notes & Change Log
본 문서를 사용하여 뉴타닉스 바이블의 변경 사항, 업데이트 및 추가 사항에 대한 최신 정보를 얻을 수 있습니다. 본 문서는 뉴타닉스 바이블의 내용이 변경될 때마다 업데이트됩니다.
Change Log
| 날짜 | 요약 | 상세 사항 |
| 2022년 11월 14일 | Book of Nutanix Cloud Clusters - AWS 업데이트 |
|
| 2022년 09월 09일 | 'Book of Storage Services - Files' 부분 업데이트 |
|
| 2022년 07월 28일 | Book of AOS에서 curator_cli 명령에 대한 설명 변경 |
|
| 2022년 07월 26일 | 'Book of Storage Services - Objects' 부분 업데이트 |
|
| 2022년 07월 25일 | 오브젝트 섹션의 'Book of Storage Services' 업데이트 |
|
| 2022년 06월 01일 | Book of Nutanix Cloud Clusters 업데이트 |
|
| 2022년 05월 20일 | Book of Network Services 업데이트 |
|
| 2022년 05월 09일 | Book of AHV 업데이트 |
|
| 2022년 05월 03일 | Book of Cloud Native 신규 추가 |
|
| 2022년 04월 15일 | Book of AOS 업데이트 |
|
| 2022년 04월 08일 | 다수 내용 업데이트 |
|
| 2022년 03월 25일 | 뉴타닉스 바이블 이미지 업데이트 |
|
| 2022년 03월 18일 | Book of AOS 업데이트 |
|
| 2022년 03월 16일 | Book of Network Services 업데이트 |
|
| 2022년 02월 18일 | 리소스 링크 업데이트 |
|
| 2021년 12월 03일 | PDF 다운로드 기능 추가 |
|
| 2021년 11월 19일 | 릴리즈 노트 추가 |
|
A Brief Lesson in History
인프라스트럭처의 역사와 오늘날 우리가 있는 곳으로 인도했던 기술들에 대해 간략히 살펴본다.
데이터센터의 진화
데이터센터는 지난 수십 년 동안 엄청나게 발전했다. 다음 섹션에서 각 시대를 자세히 살펴본다.
메인프레임 시대
메인프레임은 수년 동안 시장을 지배하였으며, 오늘날 우리기 사용하고 있는 기술의 핵심 기반을 제공하였다. 회사는 다음과 같은 메인프레임의 주요 특징을 활용할 수 있었다.
- 기본적으로 CPU, 메인 메모리, 스토리지가 컨버지드된 구조
- 내부 이중화 설계
그러나 메인프레임은 또한 다음과 같은 이슈를 제기하였다.
- 높은 인프라 조달 비용
- 내재된 복잡성
- 유연성 부족 및 높은 사일로 환경
독립형 서버로의 이동
기업 내 비즈니스 조직이 메인프레임 기능을 활용하기 어렵다는 사실이 부분적으로 피자박스 또는 독립형 서버를 도입하는 계기가 되었다. 독립형 서버의 주요 특징은 다음과 같다.
- CPU, 메인 메모리, DAS
- 메인프레임 보다 높은 유연성
- 네트워크를 통한 액세스
그러나 독립형 서버는 더 많은 이슈를 제기하였다.
- 사일로 수를 증가시킴
- 낮은 또는 균일하지 않은 자원 활용률
- 서버가 컴퓨트 및스토리지 모두에서 SPOF가 됨
중앙 집중식 스토리지
비즈니스는 항상 돈을 벌 필요가 있는데 데이터는 이러한 퍼즐의 핵심 요소이다. DAS를 사용하는 조직은 로컬에서 가용한 것보다 더 많은 공간이 필요하거나 서버 장애로 인해 데이터를 사용할 수 없는 환경에서 데이터 고가용성이 필요하였다.
중앙 집중식 스토리지는 메인프레임과 독립형 서버 모두를 대체하였는데 공유 가능한 대규모의 스토리지 풀 및 데이터 보호 기능을 제공하였다. 중앙 집중식 스토리지의 주요 특징은 다음과 같다.
- 스토리지 자원의 풀링을 통해 스토리지 활용률 향상
- RAID를 통한 중앙 집중식 데이터 보호로 서버 장애로 인한 데이터 손실 가능성 제거
- 네트워크를 통해 스토리지 서비스 제공
중앙 집중식 스토리지와 관련된 이슈는 다음과 같다.
- 중앙 집중식 스토리지가 잠재적으로 더 고가이지만 데이터는 하드웨어 보다 더 가치가 있다.
- 복잡성 증가 (SAN 패브릭, WWPNs, RAID 그룹, 볼륨, 스핀들 카운트 등)
- 중앙 집중식 스토리지는 다른 관리 툴/팀을 요구하였다.
가상화의 도입
시간상으로 이 시점에서 컴퓨트 활용률이 낮았고 자원 효율성은 수익성에 양향을 미치고 있었다. 그런 다음 가상화가 도입되어 단일 하드웨어에서 여러 개의 워크로드 및 운영체제를 VM으로 실행할 수 있었다. 가상화는 피자박스 사용률을 높였을 뿐만 아니라 사일로의 수와 장애가 미치는 영향을 증가시켰다. 가상화의 주요 특징은 다음과 같다.
- 하드웨어로부터 OS를 추상화 (VM)
- 매우 효율적인 컴퓨트 활용률은 워크로드 통합 유도
가상화와 관련된 이슈는 다음과 같다.
- 사일로 수 및 관리 복잡성 증가
- VM HA 기능 부족으로 컴퓨트 노드의 장애가 미치는 영향이 더 커짐
- 풀링된 지원 부족
- 다른 관리 툴/팀 필요
가상화의 성숙
하이퍼바이저는 매우 효율적이고 기능이 풍부한 솔루션이 되었다. VMware vMotion, HA, DRS 등과 같은 툴이 출시됨에 따라 사용자는 VM 고가용성을 제공하고 컴퓨트 워크로드를 동적으로 마이그레이션 할 수 있는 기능을 갖게 되었다. 유일한 주의사항은 두 개의 경로를 병합해야만 하는 중앙 집중식 스토리지에 의존한다는 것이었다. 유일한 단점은 이전에 스토리지 어레이에 대한 부하가 증가했고 VM 스프롤으로 인해 스토리지 I/O에 대한 경합이 발생했다.
주요 특징은 다음과 같다.
- 클러스터링을 통한 컴퓨트 자원의 풀링
- 컴퓨트 노드들 간에 워크로드를 동적으로 마이그레이션 하는 기능 (DRS/vMotion)
- 컴퓨트 노드 장애 시에 VM HA 기능 도입
- 중앙 집중식 스토리지를 요구
이슈는 다음과 같다.
- VM 스프롤에 의한 스토리지 수요 증가
- 더 많은 어레이의 스케일아웃에 대한 요구 사항은 사일로 수 및 복잡성을 증가시킴
- 어레이에 대한 요구 사항으로 인해 GB 당 가격 상승
- 어레이에 대한 자원 경합의 가능성
- 다음과 같은 요구 사항을 보장해야 하는 필요성 때문에 스토리지 설정을 훨씬 더 복잡하게 만들었다.
- 데이터스토어/LUN 당 VM 비율
- I/O 요구 사항을 만족하기 위한 스핀들 카운트
Solid State Disks (SSDs)
SSD는 수많은 디스크 인클로저에 대한 필요 없이 훨씬 높은 I/O 성능을 제공함으로써 이러한 I/O 병목현상을 완화하는 데 도움을 주었다. 그러나 성능이 엄청나게 향상되었으나 컨트롤러 및 네트워크가 가용한 방대한 I/O를 처리할 수 있도록 발전하지 못했다. SSD의 주요 특징은 다음과 같다.
- 기존 HDD 보다 훨씬 높은 I/O 특성
- 본질적으로 탐색 시간 제거
SSD와 관련된 주요 이슈는 다음과 같다.
- 병목현상이 디스크의 스토리지 I/O에서 컨트롤러/네트워크로 이동
- 사일로는 여전히 남아있음
- 어레이 설정의 복잡성은 여전히 남아있음
클라우드 시대
클라우드란 용어는 정의상 매우 모호할 수 있다. 간단히 말해서 다른 사람에 의해 어딘가에서 제공되는 서비스를 소비하고 활용할 수 있는 능력이다.
클라우드 도입으로 인해, IT, 비즈니스 및 최종 사용자의 관점이 바뀌었다.
비즈니스 그룹 및 IT 소비자는 IT가 클라우드와 동일한 기능, 민첩성 및 가치 창출 시간을 제공하도록 요구한다. 그렇지 않은 경우에 그들은 직접 클라우드로 갈 것인데, 이것은 IT 담당자에게 "데이터 보안"이라고 하는 새로운 이슈를 제기한다.
클라우드 서비스가 제공하는 핵심 기능은 다음과 같다.
- 셀프서비스 / 온 디멘드
- 신속한 가치 창출 시간 (TTV) / 진입 장벽이 거의 없음
- 서비스 및 SLA 중심
- 계약으로 가동시간 / 가용성 / 성능 보장
- 종량제 기반 모델
- 실제 사용량에 따라 비용 지불 (일부 서비스는 무료)
클라우드 분류 (Cloud Classifications)
대부분의 일반적인 클라우드 분류는 다음과 같은 세 가지의 주요 버킷으로 구분된다 (최고 레벨에서 시작하여 아래로 이동)
- SaaS (Software as a Service)
- 간단한 URL을 통해 소비되는 모든 소프트웨어 / 서비스
- 예: Workday, Salesfoce.com, Google Search 등
- PaaS (Platform as a Service)
- 개발 및 배포 플랫폼
- 예: Amazon Elastic Beanstalk / Relational Database Services (RDS), Google App Engine 등
- IaaS (Infrastructure as a Service)
- 서비스로 VM, 컨테이너, NFV 제공
- 예: Amazon EC2/ECS, Microsoft Azure, Google Compute Engine (GCE) 등
IT 포커스터의 이동 (Shift in IT focus)
클라우드는 IT에게 흥미로운 딜레마를 제기한다. IT는 클라우드를 받아들일 수도 있고, 아니면 대안을 제공하려고 노력할 수도 있다. IT는 데이터를 내부에 유지하려고 하지만, 셀프서비스, 신속성 등과 같은 클라우드 기능을 제공할 필요가 있다.
이러한 변화는 IT가 그들의 최종 사용자(회사 직원)에게 합법적인 서비스 제공자로서 보다 많은 역할을 하도록 요구한다.
레이턴시의 중요성
다음 그림은 특정 유형의 I/O와 관련된 다양한 레이턴시(Latency)를 나타낸다.
| 항목 | 레이턴시 | 비고 |
|---|---|---|
| L1 cache reference | 0.5 ns | |
| L2 cache reference | 7 ns | 14x L1 cache |
| DRAM access | 100 ns | 20x L2 cache, 200x L1 cache |
| 3D XPoint based NVMe SSD read | 10,000 of ns (expected) | 10 us or 0.01 ms |
| NAND NVMe SSD R/W | 20,000 ns | 20 us or 0.02 ms |
| NAND SATA SSD R/W | 50,000-60,000 ns | 50-60 us or 0.05-0.06 ms |
| Read 4K randomly from SSD | 150,000 ns | 150 us or 0.15 ms |
| P2P TCP/IP latency (phy to phy) | 150,000 ns | 150 us or 0.15 ms |
| P2P TCP/IP latency (vm to vm) | 250,000 ns | 250 us or 0.25 ms |
| Read 1MB sequentially from memory | 250,000 ns | 250 us or 0.25 ms |
| Round trip within datacenter | 500,000 ns | 500 us or 0.5 ms |
| Read 1MB sequentially from SSD | 1,000,000 ns | 1 ms, 4x memory |
| Disk seek | 10,000,000 ns or 10,000 us | 10 ms, 20x datacenter round trip |
| Read 1MB sequentially from disk | 20,000,000 ns or 20,000 us | 20 ms, 80x memory, 20x SSD |
| Send packet CA -> Netherlands -> CA | 150,000,000 ns | 150 ms |
(credit: Jeff Dean, https://gist.github.com/jboner/2841832)
상기 테이블은 CPU가 ~0.5-7ns에서 자신의 캐시(L1 vs. L2)에 액세스할 수 있음을 보여준다. 메인 메모리인 경우 이러한 액세스는 ~100ns에서 발생하지만 로컬 4K SSD 읽기는 150,000ns 또는 0.15ms이다.
일반적인 엔터프라이즈 클래스 SSD를 사용하는 경우 (이 경우에 Intel S3700 - SPEC), 본 디바이스는 다음을 수행할 수 있습니다.
- 랜덤 I/O 성능 (Random I/O performance):
- 랜덤 4K 읽기: 최대 75,000 IOPS
- 랜덤 4K 쓰기: 최대 36,000 IOPS
- 순차 대역폭 (Sequential bandwidth):
- 지속적인 순차 읽기: 최대 500MB/s
- 지속적인 순차 쓰기: 최대 460MB/s
- 레이턴시 (Latency):
- 읽기: 50us
- 쓰기: 65us
대역폭 살펴보기
기존 스토리지인 경우 I/O를 위한 몇 가지 주요 미디어 유형이 있다.
- 파이버 채널 (FC)
- 4-, 8-, 16- and 32-Gb
- 이더넷 (FCoE 포함)
- 1-, 10-Gb, (40-Gb IB) 등
하기 계산을 위해 인텔 S3700에서 제공하는 500MB/s 읽기, 460MB/s 쓰기 대역폭을 사용한다.
계산식은 다음과 같다.
numSSD = ROUNDUP((numConnections * connBW (in GB/s)) / ssdBW (R or W))
NOTE: 부분 SSD가 가능하지 않기 때문에 숫자는 반올림되었다. 계산식은 모든 I/O를 처리하기 위해 필요한 CPU를 고려하지 않으며 컨트롤러 CPU 파워를 무제한이라고 가정한다.
| 네트워크 대역폭 | 네트워크 대역폭을 최대로 활용하기 위해 필요한 SSD | ||
|---|---|---|---|
| 컨트롤러 연결 | 가용한 네트워크 대역폭 | 읽기 I/O | 쓰기 I/O |
| Dual 4Gb FC | 8Gb == 1GB | 2 | 3 |
| Dual 8Gb FC | 16Gb == 2GB | 4 | 5 |
| Dual 16Gb FC | 32Gb == 4GB | 8 | 9 |
| Dual 32Gb FC | 64Gb == 8GB | 16 | 19 |
| Dual 1Gb ETH | 2Gb == 0.25GB | 1 | 1 |
| Dual 10Gb ETH | 20Gb == 2.5GB | 5 | 6 |
상기 테이블에서 보는 것과 같이 SSD가 제공할 수 있는 이론적인 최대 성능을 활용하고자 할 때, 활용되는 네트워킹의 유형에 따라 1 ~ 9개의 SSD를 사용하는 어떤 경우에서든 네트워크가 병목현상의 원인이 될 수 있다.
메모리 레이턴시에 미치는 영향
일반적인 메인 메모리 레이턴시는 ~100ns(가변적임)이며 다음과 같은 계산을 수행할 수 있다.
- Local memory read latency = 100ns + [OS / hypervisor overhead]
- Network memory read latency = 100ns + NW RTT latency + [2 x OS / hypervisor overhead]
일반적인 네트워크 RTT가 ~0.5ms(500000ns, 스위치 벤더에 따라 가변적임)라고 가정하면 계산식은 다음과 같다.
- Network memory read latency = 100ns + 500,000ns + [2 x OS / hypervisor overhead]
이론적으로 10,000ns RTT를 제공하는 매우 빠른 네트워크를 가정하면 계산식은 다음과 같다.
- Network memory read latency = 100ns + 10,000ns + [2 x OS / hypervisor overhead]
이것이 의미하는 바는 이론적으로 빠른 네트워크라고 하더라도 네트워크가 아닌 메모리 액세스와 비교하면 약 10,000%의 오버헤드가 있다는 것이다. 네트워크 속도가 느린 경우에 레이턴시가 500,000% 이상 증가할 수 있다.
이러한 오버헤드를 줄이기 위해 서버 측 캐싱 기술이 도입되었다.
유저 스페이스와 커널 스페이스
자주 논의되는 주제 중의 하나는 커널 스페이스와 유저 스페이스에서 수행되는 작업과 관련된 논쟁이다. 여기에서 각각이 무엇인지, 그리고 각각의 장단점에 대해 설명한다.
모든 운영체제(OS)에는 두 가지 핵심 실행 영역이 있다.
- 커널 스페이스 (Kernel Space)
- OS에서 가장 많은 권한을 갖는 부분
- 스케줄링, 메모리 관리 등을 처리
- 물리적 디바이스 드라이버를 포함하고 하드웨어 상호작용을 처리
- 유저 스페이스 (User Space)
- 커널 스페이스 이외의 모든 것
- 대부분의 애플리케이션과 프로세스가 있는 곳
- 보호된 메모리 및 실행
이 두 개의 스페이스는 OS 오퍼레이션을 위해 함께 동작한다. 다음 단계로 넘어가기 전에 몇 가지 주요 항목을 정의한다.
- 시스템 콜 (System Call)
- 커널 콜(Kernel Call)이라고도 불리는데, 액티브 프로세스에서 인터럽트(자세한 것은 나중에 설명)를 통해 생성된 요청으로 커널에 의해 수행되는 어떤 작업
- 컨텍스트 스위치 (Context Switch)
- 실행을 프로세스에서 커널로 또는 그 반대로 이동
예를 들어, 일부 데이터를 디스크에 쓰는 간단한 애플리케이션인 경우에 다음과 같은 순서로 작업이 수행된다.
- 애플리케이션이 디스크에 데이터를 쓰려고 한다.
- 시스템 콜을 호출한다.
- 커널로 컨텍스트를 전환한다.
- 커널이 데이터를 복사한다.
- 드라이버를 통해 디스크에 쓰기를 실행한다.
다음은 이러한 상호작용의 예를 보여준다.
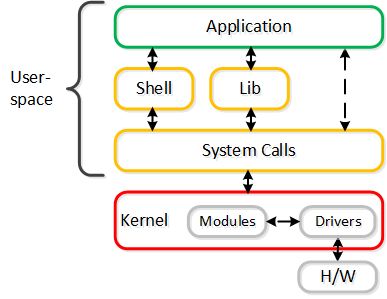 유저 및 커널 스페이스 상호작용 (User and Kernel Space Interaction)
유저 및 커널 스페이스 상호작용 (User and Kernel Space Interaction)
하나가 다른 것보다 나은가? 현실에는 각각 장단점이 있다.
- 유저 스페이스 (User Space)
- 매우 유연함
- 장애 도메인의 격리 (프로세스)
- 비효율적일 수 있음
- 컨텍스트 스위치를 전환하는 데 걸리는 시간 (~1,000ns)
- 커널 스페이스 (Kernel Space)
- 매우 엄격함
- 장애 도메인이 넓음
- 효율적일 수 있음
- 컨텍스트 스위치를 줄임
폴링과 인터럽트
또 다른 핵심 컴포넌트는 이 둘 사이의 상호작용을 처리하는 방법이다. 상호작용에는 두 가지 주요 유형이 있다.
- 폴링 (Polling)
- 끊임없이 "POLL", e.g. 지속적으로 무언가를 요청
- 예: 마우스, 모니터 새로 고침 빈도 등
- CPU를 지속적으로 요구하지만 레이턴시는 훨씬 짧음
- 커널 인터럽트 핸들러 비용 제거
- 컨텍스트 스위치를 제거
- 인터럽트 (Interrupt)
- "미안하지만, 나는 FOO가 필요해"
- 예: 무언가의 요청을 위해 손을 듦
- "CPU 효율"이 더 높을 수 있지만 반드시 그런 것은 아님
- 일반적으로 훨씬 더 높은 레이턴시
유저 스페이스 / 폴링으로 이동
디바이스가 훨씬 빨라짐에 따라 (e.g. NVMe, 인텔 Optane, pMEM), 커널과 디바이스 상호작용이 병목현상이 되었다. 이러한 병목현상을 없애기 위해 많은 벤더가 작업을 커널에서 폴링 기반의 유저 스페이스로 옮김으로써 훨씬 나은 결과를 얻었다.
이에 대한 좋은 사례가 인텔의 Storage Performance Development Kit (SPDK) 및 Data Plane Development Kit (DPDK)이다. 이 프로젝트들은 성능을 극대화하고 가능한 한 레이턴시를 줄이는 데 중점을 두고 있으며 큰 성공을 거두었다.
이러한 변화는 두 가지 핵심 변경으로 이루어져 있다.
- 디바이스 드라이버를 유저 스페이스로 이동 (커널 대신)
- 폴링 사용 (인터럽트 대신)
이는 커널 기반의 작업과 비교했을 때 훨씬 뛰어난 성능을 제공하는 데 다음을 제거하였기 때문에 가능하게 되었다.
- 값비싼 시스템 콜 및 인터럽트 핸들러
- 데이터 복사
- 컨텍스트 스위치
다음은 유저 스페이스 드라이버를 사용하는 디바이스 상호작용을 보여준다.
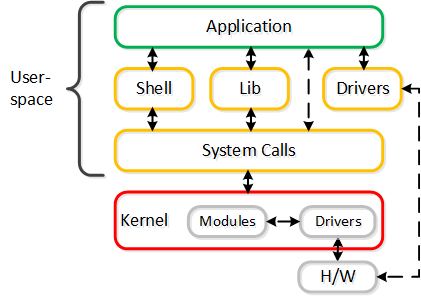 유저 스페이스와 폴링 상호작용 (User Space and Polling Interaction)
유저 스페이스와 폴링 상호작용 (User Space and Polling Interaction)
사실은 뉴타닉스가 AHV 제품(vhost-user-scsi)을 위해 개발했던 일부 소프트웨어가 인텔의 SPDK 프로젝트에 실제적으로 사용되고 있다.
Book of Web-Scale
web·scale - /web ‘ skãl/ - noun - computing architecture
인프라 및 컴퓨팅 아키텍처에 대한 새로운 접근 방식.
본 섹션에서는 “웹-스케일(Web-Scale)” 인프라의 몇 가지 핵심 개념과 이를 활용하는 이유에 대해 설명한다. 시작하기 전에, "웹-스케일은 웹-스케일(e.g. Google, Facebook, Microsoft)이 되어야 한다는 것을 의미하는 것은 아니다"라는 것을 명시해야 한다. “웹-스케일” 구조는 어떤 규모(세 개의 노드 또는 수천 개의 노드)에서도 적용 가능하며 많은 장점을 제공한다.
역사적으로 도전 과제는 다음과 같다.
- 복잡성, 복잡성, 복잡성
- 증분 기반 성장에 대한 요구
- 민첩성 필요
"웹 스케일" 인프라에 대해 이야기할 때 사용되는 몇 가지 핵심 컨스트럭트가 있다.
- 하이퍼컨버전스 (Hyper-convergence)
- 소프트웨어 정의 인텔리전스 (Software defined intelligence)
- 분산 자율 시스템 (Distributed autonomous system)
- 증분 및 선형 스케일 아웃 (Incremental and linear scale out)
기타 관련 항목은 다음과 같다.
- API 기반 자동화 및 풍부한 분석 기능 (API-based automation and rich analytics)
- 핵심 테넌트로서의 보안 (Security as a core tenant)
- 셀프 힐링 (Self-healing)
다음 섹션에서 그들이 실제로 무엇을 의미하는지에 대한 기술적 관점을 제공한다.
하이퍼컨버전스 (Hyper-Convergence)
하이퍼컨버전스(Hyper-convergence)가 실제로 무엇을 의미하는지에 대해서는 의견이 분분하다. 또한 컴포넌트(e.g. 가상화, 네트워킹 등)의 범위에 따라 다르다. 그러나 핵심 개념은 다음과 같다: 기본적으로 두 개 이상의 컴포넌트를 하나의 유닛으로 결합한다. 여기에서 “기본적으로(Natively)”가 핵심 단어이다. 가장 효과적이기 위해서는 컴포넌트가 기본적으로 통합되어야 하며 단순히 함께 번들 되어서는 안된다. 뉴타닉스의 경우 컴퓨트 + 스토리지를 기본적으로 통합하여 어플라이언스에서 사용되는 단일 노드를 구성한다. 다른 벤더에게는 스토리지를 네트워크 등과 통합하는 것이 될 수 있다.
하이퍼컨버전스가 실제적으로 의미하는 것은 다음과 같다.
- 쉽게 확장할 수 있도록 두 개 이상의 컴포넌트를 단일 유닛(Single Unit)으로 기본적으로 통합하는 것
장점은 다음과 같다.
- 유닛 단위로 확장
- 로컬 I/O 지원
- 컴퓨트와 스토리지를 통합함으로써 기존 컴퓨트/스토리지 사일로 제거
소프트웨어 정의 인텔리전스 (Software-Defined Intelligence)
소프트웨어 정의 인텔리전스(Software-Defined Intelligence)는 일반적으로 전용 또는 특정 하드웨어(e.g. ASIC/FPGA)에 구현된 핵심 로직을 범용 하드웨어에서 소프트웨어로 구현하는 것이다. 뉴타닉스의 경우 기존 스토리지 로직(e.g. RAID, 중복제거, 압축 등)을 표준 하드웨어에 탑재된 각 뉴타닉스 컨트롤러 VM(CVM)에서 실행되는 소프트웨어로 구현하였다.
Note
지원 아키텍처 (Supported Architectures)
뉴타닉스는 현재 x86 및 IBM POWER 아키텍처를 모두 지원한다.
소프트웨어 정의 인텔리전스의 실제적인 의미는 다음과 같다.
- 하드웨어에서 핵심 로직을 가져와 범용 하드웨어에서 소프트웨어로 수행
장점은 다음과 같다.
- 빠른 릴리스 사이클
- 전용 하드웨어에 대한 의존성 제거
- 더 나은 경제성을 위해 범용 하드웨어 활용
- 평생 투자 보호
평생 투자 보호(Lifespan Investment Protection)에 대해 좀 더 부연 설명하면: 구형 하드웨어에서 최신 및 최고의 소프트웨어를 실행할 수 있다. 이것은 감가상각 주기에 들어간 하드웨어에서 최신 소프트웨어를 실행시킬 수 있으며 공장에서 출하된 새로운 제품과 기능적으로 동일하다는 것을 의미한다.
분산 자율 시스템 (Distributed Autonomous Systems)
분산 자율 시스템(Distributed Autonomous Systems)은 단일 유닛이 어떤 일의 수행에 대한 책임을 갖는 기존 개념에서 벗어나 클러스터 내의 모든 노드에게 그 역할을 분산하는 것을 포함한다. 이것을 순수 분산 시스템을 만드는 것으로 생각할 수 있다. 전통적으로 벤더는 하드웨어가 매우 안정적일 것이라고 가정했는데 이것은 대부분의 경우에 사실일 수 있다. 그러나 분산 시스템의 핵심은 하드웨어 장애가 궁극적으로 발생할 것이고 해당 장애를 우아하고 중단 없는 방식으로 처리하는 것이 중요하다는 아이디어이다.
분산 시스템은 장애를 수용하고 치료하며 셀프-힐링 및 자율적인 무언가를 형성하도록 설계되었다. 컴포넌트 장애 시에 시스템은 장애를 투명하게 처리 및 치료하며 예상된 오퍼레이션을 지속한다. 경고를 통해 관리자가 장애 상황을 인지할 수 있지만 시간에 민감한 치명적인 사항이 아니면 어떤 조치(e.g. 장애 노드 교체)는 관리자의 일정에 맞추어 수행될 수 있다. 다른 방법은 장애가 발생한 상태로 두는 것이다(교체 없는 리빌드). “리더(Leader)”가 필요한 항목인 경우에 선출 프로세스(Election Process)가 활용된다. 리더가 실패하면 새로운 리더가 선출된다. 작업 처리를 분산하기 위해 맵리듀스(MapReduce) 개념이 활용된다.
분산 자율 시스템이 실제적으로 의미하는 것은 다음과 같다.
- 시스템 내의 모든 노드에 역할 및 책임을 분산
- 맵리듀스와 같은 개념을 활용하여 작업의 분산 처리 수행
- “리더(Leader)”가 필요한 경우에 선출 프로세스 활용
장점은 다음과 같다.
- SPOF 제거
- 워크로드를 분산하여 병목현상 제거
점진적인 선형 스케일아웃 (Incremental and linear scale out)
증분 및 선형 스케일아웃(Incremental and Linear Scale-out)은 특정 규모의 자원으로 시작하고 필요할 때 시스템을 확장함과 동시에 시스템의 성능을 선형적으로 증가시키는 기능과 관련되어 있다. 위에서 언급한 모든 컨스트럭트는 이것을 실현하는 데 중요한 역할을 한다. 예를 들어 전통적으로 가상 워크로드를 실행하기 위해 3-계층의 컴포넌트가 있다: 서버, 스토리지, 네트워크 - 이들 각각은 독립적으로 확장된다. 예를 들어 서버 수를 확장할 때 스토리지 성능을 확장하지 않는다. 뉴타닉스와 같은 하이퍼컨버지드 플랫폼을 사용하면 새로운 노드를 확장할 때 다음과 같은 자원이 자원이 동시에 확장된다.
- 하이퍼바이저 / 컴퓨트 노드 수
- 스토리지 컨트롤러 수
- 컴퓨트 및 스토리지 성능 / 용량
- 클러스터 전체 오퍼레이션에 참여하는 노드 수
점진적인 선형 스케일아웃이 실제적으로 의미하는 것은 다음과 같다.
- 성능/능력을 선형적으로 증가시키면서 스토리지/컴퓨트를 점진적으로 확장할 수 있는 기능
장점은 다음과 같다.
- 작은 규모로 시작하고 확장하는 기능
- 규모에 관계없이 균일하고 일관성 있는 성능
요약 정리 (Making Sense of It All)
웹-스케일 인프라의 특징을 요약하면 다음과 같다.
- 비효율적인 컴퓨트 활용률이 가상화로 이동하는 계기가 되었다.
- vMotion, HA, DRS 등과 같은 기능은 중앙 집중식 스토리지를 요구하였다.
- VM 스프롤은 스토리지에서 부하 및 경합이 증가하였다.
- SSD가 이슈를 줄이기 위해 도입되었으나 병목현상이 네트워크/컨트롤러로 변경되었다.
- 네트워크를 통한 캐시/메모리 액세스는 오버헤드가 커서 장점이 최소화되었다.
- 어레이 설정의 복잡성은 여전히 동일한 상태로 남아 있다.
- 서버 측 캐시가 어레이 부하 및 네트워크 영향을 줄이기 위해 도입되었으나 솔루션에 다른 컴포넌트를 추가시켰다.
- 로컬리티는 전통적으로 네트워크를 경유할 때 직면하는 병목현상 및 오버헤드를 줄이는 데 도움을 준다.
- 포커스가 인프라에서 관리 편의성 및 스택 단순화로 이동되었다.
- 웹-스케일 세계의 탄생!
About the Nutanix Bible
뉴타닉스 바이블은 Dheeraj Pandey(뉴타닉스의 창립자이자 전 CEO)와 Steven Poitras(전 수석 설계자) 없이는 불가능했을 것입니다.
뉴타닉스 바이블이 무슨 이유로 어떻게 만들어졌는지에 대한 Dheeraj의 인용문을 참조해 주세요:
First and foremost, let me address the name of the book, which to some would seem not fully inclusive vis-à-vis their own faiths, or to others who are agnostic or atheist. There is a Merriam Webster meaning of the word “bible” that is not literally about scriptures: “a publication that is preeminent especially in authoritativeness or wide readership”. And that is how you should interpret its roots. It started being written by one of the most humble yet knowledgeable employees at Nutanix, Steven Poitras, our first Solution Architect who continues to be authoritative on the subject without wielding his “early employee” primogeniture. Knowledge to him was not power – the act of sharing that knowledge is what makes him eminently powerful in this company. Steve epitomizes culture in this company – by helping everyone else out with his authority on the subject, by helping them automate their chores in Power Shell or Python, by building insightful reference architectures (that are beautifully balanced in both content and form), by being a real-time buddy to anyone needing help on Yammer or Twitter, by being transparent with engineers on the need to self-reflect and self-improve, and by being ambitious.
When he came forward to write a blog, his big dream was to lead with transparency, and to build advocates in the field who would be empowered to make design trade-offs based on this transparency. It is rare for companies to open up on design and architecture as much as Steve has with his blog. Most open source companies – who at the surface might seem transparent because their code is open source – never talk in-depth about design, and “how it works” under the hood. When our competitors know about our product or design weaknesses, it makes us stronger – because there is very little to hide, and everything to gain when something gets critiqued under a crosshair. A public admonition of a feature trade-off or a design decision drives the entire company on Yammer in quick time, and before long, we’ve a conclusion on whether it is a genuine weakness or a true strength that someone is fear-mongering on. Nutanix Bible, in essence, protects us from drinking our own kool aid. That is the power of an honest discourse with our customers and partners.
This ever-improving artifact, beyond being authoritative, is also enjoying wide readership across the world. Architects, managers, and CIOs alike, have stopped me in conference hallways to talk about how refreshingly lucid the writing style is, with some painfully detailed illustrations, visio diagrams, and pictorials. Steve has taken time to tell the web-scale story, without taking shortcuts. Democratizing our distributed architecture was not going to be easy in a world where most IT practitioners have been buried in dealing with the “urgent”. The Bible bridges the gap between IT and DevOps, because it attempts to explain computer science and software engineering trade-offs in very simple terms. We hope that in the coming 3-5 years, IT will speak a language that helps them get closer to the DevOps’ web-scale jargon.
– Dheeraj Pandey, Former CEO of Nutanix
Have feedback? Find a typo? Send feedback to biblefeedback at nutanix dot com
To learn more about Nutanix, check it out for yourself by taking a Nutanix Test Drive!
Thank you for reading The Nutanix Bible! Stay tuned for many more upcoming updates and enjoy the Nutanix platform!
This Classic Edition of The Nutanix Bible is an homage to the OG, Steve Poitras who started the Nutanix Bible ten years ago!